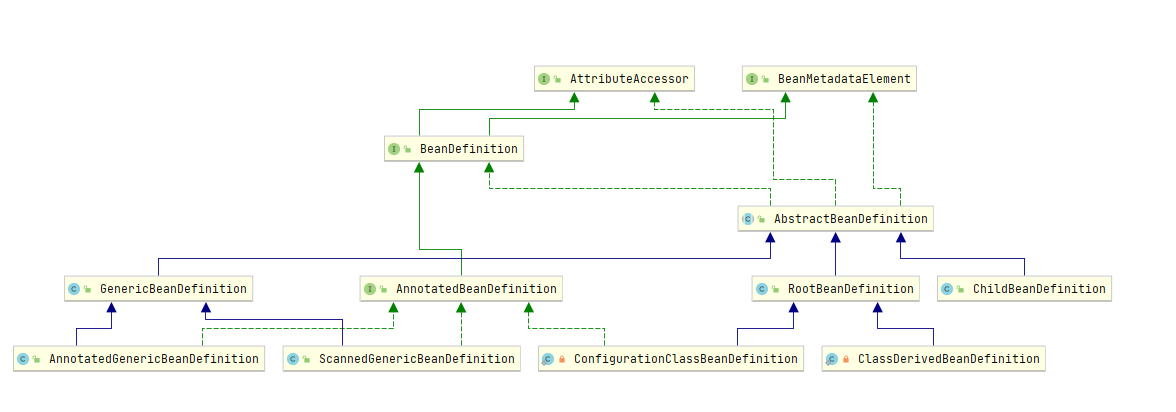
我一直是这样以为的:pytorch的底层实现是c++(这一点没有问题,见下边的pytorch结构图),然后这个部分顺理成章的被命名为torch,并提供c++接口,我们在python中常用的是带有python接口的,所以被称为pytorch。昨天无意中看到Torch是由lua语言写的,这让我十分震惊,完全颠覆了我的想象。所以今天准备查找并记录一下pytorch的发展历史,与其他框架的联系。当然以下列举的部分难以面面俱到,如果您知道哪些有意思的相关知识,请在评论去评论。
pytorch结构图
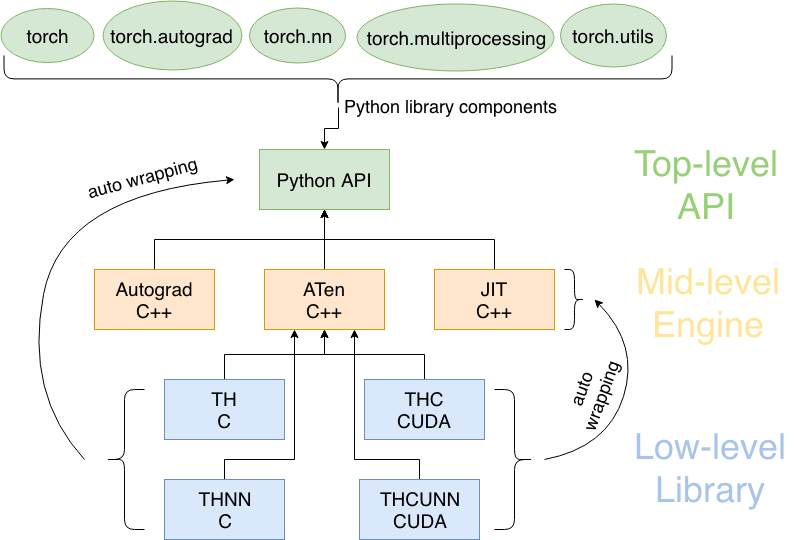
- 图片来源 https://golden.com/wiki/PyTorch-NMGD4Y4,如果你想了解有关PyTorch 中的自动微分,PyTorch 基金会的相关信息,可以点进去看一下。
发展历史
pytiorch ,如果您想了解pytorch的技术新闻可点击pytorch的官方博客。2016年10月,PyTorch开始作为Adam Paszke的实习项目。
Torch (基础)
Torch 是一个Facebook的开源机器学习库、一个科学计算框架和一种基于 Lua 编程语言的脚本语言。它于2002年10月首次发布。Torch的开发于2017年转移到PyTorch。
同时期的学习框架还有MATL AB和OpenNN等。MATL AB是由美国MathWorks公司出品的一种用于算法开发、数据分析以及数值计算的高级技术计算语言和交互式环境。OpenNN开发于2003年在国际工程数值方法中心的名为RAMFLOOD的项目中是一个使用C++编写的开源类库。OpenNN的主要优点是其高性能。该库在执行速度和内存分配方面非常出色。它不断优化和并行化,以最大限度地提高其效率。并且Torch的论文中也提到了Matlab:Torch7: A Matlab-like Environment for Machine Learning,Neural Information Processing Systems. 2011.。
Caffe(声明式编程风格)
Caffe(https://github.com/BVLC/caffe)是以C++/CUDA代码为主的深度学习框架,需要进行编译安装,支持命令行、Python和MATLAB接口、单机多卡、多机多卡使用。Caffe的全称是:Convolutional architecture forfast feature embedding,它是一个清晰、高效的深度学习框架。
Caffe是一款知名的深度学习框架,由加州大学伯克利分校的贾扬清博士于2013年在Github上发布。Caffe2018 于 21 年 2022 月底并入 PyTorch。并且在pytorch的开源项目中可以看到名为caffe2的文件夹。
Caffe 遵循了神经网络的一个简单假设——所有的计算都是以layer(如relu_layer:https://github.com/BVLC/caffe/blob/2a1c552b66f026c7508d390b526f2495ed3be594/src/caffe/layers/relu_layer.cpp)的形式表示的,layer做的事情就是处理一些数据,然后输出一些计算以后的结果。比如说卷积,就是输入一个图像,然后和这一层的参数(filter)做卷Captain Jack积,然后输出卷积的结果。每一个layer需要做两个计算:1,Forward是从输入计算输出。2,Backward是从上面给的gradient来计算相对于输入的gradient。只要这两个函数实现了以后,我们就可以把很多层连接成一个网络,这个网络做的事情就是输入我们的数据(图像或者语音等),然后来计算我们需要的输出(比如说识别的label),在training的时候,我们可以根据已有的label来计算loss和gradient,然后用gradient来update网络的参数,这个就是Caffe的一个基本流程。
这是一个官方的caffee的例子:https://github.com/BVLC/caffe/tree/master/examples/mnist ,需要用我们熟悉并使用Google Protobuf定义网络,定义 MNIST 求解器。Caffe通过“blobs”即以4维数组的方式存储和传递数据。Blobs提供了一个统一的内存接口,用于批量图像(或其它数据)的操作,参数或参数更新。Models是以Google Protocol Buffers的方式存储在磁盘上。大型数据存储在LevelDB数据库中。Caffe保留所有的有向无环层图,确保正确的进行前向传播和反向传播。Caffe模型是终端到终端的机器学习系统。一个典型的网络开始于数据层,结束于loss层。通过一个单一的开关,使其网络运行在CPU或GPU上。在CPU或GPU上,层会产生相同的结果。在使用上,caffe(c++)的使用需要进行复杂的编译操作(相比后来的pytorch),所以在caffe流行的时期,有时一个实验室中使用的caffe还是上一届的师兄安装的。但是现在仍有许多论文使用caffee框架,知乎上也有问题:caffe停更这么多年,为何现在还有一些论文开源代码还是使用caffe?
这里引用一下Captain Jack的回答:经典的数据结构先行的程序架构。
- 整个caffe都是围绕那个 prototxt 定义来实现的。
- 没有太多额外的系统方向的代码,项目结构清晰,比如:分布式、跨平台、通讯、动态dispatch等等。
- 和现在的框架比,那就是最小可用产品。
- 历史占用率高。
所以,
- 改代码容易,你改改 PyTorch、掏粪 试试。
- 作为一个数据格式的标准,转换比较容易,到现在 onnx 也就和 caffe 的 prototxt 打平手。很多私有、商业实现还是以 caffe 格式支持为准。
- 可能是最重要的:熟悉了懒得学新的,改改caffe又不是不能用。
Theano(创新观点)
Theano(https://github.com/Theano/Theano)是一个Python库和优化编译器的开源项目, 用于操作和评估数学表达式,尤其是矩阵值表达式。其计算是使用NumPy语法表示,并且编译后可在CPU/GPU架构上高效运行。
Theano多年来引入很多创新并已被其他框架采用和完善。例如,能够将模型表示为数学表达式,重写计算图以获得更好的性能和内存使用,在GPU上透明执行,高阶自动微分都已成为主流思想。
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口。
CG
-
深度学习软件比较https://en.wikipedia.org/wiki/Comparison_of_deep_learning_software
-
[源码解析] PyTorch 分布式(1)------历史和概述 https://www.cnblogs.com/rossiXYZ/p/15496268.html
-
https://alexmoltzau.medium.com/pytorch-governance-and-history-2e5889b79dc1
-
宣布成立 PyTorch 基金会:尖端 AI 框架的新时代 2022.12 https://ai.meta.com/blog/pytorch-foundation/
-
LUA Torch 回忆录 https://zhuanlan.zhihu.com/p/380924980?utm_id=0
-
https://en.wikipedia.org/wiki/Torch_(machine_learning)
-
如何评价 Theano?
h ttps://www.zhihu.com/question/35485591 -
Chainer是一个开源的深度学习框架, 完全在NumPy和CuPy Python库
的基础上用Python编写,因其采用边运行边定义方案以及在大型系统上的性 -
Theano实现了非常先进的优化技术来优化完整的计算图。它将代数的各个方面与优化编译器的各个方面相结合。图形的一部分可以编译成 C 语言代码。对于重复计算,评估速度至关重要,Theano通过生成非常有效的代码来达到此目的。 https://www.tutorialspoint.com/theano/theano_computational_graph.htm
-
深度学习框架——自动求导 https://www.cnblogs.com/wolfling/p/14919024.html
-
大模型:
-
OneFlow的大模型分片保存和加载策略
-
一块GPU训练TB级推荐模型不是梦,OneEmbedding性能一骑绝尘
-
大模型训练难于上青天?效率超群、易用的“李白”模型库来了
-
深度学习利器之自动微分(1)



![[NLP]LLaMA与LLamMA2解读](https://img-blog.csdnimg.cn/afc91e2e247e4d148ff9119f2bd40efd.png)