Llama 2 发布! Meta 刚刚发布了 LLaMa 2,它是 LLaMA 的下一代版本,具有商业友好的许可证。🤯😍 LLaMA 2 有 3 种不同的尺寸:7B、13B 和 70B。 7B & 13B 使用与 LLaMA 1 相同的架构,并且是商业用途的 1 对 1 替代🔥

简介
- 🧮 7B、13B & 70B 参数版本
- 🧠 70B模型采用分组查询注意力(GQA)
- 🛠 聊天模型可以使用工具和插件
- 🚀 LLaMA 2-CHAT 与 OpenAI ChatGPT 效果一样好
- 🤗 发布在HuggingFace:https://huggingface.co/meta-llama

- 公告: https://ai.meta.com/llama/
- 论文:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
- 模型: https://huggingface.co/models?other=llama-2
Llama 2相比Llama有哪些升级?
-
Llama 2 模型接受了 2 万亿个标记的训练,上下文长度是 Llama 1 的两倍。Llama-2-chat 模型还接受了超过 100 万个新的人类注释的训练。
-
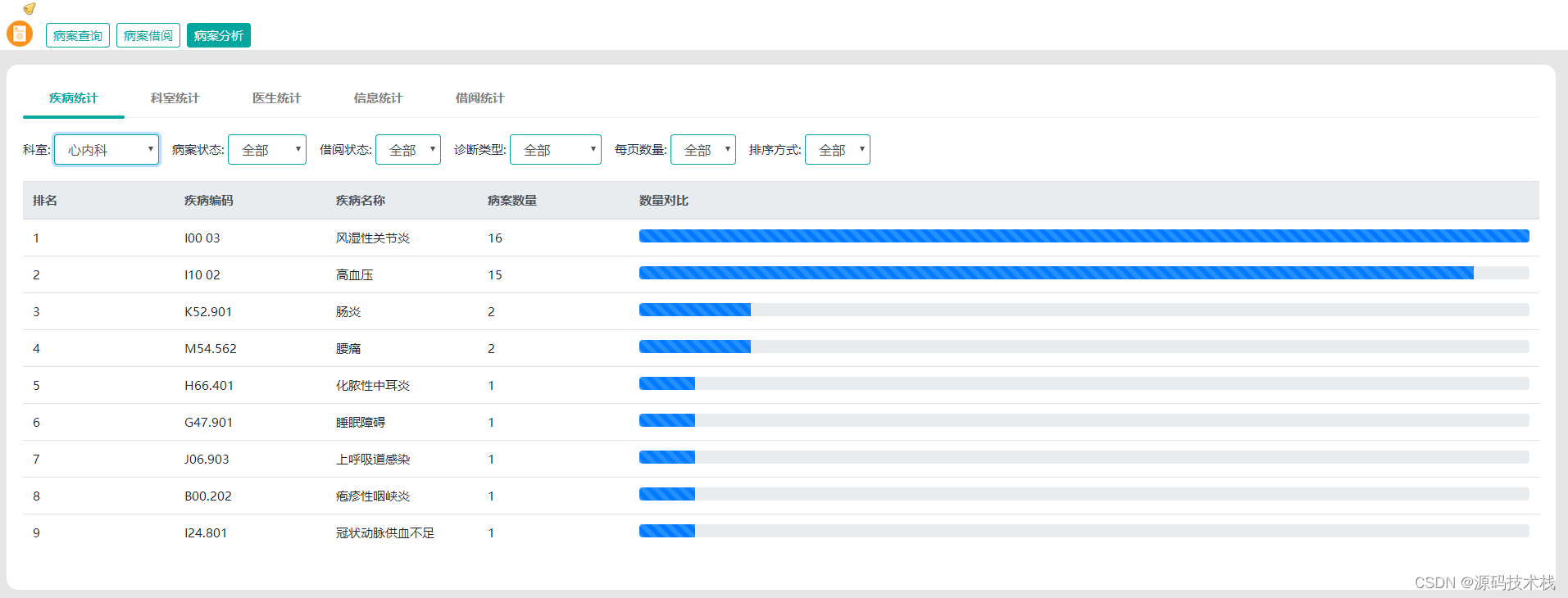
Llama 2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。
- 从人类反馈中强化学习,除了Llama 2版本,还发布了LLaMA-2-chat ,使用来自人类反馈的强化学习来确保安全性和帮助性。
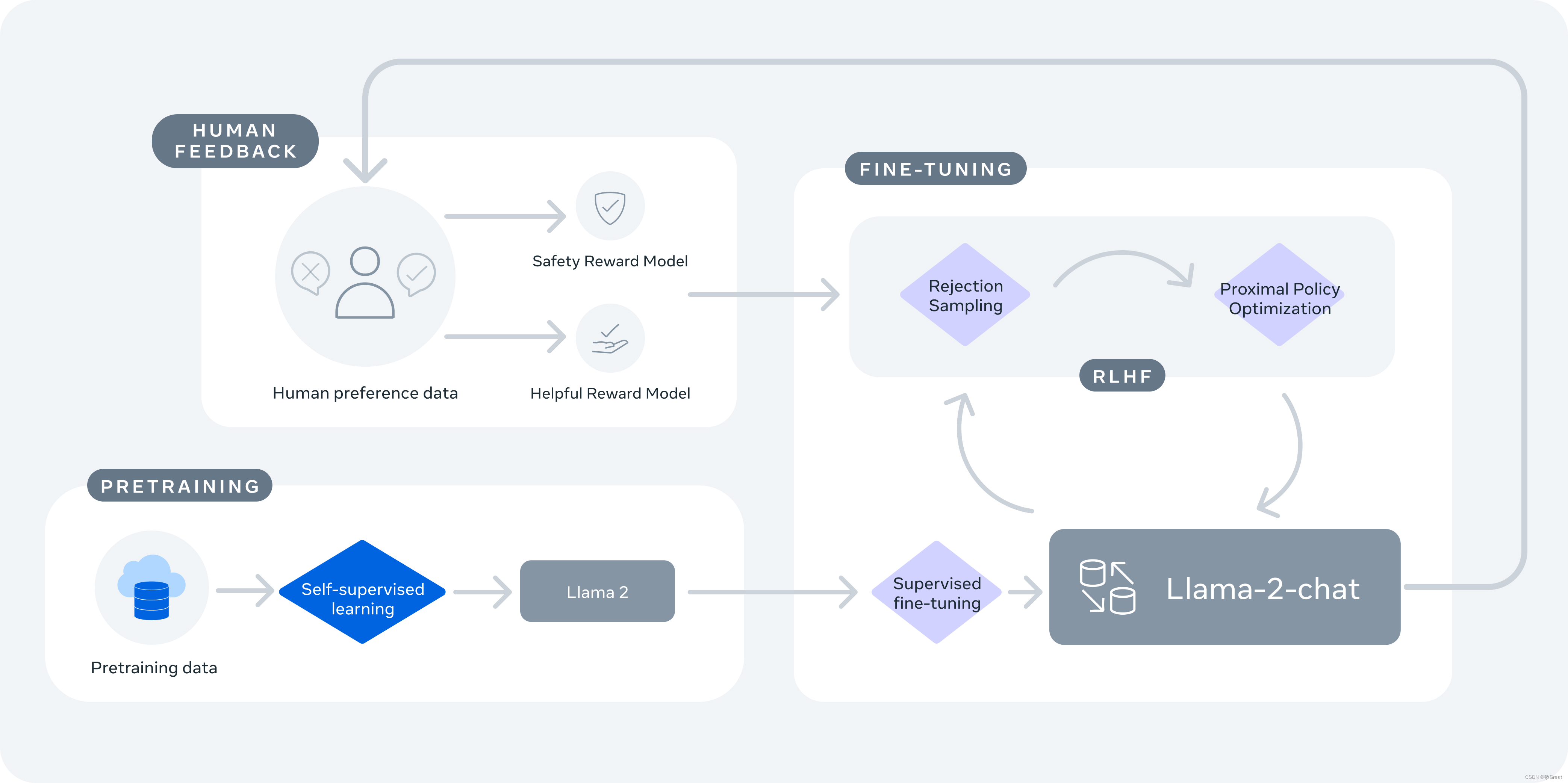
训练 Llama-2-chat:Llama 2 使用公开的在线数据进行预训练。 然后通过使用监督微调创建 Llama-2-chat 的初始版本。 接下来,Llama-2-chat 使用人类反馈强化学习 (RLHF) 进行迭代细化,其中包括拒绝采样和近端策略优化 (PPO)。
预训练
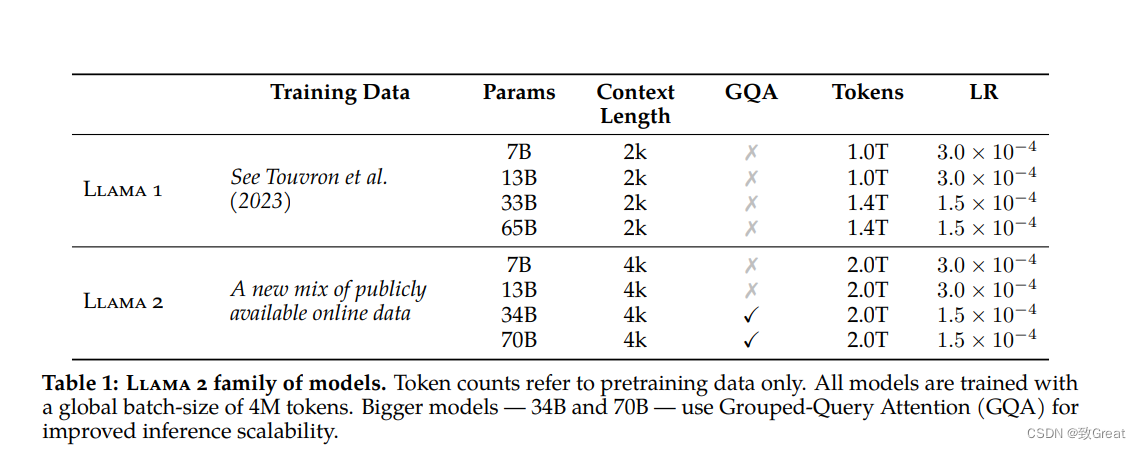
为了创建新的 Llama 2 模型系列,我们从Llama预训练方法开始(在参数小的情况尽量学习更多高质量的数据),使用优化的自回归变压器,但进行了一些更改以提高性能。具体来说,进行了更强大的数据清理 ,更新了数据混合,对总标记数量增加了 40% 进行了训练,将上下文长度加倍,并使用分组查询注意力 (GQA) 来提高更大模型的推理可扩展性。 表 1 比较了新 Llama 2 型号与 Llama 1 型号的属性。
预训练数据
从论文总结来看,主要有以下工作:
- 训练语料库包含来自公开来源的新数据组合,其中不包括来自 Meta 产品或服务的数据,强调公开
- 努力从某些已知包含大量个人信息的网站中删除数据,注重隐私。
- 对 2 万亿个token的数据进行了训练,因为这提供了良好的性能与成本权衡,对最真实的来源进行上采样,以增加知识并抑制幻觉,保持真实
- 进行了各种预训练数据调查,以便用户更好地了解模型的潜在能力和局限性,保证安全
预训练细节
模型结构
Llama 2采用了 Llama 1 的大部分预训练设置和模型架构,使用标准Transformer 架构,使用 RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
与 Llama 1 的主要架构差异包括增加了上下文长度和分组查询注意力(GQA)。 论文在附录 A.2.1 节中详细介绍了这些差异消融实验以证明其重要性。
- 上下文长度: Llama 2 的上下文窗口从 2048 个标记扩展到 4096 个字符。 越长上下文窗口使模型能够处理更多信息,这对于支持聊天应用程序中较长的历史记录、各种摘要任务以及理解较长的文档。多个评测结果表示较长的上下文模型在各种通用任务上保持了强大的性能。
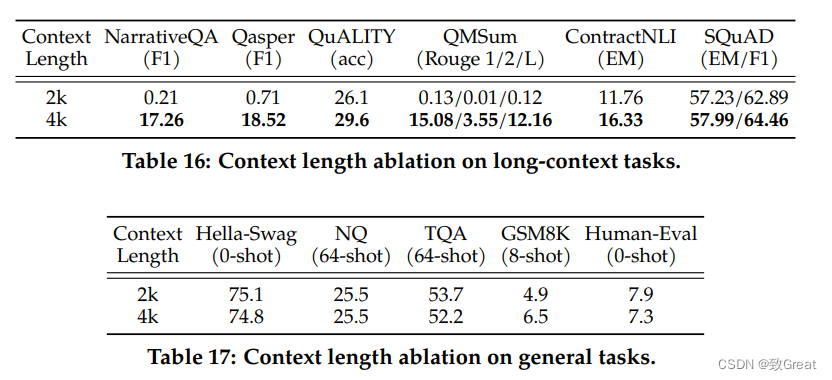
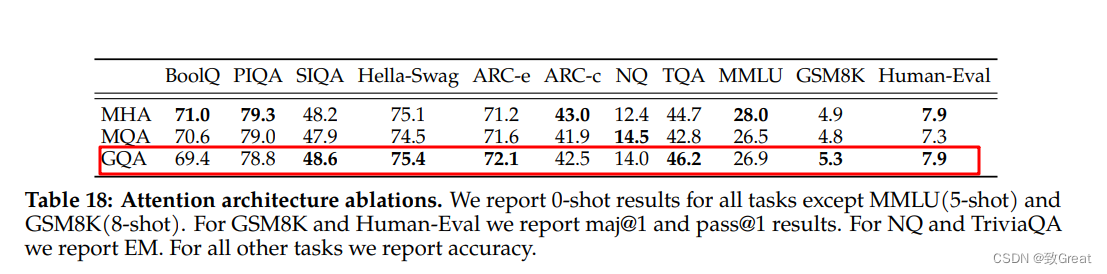
- Grouped-Query Attention 分组查询注意力:(1)自回归解码的标准做法是缓存序列中先前标记的键 (K) 和值 (V) 对,从而加快注意力计算速度。 然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA) 模型中与 KV 缓存大小相关的内存成本显着增长。 对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,而不会大幅降低性能。 可以使用具有单个 KV 投影的原始多查询格式(MQA)或具有 8 KV 投影的分组查询注意力变体(GQA)。(2)论文将 MQA 和 GQA 变体与 MHA 基线进行了比较,使用 150B 字符训练所有模型,同时保持固定的 30B 模型大小。 为了在 GQA 和 MQA 中保持相似的总体参数计数,增加前馈层的维度以补偿注意力层的减少。 对于 MQA 变体,我们将 FFN 维度增加 1.33 倍,对于 GQA 变体,Llama将其增加 1.3 倍。 从结果中观察到 GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均优于 MQA 变体。
超参数
- 使用 AdamW 优化器进行训练,其中 β1 =0.9,β2 = 0.95,eps = 10−5。
- 使用余弦学习率计划,预热 2000 步,衰减最终学习率降至峰值学习率的 10%。
- 使用 0.1 的权重衰减和1.0的梯度裁剪。
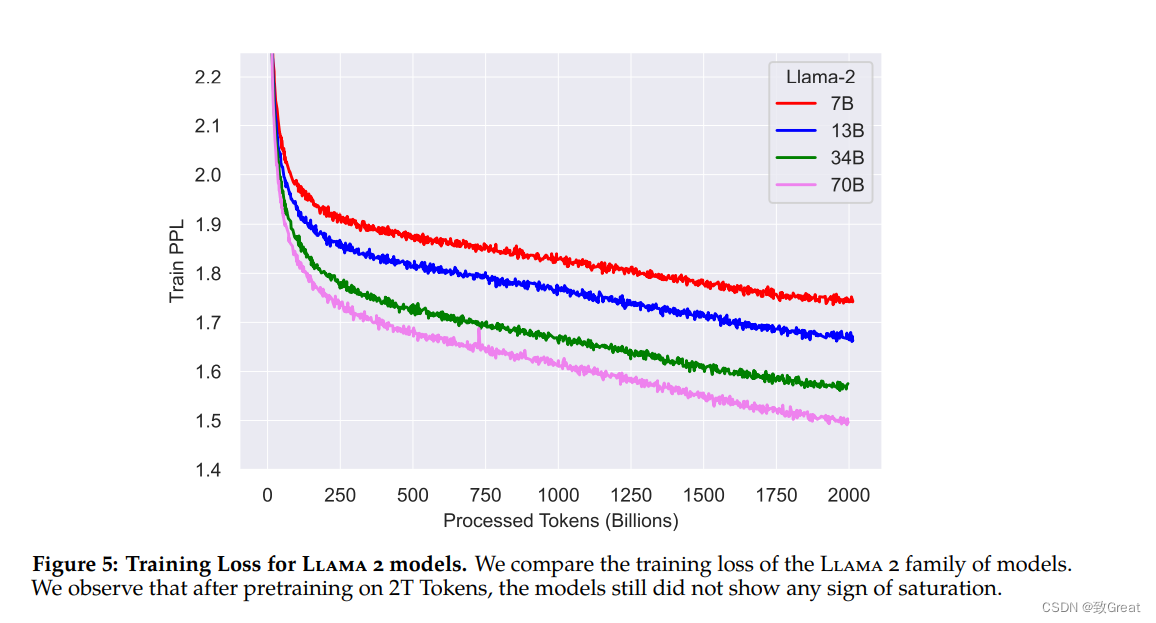
下图显示了使用这些超参数的 Llama 2 的训练损失。
分词器
Llama 2使用与 Llama 1 相同的分词器; 它采用字节对编码(BPE)算法,使用 SentencePiece 实现。 与Llama 1 一样,将所有数字拆分为单独的数字,并使用字节来分解未知的 UTF-8 字符。 总数
词汇量为 32k 个token
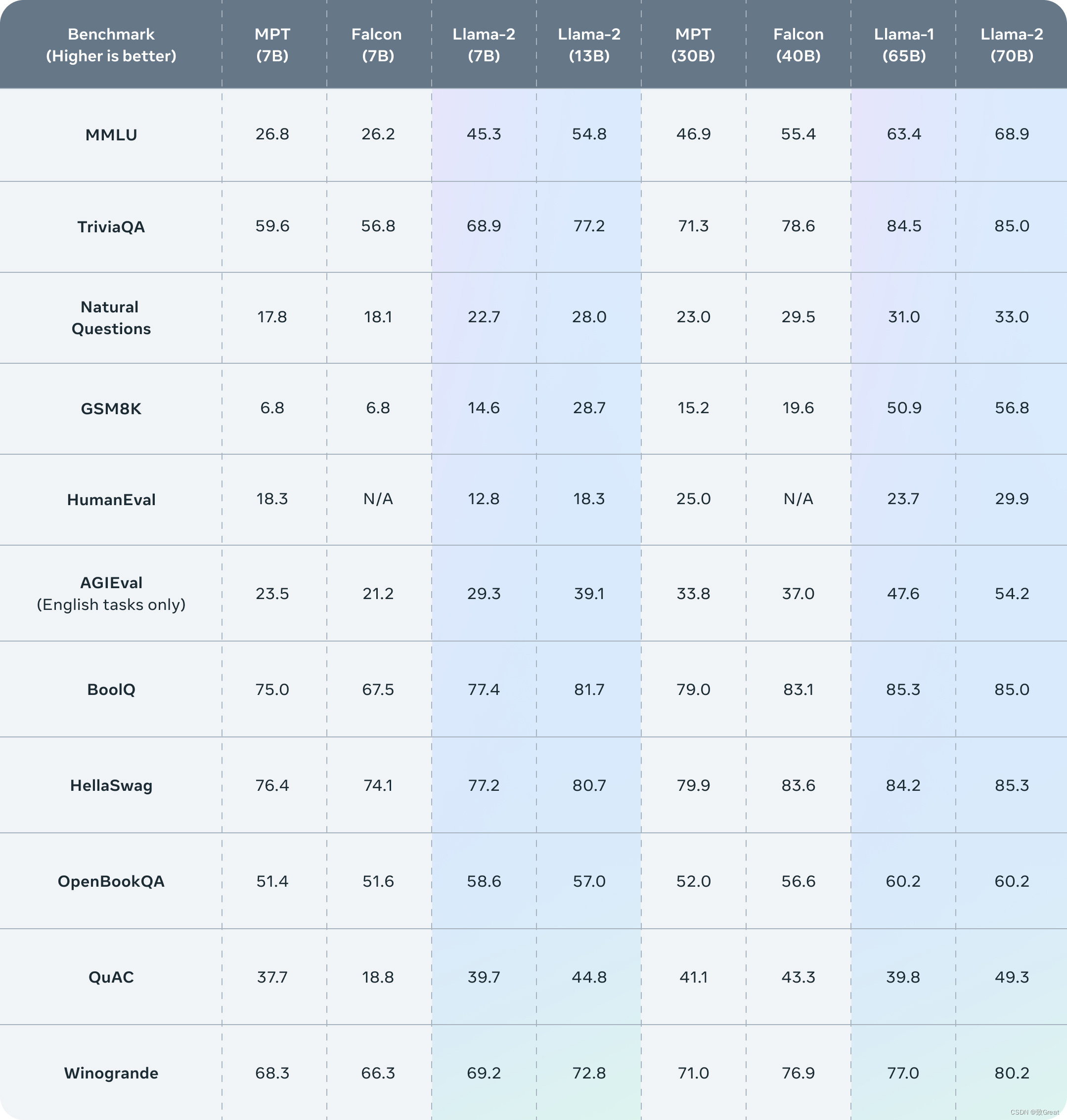
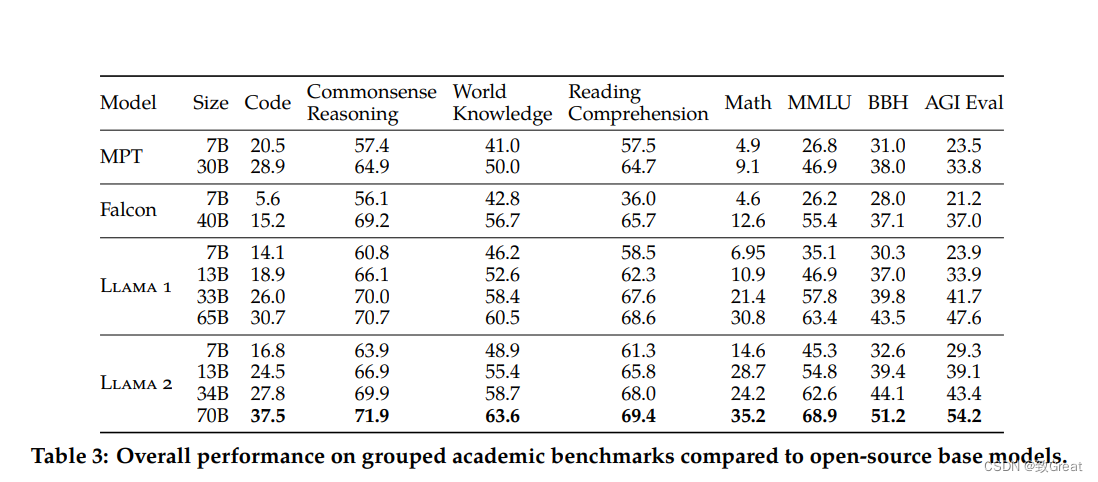
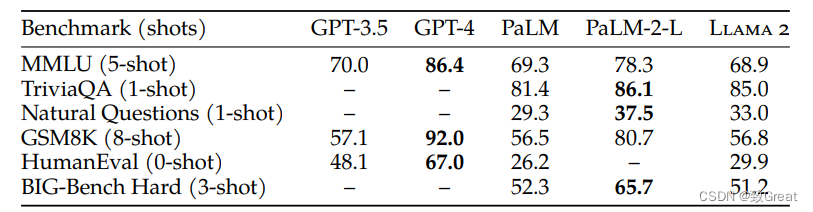
Llama 2评估结果
Llama 2 在许多外部基准测试中都优于其他开源语言模型,包括推理、编码、熟练程度和知识测试。
微调
Llama 2-Chat 是数月实验研究和对齐技术迭代应用的结果,包括指令微调和 RLHF,需要大量的计算和数据标注资源。
有监督微调

- 指令数据质量非常重要,包括多样性,注重隐私安全不包含任何元用户数据,还观察到,不同的注释平台和供应商可能会导致下游模型性能明显不同,这凸显了数据检查的重要性
- 微调细节:(1)对于监督微调,使用余弦学习率规划器,初始学习率为 2 × 10−5,权重衰减为 0.1,批量大小为 64,序列长度为 4096 个标记。(2)对于微调过程,每个样本都包含提示和答案, 为了确保正确填充模型序列长度,连接训练集中的所有提示和答案。 使用特殊标记来分隔提示和答案部分。(3) 利用自回归目标,将用户提示中的token损失归零,仅对答案token进行反向传播。 最后对模型进行了 2 个 epoch 的微调。
- 引入Ghost Attention (GAtt)有助于控制多个回合的对话效果
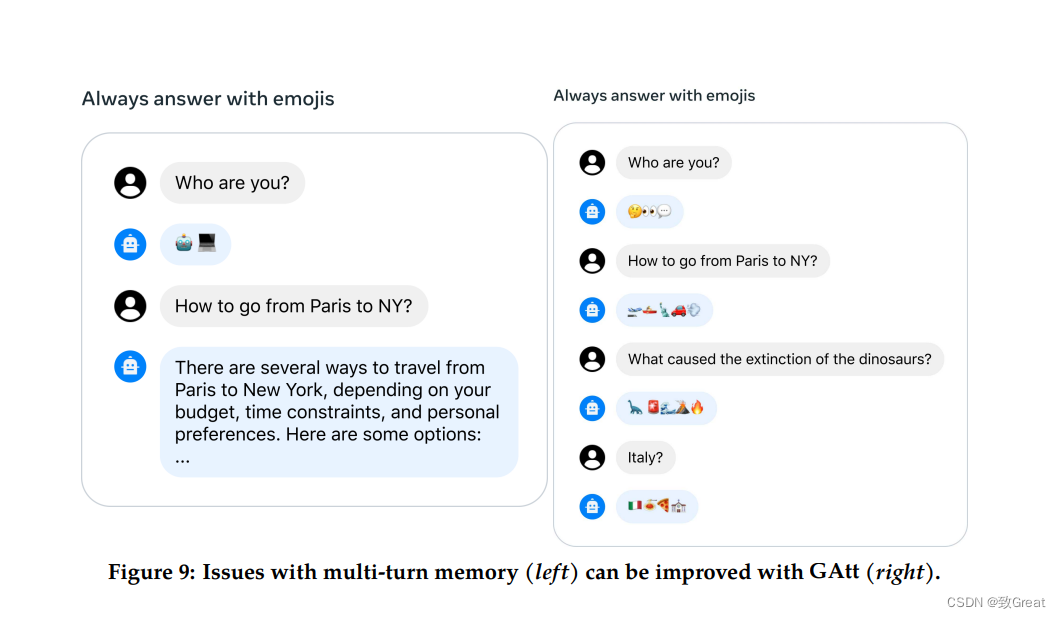
假设我们可以访问两个人(例如,用户和助手)之间的多轮对话数据集,其中包含消息列表 [u1, a1, . 。 。 , un, an],其中 un 和 an 分别对应于第 n 轮的用户消息和助理消息。 然后,我们定义一条指令,inst,在整个对话过程中都应遵守该指令。 例如,inst 可以是“充当”。 然后我们可以将该指令综合连接到对话的所有用户消息。接下来,可以使用最新的 RLHF 模型从这些合成数据中进行采样。 我们现在有了一个上下文对话和样本,可以用来微调模型,其过程类似于拒绝采样。 可以在除第一轮之外的所有轮次中删除它,而不是用指令来增加所有上下文对话轮次,但这会导致系统消息之间的训练时间不匹配,即最后一个轮次之前出现的所有中间辅助消息 轮到我们的样品了。 为了解决这个可能会损害训练的问题,我们只需将前一轮的所有标记的损失设置为 0,包括辅助消息。
此外论文还有大篇幅介绍RLHF,我们后续再讲
关于中文
预训练数据中的语言分布,百分比 >= 0.005%。 大多数数据都是英文的,这意味着 Llama 2 在英语用例中表现最佳。 大的未知类别是部分由编程代码数据组成。
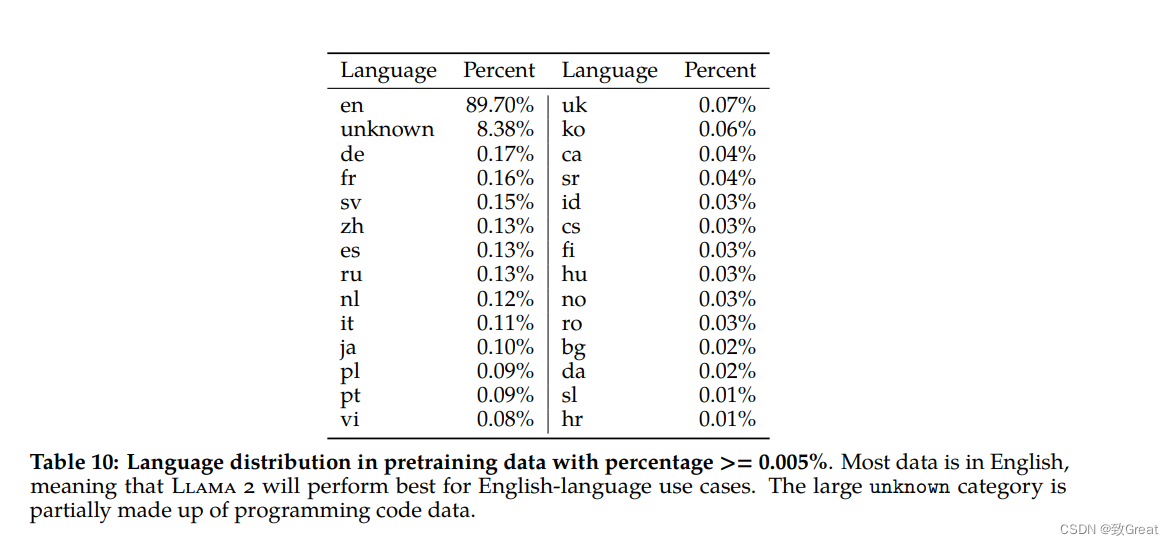
另外词表也是Llama 1同样大小(32k),所以基于Llama2还需要做中文增强训练。