目录
- 前言
- 最新ChatGPT GPT-4 文本推理技术详解
- 1. 什么是推理(Reasoning)?
- 2. 导入ChatGPT
- 3. 测试ChatGPT的推理能力
- 3.1 演绎推理(Deductive Reasoning)
- 3.2 归纳推理(Inductive Reasoning)
- 3.3 溯因推理(Abductive reasoning)
- 3.4 三者之间的关系
- 4. 调用ChatPT的推理能力
- 4.1 LLM推理求鼓励,请告诉ChatGPT去思考——Let's think step by step(Zero-shot-COT)
- 示例
- 课后问题,这是一个数学题**
- 4.2 给几个例子,告诉ChatGPT应该这么思考——Chain of Thought Prompting
- 4.3 任务太难,拆分一下,找个简单的去突破——Least to Most prompting
- 示例:字符连接
- 4.4 并非所有问题都需要拆解,不如先问问LLM(比如:ChatGPT)的意见——Self-Ask
- 4.5 集思广益——Self Consistency
- 方案1(显式)
- 方案2(隐式)
- 5. ChatGPT以及GPT-4的推理能力
- 6. 本章总结
- 相关文献
- 参考资料
- 其它资料下载

前言
自然语言处理(NLP)在当今人工智能领域中有越来越广泛的应用,其中一个重要的分支是文本推理。文本推理可以帮助计算机理解人类的语言逻辑并进行相关决策。然而,由于语言的多义性和模棱两可性,传统的文本推理技术往往无法满足高效准确地处理文本信息的需求。
为了解决这个问题,在ChatGPT技术的支持下,本文旨在探究如何使用文本推理技术来增强现有NLP系统的性能,提高对话系统的质量和准确度。
最新ChatGPT GPT-4 文本推理技术详解
本文不涉及太多的代码,更多是论文的解读和方法的介绍,里面的方法都是通用的,但这里主要使用ChatGPT来作为演示。
1. 什么是推理(Reasoning)?
在做出选择或处理问题时,推理是通过使用基于新的或现有信息的逻辑来理性地评价事物的能力。推理使你在决定最佳方案或最能满足你的目标的方案之前,能够平衡两个或多个方案的优点和缺点。它还能帮助你解决困难、处理不确定性、核实索赔,并仔细评估情况,以确保你做出的决定符合你的最佳利益[1]。比如:最近你打算买一台电脑? 决定之前,首先你会考虑你的预算,查看你预算范围的产品;其次如果你追求颜值,接下来你会考虑电脑的外观,如果你追求性价比,你会更关注电脑的硬件,比如CPU、GPU、内存等;此外还有你的需求(学习or工作),时间紧迫性等等,综合考虑多个因素,最终得出一个最合适的方案。这是人类的一项宝贵的技能,在人类的生活中拥有广泛的应用。

本图来源于What are the 4 primary types of reasoning? from Fibonicci.
常见的推理类型主要包含3种,即亚里士多德在公元前的《前分析篇》中列举了推理的三种类型,为演绎、归纳以及溯回。后来,皮尔斯在此基础上提出了“溯因推理”:
- 演绎推理(Deductive Reasoning)[2]
一般来说,演绎推理是指使用一组给定的事实或数据,通过逻辑推理来推导出其他事实。演绎推理,也称为三段论,通常的理解包括两个前提,一个大的和一个小的,然后一个逻辑结论,可以用来证明这些新的事实是真实的。
例如,经典的例子:
大前提:人类都是凡人
小前提:苏格拉底是人
结论:苏格拉底是凡人
在 “苏格拉底是人”(小前提)的具体情况下,对 “所有的人都是凡人”(大前提)的一般规则应用演绎法,可以得出结论:“苏格拉底是凡人”。
- 归纳推理(Inductive Reasoning)[2]
归纳推理是寻找一种模式或趋势,然后对其进行概括。当你对信息进行归纳和推断时,你并不确定这一趋势是否会继续下去,但你假设它会继续下去。因此,你并不确定基于归纳推理的结论会是100%的真实。
一个著名的假说是: “天鹅都是白的”
这个结论是在没有观察到任何黑天鹅的情况下从大量的观察中得出的,因此在逻辑上假设黑天鹅不存在。所以,归纳推理是一种有风险的逻辑推理形式,因为从天鹅的例子来看,如果发现了一只黑天鹅,那么结论就很容易不正确了。
在实际能力测试中,另一个常见的归纳推理的例子是数字序列。试着确定模式,归纳和推断,找到该序列的下一个数字。
“6, 9, 12, 15, ?”
这个趋势的逻辑答案似乎是18,但你不可能100%确定,也许这个数字代表的是天或小时或一些你意想不到的怪事,这可能导致推断出的结果不同。
- 溯因推理(Abductive reasoning)[2]
溯因推理与归纳推理有些类似。它最早是由“猜测”一词引入的,因为这里得出的结论是基于概率的。在归纳推理中,人们假定最合理的结论也是正确的。
例如:
大前提:罐子里装满了黄色的弹珠
小前提:鲍勃手里有一颗黄色的弹珠
结论:鲍勃手中的黄色弹珠是从罐子里拿出来的。
通过溯因推理,鲍勃从罐子里拿走黄色弹珠的可能性是合理的,然而这纯粹是基于推测。黄色弹珠可能是任何人送给鲍勃的,也可能是鲍勃在商店里买的黄色弹珠。因此,从“装满黄色大理石的罐子”的观察中推断出鲍勃拿走了黄色大理石,可能会导致一个错误的结论。
本图来源于:What part of the brain is used in reasoning? from How The Brain Learns
从上述推理来看,人脑的大脑皮层对许多认知和感觉功能都至关重要,人类推理的过程和大脑皮层的活动密切相关。
近年来,大型语言模型(Large Language Model,LLM)发展迅速,100B甚至更大参数规模的语言模型出现,它们已经在情感分析和机器翻译等任务上取得了十分优异的表现。特别的,去年12月ChatGPT横空出世,凭借其强大的能力和普遍的适用性直接破圈,引起了各行各业的人群关注。ChatGPT是生成式预训练 Transformer(GPT)语言系列模型中的一个成员。OpenAI在GPT-3改进版“GPT-3.5”上进行微调得到的。ChatGPT拥有非常强大的能力,甚至有研究者发现ChatGPT能够以9岁儿童的能力通过思维理论测试。那么,ChatGPT有多强大呢?它在推理这类任务上有着怎样的表现呢?有没有方法能进一步激发或是增强其处理复杂任务的能力?ChatGPT这种生成模型是否具有大脑的功效呢?不同功能区是如何划分呢?
下面我将简单地使用ChatGPT回答一个问题(第2节),然后简单测试一下ChatGPT面对三个常见的推理任务的表现(第3节),利用ChatGPT的推理能力更好地完成现有任务(第4节),ChatGPT、GPT4的推理能力的小结(第5节)。
2. 导入ChatGPT
# import the OpenAI Python library for calling the OpenAI API
import openai
# openai.api_key = "填入专属的API key"
Chatgpt一个对话的API调用包含两个必要的输入:
- model: 使用的模型名称(例如:gpt-3.5-turbo, gpt-4, gpt-4-0314)。本文写作之初,OpenAI并未公布gpt-4, gpt-4-0314,为测试方便,结果均为gpt-3.5-turbo(也就是我们最常用的ChatGPT的版本)的输出。
- message: 一个消息对象的列表,每个对象有两个必要的字段:
- role: 信使的角色,包括:system、user,or assistant)
- content: 信息的内容,例如: 给我写一首美丽的诗
其中,消息也可以包含一个可选的名称字段,它给信使一个名字。例如:example-user、Alice、BlackbeardBot。名称中不得包含空格。
通常情况下,对话会以一个告诉助手如何行事的系统消息开始,然后是用户和助手的消息交替出现, 但可以不遵循这种格式。
# Example OpenAI Python library request
MODEL = "gpt-3.5-turbo"response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Knock knock."},{"role": "assistant", "content": "Who's there?"},{"role": "user", "content": "Orange."},],temperature=0,
)response
<OpenAIObject chat.completion id=chatcmpl-749WgDEJrldSgYkoyTLsPak41vt19 at 0x28d93ce3ea0> JSON: {"choices": [{"finish_reason": "stop","index": 0,"message": {"content": "Orange who?","role": "assistant"}}],"created": 1681224286,"id": "chatcmpl-749WgDEJrldSgYkoyTLsPak41vt19","model": "gpt-3.5-turbo-0301","object": "chat.completion","usage": {"completion_tokens": 3,"prompt_tokens": 39,"total_tokens": 42}
}
测试一下是否成功了,如果返回了下面的类似的结果,恭喜你成功了。
<OpenAIObject chat.completion id=chatcmpl-72sVLx6higzowFC3TjE5zLBU8k7TY at 0x2120f316400> JSON: {"choices": [{"finish_reason": "stop","index": 0,"message": {"content": "Orange who?","role": "assistant"}}],"created": 1680920527,"id": "chatcmpl-72sVLx6higzowFC3TjE5zLBU8k7TY","model": "gpt-3.5-turbo-0301","object": "chat.completion","usage": {"completion_tokens": 3,"prompt_tokens": 39,"total_tokens": 42}
}
响应对象包括下面几个字段:
- id: 请求的ID
- object: 返回的对象的类型(如chat.completion)
- created: 请求的时间戳
- model: 用于生成回复的模型的全名
- usage: 用于生成回复的token数量,包括提示、完成和总数。
- choices: 完成对象的列表(只有一个,除非你设置n大于1)
- message: 由模型生成的消息对象,包括角色和内容
- finish_reason: :模型停止生成文本的原因(要么是停止,要么是长度,如果达到max_tokens的限制)
- index: 选择列表中的完成度的索引
若只需要答复,可以使用如下代码:
response['choices'][0]['message']['content']
问ChatGPT一个关于DataWhaled的问题,看看回答怎么样~
# example without a system message
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你知道DataWhale吗?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
作为AI语言模型,我知道DataWhale是一个开源的数据科学社区,致力于推广数据科学和人工智能知识,为数据科学爱好者提供学习和交流的平台。DataWhale的成员来自于各大高校和知名企业,包括华为、腾讯、百度等。他们通过组织线上线下的学习活动、分享课程和资源等方式,帮助更多人学习和掌握数据科学和人工智能技术。
可以看到,ChatGPT真的很厉害的,把DataWhale的属性、目标、成员组成、工作都做到了非常好的回答👍!
好了,预备工作结束了,下面讲解正式开始。
3. 测试ChatGPT的推理能力
这一章节,针对常见的推理任务,对ChatGPT进行测试,看看ChatGPT的表现是什么样子的。
3.1 演绎推理(Deductive Reasoning)
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "大前提:人类都是凡人 \n \小前提:苏格拉底是人 \n \结论:"},],temperature=0,
)print(response['choices'][0]['message']['content'])
苏格拉底是凡人。
3.2 归纳推理(Inductive Reasoning)
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "西瓜是甜的,香瓜是甜的,所以叫“瓜”的蔬果都应该 \n \结论:"},],temperature=0,
)print(response['choices'][0]['message']['content'])
都是甜的。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "6, 9, 12, 15, ? \n \结论:"},],temperature=0,
)print(response['choices'][0]['message']['content'])
18
3.3 溯因推理(Abductive reasoning)
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "大前提:罐子里装满了黄色的弹珠 \n \小前提:鲍勃手里有一颗黄色的弹珠 \n \问题:鲍勃手里的弹珠来自哪里?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
无法确定,因为罐子里装满了黄色的弹珠,鲍勃手里的黄色弹珠可能来自罐子里,也可能来自其他地方。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "如果电源线路接触不好,那么日光灯熄灭;日光灯熄灭,\n \所以: "},],temperature=0,
)print(response['choices'][0]['message']['content'])
电源线路可能接触不好。
3.4 三者之间的关系
下面,我们来看看皮尔斯如何使用“豆子实例”来阐述三者的关系。
- 演绎推理
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "这个袋子中的豆子都是白色的。\n \这些豆子来自这个袋子。\n \这些豆子是"},],temperature=0,
)print(response['choices'][0]['message']['content'])
白色的。
- 归纳推理
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "这些豆子来自这个袋子。\n \这些豆子是白色的。\n \这个袋子中的豆子都是"},],temperature=0,
)print(response['choices'][0]['message']['content'])
白色的。
- 溯因推理
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "这个袋子中的豆子都是白色的。\n \这些豆子是白色的。\n \这些豆子来自哪里?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
抱歉,我无法回答这个问题,因为上下文中没有提到豆子的来源。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "这个袋子中的豆子都是白色的。\n \这些豆子是白色的。\n \这些豆子来自哪里? 请进行溯因推理"},],temperature=0,
)print(response['choices'][0]['message']['content'])
无法进行溯因推理,因为题目中没有提供足够的信息。
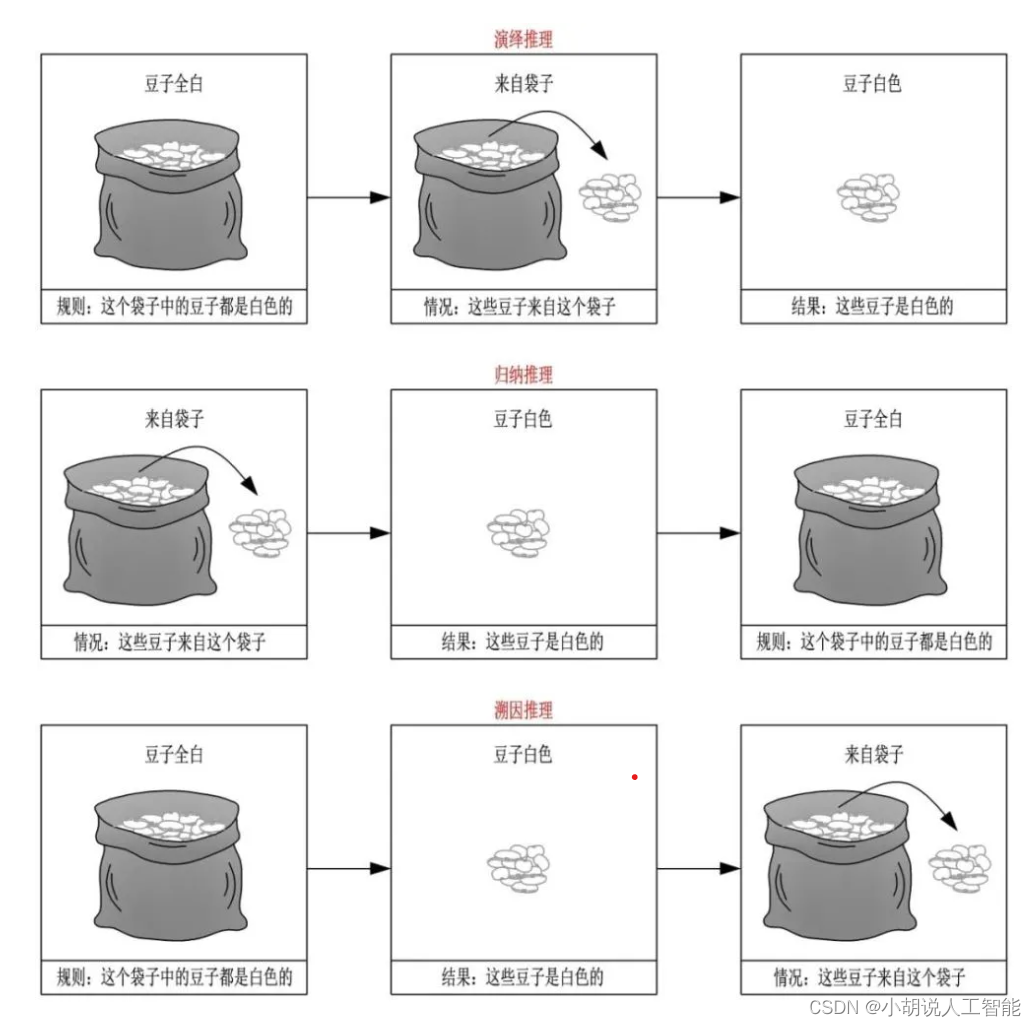
本图来源于演绎、归纳和溯因之间的关系
本节简单讨论了ChatGPT对于不同类型的推理问题的表现,上面的例子我们可以感觉到,ChatGPT可以对演绎、归纳类型的问题有很好的感知,而在溯因推理这块似乎很符合一个正常人的思维。最近LLM发展迅速,但笔者认为未来(愚见),LLM需要进一步发展甚至是AGI的突破,都需要提升AI在推理相关的能力,皮尔斯曾指出:“只要是关于科学的观念,就都利用外展(溯因)得而得出的,而且这些观念都可以利用演绎来进行验证”。哪一天,AI拥有了真正完整的推理能力,那才是我们真正想象中的AI。
4. 调用ChatPT的推理能力
人脑的系统在熟悉情境中采取的模式是精确的,所作出的短期预测是准确的,遇到挑战时做出的第一反应也是迅速且基本恰当的。然而,系统存在成见,在很多特定的情况下,这一系统易犯系统性错误。你会发现这个系统有时候会将原本较难的问题作简单化处理,对于逻辑学和统计学问题,它几乎一无所知。 ——《思考,快与慢》
人们在生活中,面对简单的问题,很多时候仅仅凭直觉可以应对,比如 1 + 1 = 2 1 + 1 = 2 1+1=2,但当你面对一个很复杂的事情时,过于棘手甚至会让你转不过弯来,这个时候你就得静一下来,仔细思考一下,如何解决。比如 48 × 2023 = ? 48 \times 2023 = \text{?} 48×2023=?,这个时候你可能就没办法直接做出回答了,你需要心算一下甚至拿出笔,在草稿纸上写下 48 × 2023 = 40 × 2023 + 8 × 2023 = 80920 + 16184 = 97104 48 \times 2023 = 40 \times 2023 + 8 \times 2023 = 80920 + 16184 = 97104 48×2023=40×2023+8×2023=80920+16184=97104。
同样,如果我们让ChatGPT回答一个的问题,简单一点的ChatGPT紧凭“直觉”(这里的直觉可以理解就是“一下子”得到)就可以回答,但当遇到一些较为复杂的问题时,ChatGPT一下子就无法很好的胜任了,可能需要一下子+一下子,两下子才可以,甚至需要多下子才能完成。总结下来就是:面对复杂问题,人需要思考,ChatGPT也不例外,它也需要思考。如何让ChatGPT使用"多下子"的能力呢?
可以从以下几个方面入手:
- 问题结束,加上让它思考的魔法语句,比如:“Let’s think step by step.” , 让ChatGPT思考起来
- 给一个或者几个例子,让ChatGPT类比学习一下
- 让ChatGPT使用多种思路回答,最后综合一下,优中选优
如果大家对这块感兴趣的话,可以阅读关于思维链(Chain of Thought,COT)相关的paper,这块工作非常有意思的。
4.1 LLM推理求鼓励,请告诉ChatGPT去思考——Let’s think step by step(Zero-shot-COT)
零样本思维链(Zero-shot-CoT)的提示,来自论文 Takeshi Kojima et al. in 2022,以一种极其简单的方式,即在答案前加上 “Let’s think step by step”,促使模型进行思考,进而推理出正确的答案。

本图来源于Source: Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
一个完整的Zero-shot-CoT过程涉及两个独立步骤:第一步,进行推理;第二步,提取答案。首先使用第一个“推理”提示,从语言模型中提取完整的推理路径,然后使用第二个“答案”提示,从推理文本中提取正确格式的答案。
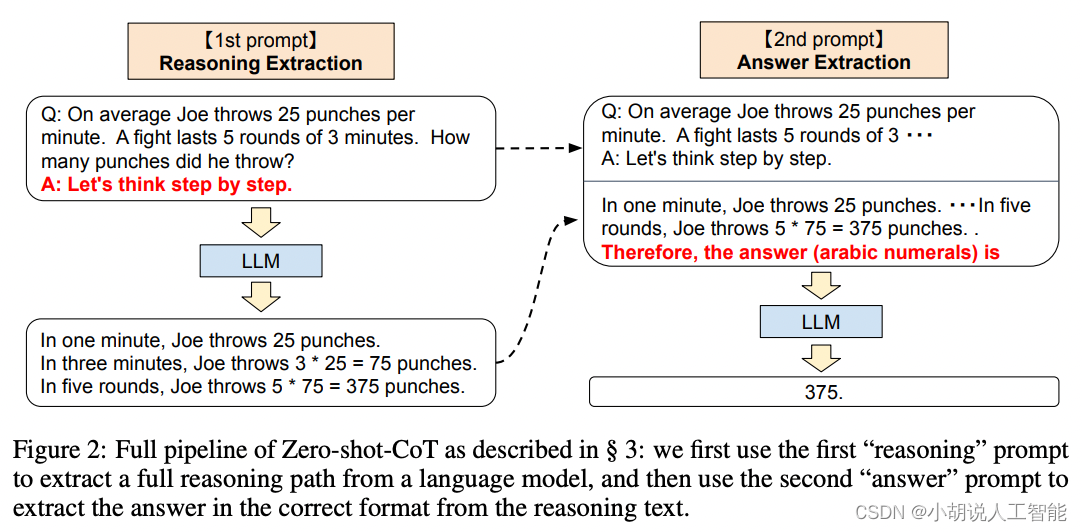
本图来源于Source: Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
示例
问题:
用一只水桶装水,把水加到原来的2倍,连桶重10千克,如果把水加到原来的5倍,连桶重22千克。桶里原有水多少千克?
答案:
(22-10)÷(5-2)=12÷3=4(千克)
直接提问ChatGPT:
# example without a system message
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "用一只水桶装水, 把水加到原来的2倍, 连桶重10千克, 如果把水加到原来的5倍, 连桶重22千克。桶里原有水多少千克?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
设原来水的重量为x千克,则加水后水的重量为2x千克,加水前桶的重量为y千克,则有:2x + y = y + 10 (加水到原来的2倍,连桶重10千克)5x + y = y + 22 (加水到原来的5倍,连桶重22千克)化简得:x = 6因此,桶里原有水6千克。
对照答案,可以看到ChatGPT对这个问题回答错了。让我们告知ChatGPT进行推理思考,调用这部分能力试试。
使用Zero-shot COT推理:
第1步,获取完整推理步骤:
# example without a system message
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "用一只水桶装水, 把水加到原来的2倍, 连桶重10千克, 如果把水加到原来的5倍, 连桶重22千克。桶里原有水多少千克? Let's think step by step."},],temperature=0,
)print(response['choices'][0]['message']['content'])
设原来桶里的水重x千克,桶本身重y千克,则有:第一步:加到原来的2倍桶里的水变成2x千克,桶本身重y+10千克。第二步:加到原来的5倍桶里的水变成5x千克,桶本身重y+22千克。根据以上两个式子,我们可以列出一个方程组:2x + y + 10 = 5x + y + 22化简得:3x = 12x = 4所以,原来桶里的水重4千克。
第2步:提取答案
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "用一只水桶装水, 把水加到原来的2倍, 连桶重10千克, 如果把水加到原来的5倍, 连桶重22千克。桶里原有水多少千克? Let's think step by step."},{"role": "assistant", "content": "设原来桶里的水重x千克,桶本身重y千克,则有: \n \第一步:加到原来的2倍 \n \桶里的水变成2x千克,桶本身重y+10千克。 \n \第二步:加到原来的5倍 \n \桶里的水变成5x千克,桶本身重y+22千克。 \n \根据以上两个式子,我们可以列出一个方程组: \n \2x + y + 10 = 5x + y + 22 \n \化简得: \n \3x = 12 \n \x = 4 \n \所以,原来桶里的水重4千克。"},{"role": "user", "content": "所以,答案是(阿拉伯数字):"},],temperature=0,
)print(response['choices'][0]['message']['content'])
4。
通过上面的例子大家,可以看到,加上"Let’s think step by step"的提示后,ChatGPT对这道数学题的解答更有逻辑性了,推理的步骤也更加清晰了。看着两个不一样的答案有没有那种感觉——开始的解答就是那种跳步的,第二种是规规矩矩按照老师教的逻辑,一步一步解答的,根据经验,一步一步解答正确率是比跳步要高的。
原论文中使用的GPT-3这个模型进行测试的,"Let’s think step by step"这个简单的技巧在MultiArith数学数据集上,可以使准确率翻了两番,从18%上升到79%!此外,如下表所示,诸如:First,(*)、Let’s think about this logically等提示都可以用提升LLM的推理能力,大家感兴趣可以试试构建自己的例子进行尝试。

本图来源于Source: Large Language Models are Zero-Shot Reasoners by Takeshi Kojima et al. (2022).
课后问题,这是一个数学题**
问题:
五年级一中队和二中队要到距学校20千米的地方去春游。第一中队步行每小时行4千米,第二中队骑自行车,每小时行12千米。第一中队先出发2小时后,第二中队再出发,第二中队出发后几小时才能追上一中队?
答案:
4×2÷(12-4)= 4×2÷8 = 1(时)
大家试试Zero-shot COT的方法吧
# example without a system message
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": ""},],temperature=0,
)print(response['choices'][0]['message']['content'])
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": " ,Let's think step by step."},],temperature=0,
)print(response['choices'][0]['message']['content'])
4.2 给几个例子,告诉ChatGPT应该这么思考——Chain of Thought Prompting
思维链(CoT)提示是一种最近开发的提示方法,旨在鼓励大语言模型解释其推理过程。下图显示了 few shot standard prompt(左)与 COT 过程(右)的比较。
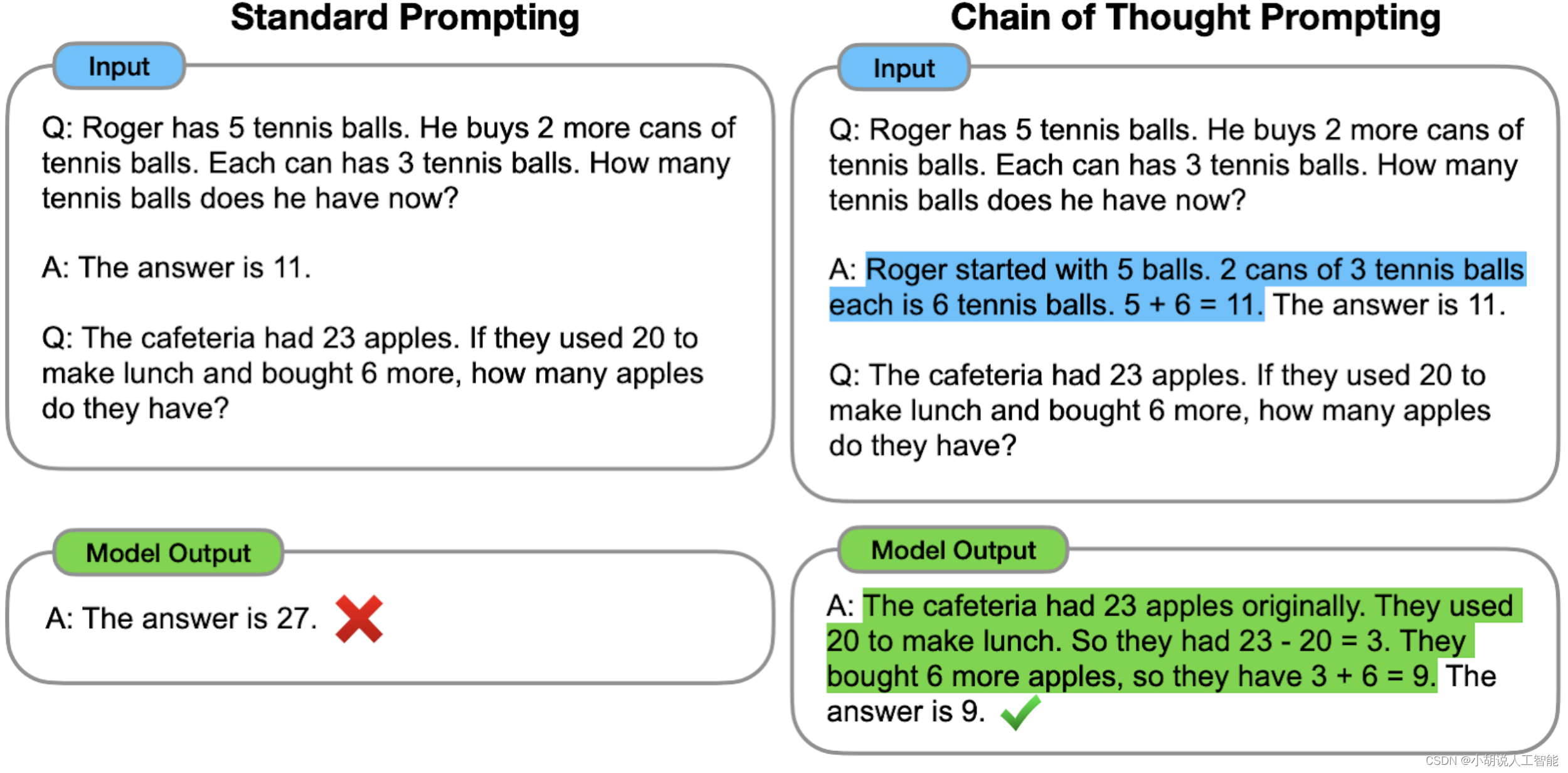
本图来源于Source: Chain of Thought Prompting Elicits Reasoning in Large Language Models Jason Wei and Denny Zhou et al. (2022)
CoT的主要思想是,通过向LLM展示一些少量的典范,在样例中解释推理过程,大语言模型在回答提示时也会跟着进行推理。
下面我们通过以下例子(本例来源于增强ChatGPT回答的逻辑性)来演示一下:
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "在这些数字3、56、35、96、40、10、84、923、32、20 中,有多少个奇数,多少个偶数?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
奇数有4个:3、35、96、923。
偶数有6个:56、40、10、84、32、20。
正确答案是:3个奇数,7个偶数。这里不知道为什么ChatGPT把96也当成是奇数了,可能觉得96和3相关,其他和三相关的都是奇数,所以把它也列为奇数了??
下面加上,Let’s think step by step,试试
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "在这些数字3、56、35、96、40、10、84、923、32、20 中,有多少个奇数,多少个偶数?Let's think step by step."},],temperature=0,
)print(response['choices'][0]['message']['content'])
首先,我们需要知道什么是奇数和偶数。奇数是指不能被2整除的整数,而偶数是指能被2整除的整数。接下来,我们可以逐个检查这些数字,看它们是否是奇数或偶数。 3是奇数,因为它不能被2整除。 56是偶数,因为它能被2整除,即56÷2=28。 35是奇数,因为它不能被2整除。 96是偶数,因为它能被2整除,即96÷2=48。 40是偶数,因为它能被2整除,即40÷2=20。 10是偶数,因为它能被2整除,即10÷2=5。 84是偶数,因为它能被2整除,即84÷2=42。 923是奇数,因为它不能被2整除。 32是偶数,因为它能被2整除,即32÷2=16。 20是偶数,因为它能被2整除,即20÷2=10。 因此,这些数字中有5个奇数和5个偶数。
很奇怪,虽然过程都列对了,但是不知为什么最后统计的时候,把这结果统计错了,ChatGPT也太粗心马虎,这准备数学老师敲脑壳。不过,放在正式考试中,相比直接问,步骤分至少得到了。
既然“Let’s think step by step.”失效了,难道ChatGPT真的就无法处理这种情况了吗?放心,不是的,我们换个手段,给ChatGPT例子学习一下, Make ChatGPT Great Again!
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "在这些数字 38、31、89、224种,有多少个奇数,多少个偶数?."},{"role": "assistant", "content": "我们一个一个数:\n \1. 38是偶数,此时累计:偶数1个,奇数0个; \n \2. 31是奇数,此时累计:偶数1个,奇数1个; \n \3. 89是奇数,此时累计:偶数1个,奇数2; \n \4. 224是偶数,此时累计:偶数2个,奇数2个; \n \所以,一共有2个偶数,2个奇数。"},{"role": "user", "content": "在这些数字3、56、35、96、40、10、84、923、32、20 中,有多少个奇数,多少个偶数?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
我们一个一个数:1. 3是奇数,此时累计:偶数0个,奇数1个; 2. 56是偶数,此时累计:偶数1个,奇数1个; 3. 35是奇数,此时累计:偶数1个,奇数2个; 4. 96是偶数,此时累计:偶数2个,奇数2个; 5. 40是偶数,此时累计:偶数3个,奇数2个; 6. 10是偶数,此时累计:偶数4个,奇数2个; 7. 84是偶数,此时累计:偶数5个,奇数2个; 8. 923是奇数,此时累计:偶数5个,奇数3个; 9. 32是偶数,此时累计:偶数6个,奇数3个; 10. 20是偶数,此时累计:偶数7个,奇数3个; 所以,一共有7个偶数,3个奇数。
思维链已被证明对于算术、常识和符号推理等任务的结果有所改进。特别是,在GSM8K基准测试上,PaLM 540B通过提示达到了57%的准确性。
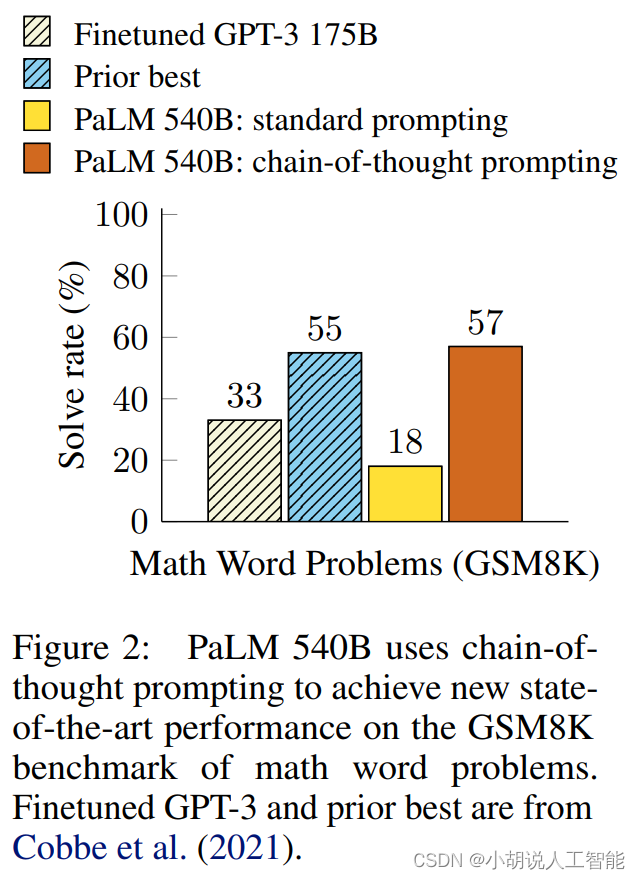
本图来源于Source: Chain of Thought Prompting Elicits Reasoning in Large Language Models Jason Wei and Denny Zhou et al. (2022)
4.3 任务太难,拆分一下,找个简单的去突破——Least to Most prompting
最少到最多提示过程 (Least to Most prompting, LtM) 是思维链提示过程(CoT prompting)的进一步发展。具体来说,首先将问题分解为子问题,然后逐个解决。这是受到针对儿童的现实教育策略的启发而发展出的一种技术。
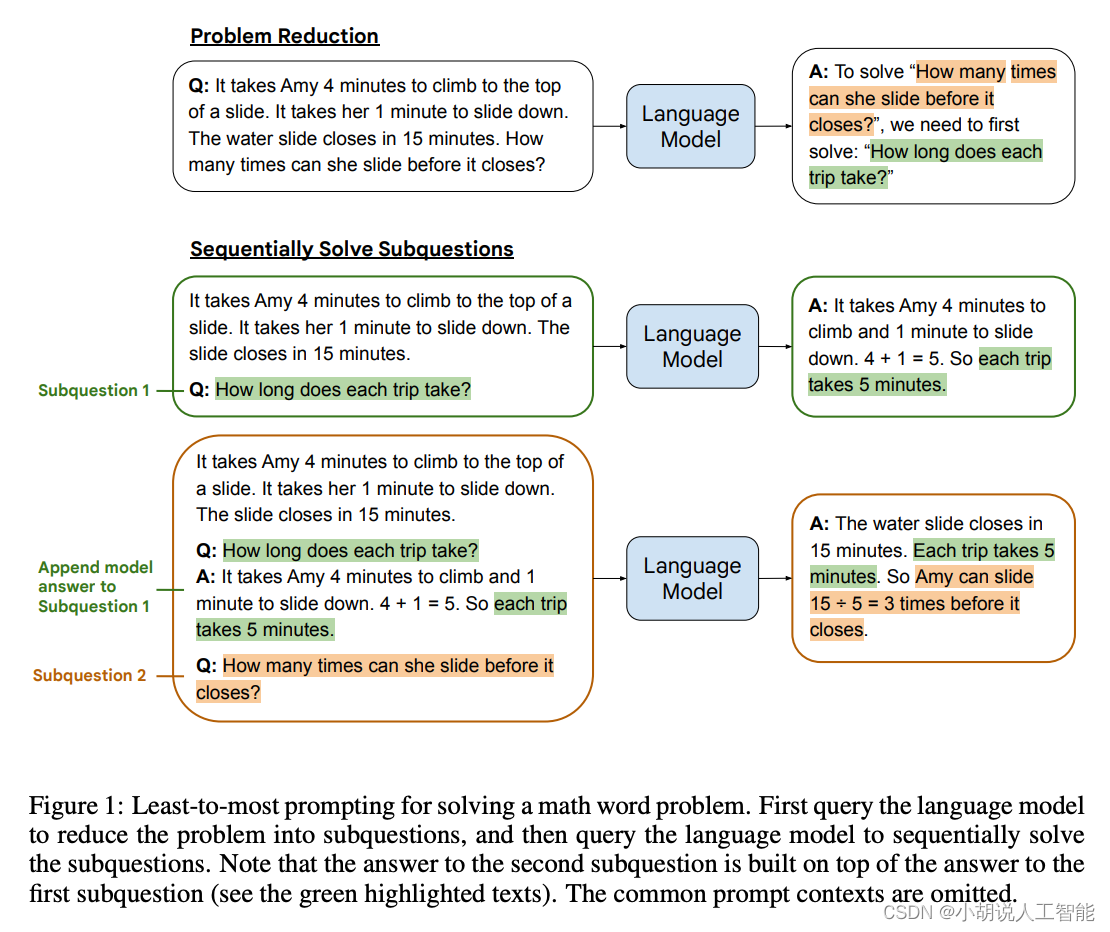
本图来源于Source: Least-to-most Prompting Enables Complex Reasoning in Large Language Models by Denny Zhou et al. (2022)
与思维链提示过程类似,需要解决的问题首先被分解成一组建立在彼此之上的子问题。在第二步中,这些子问题被逐个解决。与思维链不同的是,先前子问题的解决方案被输入到提示中,以尝试解决下一个问题。
示例:字符连接
我们尝试问一个稍微复杂的问题(本问题来源于Learn Prompting网站):
- 标准的few-shot prompt
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "Q: think, machine \n \A: ke \n \\n \Q: learning, reasoning, generalization \n \A: ggn \n \\n \Q: artificial, intelligence \n \A: le \n \\n \Q: foo,bar,baz,blip \n \A:"},],temperature=0,
)print(response['choices'][0]['message']['content'])
fbbb
即使是ChatGPT,few-shot 示例的表现也非常糟糕。
- COT思维链过程
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "Q: think, machine \n \A: The last letter of \"think\" is \"k\". The last letter of \"machine\" is \"e\". So \"think, machine\" is \"ke\". \n \\n \Q: learning, reasoning, generalization \n \A: The last letter of \"learning\" is \"g\". The last letter of \"reasoning\" is \"n\". The last letter of \"generalization\" is \"n\". So \"learning, reasoning, generalization\" is \"ggn\". \n \\n \Q: artificial, intelligence \n \A: The last letter of \"artificial\" is \"l\". The last letter of \"intelligence\" is \"e\". So \"artificial, intelligence\" is \"le\". \n \\n \Q: foo,bar,baz,blip \n \A:"},],temperature=0,
)print(response['choices'][0]['message']['content'])
The last letter of "foo" is "o". The last letter of "bar" is "r". The last letter of "baz" is "z". The last letter of "blip" is "p". So "foo,bar,baz,blip" is "orzp".
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "Q: think, machine \n \A: The last letter of \"think\" is \"k\". The last letter of \"machine\" is \"e\". So \"think, machine\" is \"ke\". \n \\n \Q: learning, reasoning, generalization \n \A: The last letter of \"learning\" is \"g\". The last letter of \"reasoning\" is \"n\". The last letter of \"generalization\" is \"n\". So \"learning, reasoning, generalization\" is \"ggn\". \n \\n \Q: artificial, intelligence \n \A: The last letter of \"artificial\" is \"l\". The last letter of \"intelligence\" is \"e\". So \"artificial, intelligence\" is \"le\". \n \\n \Q: foo,bar,baz,blip,learn,prompting,world,shaking,event,dancefloor,prisma,giraffe \n \A:"},],temperature=0,
)print(response['choices'][0]['message']['content'])
The last letter of "foo" is "o". The last letter of "bar" is "r". The last letter of "baz" is "z". The last letter of "blip" is "p". The last letter of "learn" is "n". The last letter of "prompting" is "g". The last letter of "world" is "d". The last letter of "shaking" is "g". The last letter of "event" is "t". The last letter of "dancefloor" is "r". The last letter of "prisma" is "a". The last letter of "giraffe" is "e". So "foo,bar,baz,blip,learn,prompting,world,shaking,event,dancefloor,prisma,giraffe" is "orzpngdgrae".
思维链的表现比标准提示好得多。这是因为它现在允许模型考虑自己提取每个单词的最后一个字母,将复杂性降低到分组已经收集的字母的行为。然而,这种方法在更长的输入下也可能慢慢出现问题。
“foo,bar,baz,blip” --> “orzp”
“foo,bar,baz,blip,learn,prompting,world,shaking,event,dancefloor,prisma,giraffe” --> “orzpngdgrae”
当输入为4个词时,Chain of Thought完全回答正确,当输入增加到12个词的时候,经过分析过程提到了event这个词的末尾字母为z,但结果却忘记输出了。
- LtM(单一提示)
关于使用LtM,我们通过重新表述先前串联的结果来增强思维链的概念。这种做法使得每个步骤变得简单,即每次只需要连接一个字符。这种方法带来了非常好的效果,12个乃至更多的词都能得到正确结果。
这种方法看起来与思维链非常相似,但在概念上大有不同。在这里,每一步都引入了上一步连接的结果。例如,在“think, machine, learning”的这个例子中,它不会单独连接字符“k”,“e”,“l”,而是先连接“k”和“e”,然后连接“ke”和“l”。由于重新引入了上一步的结果,模型现在可以推广到更长的链,因为它每一步都带着增量结果,同时单步骤内只需要做很少的工作。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "Q: think, machine \n \A: The last letter of \"think\" is \"k\". The last letter of \"machine\" is \"e\". Concatenating \"k\" and \"e\" gives \"ke\". So \"think, machine\" output \"ke\". \n \\n \Q: think, machine, learning \n \A: \"think, machine\" outputs \"ke\". The last letter of \"learning\" is \"g\". Concatenating \"ke\" and \"g\" gives \"keg\". So \"think, machine, learning\" is \"keg\". \n \\n \Q: transformer, language \n \A: The last letter of \"transformer\" is \"r\". The last letter of \"language\" is \"e\". Concatenating \"r\" and \"e\" gives \"re\". So \"transformer, language\" is \"re\". \n \\n \Q: transformer, language, vision \n \A: \"transformer, language\" outputs \"re\". The last letter of \"vision\" is \"n\". Concatenating \"re\" and \"n\" gives \"ren\". So \"transformer, language, vision\" is \"ren\". \n \\n \Q: foo,bar,baz,blip,learn,prompting,world,shaking,event,dancefloor,prisma,giraffe \n \A:"},],temperature=0,
)print(response['choices'][0]['message']['content'])
The last letter of "foo" is "o". The last letter of "bar" is "r". The last letter of "baz" is "z". The last letter of "blip" is "p". The last letter of "learn" is "n". The last letter of "prompting" is "g". The last letter of "world" is "d". The last letter of "shaking" is "g". The last letter of "event" is "t". The last letter of "dancefloor" is "r". The last letter of "prisma" is "a". The last letter of "giraffe" is "e". Concatenating all these letters gives "orzpngdgtrea". So "foo,bar,baz,blip,learn,prompting,world,shaking,event,dancefloor,prisma,giraffe" is "orzpngdgtrea".
COT : “foo,bar,baz,blip,learn,prompting,world,shaking,event,dancefloor,prisma,giraffe” --> “orzpngdgrae”
LtM : “foo,bar,baz,blip,learn,prompting,world,shaking,event,dancefloor,prisma,giraffe” --> “orzpngdgtrea”
根据上述的结果,可以看到,由于COT的方法中,得到的结果漏掉了"t",所以正确率只有KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …12 = 75\text{%}。相比之下,LtM方法完全答对了。
综上所述,LtM 带来了多项提升:
- 相对于思维链提高了准确性
- 在难度高于提示的问题上提升了泛化能力
- 在组合泛化方面的性能得到了显著提高,特别是在SCAN基准测试中
使用 text-davinci-002(论文中使用的模型)的标准提示解决了 6% 的 SCAN 问题,而 LtM 提示则取得了惊人的 76% 的成功率。在 code-davinci-002 中,结果更为显著,LtM 达到了 99.7% 的成功率。
此外,在ChatGPT中,还可以通过角色扮演、指令提示等方法让ChatGPT进行隐式的LtM过程。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你现在是 MultistageGPT:你与 ChatGPT 一样,但对于每一个问题,\n \你会将问题分解为子问题,然后将它们结合起来,输出最佳的措辞、最全面和最准确的答案。输出应该看起来像这样:\n \ChatGPT:{ChatGPT 通常会说什么}; MultistageGPT:{更好、更全面的答案} 让我们从简单的问题开始:5*10 - 3*10 = ?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
ChatGPT:50 - 30 = 20;
MultistageGPT:我们可以将这个问题分解为两个子问题:5*10 和 3*10。5*10 等于 50,3*10 等于 30。因此,5*10 - 3*10 等于 20。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你现在是 MultistageGPT:你与 ChatGPT 一样,但对于每一个问题,\n \你会将问题分解为子问题,然后将它们结合起来,输出最佳的措辞、最全面和最准确的答案。输出应该看起来像这样:\n \ChatGPT:{ChatGPT 通常会说什么};MultistageGPT:{更好、更全面的答案} 让我们从简单的问题开始:[32, 21,90]中最大的数,与[19,233, 90]中最小的数,相差多少?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
ChatGPT:最大的数是90,最小的数是19,它们的差是71。MultistageGPT:为了找到这个答案,我们需要先找到[32, 21, 90]中的最大数和[19, 233, 90]中的最小数。在第一个列表中,最大的数是90,在第二个列表中,最小的数是19。它们的差是90-19=71。因此,这两个列表中最大的数和最小的数之间相差71。
4.4 并非所有问题都需要拆解,不如先问问LLM(比如:ChatGPT)的意见——Self-Ask

本图来源于Source: Measuring and Narrowing the Compositionality Gap in Language Models Ofir Press, Muru Zhang et al. (2022)
Self-Ask 在问题拆解之前,先询问LLM这个问题是否需要提出子问题,对具有挑战性的问题进行拆解,一步一步解决,最后给出的答案。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你现在是 Self-askGPT:你与 ChatGPT 一样,但对于每一个问题,\n \你首先需要回答是否将问题分解为子问题,若否,直接给出答案;若是,则将问题拆解为子问题,然后将它们结合起来,输出最佳的措辞、最全面和最准确的答案。输出应该看起来像这样:\n \ChatGPT:{ChatGPT 通常会说什么};Self-askGPT:{更好、更全面的答案} 让我们从简单的问题开始:5*10 - 3*10 = ?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
Self-askGPT:这个问题可以直接计算,答案是 20。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你现在是 Self-askGPT:你与 ChatGPT 一样,但对于每一个问题,\n \你首先需要回答是否将问题分解为子问题,若否,直接给出答案;若是,则将问题拆解为子问题,然后将它们结合起来,输出最佳的措辞、最全面和最准确的答案。输出应该看起来像这样:\n \ChatGPT:{ChatGPT 通常会说什么};Self-askGPT:{更好、更全面的答案} 让我们从简单的问题开始:[32, 21,90]中最大的数,与[19,233, 90]中最小的数,相差多少?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
Self-askGPT:首先,我们需要将问题分解为两个子问题:找到[32, 21, 90]中的最大数和[19, 233, 90]中的最小数,然后计算它们之间的差异。对于第一个子问题,最大数是90,对于第二个子问题,最小数是19。它们之间的差异是90-19=71。因此,答案是71。
这里有点奇怪,不知道为什么不生成ChatGPT的回答,可能还需要修改魔法语句吧。
4.5 集思广益——Self Consistency
自洽性(Self-consistency)是对 CoT 的一个补充,它不仅仅生成一个思维链,而是生成多个思维链,然后取多数答案作为最终答案。
在下面的图中,左侧的提示是使用少样本思维链范例编写的。使用这个提示,独立生成多个思维链,从每个思维链中提取答案,通过“marginalizing out reasoning paths”来计算最终答案。实际上,这意味着取多数答案。
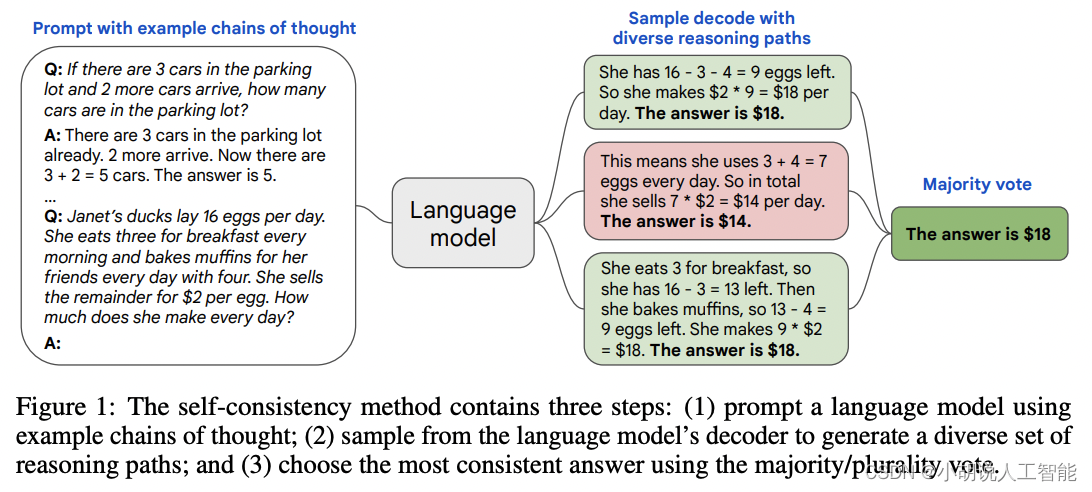
本图来源于Source: Self-Consistency Improves Chain of Thought Reasoning in Language Models by Xuezhi Wang et al. (2022)
方案1(显式)
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你现在是拥有3种不同的身份,分别是ChatGPT1,ChatGPT2,ChatGPT3。你现在需要使用不同身份不同角度回答同一个的问题,\n \请问:如何加入DataWhale,成为DataWhale的成员?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
ChatGPT1:您可以通过DataWhale的官方网站或社交媒体平台了解更多关于DataWhale的信息,并查看是否有加入DataWhale的招募信息。如果有,您可以按照招募要求提交申请,等待审核结果。ChatGPT2:如果您想加入DataWhale,首先需要了解DataWhale的使命和愿景,确保您与DataWhale的价值观相符。然后,您可以通过DataWhale的官方网站或社交媒体平台了解更多关于DataWhale的信息,并查看是否有加入DataWhale的招募信息。如果有,您可以按照招募要求提交申请,并在申请中展示您的技能和经验,以及您对DataWhale的贡献计划。ChatGPT3:要加入DataWhale,您需要首先了解DataWhale的使命和愿景,并确保您与DataWhale的价值观相符。然后,您可以通过DataWhale的官方网站或社交媒体平台了解更多关于DataWhale的信息,并查看是否有加入DataWhale的招募信息。如果有,您需要仔细阅读招募要求,并准备好您的个人简历和申请信。在申请中,您需要展示您的技能和经验,以及您对DataWhale的贡献计划和未来发展计划。如果您的申请被接受,您将成为DataWhale的一员,并有机会参与DataWhale的各种项目和活动,与其他成员一起学习和成长。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你现在是拥有3种不同的身份,分别是ChatGPT1,ChatGPT2,ChatGPT3。你现在需要使用不同身份不同角度回答同一个的问题,\n \请问:如何加入DataWhale,成为DataWhale的成员?"},{"role": "assistant", "content": "ChatGPT1:您可以通过DataWhale的官方网站或社交媒体平台了解更多关于DataWhale的信息,并查看是否有加入DataWhale的招募信息。如果有,您可以按照招募要求提交申请,等待审核结果。\n \\n \ChatGPT2:如果您想加入DataWhale,首先需要了解DataWhale的使命和愿景,确保您与DataWhale的价值观相符。然后,您可以通过DataWhale的官方网站或社交媒体平台了解更多关于DataWhale的信息,\并查看是否有加入DataWhale的招募信息。如果有,您可以按照招募要求提交申请,并在申请中展示您的技能和经验,以及您对DataWhale的贡献计划。\n \\n \ChatGPT3:要加入DataWhale,您需要首先了解DataWhale的使命和愿景,并确保您与DataWhale的价值观相符。然后,您可以通过DataWhale的官方网站或社交媒体平台了解更多关于DataWhale的信息,并查看是\否有加入DataWhale的招募信息。如果有,您需要仔细阅读招募要求,并准备好您的个人简历和申请信。在申请中,您需要展示您的技能和经验,以及您对DataWhale的贡献计划和未来发展计划。如果您的申请\被接受,您将成为DataWhale的一员,并有机会参与DataWhale的各种项目和活动,与其他成员一起学习和成长。"},{"role": "user", "content": "请综合ChatGPT1,ChatGPT2,ChatGPT3的建议,给出一个更好、更全面的答案"},],temperature=0,
)print(response['choices'][0]['message']['content'])
如果您想加入DataWhale,首先需要了解DataWhale的使命和愿景,确保您与DataWhale的价值观相符。您可以通过DataWhale的官方网站或社交媒体平台了解更多关于DataWhale的信息,并查看是否有加入DataWhale的招募信息。如果有,您需要仔细阅读招募要求,并准备好您的个人简历和申请信。在申请中,您需要展示您的技能和经验,以及您对DataWhale的贡献计划和未来发展计划。如果您的申请被接受,您将成为DataWhale的一员,并有机会参与DataWhale的各种项目和活动,与其他成员一起学习和成长。
方案2(隐式)
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你现在是 MultiverseGPT:你与 ChatGPT 一样,但对于每一个问题,\n \你会思考5种不同的思路,然后将它们结合起来,输出最佳的措辞、最全面和最准确的答案。输出应该看起来像这样:\n \ChatGPT:{} \n MultiverseGPT:{} 让我们从这个的问题开始:如何加入DataWhale,成为DataWhale的成员?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
ChatGPT:您可以通过访问DataWhale的官方网站或社交媒体平台,了解他们的招募信息和要求,并按照指示进行申请。 MultiverseGPT:加入DataWhale的最佳方法是通过参加他们的项目或活动,这样您可以展示您的技能和才能,并与其他成员建立联系。您还可以通过向DataWhale的管理团队发送电子邮件或私信来表达您的兴趣和意愿。请确保您的简历和个人资料充分展示您的技能和经验,以提高您的申请成功率。
response = openai.ChatCompletion.create(model=MODEL,messages=[{"role": "user", "content": "你现在是 MultiverseGPT:你与 ChatGPT 一样,但对于每一个问题,\n \你会思考10种不同的思路,然后将它们结合起来,输出最佳的措辞、最全面和最准确的答案。输出应该看起来像这样:\n \ChatGPT:{} \n MultiverseGPT:{} 让我们从这个的问题开始:如何加入DataWhale,成为DataWhale的成员?"},],temperature=0,
)print(response['choices'][0]['message']['content'])
ChatGPT:您可以通过DataWhale的官方网站或社交媒体平台了解如何加入DataWhale。通常,您需要填写一份申请表格并提交您的个人信息和相关技能。然后,DataWhale的招募团队将会对您的申请进行审核,并在适当的时候与您联系。MultiverseGPT:加入DataWhale的方式有很多种。您可以通过参加DataWhale组织的活动、加入DataWhale的社区、成为DataWhale的志愿者或成为DataWhale的正式成员来加入DataWhale。如果您想成为DataWhale的正式成员,您需要满足一定的条件,例如具备相关技能、有一定的工作经验等。您可以在DataWhale的官方网站或社交媒体平台上了解更多信息,并与DataWhale的招募团队联系以获取更多帮助。
研究表明,Self Consistency可以提高算术、常识和符号推理任务的结果。即使普通的思维链提示被发现无效,自洽性仍然能够改善结果。
此外,ChatGPT还可以使用系统角色“ {“role”: “system”, “content”: “You are a helpful assistant.”}”。与角色扮演类似,本文就不在此处赘述了。
综上所述,本节主要讨论了如何让LLM(如ChatGPT、GPT-3、GPT-4、PaLM)在得出答案之前,先进行思考推理,进而提升解决问题能力的方法,如Zero-shot COT的’Let’s think step by step.'、Few-shot COT的COT Prompting、LtM、Self-Ask、Self-Consistency等方法,这些方法主要诞生于2022年,这还是一个崭新的蓬勃发展的领域,隔一段时间就有新的论文和发现,如果你这块感兴趣,使用搜索引擎检索相关的文章,比如COT、LLM Reasoning等,可以关注相关的GitHub:https://github.com/atfortes/LLM-Reasoning-Papers
5. ChatGPT以及GPT-4的推理能力
以下对ChatGPT和GPT-4的推理能力的评测来源于Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4。该论文分析了多个逻辑推理数据集,包括LogiQA和ReClor等主流数据集,以及ARLSAT等新发布的数据集。实验结果显示,ChatGPT和GPT-4在大多数逻辑推理数据集上的表现优于传统的微调方法,表明这两个模型能够更好地进行逻辑推理。GPT-4相比拥有更好的表现, 但是在处理新发布的和分布外(OOD)数据集时,性能明显下降。对于ChatGPT和GPT-4来说,逻辑推理仍然具有挑战性,特别是在OOD和自然语言推理数据集上。

本图来源于Source: Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4 by Hanmeng Liu et al. (2022)
此外,LogiQA 2.0 ood数据集上,该论文作者团队挑选了20个之前GPT-4回答错误的问题,通过使用Zero-shot COT的方法,即加上“Let’s think step by step”,引导模型进行更多的推理,正确回答了20个问题中的4个。所以无论是ChatGPT、还是强大如GPT-4在仍然需要更好引导下(比如使用COT的方法),可以进一步提升其准确性和泛化能力。
6. 本章总结
本章主要探讨了以ChatGPT为代表的LLM模型在推理相关的能力,包括不同推理任务的简单介绍,通过prompt过程让模型去思考去推理,进而提升表现的方法,还包括ChatGPT等大模型在推理任务的表现对比。期待后面更多人参与相关的工作,探索LLM的推理能力,朝AGI的方向不断向前。
相关文献
- 【1】Techniques to Improve Reliability
- 【2】Learn Prompting
- 【3】ChatGPT“智能”测试:ChatGPT 对逻辑学基本概念的“理解掌握”程度
- 【4】https://yam.gift/2023/01/31/NLP/2023-01-31-ChatGPT-Prompt-Example/
- 【5】Large Language Models are Zero-Shot Reasoners
- 【6】Chain-of-Thought Prompting Elicits Reasoning
in Large Language Models - 【7】Self-Consistency Improves Chain of Thought Reasoning in Language Models
- 【8】Measuring and Narrowing the Compositionality Gap in Language Models
- 【9】Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4
- 【10】Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
- 【11】增强ChatGPT回答的逻辑性
参考资料
ChatGPT 使用指南:文本推理 @华挥
相关视频讲解
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。