文章目录
- 0 背景
- 1 IMCI 架构
- 1.1 架构演进的背景
- 1.2 基本架构
- 1.2 基本使用
- 1.4 列索引存储 设计
- 1.5 RW-RO 的数据同步实现
- 1.5.1 CALS
- 1.5.2 2P-COFFER
- 1.6 计算引擎实现
- 1.7 性能
近期除了本职工作之外想要再跟进一下业界做讨论以及落地的事情,扩宽一下视野,计划每周能精读一篇与工作领域相关的论文。
看到了 PolarDB 团队在2023年 SIGMOD 工业paper上发的 IMCI,是当下 HTAP 方向在探索落地的架构 PolarDB-IMCI (In-Memory-Column-Index),学习一番。
0 背景
云原生数据库已经是行业的必然趋势,以其 极高的弹性、灵活的按需收费 和 极地的运营成本在数据库市场腾飞。
同时 AP + TP 之间的界限在逐渐模糊,很多应用期望一套数据库系统能同时支持事务以及分析处理。传统的解决方案是为这两种场景分别部署一个数据库,两个数据库之间通过 ETL 做数据同步。这样的方式并不高效,数据同步之间延时非常大 且消耗极大的物理资源 (TP数据库中消耗了大量的CPU、内存 将数据存储下来、又消耗大量的网络资源发送给 AP数据库,AP数据库再消耗较多的内存、CPU资源将同样的数据再存储一份到本地)。因为应用场景想要使用HTAP能力时有这种问题,论文中提出了 PolarDB-IMCI 的设计目标:
- Transparent Query Execution (Query的透明执行)。为TP和AP 维护统一的SQL接口,同一个query可以再AP 又可以再TP场景执行,方便用户使用。
- Advanced OLAP Performance (顶级的 OLAP 性能)。虽然是HTAP数据库,但是在AP场景能够达到和业界前沿的AP数据库接近的性能
- Minimal Perturbation on OLTP Workloads(对TP 场景影响最小化)。TP场景的查询延时敏感,实现过程中需要尽可能减少对TP workload的影响。所以需要对AP以及TP的 query 做资源隔离(肯定不可能在同一套物理资源上来跑)。
- High Data Freshness (高数据新鲜度),HTAP肯定有数据同步,TP生成的数据越快被AP系统可见,就越能发挥数据的价值,尤其是社交媒体 以及 电商领域,能获得用户的一手数据进行分析并反馈给用户。这里提出了 visibility delay 来对数据新鲜度进行定义,能够提供越低的 visibility delay 则新鲜度越高,更有价值。
- Excellent Resource Elasticity (极致的资源弹性能力)。 HTAP 对资源的消耗较大且不稳定,workload 相比 纯TP 以及 AP 更复杂,所以分钟级别甚至秒级别的横向扩展能力 能够为用户提供强大的AP性能。
首先从结果来看:
- TPC-H(100G) 性能 PolarDB-IMCI 比 TP场景的PolarDB 性能高了 100倍,基本和 ClickHouse的AP性能接近。
- TP 场景的性能也只下降了 5% 且 visibility delay 在普通的workload下小于 5ms,heavy workload下 小于30ms。
- 弹性能力能够在十几秒内完成。
这个性能真的很强,TP性能基本稳定的情况 AP性能竟然接近 CK。
一起学习一下 IMCI 是如何达成这个效果的。
1 IMCI 架构
1.1 架构演进的背景
业界在HTAP 领域也有不少落地的产品,架构上 大体分为两类:
- 单实例的HTAP。比如,Oracle Dual 可以将行存数据在内存中构建为 IMCU (列存单元)提供高效的数据扫描。对于 IMCU 的更新会以日志性能被以元数据形式临时保存,可以通过batch方式在累积了一批更新之后再重新插入到IMCU 内存数据结构之中(减少频繁的IMCU的更新对资源的消耗)。单节点实现HTAP 有很明显的问题,对TP影响较大(同一台机器)、没有弹性(只能服务于数据量较小的AP场景,在当下应用场景较少)、数据新鲜度不够(为了降低对TP的影响而做的 ICMU batch更新肯定影响新鲜度,无法以AP方式快速拿到较新的数据)。SQL Server 的CSI HTAP 单机架构就更为合理一些,支持列存索引的列存储,可以定期将TP的数据更新 merge到 CSI,不需要重新构建内存数据结构。
- 多实例的HTAP。这样的架构当下相对较多。AP 和 TP的 query 可以隔离执行,每一个实例都可以配置适合其工作的架构;比如AP场景对计算要求较高,则可以为其节点配置较高性能的CPU从而加速AP性能。
业界已经落地的 多节点的HATP系统,比如 SAP HANA 通过ATR(Asynchronous Table Replication) 实现表数据 在 主从节点之间的复制,按照session粒度并行重放。这样的数据同步方式过于粗糙,多个session 可能插入/更新同一行,每一个session的数据都得在从节点重放,并没有做合并。 Google F1 Lighting 通过CDC 来捕获对当前数据库的更新操作,合并之后再同步到从节点。TIDB 通过 raft 实现了行存引擎(TIKV) 和 列存引擎 (TiFlash), TiFlash 作为 raft learner 异步接受来在 tikv leader的 TP数据存储到本地,TiFlash 因为是 learner 不会参与选举,不会影响 tikv 节点的 TP workload。ByteHTAP (字节的HTAP产品)是通过 binlog 异步同步到 AP 服务中,其中用于TP服务的是 ByteNDB(MySQL协议),用户 AP 服务的是 Flink。Oracle Dual 后来新版本也实现了多实例的HTAP架构,其多实例架构下通过 Standy 节点提供 AP 负载 ,在主实例和 standy 实例之间通过 REDO-log 进行数据同步。PolarDB-IMCI 是通过 REDO 日志做异步数据同步。
同时 在云原生架构下, PolarDB-IMCI 和众多上云数据库产品一样利用其存储计算节藕的能力,存储采用了共享存储(polar-fs),且利用其内部在云原生足够的新技术来提升到共享存储上的数据访问性能。所以相比于 SingleStore 数据先commit到本地,再异步同步到远端共享存储 blob-store来说 PolarDB-IMCI 直接可以高效在 共享存储上提交,这样数据的新鲜度 以及 各种状态都能够直接从 共享存储上提取。
1.2 基本架构
其基本架构图如下:
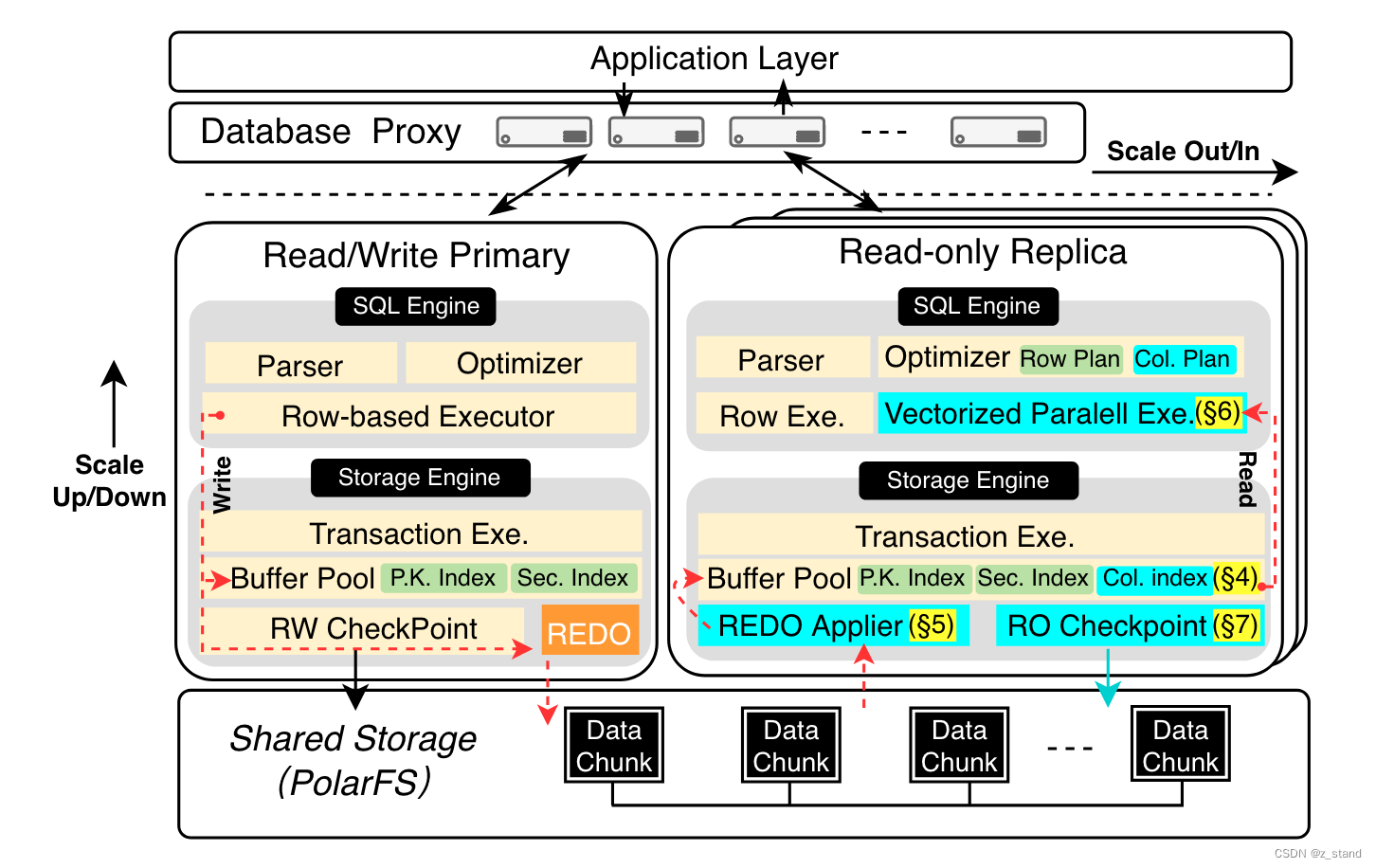
这个图展示的是整个 PolarDB-IMCI 支持 HTAP 的完整架构,关于其 IMCI的部分其实主要是在 Read-only中的 Storage-Engine中的 Col.index 部分,整个存算分离架构从下向上可以分为两层:
- 存储层。一个用户态的分布式文件系统 PolarFS,具有高可用和高可靠能力。
- 计算层是数据库部分 会有多个节点,包括一个读写主节点(RW node,其能够满足95%用户的写需求)和 几个用于只读的节点(RO node,RO节点能够快速弹性来服务读请求)。RO节点内部既支持 基于行的执行引擎 又支持 向量化执行引擎,这样能同时服务TP 和 AP的读。IMCI 优化器会自动适应两个执行引擎,比如用户query执行了聚合函数,则使用向量化执行引擎;用户query 中使用点查,则优化器切为 按行提取数据的执行引擎。RO 节点并没有直接用业界已有的OLAP系统(clickhouse),主要是考虑兼容性,RO节点还需要服务部分TP需求,直接用已有的AP系统改造成本更高。
- 计算层 用于负载均衡的 proxy 无状态节点。
所有的节点都通过 RDMA 连接,能够实现数据的低延时访问(数据库创业公司像是 singlestore 为了低延迟也只能先放本地,再异步存储到远端对象存储),这个架构在国内只有阿里能玩得起,全链路都是自己维护,其他的都只能用 S3 + 本地磁盘来达到低延迟访问数据的目的。
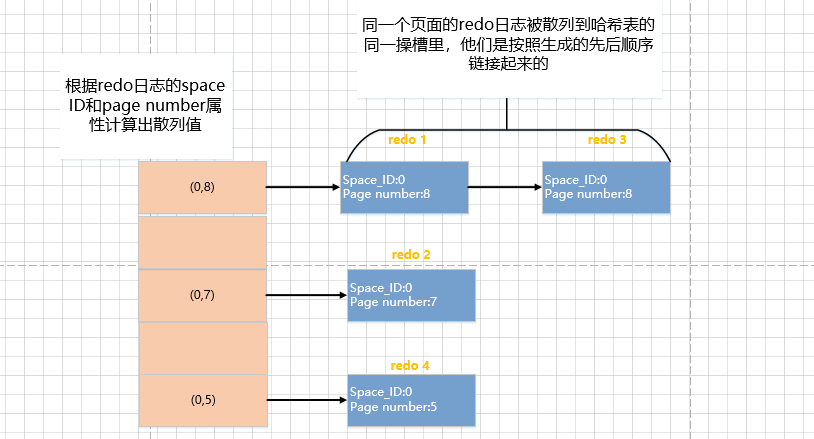
IMCI部分 是在 RO node中允许在行存上构建内存中的列存索引。为了保障列存索引访问到的数据和行存保持一致性,RO node 在构建IMCI 的构建过程会维护 RID(row-ID ) --> PK(Primary key) 的定位器,其通过内存的 两层LSM-tree来维护,方便 内存压缩、插入 以及 scan。
RW-RO 节点数据同步实现 是通过异步复制框架来做的。数据在 RW节点写入并生成Redo (Commit-Ahead)日志即返回,后续的Redo 日志同步到 RO 时异步完成,RO节点解析 Redo 中的行存数据格式再转为列存索引则是 RO节点的工作。基本不会影响对 RW节点处理TP workload的性能。
1.2 基本使用
PolarDB-IMCI 与 MySQL语法完全兼容,用户可以用类似如下SQL 建表以及创建索引:
CREATE TABLE demo_table { C1 INT(11) NOTNULL,C2 INT(11) DEFULT NULL, C3 INT(11) DEFULT NULL, C4 INT(11) DEFULT NULL, C5 LONGTEXT DEFULT NULL, PRIMARY KEY(C1), KEY SEC_INDEX(C2), KEY COLUMN_INDEX(C3, C4, C5)
}
指定了这个表在 C1 列 创建主键索引,C2 列创建二级索引,C3,C4,C5 创建 IMCI 列索引;然后也可以后续通过 ALTER 修改、添加 列索引。
1.4 列索引存储 设计
其基本架构如下,也就是上面架构图中 RO node中的 col-index 部分。
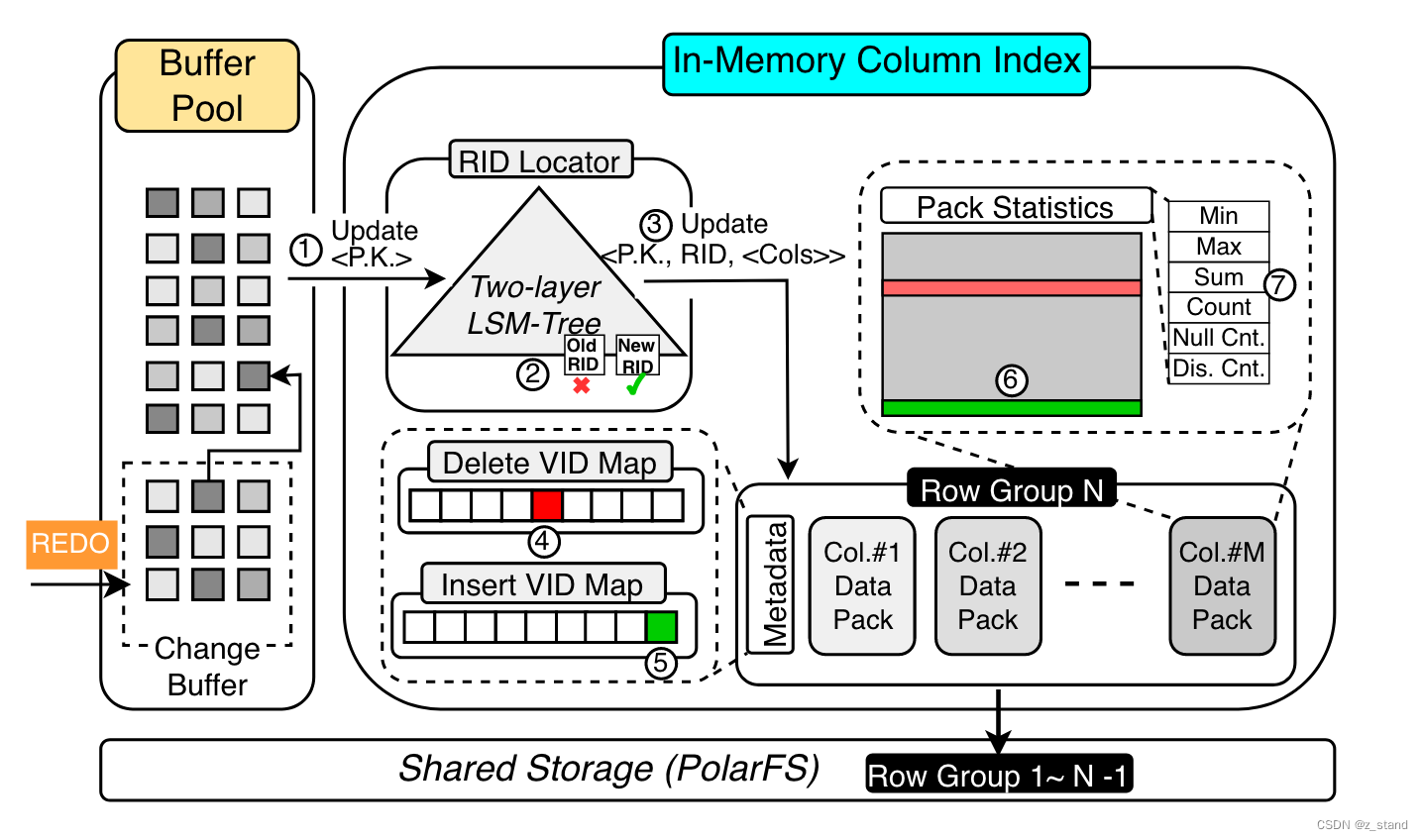
数据 插入到 IMCI中是以 append-only形态(毕竟是LSM-tree), LSM-tree 会将所有的数据行划分为多个 row-group,即多行数据形成一个row-group。其中的每一列数据则是一个 data-pack,每一个data-pack中的 头部 还会包含当前列的 statistics 数据,用来加速列的读取 以及 服务器于优化器做plan。 这其实就是基本的列存格式,可能大家的实现都差不太多。当然,有一些实现是每一个文件只存储一列的数据,这样读取某一列的时候只需要打开一个文件,但是对于一列的多行的读取则需要打开多个文件,IMCI这个多行多列的聚合只需要打开一个文件就好了。
为了支持 RR隔离级别,默认是MVCC来实现。IMCI中会按照行的插入顺序分配一个64bits 的全局递增且唯一的row-id。两层LSM-tree 作为RID locator中会维护 <primary-key, rowid>的映射,提升内存利用率,通过 RID-locator 能够定位到某一个key所处的 Row-Group。
row-group 在内存中构建好格式 然后存储在磁盘上,类似memtable-flush操作。比如当前的row-group N-1 数据量达到指定阈值之后就可以变为immutable,写入到polar-fs中,创建一个新的row-group N 继续接受新的写入。
每一个 row-group 都会维护一个metadata区域,用来单独存放 delete-vid-map 以及 insert-vid-map。insert 一行数据,则是append 一个<row-id, timestamp> insert-vid-map中。update 一行数据则同样 插入一个新的<row-id, timestamp> 到 insert-vid-map 以及 旧的rowid,以及当前timestamp到 delete-id-map。这个是MVCC的基本实现,对于行的更新也是插入新版本到对应row-group的data-pack末尾以及同样方式的标记删除,并记录rowid,timestamp到 row-group中的 metadata中。读取具体row-group的时候分别在 insert以及delete vid-map提取对应的 row-id, timestamp信息,比较timestamp 来 确认一个rowid 对应的行是否可见。也就是类似 PG 中 tuple 行维护的 xmin和 xmax,确认一个tuple是否可见,只需要比较这个tup 对应的xmin和xmax 和 snapshot中维护的xmin和xmax 以及 xip的大小关系就好了。
总结来说
插入流程如下:
- IMCI 为当前行分配一个 RID
- 构建一个<primarykey, rid> 的映射,插入到 rid-locator 即两层 LSM-tree 中。
- 将数据append到 对应row-group中的 data-pack中
- 将 <rid, current-timestamp> 插入到 insert-vid-map中
删除流程如下:
- 通过要删除的行的 PK(primary-key) 在 rid-locator中查找最新的 rid。
- 将 <rid, current-timestamp> 插入到 delete-vid-map中
- 从 rid-locator中删除 <primarykey, rid> 的记录。
update流程是先做删除操作,再做插入操作,上图架构图中已经展示了。
从上面的流程中可以总结一下利用 append-only + LSM-tree 的优势:
- 因为IMCI看到的都是 commit的log,这一些数据都一定是需要持久化的,所以不需要考虑实时的rollback问题。这样append-only的无锁并发操作同一行的优势旧体现得非常明显。
- 写性能极高,append追加写文件对 polar-fs也非常友好
- lsm-tree 内存利用率较高(数据组织有序且密集,对压缩友好)
当然因为 row-group 是append-only 的,也需要对其数据进行compaction,否则无效版本过多会影响scan 性能, 并且造成空间浪费问题。
Compaction策略是论文中提到的感觉过于简单: 定期检测 多个 row-group中的 有效行数(通过每一个row-group的metadata 来确定),如果发现这几个 row-group 文件的无效行过多(超过一个阈值),则启动一个后台线程调度compaction事务:读取有效行并append到新的 row-group中,写入到文件;完成文件的写入之后重新更新 rid-locator; 删除文件(这个过程我理解需要对rid-locator加锁)。
因为这个磁盘数据结构不太清楚,论文没有说磁盘的文件组织是否也是LSM-tree形态?当然维护磁盘的lsm-tree,其compaciton 的CPU消耗过高,因为需要排序。这相比于云上的低效compaction造成的空间放大来说还是微不足道,毕竟上云之后cpu肯定更贵,所以这块的compaction策略是合理的。不用去考虑不同 row-group文件之间的排序,compaction过程就是 单纯得扫描文件中的有效行插入到新的活跃的 row-group 中统一压缩之后再持久化就好了,除了压缩整个过程对CPU的消耗是较低的。
1.5 RW-RO 的数据同步实现
介绍完 列存索引的基本实现之后再看看 RW-RO节点之间如何高效的做数据同步,如何对 OLTP workload 产生最小的影响?
前面介绍过 数据同步是通过 异步同步 物理REDO-log,RO-node 需要做一些努力尽可能保证数据的新鲜度。
PolarDB-IMCI 通过两种方式来降低 TP 场景的延迟 以及 提升数据的新鲜度:
- CALS (Commit-Ahead Log Shipping)降低 对OLTP workload的影响 以及 保证数据新鲜度。
- 2P-COFFER (2-Phase ConFlictFree Parellel Relay) 提升数据在 RO node的 replay效率。
1.5.1 CALS
这个idea真的很有趣。
其数据同步的方式关键点实在 Shipping,即 RW-node 中未提交的事务也会被发送到RO-node。
如下图:
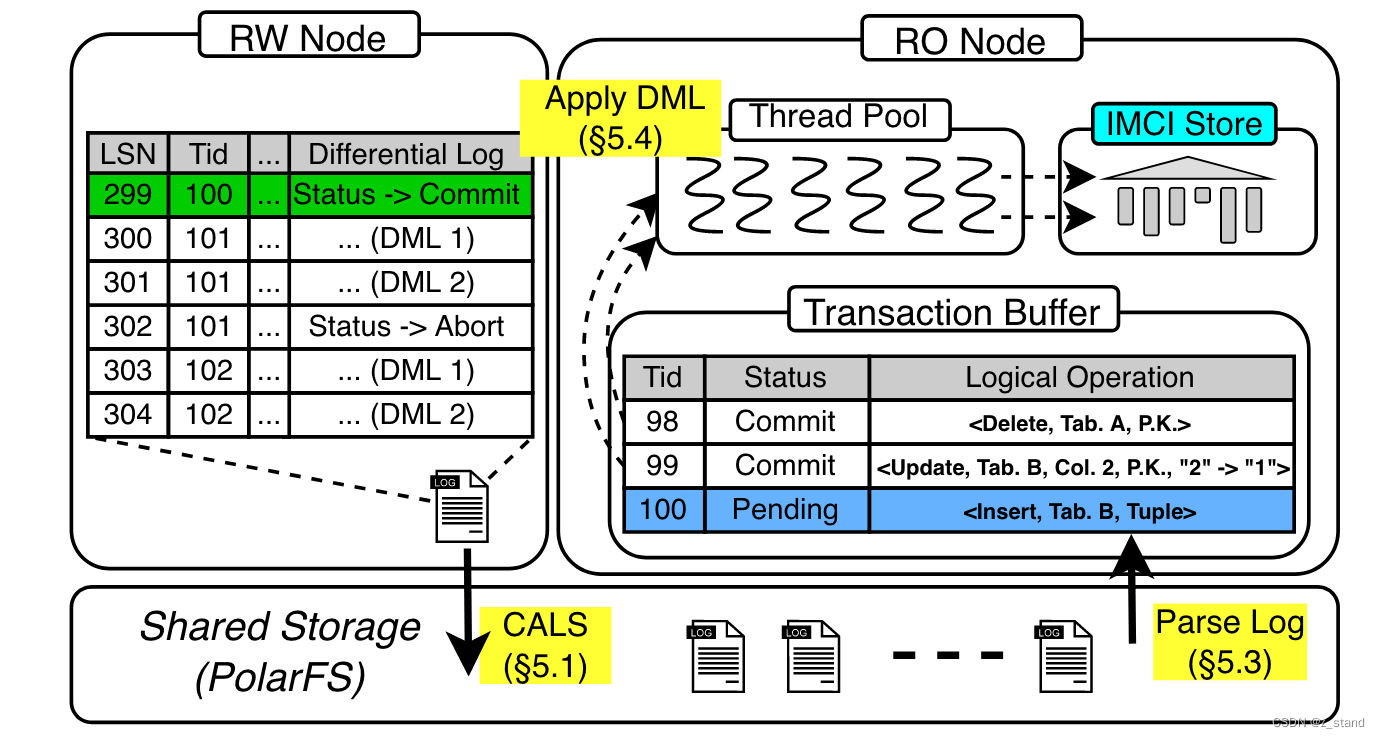
rw-node 中正在进行中的一批事务生成的redolog 在 RO节点被解析道 Transaction-Buffer中。
这个 redo-log 中每一个record 都有一个 lsn 保证数据的唯一性,还有对应的事物tid。同一个事务会有多个record,每一个事务最后一个 tid 的 record是该事务状态,是否提交或者终止。写redo-log 到polar-fs完成之后 rw-node会将最新的lsn 广播给 ro-node,ro-node会立即从 polarfs中读取 redo日志存储到 transaction-buffer 中,整个过程不需要得 rw-node 提交事务。
在RO-node 逐条解析 redo-log中的record时如果没有读到当前事务的最终事务状态之前,是不会走列存写入的逻辑的。Apply DML 操作只会在transaction-buffer 中逐条 扫描事务状态为commit的 record,对于读取上来的事务状态时abort的,则直接从当前transaction-buffer中移除就好了。
需要注意的是 RO node这里会把读取的redo-log 中的数据转为 逻辑操作记录,方便合并。因为 apply 的都是record的记录的话只需要关注最后的操作,比如操作同一行:insert,delete, update,delete,这个记录只需要记录一下 delete 这个逻辑dml操作就好了。
当然这个实现过程 也是 redo-log的劣势,相比于传输 binlog来说对空间消耗过大,但是因为有polar fs+rdma 则其传输效率高,到ro-node上再去转为逻辑 dml 操作就好了。
1.5.2 2P-COFFER
两阶段无冲突得并行重放,这两个阶段的目的是为了提升 RO 节点对 REDO log 到 IMCI 的效率。
redo-log首先被读取到 基于行存的 内存 buffer-bool中:
阶段1:
log-dispatcher 启动多个 worker 按照页粒度将 基于行存的buffer-pool 中的 record 操作转为 transaction-buffer 中的 dml逻辑操作。
对应的基本流程 以及 redo-log record的物理格式如下:
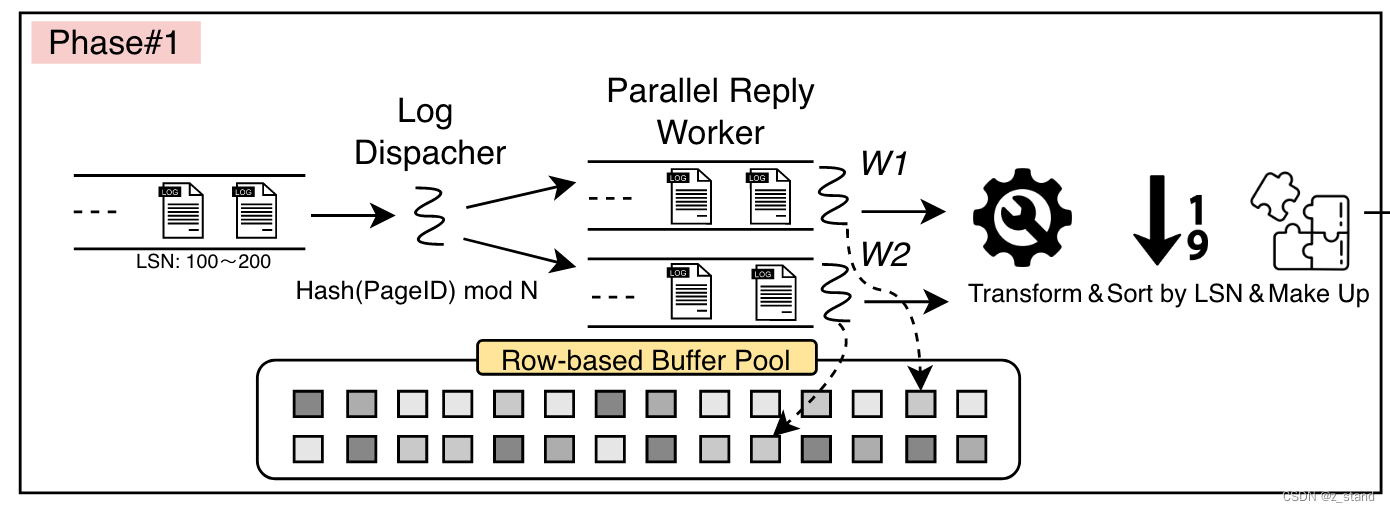

log-dispatcher 会根据每一个record操作的 pageID 将redo日志发给不同的 worker线程,每一个worker按照 lsn从小到大的顺序进行replay。这样有一个好处是不同的事务操作同一行会被放在同一个work中进行 dml的replay,这样就能进行dml的合并,合并后的结果会按照事务提交顺序 插入到 transaction-buffer中。
当然 这个过程需要丢弃数据库内部的操作,比如 btree: split,merge等。
阶段2:
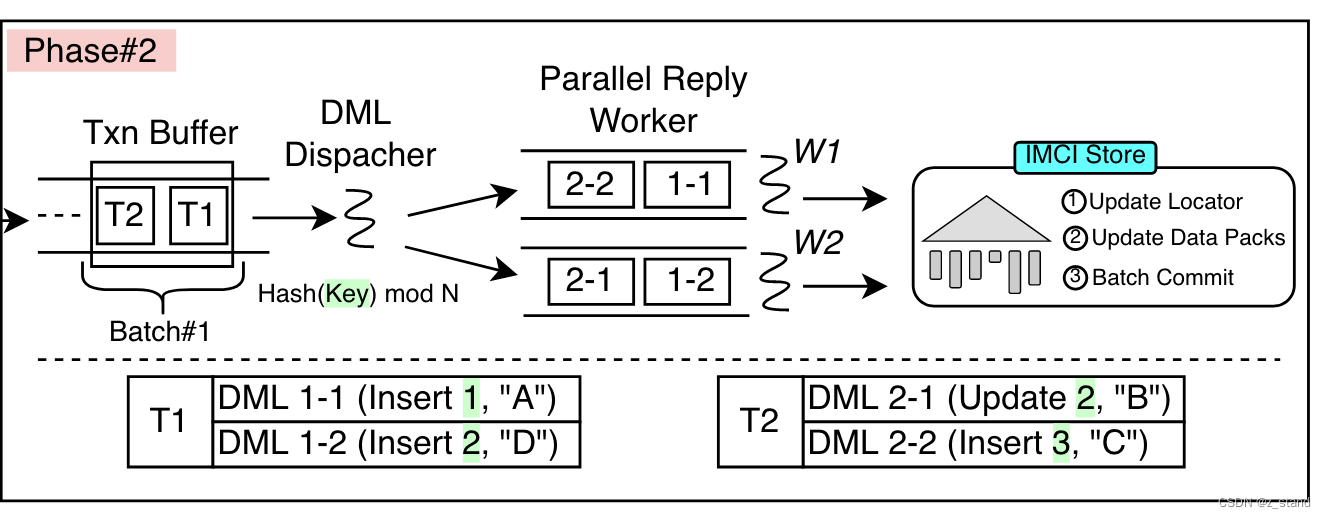
这个阶段主要是 dml-dispatcher 提取 transaction buffer中的数据,每一个事务的 多个dml语句 会被按照 primary-key 做hash 映射到不同的 worker 中进行异步 IMCI-Store的replay。
这样针对同一行的操作在 会放在相同的worker中处理,这里也是做了类似排序的功能。到 IMCI-Store中这一些 dml 转为 row-group的文件数据时 也会大概率在同一个 row-group文件,从而更有利于统计信息的维护以及 compaction。
关于数据一致性问题:
因为 redo-log 在 rw-node和 ro-node 之间是异步复制的,所以 ro-node上可能会看到旧的数据。为了在 ro-node上 提供不同的事务隔离级别(论文说是强一致,我理解应该是 RR 隔离级别) ,IMCI 通过proxy 实现了这一需求。
proxy 跟踪 rw-node 的 written-lsn 以及 所有 ro-nodes 的 applied-lsn,它们分别表示 rw和ro 节点的事务提交点。在 written-lsn 之前的事务一定已经在 rw-node 上提交,在 applied-lsn之前的事务一定在 ro-node上提交。proxy 拿到用户query 要访问的current-lsn时,找到第一个 >= current-lsn 的written-lsn,只需要将其路由到 applied-lsn >= written-lsn 的RO node 上就好了,这个ro-node 就能读到所有 <= current-lsn 的数据。 整个过程是可以保障数据访问的一致性的,但是线性一致性肯定达不到,毕竟这个一致性要求的是rw-node提交的要立即在 ro-node可见。
1.6 计算引擎实现
主要是两个阶段:
- 用户 query查询会通过基于成本的路由协议 由多个 proxy 在节点间做请求分发,比如写请求会下发到RW-node,读请求则会根据RO-node的负载情况均匀分发到不同的 RO-node上。
- 在RO-node内部则通过优化器生成查询计划,进行query的执行。
核心肯定是在阶段二,也就是RO节点内部如何执行query。
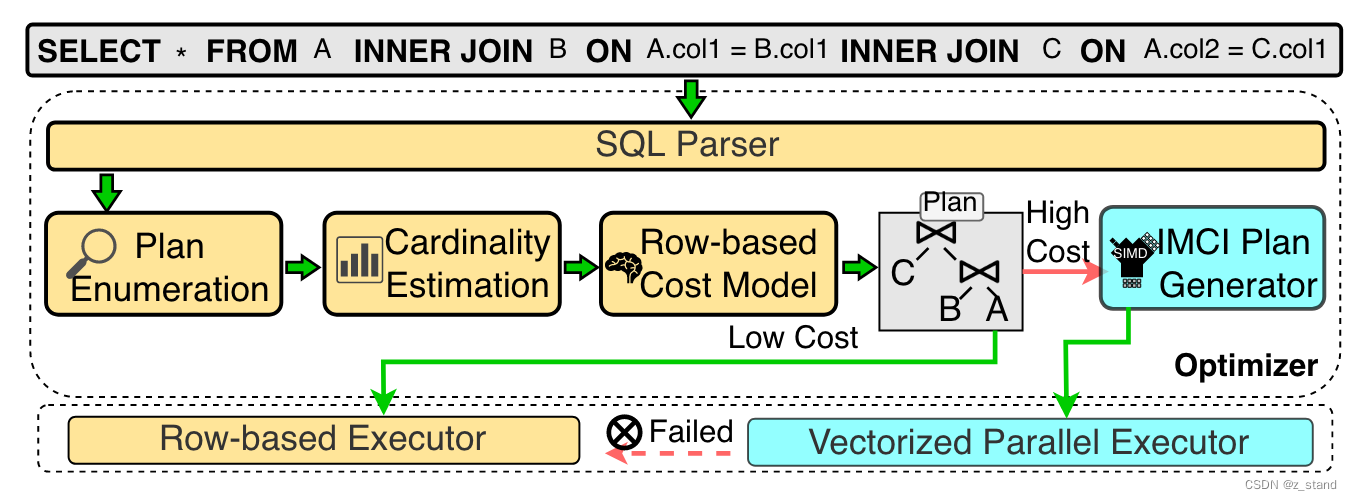
优化器会根据基于行的 cost估算 为每个查询选择合适的执行引擎,当然这里 polardb-IMCI做的并不是很强,也是他们后续的计算引擎的重点。目前是都假设所有的query都会在基于行的执行引擎上执行(cost-估算没有什么策略),先生称一个面向行的执行计划,发现实际生成后(借助读取到的statistics)成本高过阈值 则再生成一个向量化执行引擎的查询计划。
向量化执行引擎的设计基本和业界差不多:
- pipeline executor。算子之间是非阻塞运行的,且每个算子拉取数据的时候可以拉取一批数据做完计算之后将结果传递给下一个算子。比如filter 可以一次过滤数百上千条数据。从代码逻辑上来思考,本质上减少了内层循环的代码量,从原本一条数据需要执行100行代码(逐行读取,循环内有很多条件判断以及读取文件的逻辑)到 一批数据循环内只需要执行几行判断代码就好了。在 filter operator比较多的时候,这个收益是非常高的。同一批数据占用的内存可以被始终驻留在内存 甚至 cpu-cache中,访问效率大大提升。
- well-optimized parallel operators。一些算子的优化,比如 tablescan (seq-scan)可以并发发送数据包;join的无锁分区;采用缓存友好的hash表(类似 dynamic-hash) 以及 数据预读等。
- expression evaluation framework. 采用 SIMD 向量化指令 加速表达式计算。-- 这一块我基本还没了解过,需要仔细看看相关论文的介绍。😦
1.7 性能
当然,还有一些产品方面的设计我这里没有展开,比如如何实现弹性,即如何高效得增加RO-node。
性能数据主要展示了五个个维度:
- 纯 AP 性能的对比
- HTAP 负载下 AP worklod的增加对 TP work-load的影响
- 纯TP 性能的延时
- 资源弹性的能力
- 数据VD(visibility delay) 的性能
先看看一组 OLAP 的 性能数据,这个是对比 PolarDB-IMCI ,PolarDB 以及 ClickHouse 在相同的硬件环境下,相同的数据集跑出来的 标准TPCH 性能(分别是100GB 以及 1TB 数据集),执行时间越短性能越高:
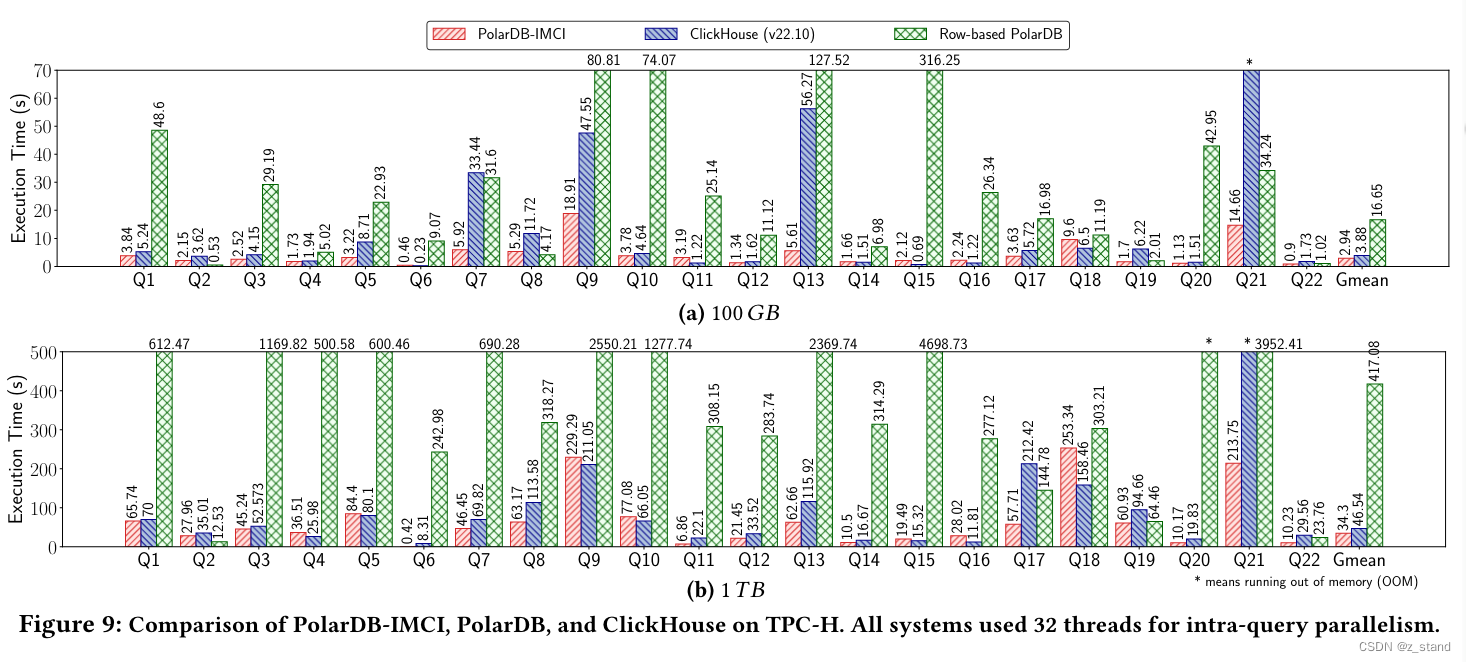
整体IMCI 的 AP 性能和 CK是基本接近的,设置在部分 query场景有不少性能提升。
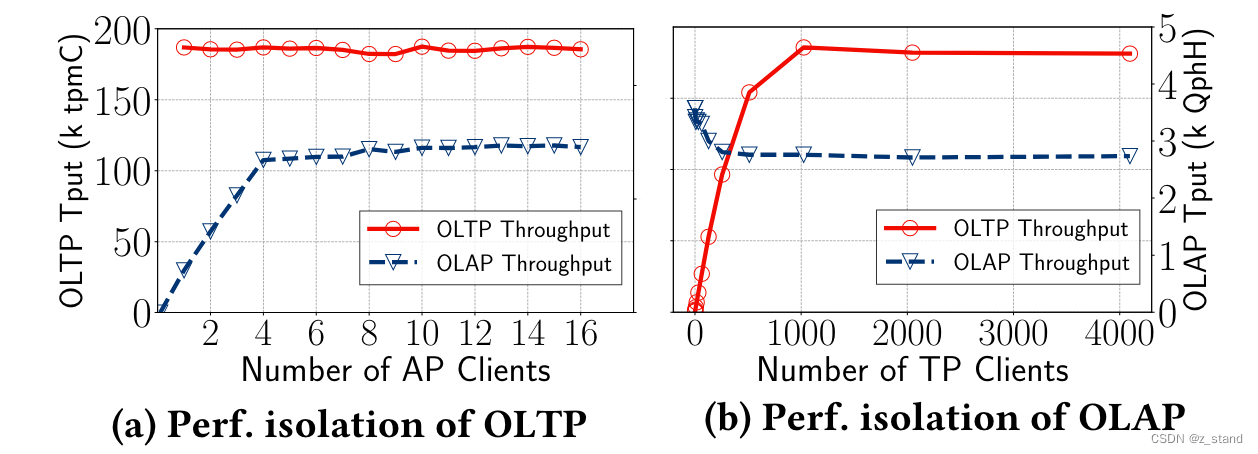
上图性能指标中
- a 是让 TP性能达到饱和,增加AP的吞吐,看是AP 是否会对TP性能有影响,发现基本没有影响。
- b 是相反的,让AP性能达到饱和,增加TP的吞吐,发现TP 性能的增加会降低 AP侧 20%的性能。原因如下: