背景
一切的一切要从那个月黑风高的晚上说起。那天晚上百无聊赖,于是打开nutsdb GitHub仓库看一下有什么issue需要处理一下。
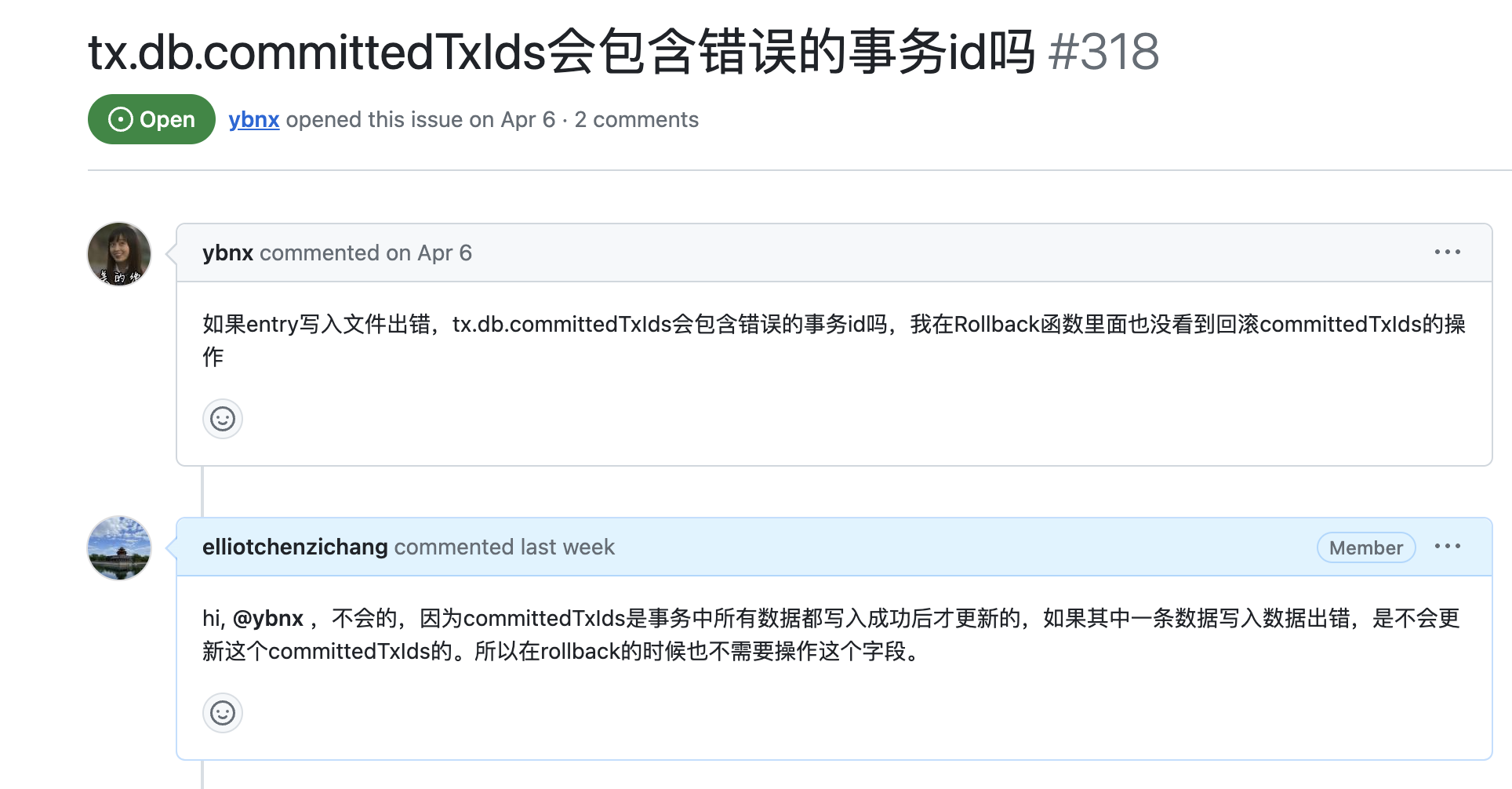
上图是我当晚发现的一条比较有意思的issue。其中committedTxIds是nutsdb中用于记录事务有没有被提交成功的数据结构。我简单的翻阅了一下代码确认了一些信息之后就回答了这个问题。但是,在翻阅代码的过程中我就隐隐约约感觉不是很对劲(这应该是男人的第六感吧hhhhh)。我仔细琢磨了一下就发现了问题所在,就是nutsdb的事务管理机制有问题。
问题是什么?
按照我之前文章讲到的。nutsdb通过持有一把db级别的读写锁来管理事务。事务分为读事务和写事务,如果用读写锁来管理就可以以一种比较简单的方式实现一写多读这样的并发级别。当事务是写事务的时候,这个事务会持有写锁,此时读取事务等待写锁释放,当事务是读事务时,读事务之间可以并发执行。事务执行流程是怎么样的呢?
- 开启事务,tx.Begin()
- 运行事务,执行读取请求,或者写入请求。
- 结束事务,tx.Commit()。如果是读事务,直接结束就好,如果是写事务,需要将本事务中涉及的数据改动持久化到磁盘中,持久化完成之后才算是结束了。另外Commit是正常的结束,而不正常的结束比如用户在事务运行途中想要结束本次操作,或者事务操作本身存在一些bug我们需要回退本次操作带来的影响。也就是我们说的Rollback,而Rollback就是不正常的结束。
事务的执行流程这里讲完了,回过头来我们那看看nutsdb的实现。nutsdb也实现了上面讲述的Begin,Commit, Rollback方法,另外在这些方法上也封装了比较高级的操作。也就是Update方法(代表写事务,当然可以也可以在这里面读数据),和View方法(代表读事务)。使用封装回调函数的方式帮助用户脱离事务状态管理的烦恼(具体可以看文档中的demo,这里就不再举例子了)。
实际上我认为大多数用户在实际操作nutsdb的时候更多的是用这两个封装好的高级方法,而不怎么使用原始方法。在浏览Update方法的时候我发现这样子封装带来的好处远远不止让用户摆脱事务状态管理这么简单。而是很多程度上避免了并发操作带来的风险。为什么这么说呢?我们以Update方法的实现来举例,且看以下Update方法的源码:
// Update executes a function within a managed read/write transaction.
func (db *DB) Update(fn func(tx *Tx) error) error {if fn == nil {return ErrFn}return db.managed(true, fn)
}// managed calls a block of code that is fully contained in a transaction.
func (db *DB) managed(writable bool, fn func(tx *Tx) error) (err error) {var tx *Txtx, err = db.Begin(writable)if err != nil {return err}defer func() {var panicked boolif r := recover(); r != nil {// resume normal executionpanicked = true}if panicked || err != nil {if errRollback := tx.Rollback(); errRollback != nil {err = errRollback}}}()if err = fn(tx); err == nil {err = tx.Commit()}return err
}
这个实现应该是比较典型的事务处理方法了,流程和上面讲的一样,Begin开启事务,执行用户提供的回调函数,Commit,如果Commit不成功就Rollback。可以发现这一整套流程都是在一个线程中跑的,如果用户一直就用这个方法来处理数据,很显然,一辈子都不可能会有并发的问题。但是可以看到,Begin,Commit,Rollback,都是开放出去的方法,也就是说,用户完全可以不使用Update,而是自己手动管理事务状态,这样也更加灵活。如果是这样就会考虑到并发操作的场景了。我们且深入分析。
事务Begin的时候必定是要持有锁的,不管是读锁还是写锁。事务Commit或者Rollback之后必定是要释放锁和资源的。那么问题来了,事务正在Commit中的时候用户执行Rollback会怎么样?Commit中就是处理本次事务(这里指写事务,因为读事务不可能提交数据)修改的数据。但是此时Rollback就会把资源释放掉。。。那岂不是完蛋了???我们可以深入看看源码。
Commit方法:
func (tx *Tx) Commit() error {for i := 0; i < writesLen; i++ {// 一个个写入本次事务操作的数据entry := tx.pendingWrites[i]}return nil
}
Rollback方法:
// Rollback closes the transaction.
func (tx *Tx) Rollback() error {if tx.db == nil {return ErrDBClosed}tx.unlock()tx.db = niltx.pendingWrites = nilreturn nil
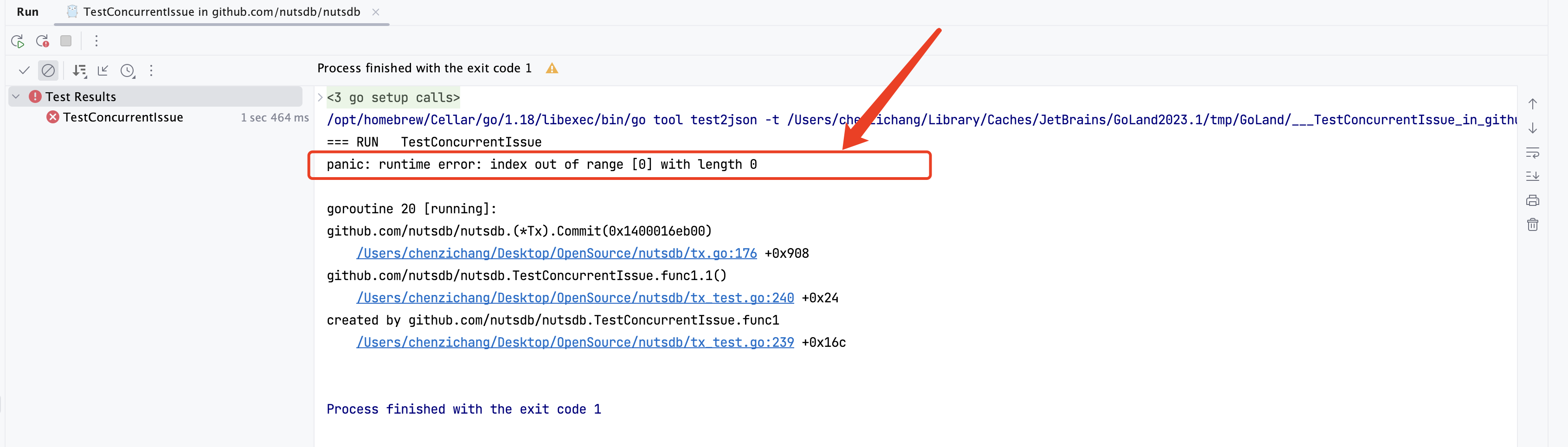
}可以看到,很显然,这两个函数在并发的情况下运行,当pendingWrites被Rollback改成nil之后,Commit方法中tx.pendingWrites[i]获取切片元素的时候就会出现panic,引起程序崩溃。这个就是潜在的并发问题。虽然按照理论是会panic,但是在好奇心的驱使下我还是写下了以下代码验证我的想法。
func TestConcurrentIssue(t *testing.T) {withDefaultDB(t, func(t *testing.T, db *DB) {testDataNumber := 1000testBucket := "test_bucket"tx, _ := db.Begin(true)for i := 0; i < testDataNumber; i++ {key := fmt.Sprintf("key_%d", i)value := fmt.Sprintf("value_%d", i)tx.Put(testBucket, []byte(key), []byte(value), Persistent)}go func() {tx.Commit()}()go func() {tx.Rollback()}()})select {}
}func (tx *Tx) Commit() error {for i := 0; i < writesLen; i++ {// 一个个写入本次事务操作的数据entry := tx.pendingWrites[i]// 在这里停顿一段时间,保证Rollback一定能并发执行到。time.Sleep(1 * time.Second)}return nil
}
来了来了他来了,他带着panic走来了。果然不出我所料。
问题修复
那么如何修复这个问题呢?我的想法是加入事务状态管理,还有对应的一些限制。
const (// txStatusRunning means the tx is runningtxStatusRunning = 1// txStatusCommitting means the tx is committingtxStatusCommitting = 2// txStatusClosed means the tx is closed, ether committed or rollbacktxStatusClosed = 3
)
如上面代码所见,加入三个状态,使用golang提供的atomic.Value进行原子操作修改事务状态。事务运行中txStatusRunning,事务提交中txStatusCommitting, 事务结束txStatusClosed。那么对应的限制应该是怎么样的呢?我认为有以下条件限制和状态转换:
- 不可提交已经结束的事务,也就是Commit完成,或者Rollback完成的事务。
- 不可Rollback已经结束的事务,也就是Commit完成,或者Rollback完成的事务。
- 不可提交正在提交中的事务。
- 不可Rollback正在提交中的事务。
- 事务Commit完成之后状态变成已结束
- 事务Rollback完成后状态变成已结束。
- 事务开始提交,状态改为Committing。
具体代码实现在这个PR中:https://github.com/nutsdb/nutsdb/pull/330。这里就不做具体代码分析了。仅做思路分享。另外后面可能会重构这部分代码,感觉写的还是有点粗糙的。。
总结
在看代码的时候要带着问题去看,他为什么这么实现的,会不会有什么潜在的问题。要是这部分让我来实现应该会怎么做。看代码的时候内心要始终持有一个想法,我们不是在看标准答案,只是在看一个参考实现,参考实现可能有错,甚至错误百出。另外有想法了也应该去验证它,在验证自己的想法之前,你永远不知道是自己错了还是代码错了。