环境:
浏览器: chrome 64
python 3.6
ps:python新手,写得不好求轻喷
ps:这是更加纯净的微博内容页面
思路步骤:
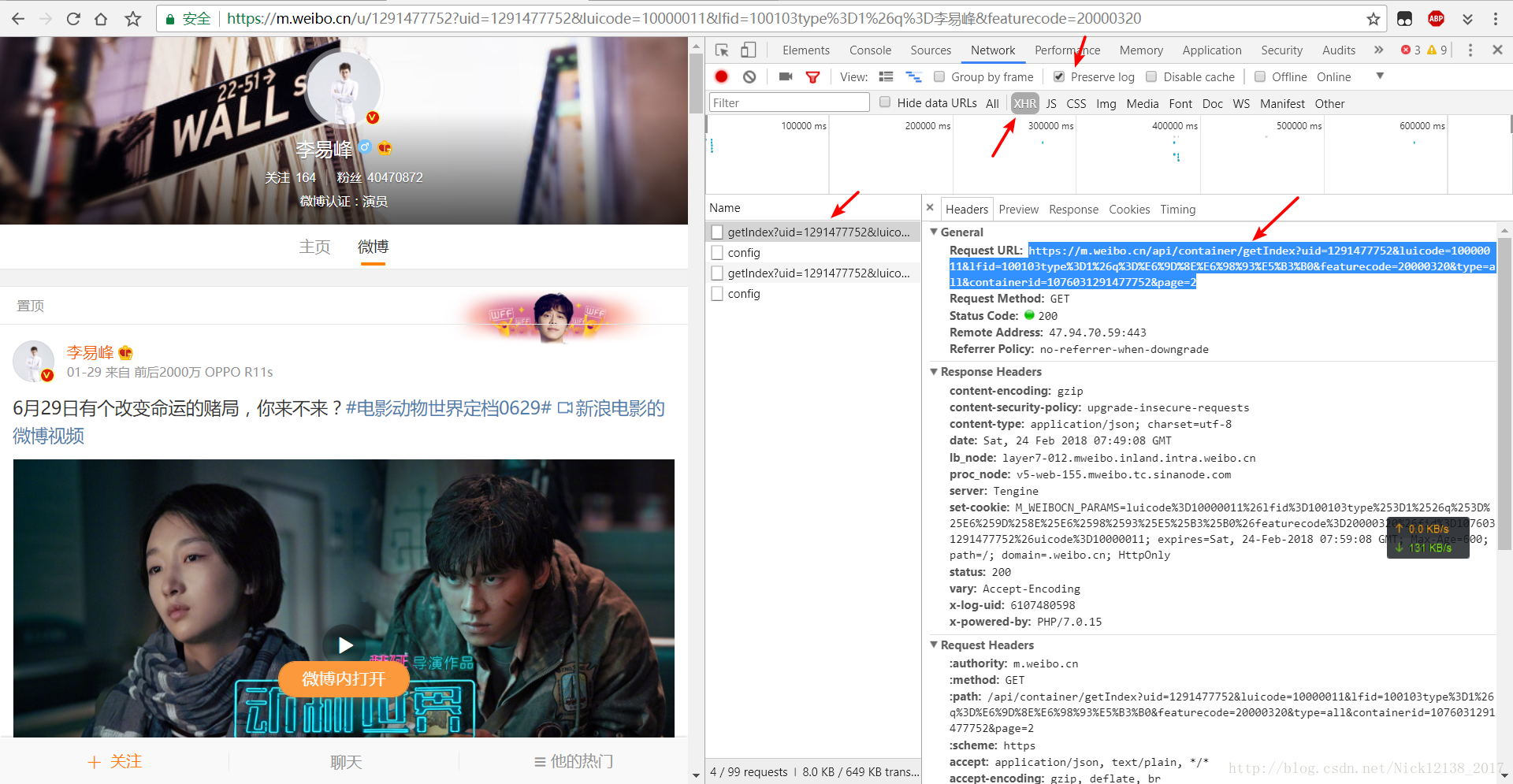
- 打开微博移动端网址并登录,
如 - 找到目标人物的微博,并按F12打开开发者模式,找到Network选项卡,勾选preserve log,类型选择XHR,下拉页面直至加载下一页,发现XHR中多了几项文件,打开图中的URL,如图
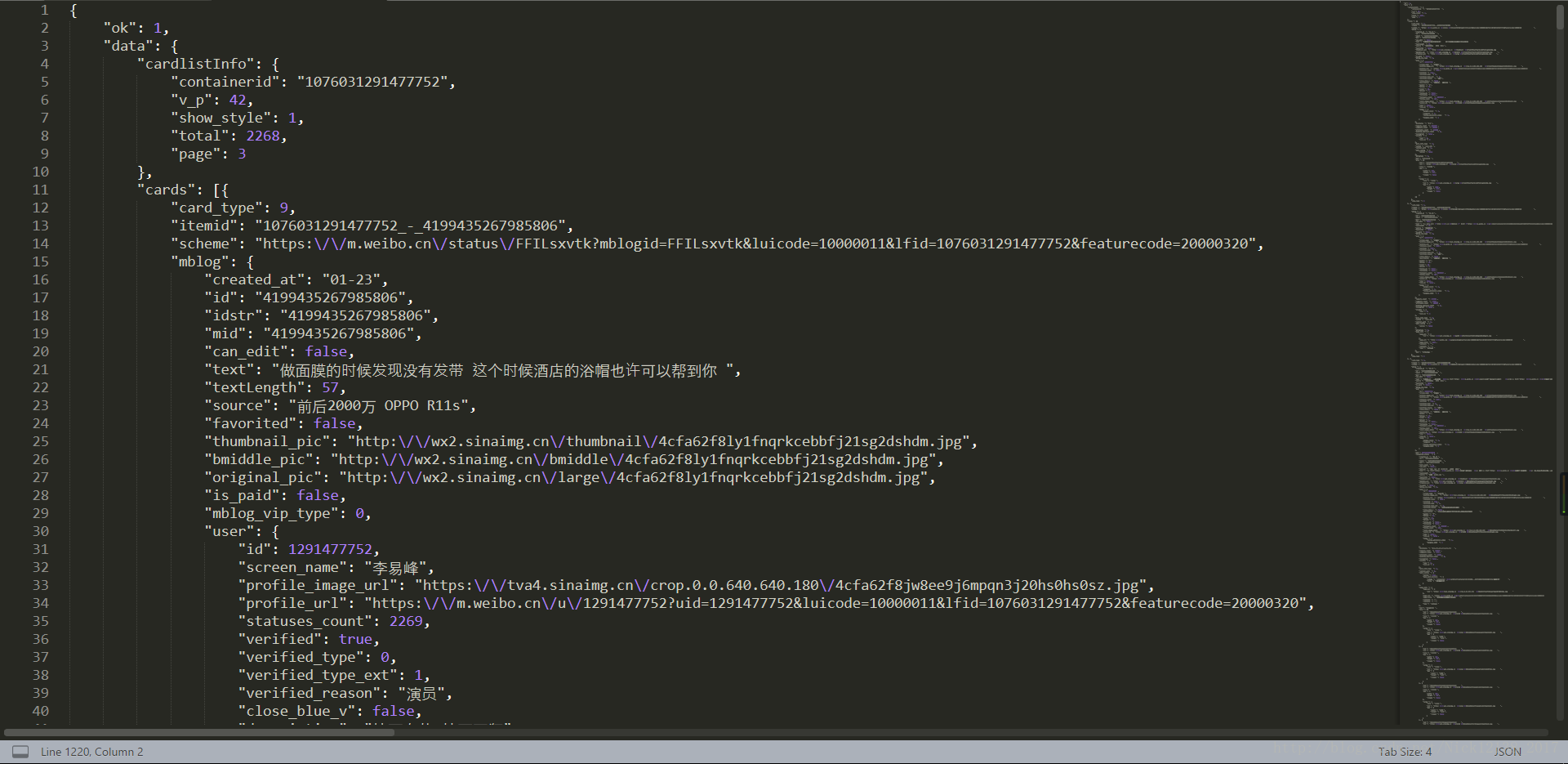
- 复制响应页面的内容,并用在线json工具解析可得
设该json为r,cards=r[‘data’][‘cards’]为微博列表,对cards中的每一个card,图片信息pics_info在card[‘mblog’][‘pics’],以此类推,获取到图片的URL之后就可以下载了

附上代码:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import threading
import time
import requests
from urllib.request import urlretrieve
import re
import json
import sys
import string
import os
import socket
import urllibbase_url="https://m.weibo.cn/api/container/getIndex?containerid=2304132331498495_-_WEIBO_SECOND_PROFILE_WEIBO&luicode=10000011&lfid=2302832331498495&featurecode=20000320&page_type=03&page={}"#半藏森林socket.getdefaulttimeout=30
pics_dir='D:/pics_origin/'def get_text(card):try:text=card['mblog']['text']except:return Noneelse:if '<' in text:text=re.findall(r'(.+?)<',text)[0]#偷懒只取了微博内容的前半部分text=re.sub(':',':',text)text=text.strip()return textdef get_cards(page):url=base_url.format(page)html=requests.get(url)r=html.json()cards=r['data']['cards']print(len(cards))return cardsdef save_pics(pics_info,text):i=0for pic_info in pics_info:pic_url=pic_info['large']['url']#原图#pic_url=pic_info['url']#低清图pic_path=pics_dir+text+'_%d.jpg'%iif os.path.exists(pics_dir+text+'_%d.jpg'%i):print(pics_dir+text+'_%d.jpg已存在'%i)i+=1continuetry:#下载图片with open(pic_path,'wb') as f:for chunk in requests.get(pic_url,stream=True).iter_content():f.write(chunk)#urlretrieve(pic_url,pics_dir+text+'_%d.jpg'%i)#except socket.timeout:# print(text+'_%d保存失败'%i)#except urllib.error.ContentTooShortError:# urlretrieve(pic_url,pics_dir+text+'_%d.jpg'%i)except:print(text+'_%d保存失败'%i)else:print(text+'_%d保存成功'%i)i+=1def check_dir():if not os.path.exists(pics_dir):os.mkdir(pics_dir)class MyThread(threading.Thread):def __init__(self,pics_info,text):threading.Thread.__init__(self)self.pics_info=pics_infoself.text=textdef run(self):save_pics(self.pics_info,self.text)check_dir()
page=1
while True:cards=get_cards(page)if len(cards)>1:threads=[]for card in cards:#下载每个card里面的图片text=get_text(card)try:pics_info=card['mblog']['pics']except:passelse:#save_pics(pics_info)thread=MyThread(pics_info,text)threads.append(thread)thread.start()for thread in threads:thread.join()page+=1time.sleep(1)else:break