比赛背景
想象一下,在失明发生之前就能够发现病变。数以百万计的人患有糖尿病性视网膜病变,这是导致老年人失明的主要原因。印度的Aravind眼科医院希望在农村地区的人们中发现并预防这种疾病,而那里的医疗筛查很难进行。目前,Aravind技术人员前往这些农村地区拍摄图像,然后依靠训练有素的医生对图像进行检查并提供诊断。因此kaggle举办了场比赛来加快疾病筛查。(本人排名:top6%,151/2987)
数据状况
图像为在各种成像条件下使用眼底摄影拍摄的大量视网膜图像。并由临床医生对每幅糖尿病视网膜病变的严重程度进行了0到4分的评分。
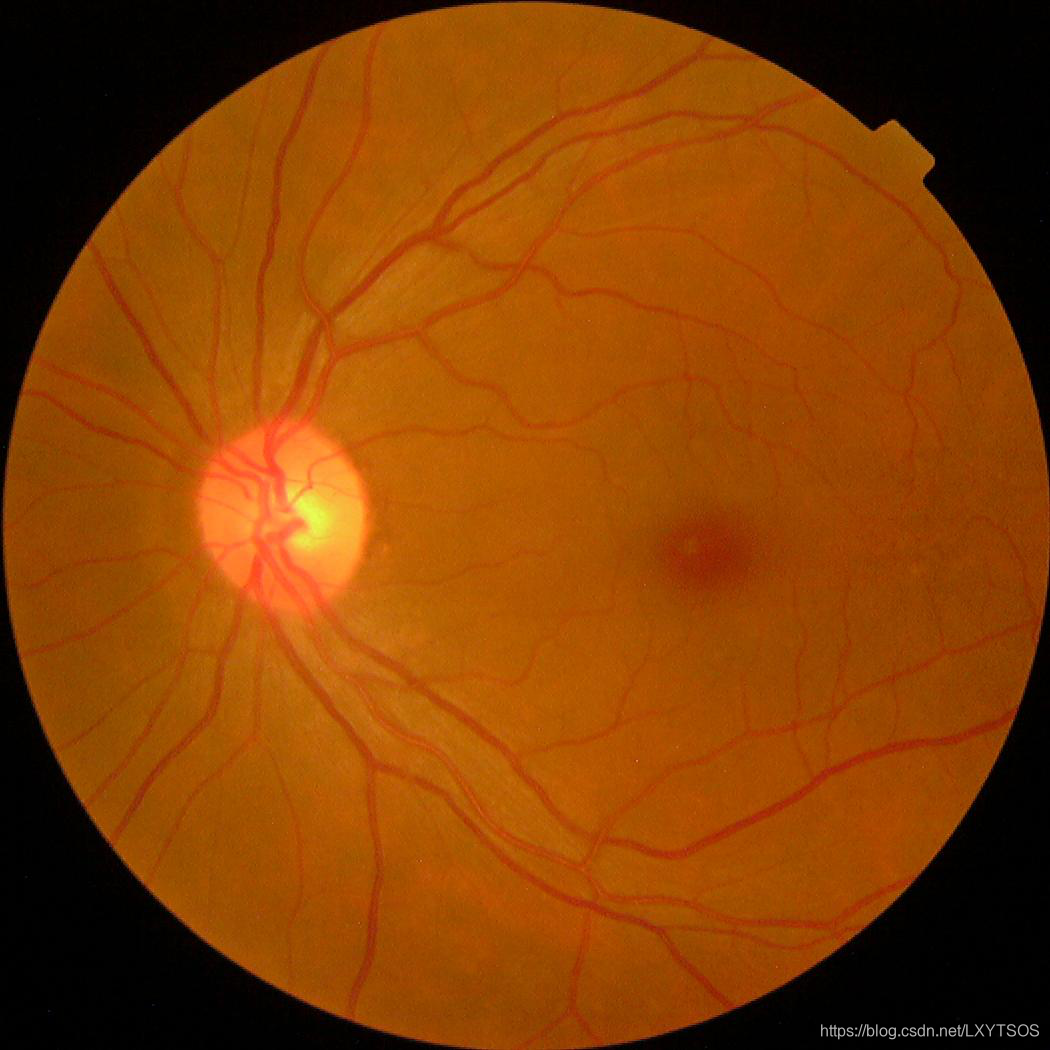
类别有5类,分别为:
0 - No DR
1 - Mild
2 - Moderate
3 - Severe
4 - Proliferative DR
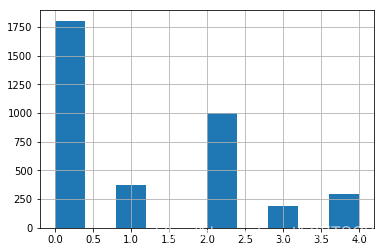
各个类别下的图片数目为:{0: 1805, 1: 370, 2: 999, 3: 193, 4: 295},如下图:
补充数据:https://www.kaggle.com/tanlikesmath/diabetic-retinopathy-resized,此数据来自于2015年的比赛:https://www.kaggle.com/c/diabetic-retinopathy-detection/
1st解决方案
验证策略
在早期阶段,作者使用2015年的数据(训练和测试数据)作为训练集,并用2019年的训练数据作为验证集,但是验证结果与LB相差比较大。因此作者将2015年和2019年的数据作为训练集,依靠LB结果来验证结果。
预处理
作者认为图像质量已经非常好了,不需要进行预处理,只是进行resize。
模型与输入大小
作者使用了集成学习的思想,使用了8个模型进行分类,并表示如果比赛还有两个星期的话,还会使用EfficientNets。作者使用的模型及输入大小如下:
2 x inception_resnet_v2, input size 512
2 x inception_v4, input size 512
2 x seresnext50, input size 512
2 x seresnext101, input size 384
作者观察了2015年的比赛发现更大的输入能取得更好的结果,但是作者发现输入大小超过384之后并没有带来多大性能提升。
损失函数
作者只使用了nn.SmoothL1Loss()作为损失函数,来简化集成学习过程。
数据增强
contrast_range=0.2,
brightness_range=20.,
hue_range=10.,
saturation_range=20.,
blur_and_sharpen=True,
rotate_range=180.,
scale_range=0.2,
shear_range=0.2,
shift_range=0.2,
do_mirror=True,
池化
对于最后一个池化层,作者发现广义平均池化(generalized mean pooling,https://arxiv.org/pdf/1711.02512.pdf) 效果比原始的平均池化效果好,代码地址:https://github.com/filipradenovic/cnnimageretrieval-pytorch。
from torch.nn.parameter import Parameter
def gem(x, p=3, eps=1e-6):return F.avg_pool2d(x.clamp(min=eps).pow(p), (x.size(-2), x.size(-1))).pow(1./p)
class GeM(nn.Module):def __init__(self, p=3, eps=1e-6):super(GeM,self).__init__()self.p = Parameter(torch.ones(1)*p)self.eps = epsdef forward(self, x):return gem(x, p=self.p, eps=self.eps) def __repr__(self):return self.__class__.__name__ + '(' + 'p=' + '{:.4f}'.format(self.p.data.tolist()[0]) + ', ' + 'eps=' + str(self.eps) + ')'
model = se_resnet50(num_classes=1000, pretrained='imagenet')
model.avg_pool = GeM()
训练和测试
训练过程可以分为两个阶段。
- 单独训练这8个模型通过public LB来验证。而为了得到更稳定的结果,作者将模型进行成对评估(每种模型都有2个,使用不同的随机种子)。作者减少超参数的自由度来减轻过拟合问题,比如,为了确定训练的最佳epoch数目,以5为步长来增加训练epoch数目。以下是第1阶段训练后的优化结果:
inceptionresnetv2 public: 0.831 private: 0.927
inception_v4 public: 0.826 private: 0.924
seresnext50 public: 0.826 private: 0.931
seresnext101 public: 0.819 private: 0.923 (the 2nd best result, missing the best)
ensemble public: 0.844 private: 0.934
- 将public测试数据添加伪标签,再使用另外两个数据集(Idrid和Messidor),将它们添加到训练集中。
2nd解决方案
数据
使用2015年的数据对模型进行预训练,public LB只有0.73~0.75.
使用2019年数据训练,2015年数据进行测试。
模型
作者使用了se-resnet50,se-resnet101,densenet,效果都不行,唯一效果好的网络是efficient-net,因此作者集成了efficient-net b3, b4, b5。
- b3图像尺寸:300
- b4图像尺寸:460
- b5图像尺寸:456
预处理
作者截取掉了图像中黑色的区域,然后只是对图像进行resize。
数据增强
作者使用了有生以来最多的数据增强操作:Blur, Flip, RandomBrightnessContrast, ShiftScaleRotate, ElasticTransform, Transpose, GridDistortion, HueSaturationValue, CLAHE, CoarseDropout。它们都来自于albumentations库。
训练
使用2015年的数据进行预训练模型(b3训练大概80轮,b5训练大概15轮),使用2019年的数据进行训练(b3训练大概50轮,b5训练大概15轮),选取表现最好的模型,然后把这两个模型的结果求均值。作者也使用了TTA。
秘方
作者对测试数据进行伪标签标注,然后使用训练数据+带伪标签的测试数据进行fine-tune网络,结果得到了巨大提升,因此作者进行了多次伪标签操作,同样,对2015年的测试数据也打上伪标签来增加训练数据。
(第3名解决方案截止本文发表时,还没有公布)
4th解决方案
预处理
截取掉黑色部分信息(训练和测试都采用),代码来自于这里:
def crop_image_from_gray(img,tol=7):if img.ndim ==2:mask = img>tolreturn img[np.ix_(mask.any(1),mask.any(0))]elif img.ndim==3:gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)mask = gray_img>tolcheck_shape = img[:,:,0][np.ix_(mask.any(1),mask.any(0))].shape[0]if (check_shape == 0): # image is too dark so that we crop out everything,return img # return original imageelse:img1=img[:,:,0][np.ix_(mask.any(1),mask.any(0))]img2=img[:,:,1][np.ix_(mask.any(1),mask.any(0))]img3=img[:,:,2][np.ix_(mask.any(1),mask.any(0))]# print(img1.shape,img2.shape,img3.shape)img = np.stack([img1,img2,img3],axis=-1)# print(img.shape)return img
数据增强
使用Dihedral, RandomCrop, Rotation, Contrast, Brightness, Cutout, PerspectiveTransform, Clahe。
模型
作者发现在大模型上使用高分辨率图像更容易过拟合,因此作者使用小模型配高分辨率图像或者大模型配低分辨率图像:
- EfficientNet-B7 (224x224) LB 0.840
- EfficientNet-B6 (240x240) LB 0.832
- EfficientNet-B5 (256x256) LB 0.831
- EfficientNet-B4 (320x320) LB 0.826
- EfficientNet-B3 (352x352) *LB Don’t Know
- EfficientNet-B2 (376x376) LB 0.828
使用5折交叉验证和TTA(8张图片,四个边角图片,然后再翻转)。
训练过程
在2015年所有数据(训练集和测试集)上预训练模型,轮数25轮,不进行验证,然后在2019年数据上进行5折交叉验证。
预测过程
使用5个模型+TTA(8张边角图片),只预处理图片一次来节省时间。
5th解决方案
模型
- efficientnet-b0
- efficientnet-b1
- efficientnet-b2
- efficientnet-b3
数据预处理和增强
- 截取掉黑色背景
- 图像大小:384 x 384
- 使用Fliplr, Flipud, Randomrotate(0, 360), zoom(1.0, 1.35)和自行设计的透视变换方法。
训练策略
- 五折交叉验证
- 不在2015年数据上预训练并在2019年数据上微调,而是将2015年和2019年数据结合起来训练模型,在2015年private test和2019年验证数据上进行验证。
- lr_schedule:Adam优化器,lrs=[5e-4, 1e-4, 1e-5, 1e-6],训练25轮,在[10, 16, 22]轮进行学习率衰减。
- 2*TTA
- threshold:[0.5, 1.5, 2.5, 3.5]
伪标签
- 作者认为伪标签是赢得比赛的关键,因为不知道2019年private test数据集的分布,所以将三份数据集(2015年数据,2019年训练数据和2019年public数据)结合起来训练模型,使模型能够识别这三种不同的数据分布。
- 作者没有使用2019年的public数据做伪标签样本,而是选择更高置信度的样本
- 伪标签降低了本地mse损失,提高了qwk值(二次加权Kappa)。
本人解决方法
2015年数据+2019年数据作为训练验证集,模型使用efficient-net b5,图像大小256,优化器使用了前段时间刚出的RAdam和Ranger。
小贴士
TTA
Test Time Augmentation,测试时增强,这里会为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中;然后对多个版本进行计算得到平均输出,作为图像的最终输出分数。这种做法在AlexNet的论文中就已经有了。在fast ai中可以通过以下方式实现:
preds, target = learn.TTA()
伪标签(pseudo label)
对于public test数据,使用训练数据训练出的模型对它进行预测,对于置信度高的样本,我们将预测结果作为它的“标签”——伪标签(又称软标签,soft label),然后将伪标签数据添加到训练数据中。
QWK(二次加权Kappa)
比赛使用QWK来评估结果,对于眼底图像识别,class=0为健康,class=4为疾病晚期非常严重,所以对于把class=0预测成4的行为所造成的惩罚应该远远大于把class=0预测成class=1的行为,使用quadratic的话将0预测成4所造成的惩罚就等于16倍的将0预测成1的惩罚。