什么是Stable Diffusion
Stable Diffusion 是在2022年发布的深度学习文本到图像生成模型。它主要用于根据文字的描述生成详细图像,尽管它也可以应用于其他任务,如内插绘制、外插绘制,以及在提示词(英语)指导下生成图生成图的翻译。
简单来说,就是AI画图,可以根据你的prompt生成对应的图片。
Stable Diffusion快速上手
github地址:https://github.com/camenduru/stable-diffusion-webui-colab
这里我们选择这一款模型,然后点击左边的lite

点击后会跳转到Goole的colab
什么是colab,可参考:https://blog.gm7.org/%E4%B8%AA%E4%BA%BA%E7%9F%A5%E8%AF%86%E5%BA%93/05.ai/02.bark%5B%E6%96%87%E5%AD%97%E8%BD%AC%E8%AF%AD%E9%9F%B3%5D/#%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE
点击左上角的启动图标启动即可,然后就是漫长的等待

[!TIP]
尽量选择稳定的网络,不然可能会经常断,每次断了就要重开,网上说每60秒模拟一次点击,试了下没用。
等所有命令都之行结束,会有一些web地址,点击即可到达对应的UI界面

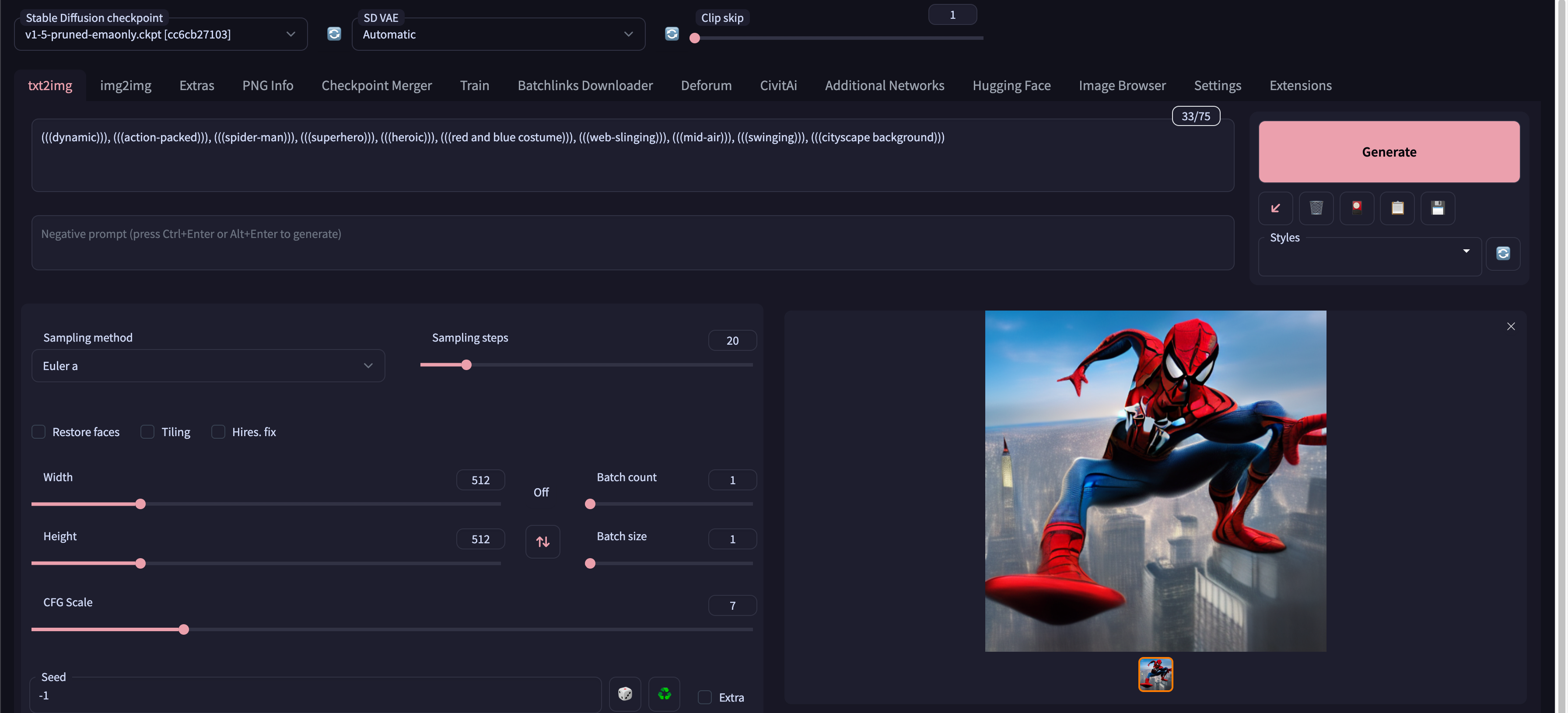
在文本框中输入prompt词即可生成对应的图片,如我这里生成的蜘蛛侠图片。
使用chatGPT生成Stable Diffusion的prompt
每次自己想prompt头都想破了,既然有AI,那就AI到底,通过AI来调教AI。
如果大家没有chatGPT账号,可以去 https://chat-shared1.zhile.io/shared.html 中体验一下
chatGPT的prompt如下:
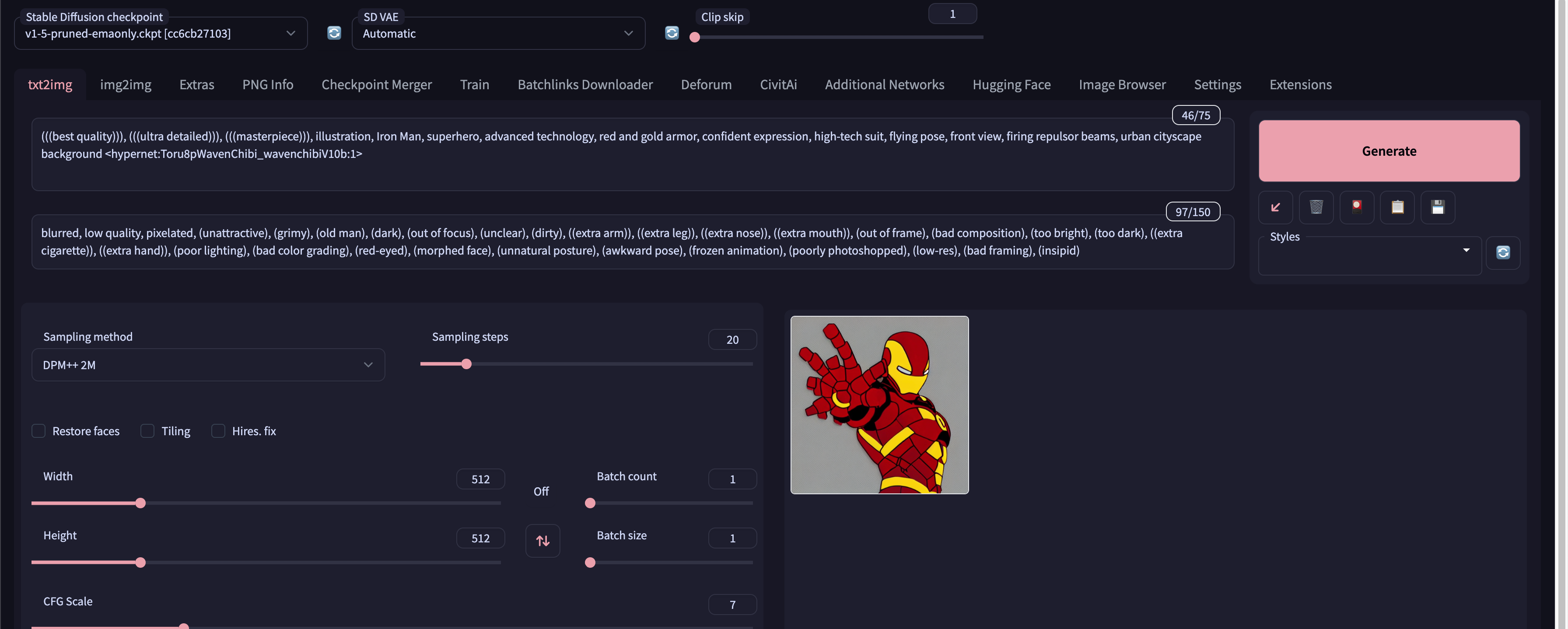
Stable Diffusion是一种利用深度学习的文生成图模型,支持使用提示词来生成新的图像,描述中包含或省略的元素。在Stable Diffusion算法中,引入了Prompt的概念,也被称为提示符。Prompt通常用于描述图像,由常见的单词构成,最好是可以在数据集来源站点(例如Danbooru)中找到的著名标签。接下来,我将解释生成Prompt的步骤,并以描述人物为例。在Prompt的生成过程中,你需要使用提示词来描述人物的属性、主题、外表、情绪、衣服、姿势、视角、动作和背景。你可以使用英语单词、短语甚至自然语言的标签来描述,不仅局限于我给你的单词。然后,将你希望相似的提示词组合在一起,使用英文逗号作为分隔符,并按从最重要到最不重要的顺序排列这些词。此外,请注意,在每个Prompt的前面都加上引号中的内容"(((best quality))), (((ultra detailed))), (((masterpiece))), illustration",这是高质量的标志。在人物属性中,"1girl"表示生成一个女孩,"2girls"表示生成两个女孩。另外,请注意,Prompt中不能包含连字符和下划线,可以包含空格和自然语言,但不要过多,避免单词重复。现在,请尝试生成一个钢铁侠的Prompt,尽可能提供更多的细节,包括人物属性、主题、外表、情绪、衣服、姿势、视角、动作和背景,并按照从最重要到最不重要的顺序排列。

Negative Prompt:
blurred, low quality, pixelated, (unattractive), (grimy), (old man), (dark), (out of focus), (unclear), (dirty), ((extra arm)), ((extra leg)), ((extra nose)), ((extra mouth)), (out of frame), (bad composition), (too bright), (too dark), ((extra cigarette)), ((extra hand)), (poor lighting), (bad color grading), (red-eyed), (morphed face), (unnatural posture), (awkward pose), (frozen animation), (poorly photoshopped), (low-res), (bad framing), (insipid)
试试效果:

高阶:载入第三方模型
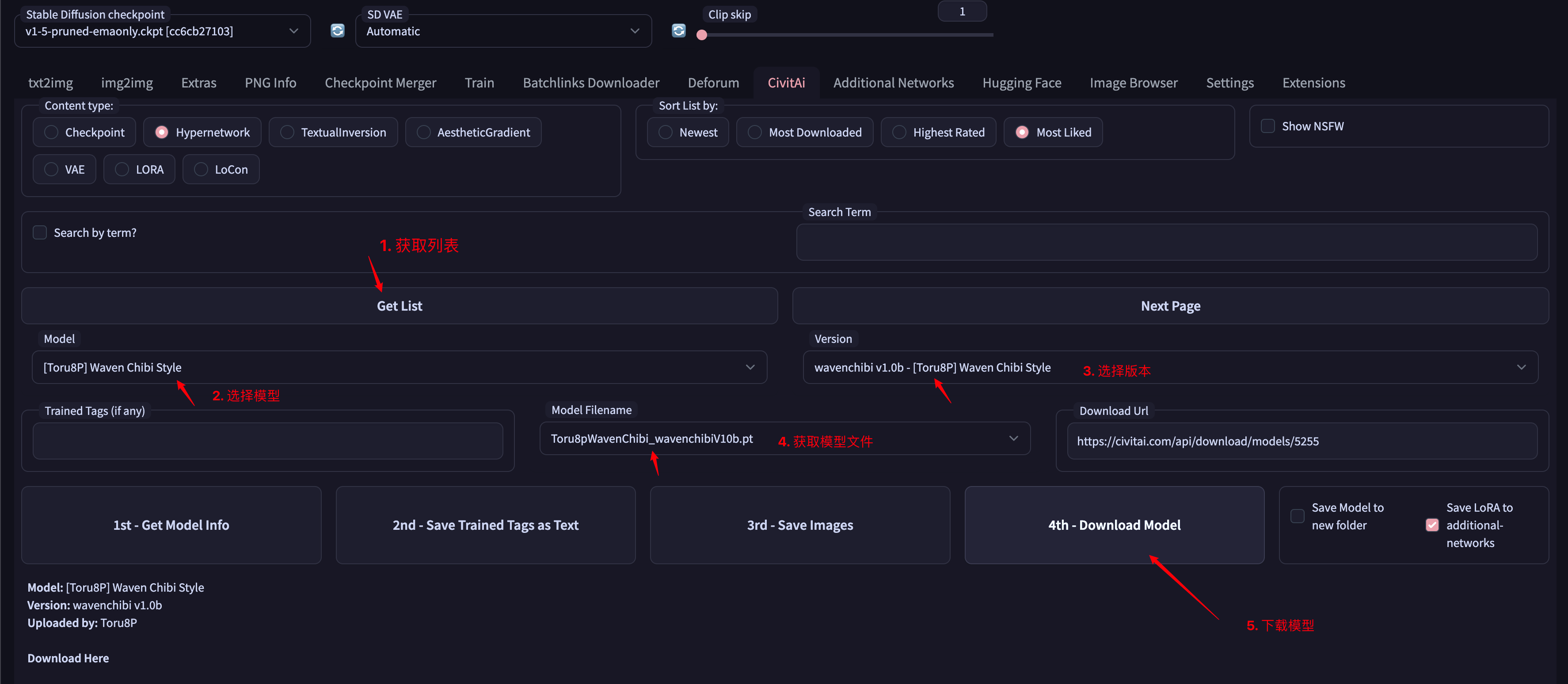
Stable Diffusion支持我们从CivitAi中加载一些模型,辅助修改生成图片的样式和内容。
举例如下:
首先下载模型
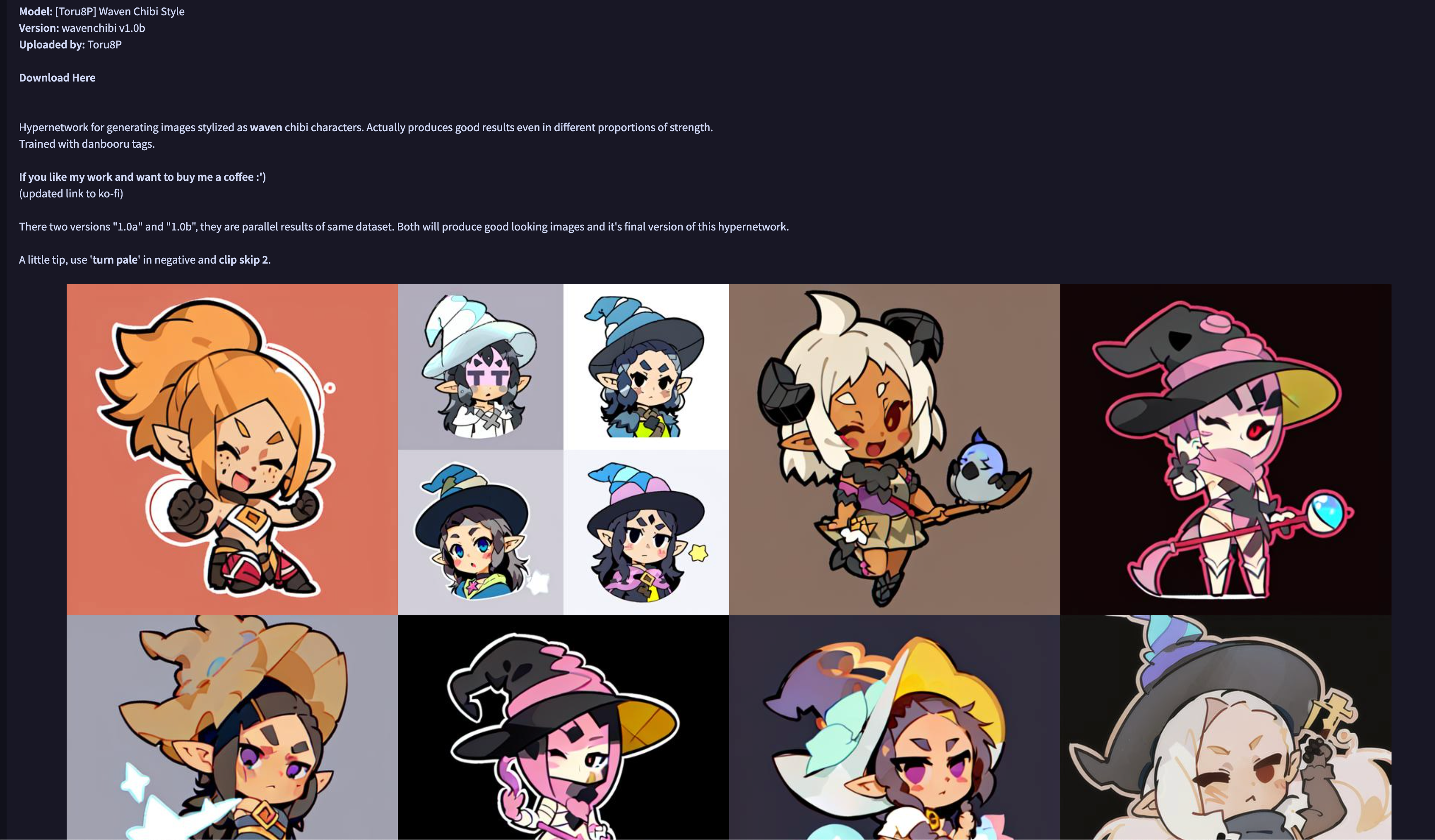
该模板的Demo如下:
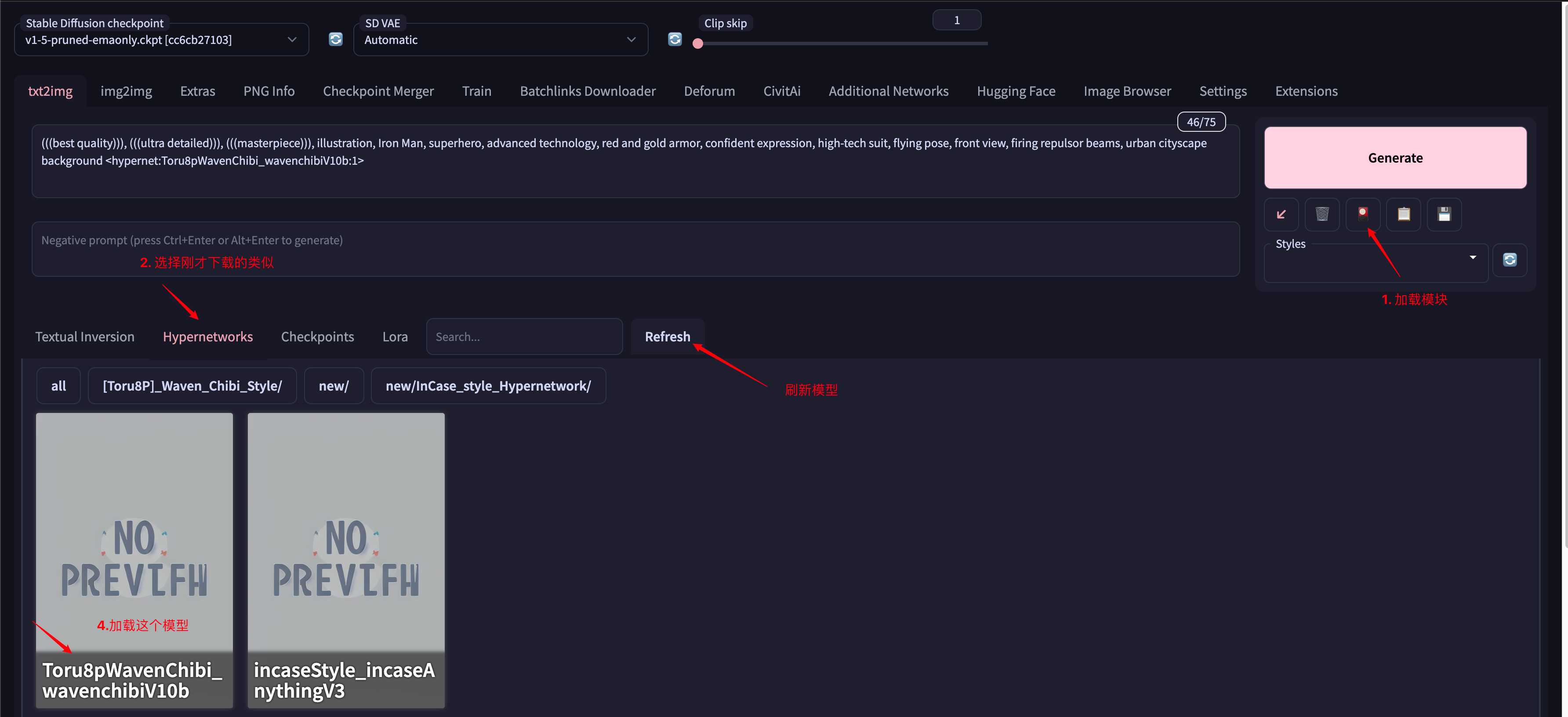
下载模型完成后,点击对应的模型即可加载改模型,可以在prompt最后看到
最终生成效果如下: