整体架构:
模型:yolox:目标检测车牌、LPRNet:识别车牌
数据集:CCPD2019、CCPD2020数据集
本算法,支持识别蓝盘和绿牌识别,黄牌因没有数据集,目前还不支持。算法不是调包,都是自己进行模型训练,到时候可以根据自己的数据集,进行训练。也可以更换检测模型
目录
- 效果展示
- 一、数据集
- 简介
- 1. CCPD数据集下载:
- 2. 数据集说明
- 3.CCPD数据集标注处理
- 4. CCPD数据集处理相关脚本
- 二、目标检测(车牌检测)
- 简介
- 1. 模型训练
- 1.1 模型训练结果
- 三、车牌识别(OCR)
- 简介
- 1. 模型结构介绍
- 2. 损失函数
- 2.1 torch.nn.CTCLoss()
- 一、简介
- 二、CTCLoss接口说明
- 三、应用实例:“CTCLoss在车牌识别中的应用”
- 四、使用注意
- 下载链接
效果展示
整体功能演示:
基于深度学习的车牌识别系统
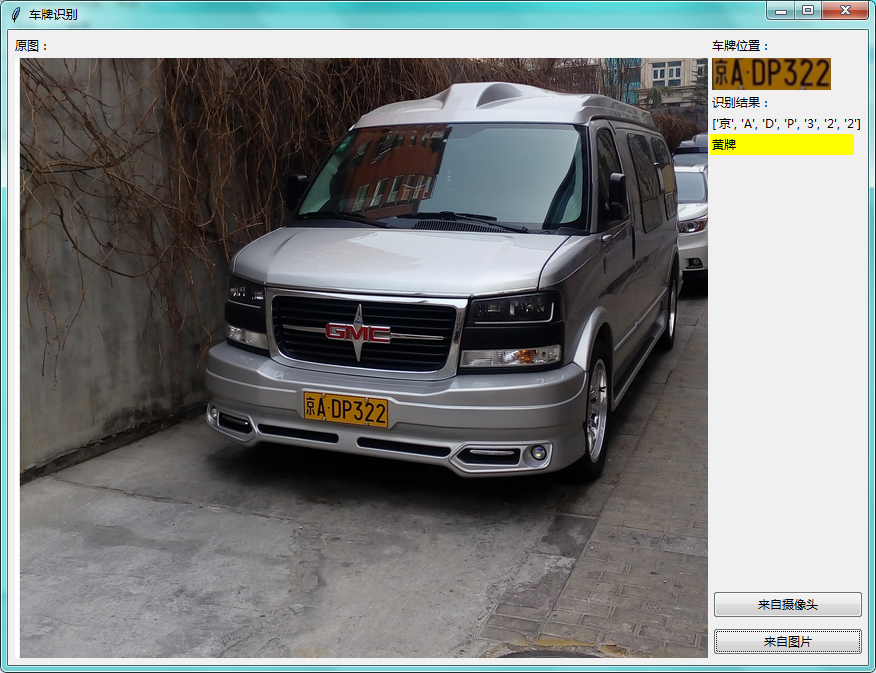
1. 识别单张图片
系统允许选择图片文件进行识别,点击图片选择按钮图标选择图片后,显示所有识别的结果,本功能的界面展示如下图所示:
识别单张图片
2. 识别文件夹下所有图片
系统允许选择整个文件夹进行识别,选择文件夹后,自动遍历文件夹下的所有图片文件,并将识别结果实时显示在右下角的表格中,本功能展示效果如下:
识别文件夹下所有图片
3. 识别视频
很多时候我们需要识别一段视频中的车牌,这里设计了视频选择功能。点击视频按钮可选择待检测的视频,系统会自动解析视频,逐帧识别多个车牌,并将结果记录在右下角表格中,效果如下图所示:
识别视频
4. 导出识别结果
本系统还添加了对识别结果的导出功能,方便后续查看,目前支持导出 csv 和 xls 两种数据格式,功能展示如下:
识别结果保存为csv、xls
下面是对代码中使用到的重点资源、知识点的详细介绍:
一、数据集
简介
CCPD是一个大型的、多样化的、经过仔细标注的中国城市车牌开源数据集。CCPD数据集主要分为CCPD2019数据集和CCPD2020(CCPD-Green)数据集。CCPD2019数据集车牌类型仅有普通车牌(蓝色车牌),CCPD2020数据集车牌类型仅有新能源车牌(绿色车牌)。
在CCPD数据集中,每张图片仅包含一张车牌,车牌的车牌省份主要为皖。
1. CCPD数据集下载:
(1)百度网盘下载链接(个人上传):
https://pan.baidu.com/s/1ZvbRUsPwpJk_39FujpjObw?pwd=nygt 提取码:nygt
(2)github下载:https://github.com/detectRecog/CCPD,github中包含详细的数据说明介绍
2. 数据集说明
CCPD2019中主要包含以下几个文件夹,
CCPD-Base:通用车牌图片,共200k
CCPD-FN:车牌离摄像头拍摄位置相对较近或较远,共20k
CCPD-DB:车牌区域亮度较亮、较暗或者不均匀,共20k
CCPD-Rotate:车牌水平倾斜20到50度,竖直倾斜-10到10度,共10k
CCPD-Tilt:车牌水平倾斜15到45度,竖直倾斜15到45度,共10k
CCPD-Weather:车牌在雨雪雾天气拍摄得到,共10k
CCPD-Challenge:在车牌检测识别任务中较有挑战性的图片,共10k
CCPD-Blur:由于摄像机镜头抖动导致的模糊车牌图片,共5k
CCPD-NP:没有安装车牌的新车图片,共5k
CCPD2020中的图像被拆分为train/val/test数据集。
3.CCPD数据集标注处理
CCPD数据集没有专门的标注文件,每张图像的文件名就是该图像对应的数据标注。例如图片3061158854166666665-97_100-159&434_586&578-558&578_173&523_159&434_586&474-0_0_3_24_33_32_28_30-64-233.jpg的文件名可以由分割符’-'分为多个部分:
(1)3061158854166666665:区域(这个值可能有问题,无用);
(2)97_100:对应车牌的两个倾斜角度-水平倾斜角和垂直倾斜角, 水平倾斜97度, 竖直倾斜100度。水平倾斜度是车牌与水平线之间的夹角。二维旋转后,垂直倾斜角为车牌左边界线与水平线的夹角。
(3)159&434_586&578:对应边界框左上角和右下角坐标:左上(159, 434), 右下(586, 578);
(4)558&578_173&523_159&434_586&474:对应车牌四个顶点坐标(右下角开始顺时针排列):右下(558, 578),左下(173, 523),左上(159, 434),右上(586, 474);
(5)0_0_3_24_33_32_28_30:为车牌号码(第一位为省份缩写),在CCPD2019中这个参数为7位,CCPD2020中为8位,有对应的关系表;
(6)64:为亮度,数值越大车牌越亮(可能不准确,仅供参考);
(7)233:为模糊度,数值越小车牌越模糊(可能不准确,仅供参考)。
4. CCPD数据集处理相关脚本
(1)CCPD数据集转VOC,xml文件保存
import shutil
import cv2
import osfrom lxml import etreeclass labelimg_Annotations_xml:def __init__(self, folder_name, filename, path, database="Unknown"):self.root = etree.Element("annotation")child1 = etree.SubElement(self.root, "folder")child1.text = folder_namechild2 = etree.SubElement(self.root, "filename")child2.text = filename# child3 = etree.SubElement(self.root, "path")# child3.text = pathchild4 = etree.SubElement(self.root, "source")child5 = etree.SubElement(child4, "database")child5.text = databasedef set_size(self, width, height, channel):size = etree.SubElement(self.root, "size")widthn = etree.SubElement(size, "width")widthn.text = str(width)heightn = etree.SubElement(size, "height")heightn.text = str(height)channeln = etree.SubElement(size, "channel")channeln.text = str(channel)def set_segmented(self, seg_data=0):segmented = etree.SubElement(self.root, "segmented")segmented.text = str(seg_data)def set_object(self, label, x_min, y_min, x_max, y_max,pose='Unspecified', truncated=0, difficult=0):object = etree.SubElement(self.root, "object")namen = etree.SubElement(object, "name")namen.text = labelposen = etree.SubElement(object, "pose")posen.text = posetruncatedn = etree.SubElement(object, "truncated")truncatedn.text = str(truncated)difficultn = etree.SubElement(object, "difficult")difficultn.text = str(difficult)bndbox = etree.SubElement(object, "bndbox")xminn = etree.SubElement(bndbox, "xmin")xminn.text = str(x_min)yminn = etree.SubElement(bndbox, "ymin")yminn.text = str(y_min)xmaxn = etree.SubElement(bndbox, "xmax")xmaxn.text = str(x_max)ymaxn = etree.SubElement(bndbox, "ymax")ymaxn.text = str(y_max)def savefile(self, filename):tree = etree.ElementTree(self.root)tree.write(filename, pretty_print=True, xml_declaration=False, encoding='utf-8')def translate(path, save_path):for filename in os.listdir(path):print(filename)list1 = filename.split("-", 3) # 第一次分割,以减号'-'做分割subname = list1[2]list2 = filename.split(".", 1)subname1 = list2[1]if subname1 == 'txt':continuelt, rb = subname.split("_", 1) # 第二次分割,以下划线'_'做分割lx, ly = lt.split("&", 1)rx, ry = rb.split("&", 1)print(lx, ly, rx, ry)results_xml = [['green', lx, ly, rx, ry]]img = cv2.imread(os.path.join(path, filename))if img is None: # 自动删除失效图片(下载过程有的图片会存在无法读取的情况)# os.remove(os.path.join(path, filename))continueheight, width, channel = img.shapesave_xml_name = filename.replace('jpg', 'xml')anno = labelimg_Annotations_xml('folder_name', filename + '.jpg', 'path')anno.set_size(width, height, channel)anno.set_segmented()for data in results_xml:label, x_min, y_min, x_max, y_max = dataanno.set_object(label, x_min, y_min, x_max, y_max)anno.savefile(os.path.join(save_path, save_xml_name))if __name__ == '__main__':# det图片存储地址img_path = r"E:\lg\BaiduSyncdisk\project\person_code\chepai_OCR\traindata\CCPD2020\ccpd_green\train"# det txt存储地址save_path = r"E:\lg\BaiduSyncdisk\project\person_code\yolox-pytorch\VOCdevkit\VOC2007\Annotations"translate(img_path, save_path)转换后的效果,labelimg打开:

(2)CCPD转LPR保存,用于OCR识别
import cv2
import os'''
1. 此种转换有缺点:CCPD车牌有重复,应该是不同角度或者模糊程度,重复的车牌,命名一样,会冲掉2. 支持绿牌,蓝牌数据集制作
'''roi_path = r'E:\lg\BaiduSyncdisk\project\person_code\chepai_OCR\traindata\CCPD2019\ccpd_base'
save_path = r'E:\lg\BaiduSyncdisk\project\person_code\chepai_OCR\traindata\LPR\11'provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W','X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X','Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']num = 0
for root, dirs, files in os.walk(roi_path):for filename in files:num += 1lpr_label = ""_, _, box, points, plate, brightness, blurriness = filename.split('-')print('plate:', plate)list_plate = plate.split('_') # 读取车牌for i, pla in enumerate(list_plate):if i == 0:lpr_label += provinces[int(pla)]elif i == 1:lpr_label += alphabets[int(pla)]else:lpr_label += ads[int(pla)]print(lpr_label)img_path = os.path.join(roi_path, filename)img = cv2.imread(img_path)assert os.path.exists(img_path), "image file {} dose not exist.".format(img_path)box = box.split('_') # 车牌边界box = [list(map(int, i.split('&'))) for i in box]xmin = box[0][0]xmax = box[1][0]ymin = box[0][1]ymax = box[1][1]crop_img = img[ymin:ymax, xmin:xmax]crop_img = cv2.resize(crop_img, (94, 24))cv2.imencode('.jpg', crop_img)[1].tofile(os.path.join(save_path, lpr_label + '.jpg'))
print("共生成{}张".format(num))转换后的结果(以名字保存图片):

二、目标检测(车牌检测)
简介
- 数据集:使用的是用上面CCPD数据集制作的VOC格式的数据集训练,包含蓝牌和绿牌,大约共20完张图片
- 模型:yolox
| 模型 | input-size | params(M) | map0.5 |
|---|---|---|---|
| yolox-s | 640*640 | 34.3 | 0.990 |
1. 模型训练
1.1 模型训练结果

三、车牌识别(OCR)
简介
- 数据集:使用的是上面CCPD制作的数据集
- 模型:LPRNet
| 模型 | input-size | params(M) | 准确率 |
|---|---|---|---|
| LPR-net | 94*24 | 1.7 | 0.995 |
1. 模型结构介绍
2. 损失函数
2.1 torch.nn.CTCLoss()
一、简介
CTC 的全称是Connectionist Temporal Classification,中文名称是“连接时序分类”,这个方法主要是解决神经网络label 和output 不对齐的问题(Alignment problem)。
优点:是不用强制对齐标签且标签可变长,仅需输入序列和监督标签序列即可进行训练,
应用场景:文本识别(scene text recognition)、语音识别(speech recognition)及手写字识别(handwriting recognition)等工程场景。
二、CTCLoss接口说明
第一步: 创建CTCLoss对象
ctc_loss = nn.CTCLoss(blank=len(CHARS)-1, reduction='mean')
参数说明:
(1) blank: 空白标签所在的label值,默认为0,需要根据实际的标签定义进行设定;
我们在预测文本时,一般都是有一个空白字符的,整个blank表示的就是空白字符在总字符集中的位置。
(2) reduction: 处理output losses的方式,string类型,可选’none’ 、 ‘mean’ 及 ‘sum’,'none’表示对output losses不做任何处理,‘mean’ 则对output losses (即输出的整个batch_size的损失做操作) 取平均值处理,‘sum’则是对output losses求和处理,默认为’mean’ 。
第二步: 在迭代中调用CTCLoss计算损失值
loss = ctc_loss(log_probs, targets, input_lengths, target_lengths)
参数说明:
(1)log_probs: shape=(T, N, C) 的模型输出张量,T: 表示输出的序列的长度; N: 表示batch_size值; C: 表示包含有空白标签的所有要预测的字符集总长度。
如:shape = (50, 32, 5000), 其中的50表示一幅图像最多有50个字, 32为batch_size, 5000表示整个数据集的字符集为5000个。
注: log_probs一般需要经过torch.nn.functional.log_softmax处理后再送入到CTCLoss中。
(2)targets: shape=(N, S) 或 (sum(target_lengths))的张量。其中对于第一种类型,N表示batch_size, S表示标签长度。
如:shape =(32, 50),其中的32为batch_size, 50表示每个标签有50个字符。
对于第二种类型,则为所有标签之和,也就是将所有的label合并成了一个1维的数据。
如: tensor([18, 45, 33, 37, 40, 49, 63, 4, 54, 51, 34, 53, 37, 38, 22, 56, 37, 38,33, 39, 34, 46, 2, 41, 44, 37, 39, 35, 33, 40])
注:targets不能包含空白标签。
(3)input_lengths: shape为(N)的张量或元组,但每一个元素的长度必须等于T即输出序列长度,一般来说模型输出序列固定后则该张量或元组的元素值均相同;
(4)target_lengths: shape为(N)的张量或元组,其每一个元素指示每个训练输入序列的标签长度,但标签长度是可以变化的;
如: target_lengths = [23, 34,32, … , 45, 34], 表示第一张图片的标签长度为23个字符,第2张图片的标签长度为34个字符。
三、应用实例:“CTCLoss在车牌识别中的应用”
(1)字符集:CHARS
CHARS = ['京', '沪', '津', '渝', '冀', '晋', '蒙', '辽', '吉', '黑','苏', '浙', '皖', '闽', '赣', '鲁', '豫', '鄂', '湘', '粤','桂', '琼', '川', '贵', '云', '藏', '陕', '甘', '青', '宁','新','0', '1', '2', '3', '4', '5', '6', '7', '8', '9','A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K','L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V','W', 'X', 'Y', 'Z', 'I', 'O', '-']
(2)创建CTCLoss对象
因为空白标签所在的位置为len(CHARS)-1,而我们需要处理CTCLoss output losses的方式为‘mean’,则需要按照如下方式初始化CTCLoss类:
ctc_loss = nn.CTCLoss(blank=len(CHARS)-1, reduction='mean')
设定输出序列长度T为18,训练批大小N为4,总的字符集长度C如上面CHARS所示为68:
(3)CTCLoss输入的解释
那么我们在训练一次迭代中打印各个输入形参得出如下结果:
1) log_probs由于数值比较多且为神经网络前向输出结果,我们仅打印其shape出来,如下:
torch.Size([18, 4, 68])
2) 打印targets如下,表示这四张车牌的训练标签,根据target_lengths划分标签后可分别表示这四张车牌:
tensor([18, 45, 33, 37, 40, 49, 63, 4, 54, 51, 34, 53, 37, 38, 22, 56, 37, 38,33, 39, 34, 46, 2, 41, 44, 37, 39, 35, 33, 40]).
共30个数字,因为,上图中的车牌号的实际长度依次为:(7, 8, 8, 7),共30个字符。
3) 打印target_lengths如下,每个元素分别指定了按序取targets多少个元素来表示一个车牌即标签:
(7, 7, 8, 8)
4) 打印input_lengths如下,由于输出序列长度T已经设定为18,因此其元素均是固定相同的:
(18, 18, 18, 18)
其中,只要模型配置固定了后,log_probs不需要我们组装再传送到CTCLoss,但是其余三个输入形参均需要我们根据实际数据集及C、T、N的情况进行设定!
四、使用注意
- 官方所给的例程如下,但在实际应用中需要将log_probs的detach()去掉,看注释行,否则无法反向传播进行训练;
如:
ctc_loss = nn.CTCLoss()
logits = lprnet(images)
log_probs = logits.permute(2, 0, 1) # for ctc loss: T x N x C
log_probs = log_probs.log_softmax(2).requires_grad_()
# log_probs = log_probs.detach().requires_grad_()
optimizer.zero_grad()# log_probs: 预测结果 [18, bs, 68] 其中18为序列长度 68为字典数
# labels: [93]
# input_lengths: tuple example: 000=18 001=18... 每个序列长度
# target_lengths: tuple example: 000=7 001=8 ... 每个gt长度
loss = ctc_loss(log_probs, labels, input_lengths=input_lengths, target_lengths=target_lengths)
-
blank空白标签一定要依据空白符在预测总字符集中的位置来设定,否则就会出错;
-
targets建议将其shape设为(sum(target_lengths)),然后再由target_lengths进行输入序列长度指定就好了,这是因为如果设定为(N, S),则因为S的标签长度如果是可变的,那么我们组装出来的二维张量的第一维度的长度仅为min(S)将损失一部分标签值(多维数组每行的长度必须一致),这就导致模型无法预测较长长度的标签;
-
输出序列长度T尽量在模型设计时就要考虑到模型需要预测的最长序列,如需要预测的最长序列其长度为I,则理论上T应大于等于2I+1,这是因为CTCLoss假设在最坏情况下每个真实标签前后都至少有一个空白标签进行隔开以区分重复项;
-
输出的log_probs除了进行log_softmax()处理再送入CTCLoss外,还必须要调整其维度顺序,确保其shape为(T, N, C)!
下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括训练代码、测试代码、训练数据、测试数据、视频,py、 UI文件等,如下图),这里已打包上传至博主的面包多平台,代码下载见下方可参考视频链接,已将所有涉及的文件同时打包,点击即可运行,完整文件截图如下:
参考视频链接:https://www.bilibili.com/video/BV1v8411D7Yg/?spm_id_from=333.999.0.0
注意:
该代码采用Pycharm+Python3.8开发,经过测试能成功运行,运行界面的主程序为main.py,另外提供测试脚本,数据转换脚本等,用到的所有程序。为确保程序顺利运行,请按照requirements.txt配置Python依赖包的版本。Python版本:3.8,为避免出现运行报错,请勿使用其他版本,详见requirements.txt文件;