视频理解学习笔记(二):I3D and Kinetics Dataset
- 视频理解的三个流派(怎么处理时序)
- 论文概览
- Kinetics Dataset
- 模型详解
- 将2D卷积网络扩张到3D(Inflating 2D ConvNets into 3D)
- 如何用预训练好的2D网络来初始化3D网络(Bootstrapping 3D filters from 2D Filters)
- 网络结构
- 实验
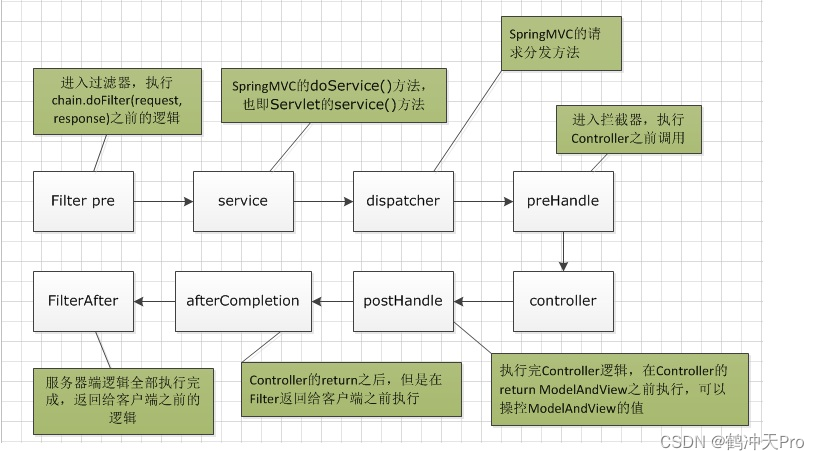
视频理解的三个流派(怎么处理时序)
- LSTM (a): ConvNet + LSTM
- 3D网络 (b): 3D-ConvNet
- 双流网络,利用光流 (c): Two-Stream
其他:
- 将3D和双流结合 (d): 3D-Fused
- I3D (e): Two-Sream I3D
论文概览
Workshop: CVPR’17
论文标题:Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
论文地址:https://arxiv.org/abs/1705.07750
论文作者:
- Joao Carreira from DeepMind
- Andrew Zisserman from DeepMind and Department of Engineering Science, University of Oxford (他也是双流网络的二作)
主要贡献:
- I3D:Two-Stream Inflated(扩大、膨胀)3D ConvNet,如何将2D模型扩大膨胀到3D模型。
- Kinetics Dataset
Kinetics Dataset
该数据集包括400个人类动作的类别,每个类别对应至少400的视频片段,且每个片段都来自不同的YouTube视频。每个视频片段(clip)都是10s。
模型详解
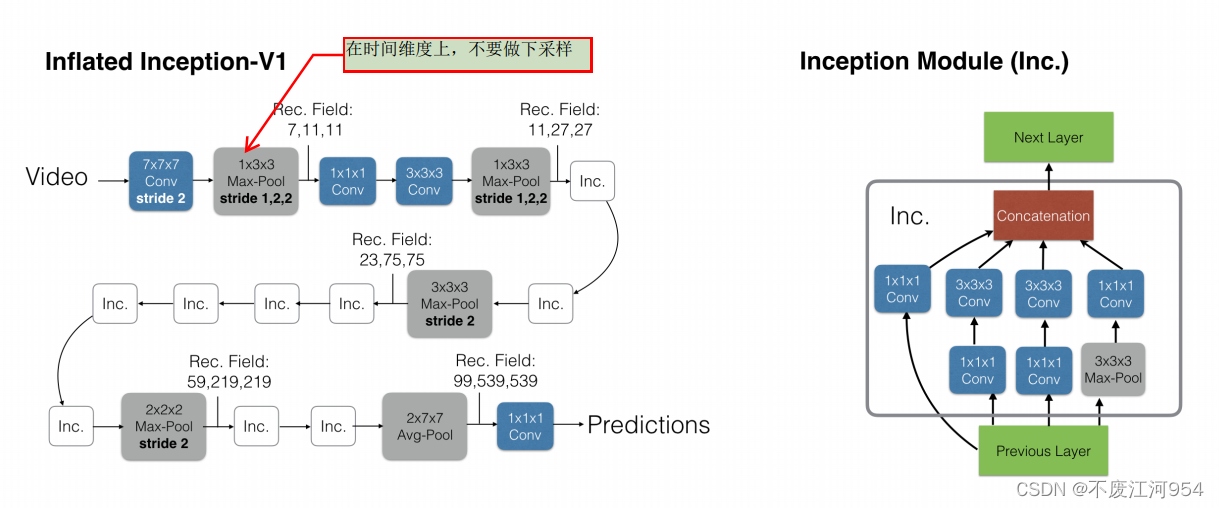
将2D卷积网络扩张到3D(Inflating 2D ConvNets into 3D)
Inflate:保持2D卷积网络框架,将2D的卷积核全部替换成3D的卷积核,将2D的pooling全部替换成3D的pooling。
如何用预训练好的2D网络来初始化3D网络(Bootstrapping 3D filters from 2D Filters)
bootstrap:引导
将2D图片重复n次获得一个n帧的boring video;将2D预训练好的模型的参数重复n次,并且rescale(即除以n,因为初始化要保证2D网络和3D网络面对同样的输入,可以得到同样的输出),赋给3D模型。
网络结构
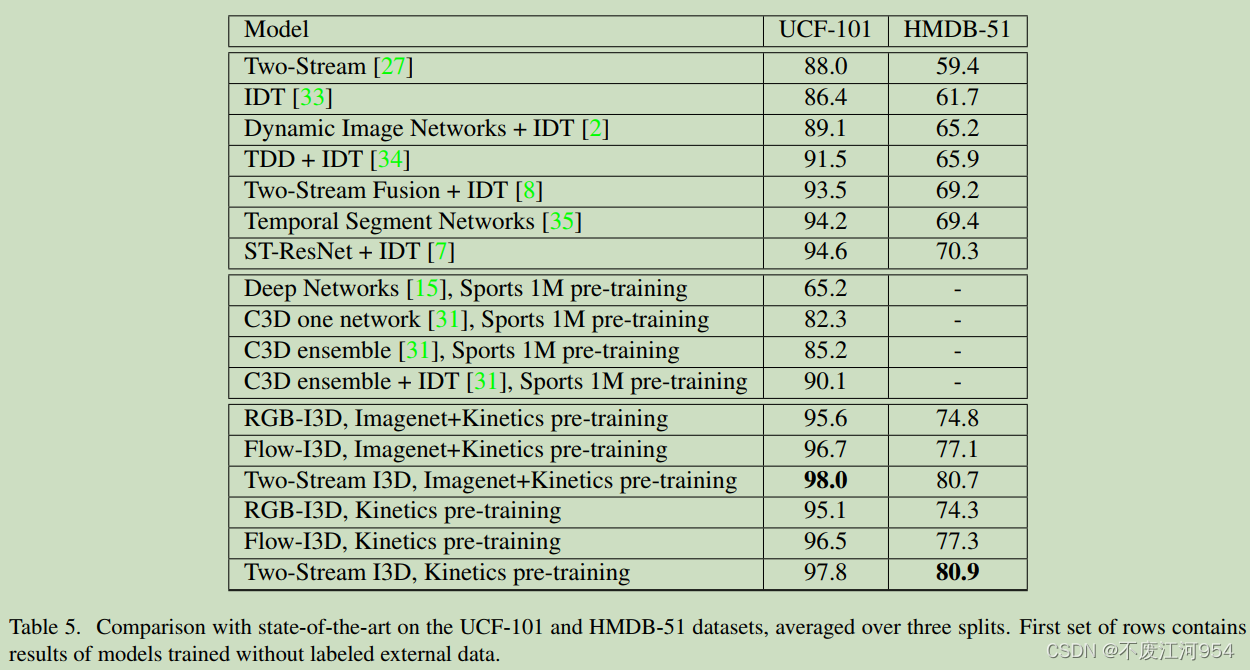
实验
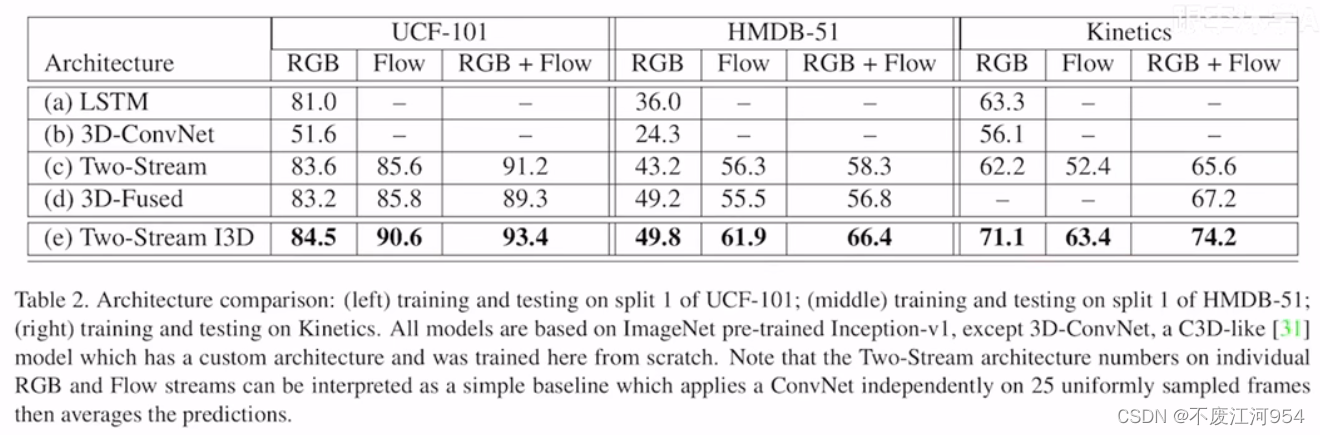
迁移学习实验效果:

肯定了预训练和迁移学习。
和其他方法对比: