RocketMQ 是阿里开源的分布式消息中间件,跟其它中间件相比,RocketMQ 的特点是纯JAVA实现
- 基础概念
Producer: 消息生产者,负责产生消息,一般由业务系统负责产生消息
Producer Group: 消息生产者组,简单来说就是多个发送同一类消息的生产者称之为一个生产者
Consumer: 消息消费者,负责消费消息,一般是后台系统负责异步消费
Consumer Group: 消费者组,和生产者类似,消费同一类消息的多个 Consumer 实例组成一个消费者组
Topic: 主题,用于将消息按主题做划分,Producer将消息发往指定的Topic,Consumer订阅该Topic就可以收到这条消息
Message: 消息,每个message必须指定一个topic,Message 还有一个可选的 Tag 设置,以便消费端可以基于 Tag 进行过滤消息
Tag: 标签,子主题(二级分类)对topic的进一步细化,用于区分同一个主题下的不同业务的消息
Queue: Topic和Queue是1对多的关系,一个Topic下可以包含多个Queue,主要用于负载均衡,Queue数量设置建议不要比消费者数少。发送消息时,用户只指定Topic,Producer会根据Topic的路由信息选择具体发到哪个Queue上。Consumer订阅消息时,会根据负载均衡策略决定订阅哪些Queue的消息
Dead-Letter Message: 死信队列用于处理无法被正常消费的消息。当一条消息初次消费失败,消息队列RocketMQ会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明Consumer在正常情况下无法正确地消费该消息。此时,消息队列RocketMQ不会立刻将消息丢弃,而是将这条消息发送到该Consumer对应的特殊队列中。
Offset: RocketMQ在存储消息时会为每个Topic下的每个Queue生成一个消息的索引文件,每个Queue都对应一个Offset记录当前Queue中消息条数
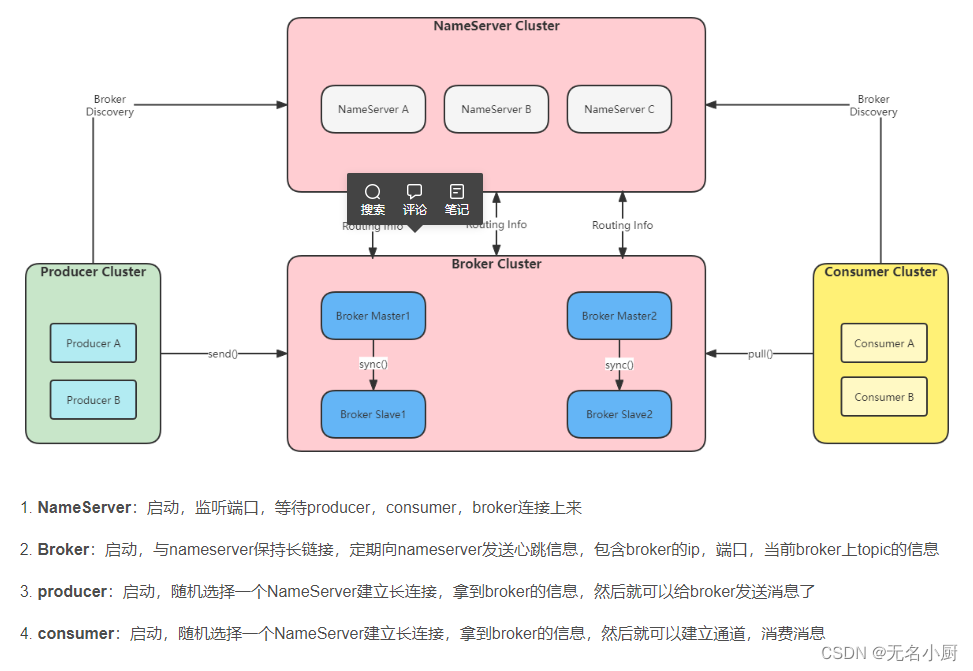
NameServer: NameServer可以看作是RocketMQ的注册中心,它管理两部分数据:集群的Topic-Queue的路由配置;Broker的实时配置信息。其它模块通过Nameserv提供的接口获取最新的Topic配置和路由信息;各 NameServer 之间不会互相通信, 各 NameServer 都有完整的路由信息,即无状态。
Broker: Broker是RocketMQ的核心模块,负责接收并存储消息,同时提供Push/Pull接口来将消息发送给Consumer。Broker同时提供消息查询的功能,可以通过MessageID和MessageKey来查询消息。Borker会将自己的Topic配置信息实时同步到NameServer - 基础架构
3为什么使用消息队列
常用场景有 4 个:异步解耦、削峰填谷,分布式事务一致性,大数据分析。
3.1 异步解耦
例如:交易系统作为淘宝和天猫主站最核心的系统,每笔交易订单数据的产生会引起几百个下游业务系统的关注,包括物流、购物车、积分、流计算分析等等,整体业务系统庞大而且复杂,消息队列RocketMQ可实现异步通信和应用解耦,确保主站业务的连续性。
3.2 削峰填谷
例如:每天 0:00 到 12:00,A 系统风平浪静,每秒并发请求数量就 50 个。结果每次一到 12:00 ~ 13:00 ,每秒并发请求数量突然会暴增到 5k+ 条。但是系统是直接基于 MySQL 的,大量的请求涌入 MySQL,每秒钟对 MySQL 执行约 5k 条 SQL。
一般的 MySQL,扛到每秒 2k 个请求就差不多了,如果每秒请求到 5k 的话,可能就直接把 MySQL 给打死了,导致系统崩溃,用户也就没法再使用系统了。但是高峰期一过,到了下午的时候,就成了低峰期,可能也就 1w 的用户同时在网站上操作,每秒中的请求数量可能也就 50 个请求,对整个系统几乎没有任何的压力。如果使用 MQ,每秒 5k 个请求写入 MQ,A 系统每秒钟最多处理 2k 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok,这样下来,哪怕是高峰期的时候,A 系统也绝对不会挂掉。
3.3 分布式事务一致性
交易系统、支付红包等场景需要确保数据的最终一致性,大量引入消息队列RocketMQ的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性。
3.4 大数据分析
数据在“流动”中产生价值,传统数据分析大多是基于批量计算模型,而无法做到实时的数据分析,利用阿里云消息队列RocketMQ与流式计算引擎相结合,可以很方便的实现业务数据的实时分析。
消息队列缺点:
(1)可用性降低
(2)系统复杂度提高
(3)一致性问题
相应解决方案