💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
1.1 场景分析概述
1.2 基于 LHS 的场景生成算法
1.3 基于 BR 的场景缩减算法
📚2 运行结果
🎉3 参考文献
🌈4 Matlab代码、数据、文章讲解

💥1 概述
文献来源:

风力发电具有无燃料成本、无污染等优点,是目前可再生能源研究和开发的重点之一。而受天然条件制约,风力的随机性和波动性是研究的难点。场景分析技术是表征风电出力的常见方法,包括场景生成与场景缩减两部分。场景生成根据研究对象的概率分布函数或统计特征,通过抽样来获得大量具有随机特征的场景。场景缩减通过数据分析减少相似场景的数量,降低计算复杂度。若能利用反映风速特征的场景生成方法准确生成大量场景,然后利用场景缩减方法,在保证精确性的同时减少相似场景的数量并得到相应的风电出力曲线,则将对电网规划设计、风电接纳能力评估、电源优化配置、储能规划及运行调度等具有重要意义。在场景生成的研究中,文献[4—5]利用蒙特卡
洛抽样法得到大规模风电场景集; 文献[6]采用反向传播( back propagation,BP) 神经网络对风电功率进行预测,进而生成风电出力的概率场景。此外,还有学者利用自回归滑动平均( auto-regressive and moving average,ARMA) 误差模型、非参数的概率预测等方法进行场景生成。场景生成的关键是保证生成的数据集能反映自身概率密度及总体特征。
在场景缩减的研究中,大多采用聚类分析法对相似场景进行缩减。文献[9]通过计算聚类有效性
指标,解决了传统 K-means 算法无法给出最佳聚类数的问题; 文献[10]针对待划分数据与聚类中心的距离等计算量大的部分,采用图形处理单元进行加速处理。此类方法对初始聚类中心要求高,且对离群点和噪声点敏感。另有研究人员使用 K-中心点聚类、分层聚类等方法进行场景缩减[11—12],此类方法步骤繁多,计算复杂,且分层聚类受奇异值的影响很大。
文中基于风速的不确定特性,建立基于拉丁超立方抽样( Latin hypercube sampling,
LHS) 与后向缩减法( backward reduction,BR) 的场景分析模型。
1.1 场景分析概述
在处理风电出力不确定性的研究中,广泛釆用 3 种方法: 模糊规划法、机会约束规划法以及场景分
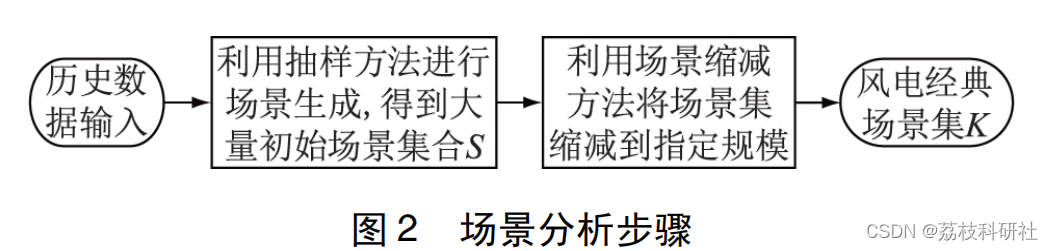
析方法[11]。文中采用场景分析法处理风电出力不确定性问题,场景分析主要分为场景生成和场景缩减 2 部分。场景生成是指根据研究对象的概率分布函数或统计特征,通过抽样等方法获得具有不确定性特征的大规模场景,可用集合 S = { S1,S2,…,SN } 表示。场景缩减则通过对集合 S 进行数据分析,减少相似场景数目,获得期望的场景数,降低计算复杂度。最终剩下的少量经典场景集可用集合K = {K1,K2,…,KM } 表示,该集合能较大程度地表征原始场景随机变量特性。具体过程如图 2 所示。
1.2 基于 LHS 的场景生成算法
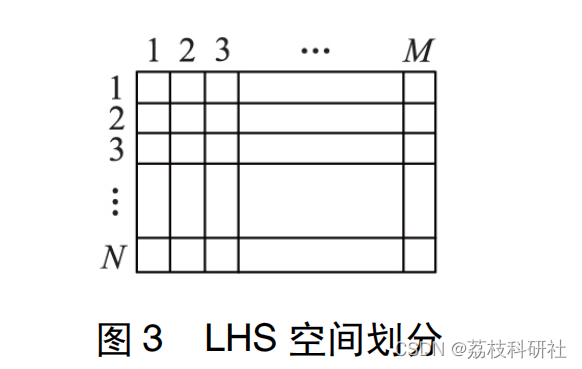
LHS 是一种分层抽样法,将一个大区间划分为若干个固定的小区间,每个小区间内只抽样 1 次。
假设对 N 维向量空间进行 M 次抽样,且对每一维进行的都是 0-1 均匀抽样,则可用 N%M 阶的矩阵 A 存储中间过程,用 N %M 阶的矩阵 B 存储样本点坐 标[17—19]。将 N 维向量空间中的每一维都等分成 M个区间,如图 3 所示。


1.3 基于 BR 的场景缩减算法
经 LHS 法得到的风速数据量庞大,各场景之间相似度很高。为更有效地将相近场景合并,文中基
于 BR 构建场景缩减模型[21—22],从而对大量数据进行处理。


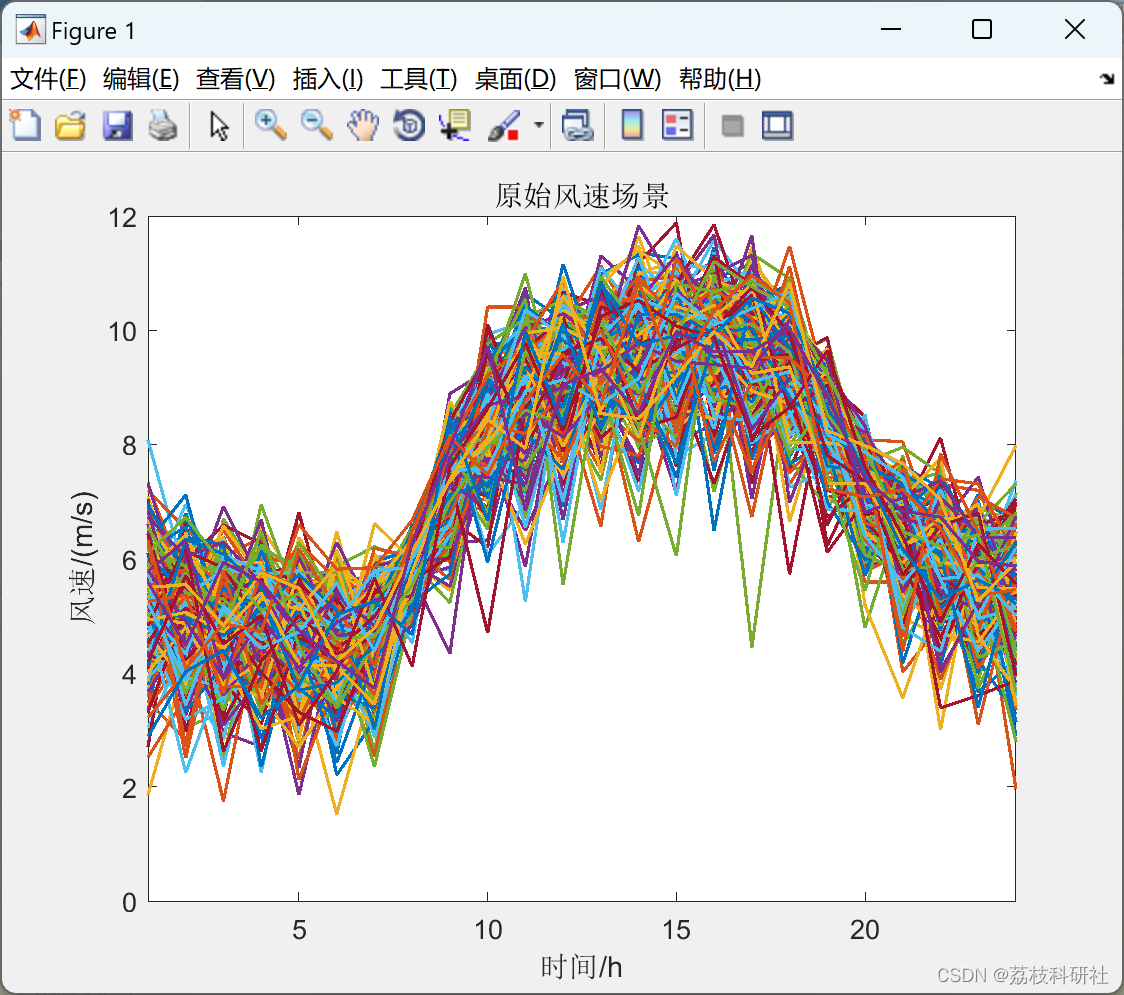
📚2 运行结果
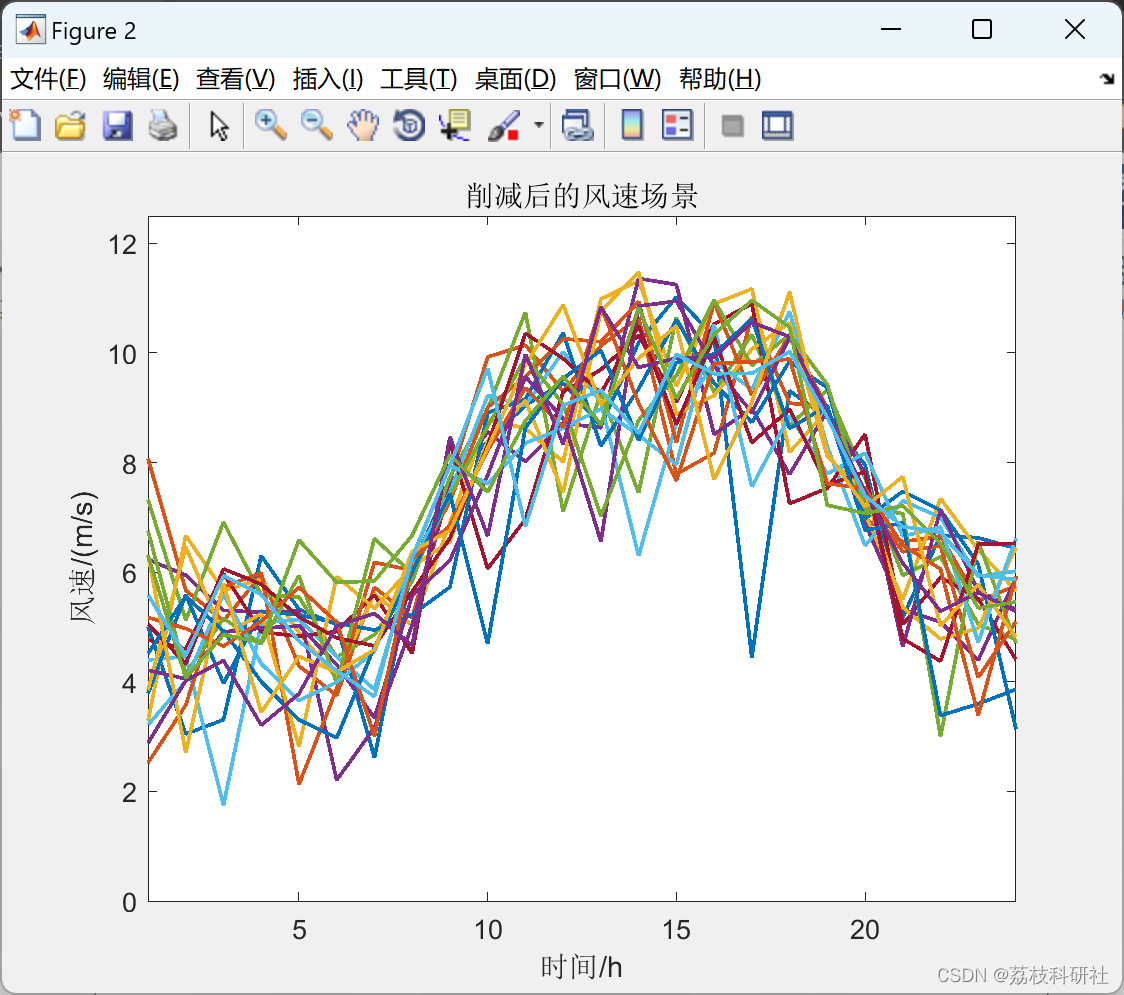
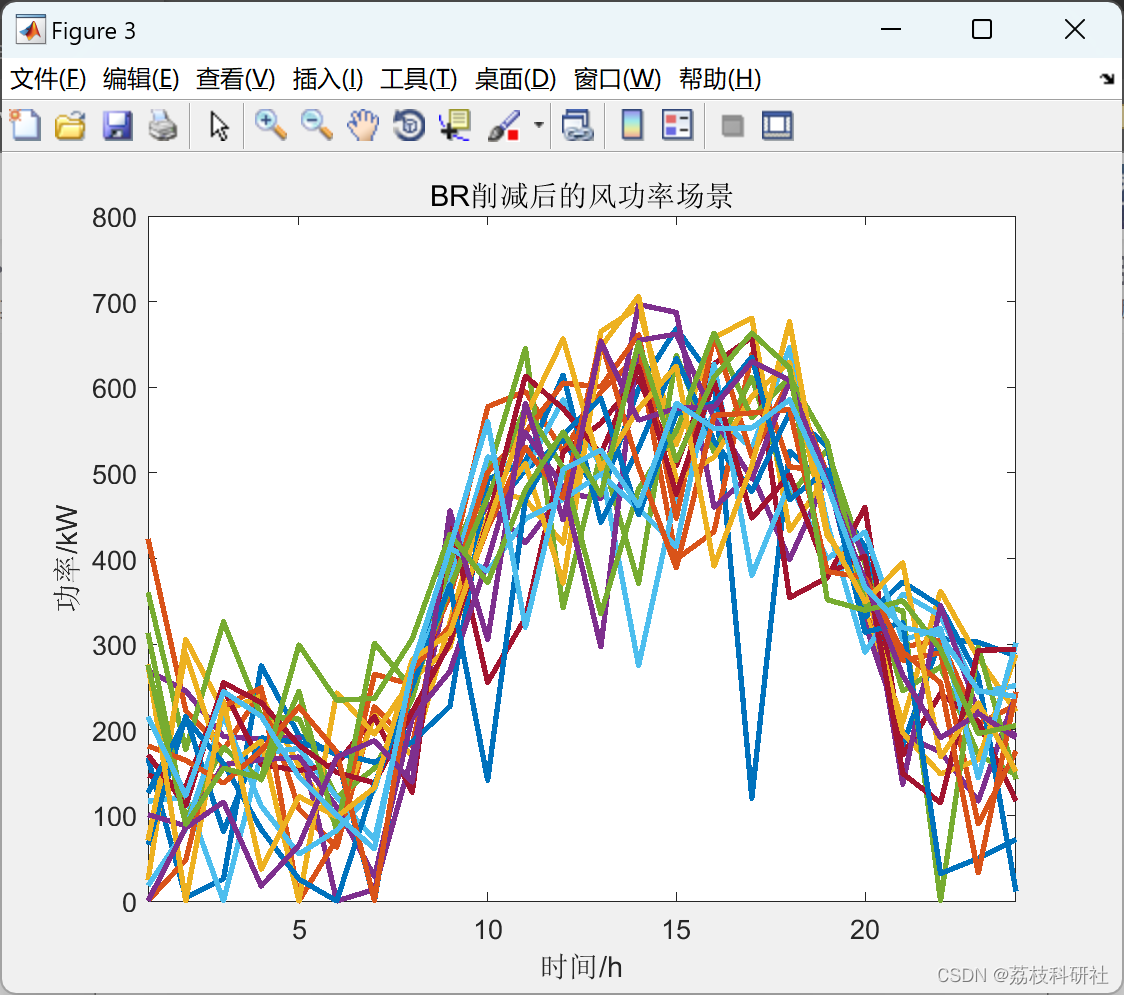
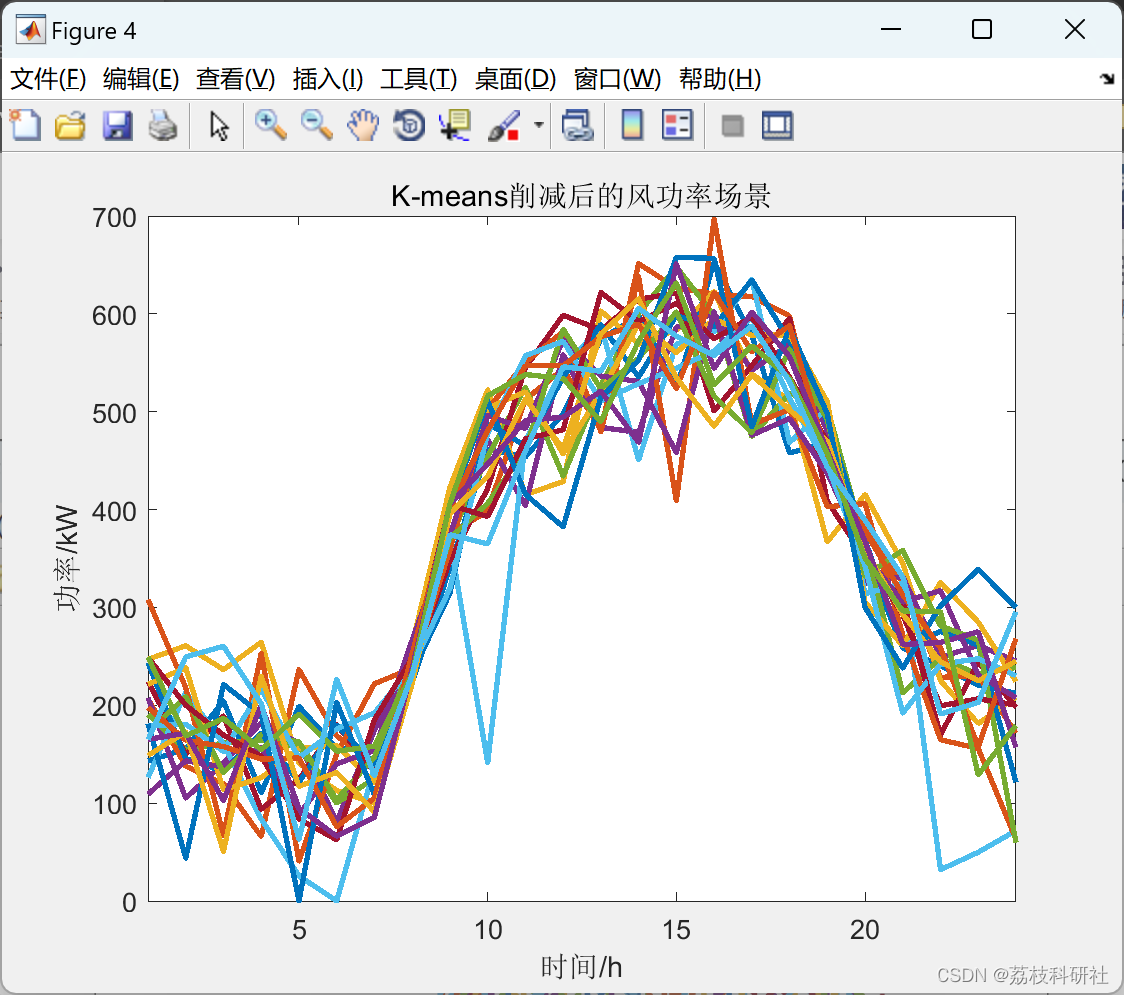
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]车兵,李轩,郑建勇等.基于LHS与BR的风电出力场景分析研究[J].电力工程技术,2020,39(06):213-219.






