1、背景介绍
泰坦尼克号沉船事件发生在1912年4月。泰坦尼克号是当时世界上最大的客运轮船,首航泰坦尼克号从英国南安普敦出发,途经法国瑟堡-奥克特维尔以及爱尔兰昆士敦,计划中的目的地为美国纽约。由于航行途中瞭望员没有及时发现前方的冰峰,船撞上冰峰发生船难。随后,泰坦尼克号沉没,2224名乘客和机组人员中有1502人遇难。沉船导致大量伤亡的原因之一是没有足够的救生艇给乘客和船员。一些人可能比其他人更有可能生存,比如妇女,儿童和上层阶级,但,幸存下来的因素研究及讨论一直没有停止过。
2、数据集说明
数据集来自Kaggle2,包括泰坦尼克号上 2224 名乘客和船员中 891 名的人口学数据和乘客基本信息。分析其中的数据,探索生还率和某些因素的关系,什么样的人在泰坦尼克号中更容易存活?
决策树算法依据对一系列属性取值的判定得出最终决策。在每个非叶子节点上进行一个特征属性的测试,每个分支表示这个特征属性在某个值域上的输出,而每个叶子节点对应于最终决策结果。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点对应的类别作为决策结果。算法的目的是产生一棵泛化性能强,即处理未见数据能力强的决策树。
数据集共有891行、12列。每条数据有12个特征,含义如下:
• PassengerId => 乘客ID
• Survived => 获救情况(1为获救,0为未获救)
• Pclass => 乘客等级(1/2/3等舱位)
• Name => 乘客姓名
• Sex => 性别
• Age => 年龄
• SibSp => 堂兄弟/妹个数
• Parch => 父母与小孩个数
• Ticket => 船票信息
• Fare => 票价
• Cabin => 客舱
• Embarked => 登船港口
数据下载地址:https://www.kaggle.com/hesh97/titanicdataset-traincsv。
3、具体要求
1、数据清理
a)查看数据行列情况,判断是否有空行,进行删除;
b)查看空值情况,按照自己分析的需求及考虑进行删除或填充操作;
from pandas import DataFrame,Series
import pandas as pd
import numpy as np
#导入混淆矩阵
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
names=['PassengerId','Survived','Pclass','Name','Sex','Age','SibSp','Parch','Ticket','Fare','Cabin','Embarked']
titanic = pd.read_csv("train.csv",header=None,names=names)
print(titanic)
print("判断空行数量:",titanic.isnull().T.all().sum())
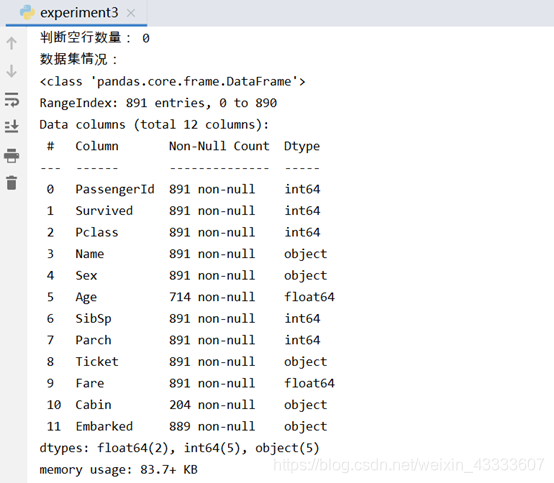
print("数据集情况:")
titanic.info()#对年龄用均值填充
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].mean())
#将登船港口拿众数填充,默认使用第一个众数值
titanic["Embarked"] = titanic["Embarked"].fillna(titanic["Embarked"].mode()[0])
#删除缺失值较多无法使用的属性
titanic.drop(['Cabin'],axis=1,inplace=True)
print("对数据集空值处理后的情况:")
titanic.info()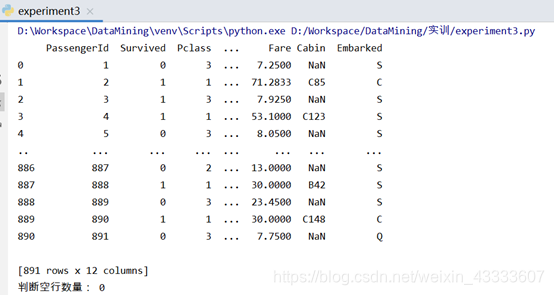
 实验结果分析:
实验结果分析:
由数据集信息可知,Age、Cabin、Embarked存在空值,其中属性Cabin缺失值过多,对后续分析用处不大,因此此处删除数据,属性Embarked仅有两个空缺值,可采用众数填充,默认选用第一个众数,属性Age数值型数据,采用均值对空缺值进行填充。对空值处理后效果为:
 2、使用可视化方法,判断哪些属性对幸存影响大
2、使用可视化方法,判断哪些属性对幸存影响大
思路:要想对数据进行分析,首先需要对数据预处理,对于此数据集,先将字符型数据进行数值化,由于属性年龄、票价差距太大,因此统一对数据进行标准化处理。
#数据集预处理——数值化
lables = ["Name","Sex","Ticket","Embarked"]
#可以知道字符型的有5列
i = 0
while(i<4):y_flag = titanic[lables[i]].unique()titanic[lables[i]] = titanic[lables[i]].apply(lambda x : y_flag.tolist().index(x))i = i+1
print(titanic.head())
#原因属性
x = titanic.iloc[:,2:]
# print(x)
#目标属性
y = titanic["Survived"]
X_lables = x.columns
print(X_lables)
#将数据集进行标准化处理
from sklearn.preprocessing import StandardScaler
standard = StandardScaler()
#对所有数据进行特征化处理
X = standard.fit_transform(x)
X = DataFrame(X,columns=X_lables)
print(X.head())数据预处理后效果:
 分别将两个目标类被救和未被就区分开,画出柱状图
分别将两个目标类被救和未被就区分开,画出柱状图
# 找到类别都为0 的
cond_0 = y == 0
cond_1 = y == 1
#获取到类别为0的Pclass的数据
az = plt.subplot(1,1,1)
X['Pclass'][cond_0].plot(kind='hist',bins=100,density = True)
X['Pclass'][cond_1].plot(kind='hist',bins=10,density = True,alpha = 0.8)
az.set_title("乘客等级")
plt.show()
# 使用循环,将10中类别画出来
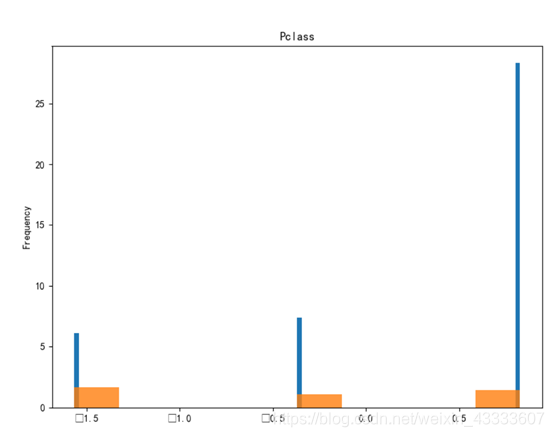
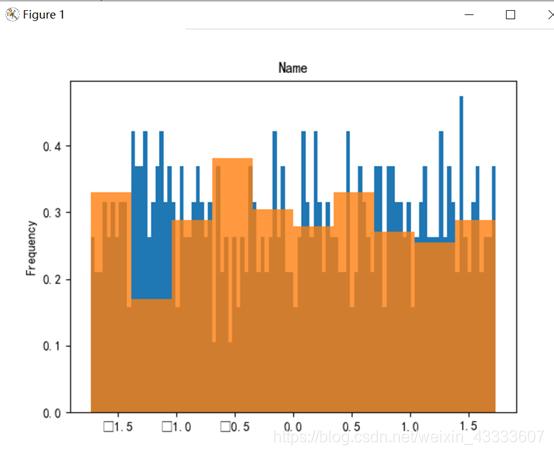
plt.figure(figsize=(9, 10 * 4))
for i in range(0, 9):ax = plt.subplot(111)X[X_lables[i]][cond_0].plot(kind='hist', bins=100, density=True, ax=ax)X[X_lables[i]][cond_1].plot(kind='hist', bins=10, density=True, ax=ax, alpha=0.8)# 添加标题ax.set_title(X_lables[i])plt.show()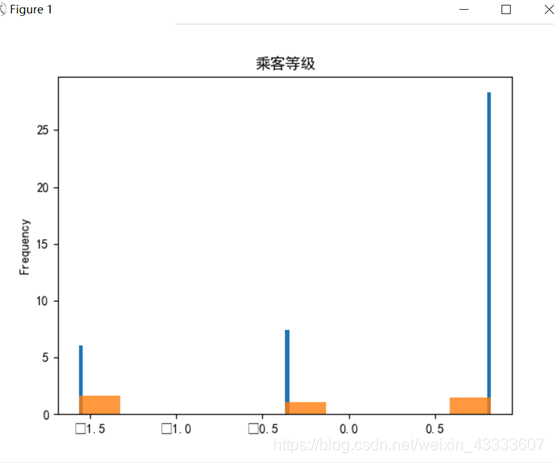
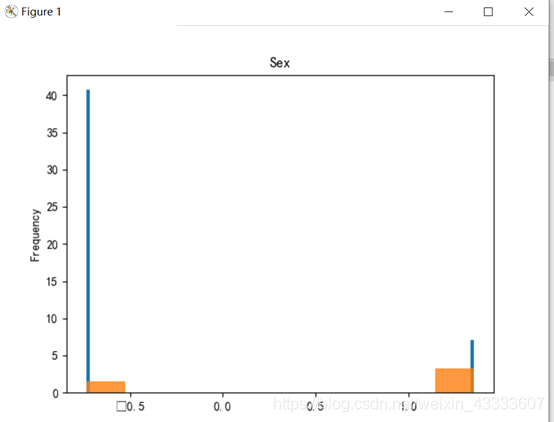
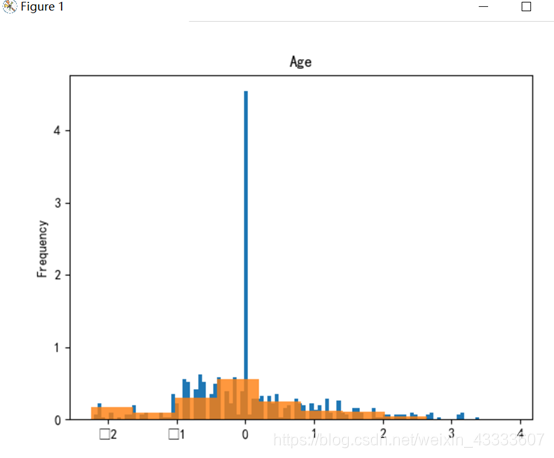
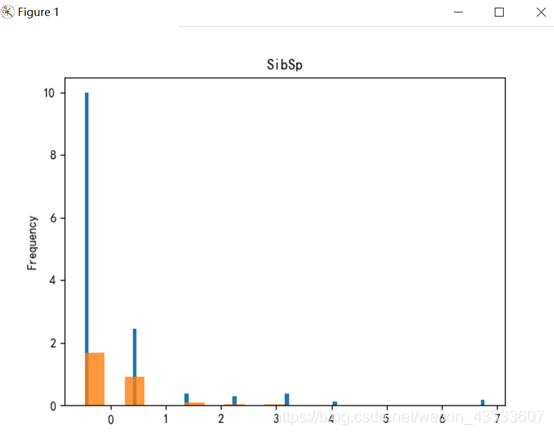
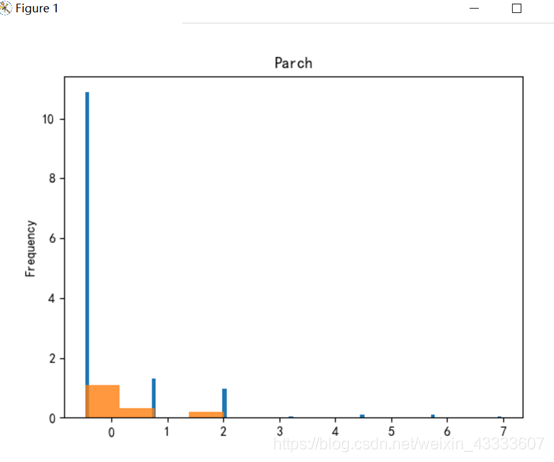
 实验结果分析:
实验结果分析:
由实验结果可知,属性Name、Ticket重合度较高,分辨价值较低,在判别是否与被救有关系上作用不大。
利用GBDT梯度提升决策树进行特征重要性排序:
#将以上得出作用不大的列删除
droplabels = ["Name","Ticket"]
X2 = X.drop(droplabels,axis=1)
# print(X2.head())
from sklearn.ensemble import GradientBoostingClassifiergbdt = GradientBoostingClassifier()
gbdt.fit(X2,y)
print(gbdt.feature_importances_)
argsort = gbdt.feature_importances_.argsort()[::-1]
print(argsort)
plt.figure(figsize=(8,5))
plt.bar(np.arange(7),gbdt.feature_importances_[argsort])
_ = plt.xticks(np.arange(9),X2.columns[argsort])
plt.show()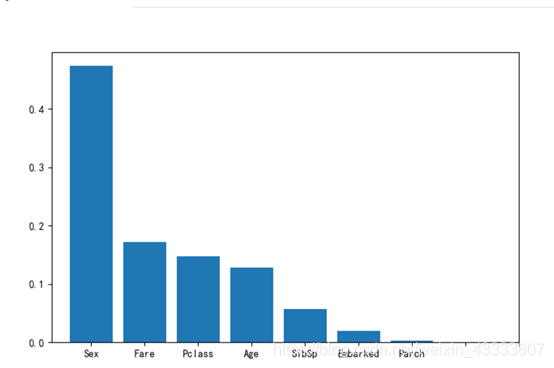 用GBDT进行梯度提升决策树后得出的结果来看,属性Parch、Embarked、Sibsp对是否被就分辨率较低,因此可忽略这些属性,综合以上结果可得出,属性Sex、Fare、Pclass以及Pclass对判断是否幸存的影响大。
用GBDT进行梯度提升决策树后得出的结果来看,属性Parch、Embarked、Sibsp对是否被就分辨率较低,因此可忽略这些属性,综合以上结果可得出,属性Sex、Fare、Pclass以及Pclass对判断是否幸存的影响大。
3、设计两个以上决策树分类模型实验,进行比较,并说明设计的理由。
使用信息熵作为依据创建决策树:
#使用决策树
from sklearn import tree
#数据集转换成训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 创建决策树对象,使用信息熵作为依据
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(X_train,y_train)
print("准确率:",clf.score(X_test,y_test))
#生成混淆矩阵,查看召回率
y_ = clf.predict(X_test)
#先生成一个混淆矩阵
cm = confusion_matrix(y_test,y_)
plot_confusion_matrix(cm,classes=[0,1])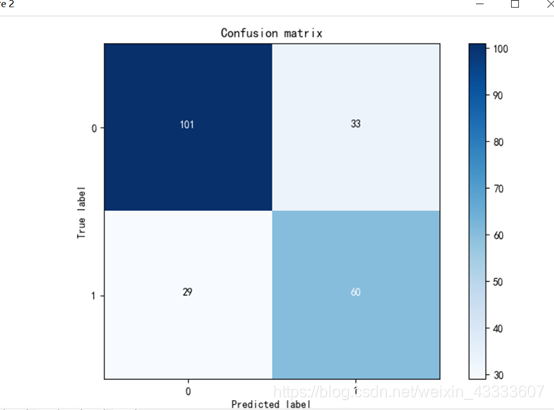
 基尼指数作为依据创建决策树:
基尼指数作为依据创建决策树:
# #使用GINi指数
clfg = tree.DecisionTreeClassifier(criterion='gini')
clfg.fit(X_train,y_train)
print("GINI指数作为依据的准确率",clfg.score(X_test,y_test))
#生成混淆矩阵,查看召回率
y_ = clfg.predict(X_test)
#先生成一个混淆矩阵
cm = confusion_matrix(y_test,y_)
plot_confusion_matrix(cm,classes=[0,1])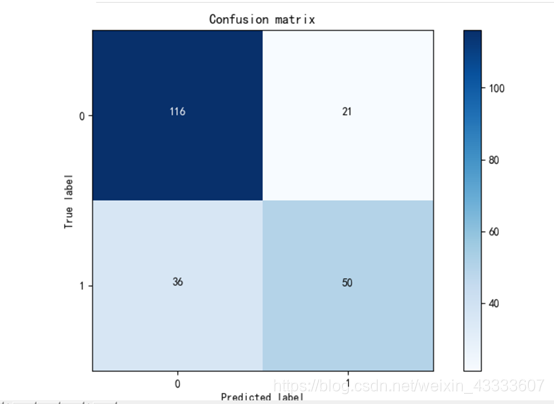
 实验结果分析:
实验结果分析:
通过分别使用信息熵和基尼指数作为依据构建决策树,在使用信息熵作为依据的决策树中准确率达77.1%,召回率达67.0%,在使用基尼指数作为依据的决策树中准确率达74.4%,召回率达58.1。因此我们可以选择以信息熵为依据构建决策树。
4、在此分析中,选择模型评估度量,并说明理由
使用循环来调整决策树参数:
i = 2
recall = []
accuracy = []
plt.figure(figsize=(24,27))
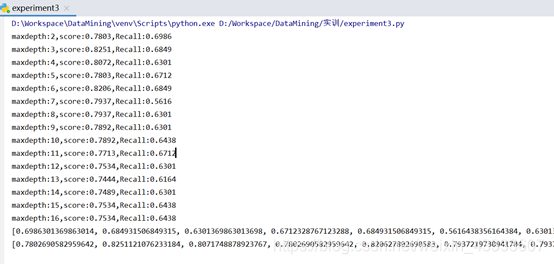
#让最大深度为16while(i<17):clf = tree.DecisionTreeClassifier(criterion='entropy',max_depth=i)clf.fit(X_train,y_train)#生成混淆矩阵,查看召回率y_ = clf.predict(X_test)#先生成一个混淆矩阵cm = confusion_matrix(y_test,y_)# print("****************")# print(cm)# print("****************")print('maxdepth:%d,score:%0.4f,Recall:%0.4f'%(i,(cm[0,0]+cm[1,1])/cm.sum(),cm[1,1]/cm[1].sum()))recall.append(cm[1,1]/cm[1].sum())accuracy.append((cm[0,0]+cm[1,1])/cm.sum())plot_confusion_matrix(i,cm,classes=[0,1])i = i + 1
plt.show()
print(recall)
print(accuracy)
plt.plot(np.arange(2,17),recall,color = 'green')plt.plot(np.arange(2,17),accuracy,color='red')
plt.show()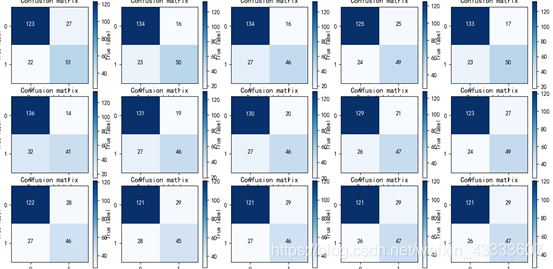
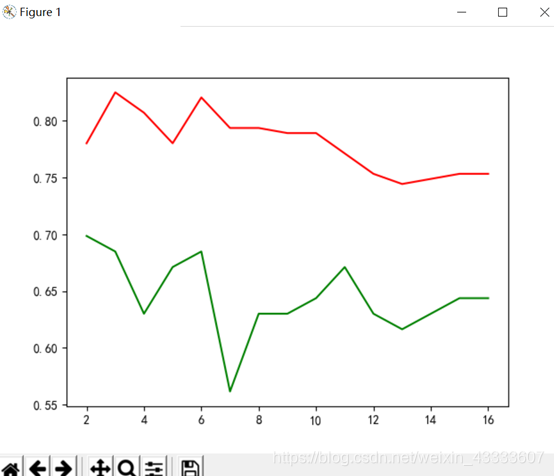 实验结果分析:
实验结果分析:
有实验结果可得出当最大深度为3是准确率达到最大值0.8251,此时召回率只有0.6849,看似准确率及召回率均达到了最大值。
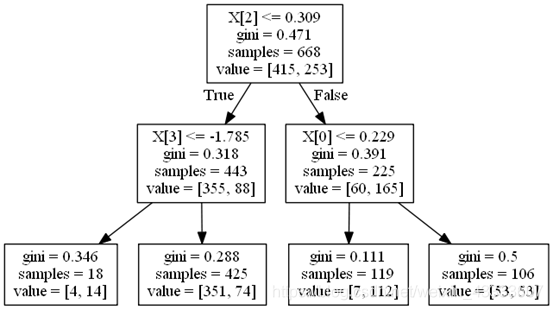
5、将建立的决策树进行可视化
根据上一问实验结果使决策树最大深度为2,画出决策树
import pydotplus
from IPython.display import Image
clf = tree.DecisionTreeClassifier(criterion='gini',max_depth=2)
clf.fit(X_train,y_train)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor("#FFF2DD")
graph.write_png('titanic.png')