摘要
DBpedia是一个社区努力从维基百科中提取结构化信息,并使这些信息在网络上可用。DBpedia允许您对来自维基百科的数据集提出复杂的查询,并将网络上的其他数据集链接到维基百科数据。我们描述了DBpedia数据集的提取,以及产生的信息如何在网络上发布,供人类和机器消费。我们描述了来自DBpedia社区的一些新兴应用,并展示了网站作者如何在他们的网站内促进DBpedia内容的发展。最后,我们介绍了DBpedia与网络上其他开放数据集互联的现状,并概述了DBpedia如何可以作为新兴开放数据网络的核心。
介绍
现在人们几乎普遍认为,将世界的结构化信息和知识拼接在一起,以回答语义丰富的查询是计算机科学的关键挑战之一,这可能会对整个世界产生巨大的影响。这导致了近30年的信息集成研究[15,19],并最终导致了语义网和相关技术的研究[1,11,13]。此类努力通常只在相对较小和专业的领域获得了吸引力,在这些领域中,可以商定一个封闭的本体、词汇表或模式。然而,更广泛的语义网愿景尚未实现,此类努力面临的最大挑战之一是如何将足够的“有趣的”和广泛有用的信息纳入系统,使其对一般受众有用和可访问。
一个挑战是,传统的在开发数据之前设计本体或模式的“自上而下”的模式在Web的规模上崩溃了:数据和元数据都必须不断演进,它们必须服务于许多不同的社区。因此,最近出现了一种构建语义网草根式的运动,使用增量式和Web 2.0启发的协作方法(10、12、13)。这样一个协作的、草根的语义网需要一种新的结构化信息表示和管理模式:首先,它必须以统一的方式处理不一致性、模糊性、不确定性、数据起源[3,6,8,7]和隐性知识。
沿着这些方向刺激协同研究的最有效方式,或许是提供丰富的多样化数据语料库。这将使研究人员能够开发、比较和评估不同的提取、推理和不确定性管理技术,并在网络上部署操作系统。
DBpedia项目从维基百科百科中派生出了这样一个数据语料库。维基百科的访问量很大,并且在不断的修改中(例如,根据alexa.com的数据,维基百科在2007年第三季度的访问量排名中排名第九)。维基百科有250多种语言版本,其中英文版本的文章超过195万篇。和许多其他网络应用一样,维基百科也存在一个问题,那就是它的搜索能力仅限于全文搜索,只能让用户非常有限地访问这个有价值的知识库。正如已经被高度宣传的那样,维基百科也展示了协作编辑数据的许多具有挑战性的属性:它有矛盾的数据、不一致的分类约定、错误,甚至是垃圾邮件。
DBpedia项目专注于将维基百科内容转换为结构化知识的任务,这样就可以利用语义网技术对其进行处理——对维基百科提出复杂的查询,将其链接到网络上的其他数据集,或者创建新的应用程序或mashup。我们做出了以下贡献:
-我们开发了一个信息提取框架,将维基百科内容转换为RDF。这些基本组件构成了进一步研究信息抽取、聚类、不确定性管理和查询处理的基础。
-我们将维基百科内容作为一个大型的、多领域的RDF数据集提供,可以在各种语义网应用中使用。DBpedia数据集由1.03亿个RDF三元组组成。
-我们将DBpedia数据集与其他开放数据集连接起来。这就形成了一个包含总计约20亿个RDF三元组的大型数据网络。
-我们开发了一系列的接口和访问模块,这样数据集就可以通过网络服务访问并链接到其他网站。
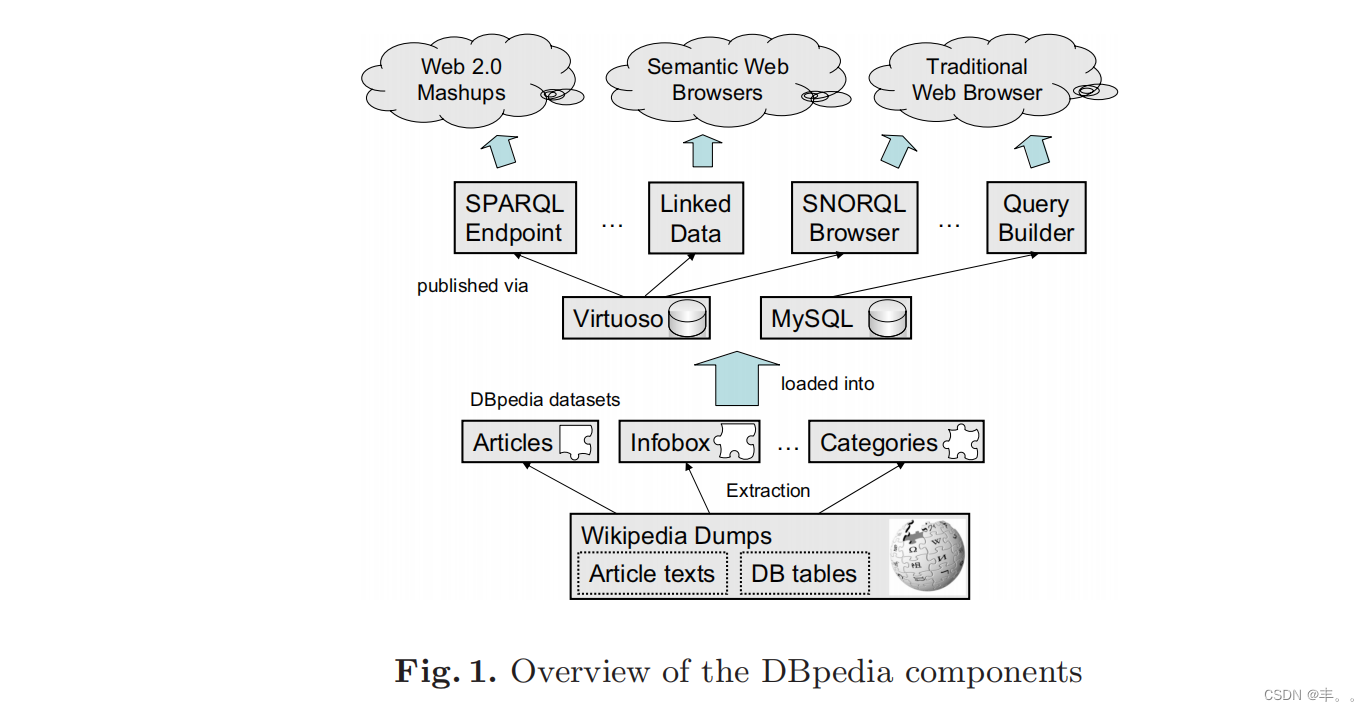
DBpedia数据集既可以导入到第三方应用程序中,也可以使用各种DBpedia用户界面在线访问。图1给出了DBpedia信息提取过程的概述,并显示了如何将提取的数据发布在网络上。这些主要的DBpedia接口目前使用Virtuoso[9]和MySQL作为存储后端。
本文的结构如下:我们在第2节中概述了DBpedia信息提取技术。结果数据集在第3节中描述。我们在第4节中展示了程序化访问DBpedia数据集的方法。在第5节中,我们展示了我们对DBpedia如何
数据集可以成为开放数据网络的核心。我们在第6节展示了访问DBpedia的几个用户界面,最后在第7节回顾了相关工作。
从维基百科中提取结构化信息
维基百科的文章主要由自由文本组成,但也包含不同类型的结构化信息,如infobox模板、分类信息、图像、地理坐标、外部网页链接和维基百科不同语言版本的链接。
mediawiki1 是用来运行维基百科的软件。由于这个维基系统的性质,基本上所有用元数据进行的编辑、链接、标注都是通过添加特殊的语法结构在文章文本内部完成的。因此,结构化的信息可以通过解析这些句法结构的文章文本来获得。
由于MediaWiki利用这些信息本身的一些信息来呈现用户界面,因此一些信息被缓存在关系数据库表中。不同维基百科语言版本的关键关系数据库表(包括包含文章文本的表)的转储定期2发布在Web上。基于这些数据库转储,我们目前使用两种不同的方法来提取语义关系:(1)我们将已经存储在关系数据库表中的关系映射到RDF上,(2)我们直接从文章内的文章文本和infobox模板中提取额外的信息。
我们用维基百科infobox模板的例子来说明从文章文本中提取语义的过程。图2展示了infobox模板(编码在维基百科的一篇文章中)和韩国小镇的渲染输出

釜山。信息框提取算法检测这样的模板,并使用模式匹配技术识别它们的结构。它选择重要的模板,然后将其解析并转换为RDF三元组。该算法使用后处理技术来提高提取的质量。Me- diaWiki链接被识别并转换为合适的uri, common units被检测并转换为数据类型。此外,该算法可以检测对象列表,这些对象列表被转换为RDF列表。关于收件箱提取算法的细节(包括数据类型识别、清洗启发式和标识符生成等问题)可以在[2]中找到。所有提取算法都是使用PHP实现的,并且在开源许可下可用。
DBpedia数据集
DBpedia数据集目前提供了超过195万个“事物”的信息,包括至少8万人、7万个位置、3.5万张音乐专辑、1.2万部电影。它包含了65.7万个指向图像的链接,160万个指向相关外部网页的链接,18万个指向其他RDF数据集的外部链接,20.7万个维基百科类别和7.5万个YAGO类别[16]。
DBpedia的概念由13种不同语言的短摘要和长摘要描述。这些摘要从英语、德语、
法语、西班牙语、意大利语、葡萄牙语、波兰语、瑞典语、荷兰语、日语、汉语、俄语、芬兰语和挪威语版本的维基百科。
DBpedia数据集总共由大约1.03亿RDF三元组组成。该数据集以一组较小的RDF文件的形式提供下载。表1给出了这些文件的概述。
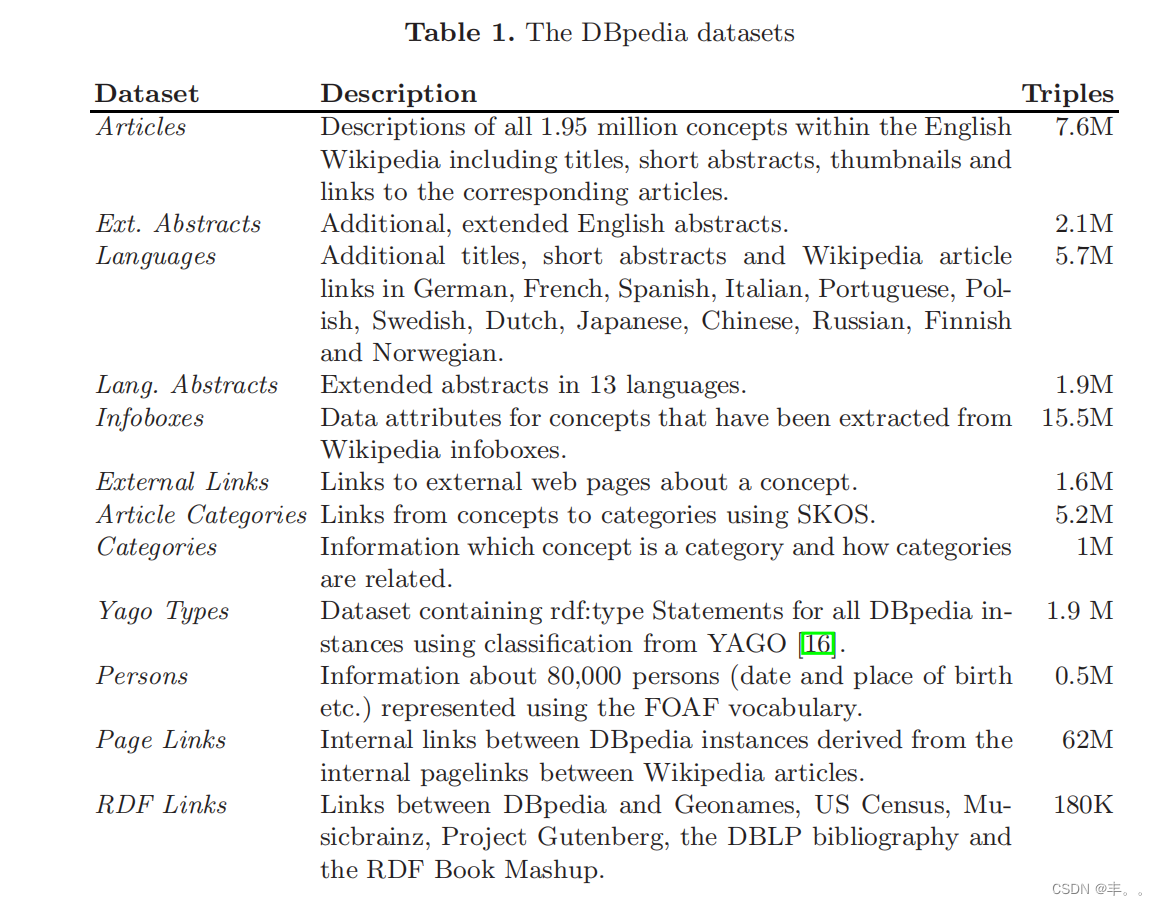
一些数据集(如Persons或Infoboxes数据集)在语义上是丰富的,因为它们包含非常具体的信息。另一些(如PageLinks数据集)包含没有特定语义的元数据(如文章之间的链接)。然而,后者可能是有益的,例如用于推导概念之间的紧密程度或搜索结果中的相关性的度量。
DBpedia数据集中描述的195万个资源中的每一个都由一个形式为http://dbpedia.org/resource/Name的URI引用标识,其中名称取自源维基百科文章的URL,其形式为http://en.wikipedia.org/wiki/Name。因此,每个资源都直接与一篇英文维基百科文章联系在一起。这为DBpedia标识符产生了某些有益的属性:
-它们涵盖了广泛的百科全书主题,
-它们由社区共识定义,对他们的管理有明确的政策,
-该概念的广泛文本定义可在知名网站(维基百科页面)找到。
访问网络上的DBpedia数据集
我们提供了三种访问DBpedia数据集的机制:链接数据、SPARQL协议和可下载的RDF转储。这些接口的免版税访问是根据GNU自由文档许可证的条款授予的。
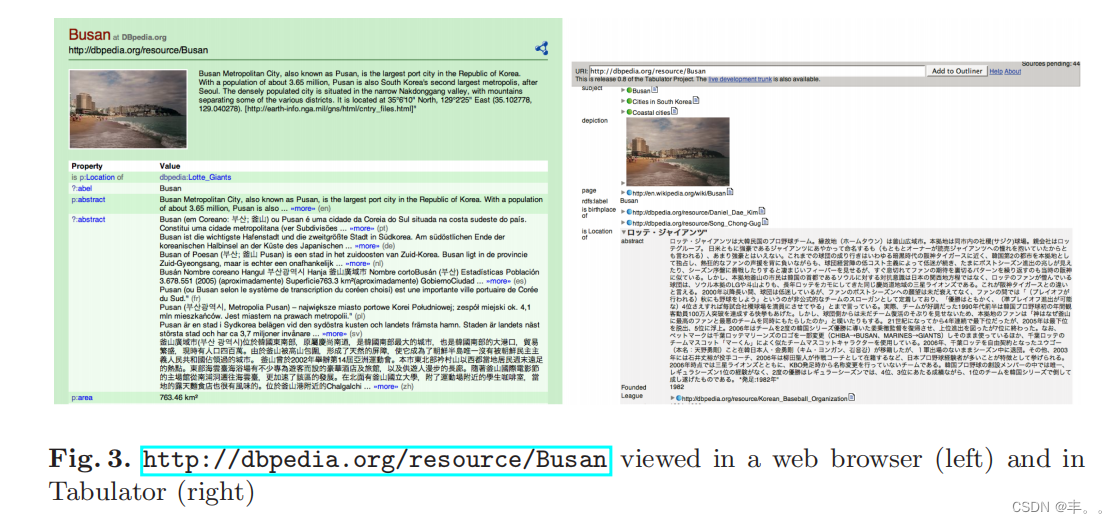
关联数据。链接数据是一种在Web上发布RDF数据的方法,它依赖http:// uri作为资源标识符,并通过HTTP协议检索资源描述[4,5]。uri被配置为返回关于资源的有意义的信息——通常是一个RDF描述,包含关于资源的所有已知信息。这样的描述通常通过URI提到相关的资源,这些资源反过来可以被访问以生成它们的描述。这就形成了一个可以跨越服务器和组织边界的、可通过web访问的资源描述的密集网格。DBpedia资源标识符(如http://dbpedia.org/resource/Busan)被设置为在被语义Web代理访问时返回RDF描述,并向传统Web浏览器返回相同信息的简单HTML视图(参见图3)。HTTP内容协商用于传递适当的格式。
能够访问链接数据的Web代理包括:1。语义Web浏览器如Disco4、Tabulator17,或OpenLink Data WebBrowser5;2.像SWSE6和Swoogle7这样的语义网络爬虫;3.语义网查询代理,如语义网客户端库8 和SWI prolog9的SemWeb客户端。
SPARQL端点。我们提供了一个用于查询DBpedia数据集的SPARQL端点。客户端应用程序可以通过SPARQL协议将查询发送到这个端点(http://dbpedia.org/sparql)。当客户端应用程序开发人员事先确切地知道需要什么信息时,此接口是合适的。除了标准的SPARQL之外,端点还支持查询语言的几种扩展,这些扩展已被证明对开发用户界面很有用:对选定的RDF谓词进行全文搜索,以及聚合函数,尤其是COUNT。为了防止服务过载,对查询成本和结果大小进行了限制。例如,请求商店全部内容的查询会因为代价过高而被拒绝。SELECT结果被截断为1000行。SPARQL端点使用Virtuoso Universal Server10托管。
RDF垃圾场。数据集的n -三重序列化可以在DBpedia网站上下载,对数据集更大部分感兴趣的网站可以使用。
将DBpedia与其他开放数据集互联
为了使DBpedia用户能够发现进一步的信息,DBpedia数据集使用RDF链接与网络上的各种其他数据源进行了互联。RDF链接使网络冲浪者能够使用语义web浏览器从一个数据源内的数据导航到其他数据源内的相关数据。RDF链接还可以被语义网搜索引擎的爬虫跟踪,这些爬虫可能对爬取的数据提供复杂的搜索和查询功能。
DBpedia互联工作是W3C语义网教育与推广(SWEO)兴趣小组的链接开放数据社区项目11的一部分。这个社区项目致力于使海量数据集和本体,如美国人口普查、Geonames、MusicBrainz、DBLP书目、WordNet、Cyc等许多其他数据集和本体,在语义网上实现互操作。DB- pedia具有广泛的主题覆盖范围,与几乎所有这些数据集都有交集,因此为此类努力提供了一个优秀的“链接枢纽”。
图4给出了目前与DBpedia相关联的数据集的概述。总的来说,这个数据网络大约相当于20亿RDF三元组。使用这些RDF链接,例如,冲浪者可以从DBpedia中的计算机科学家导航到她在DBLP数据库中的出版物,从DBpedia中的书导航到RDF book Mashup提供的对这本书的评论和销售建议,或者从DBpedia中的乐队导航到Musicbrainz或dbtune提供的他们的歌曲列表。
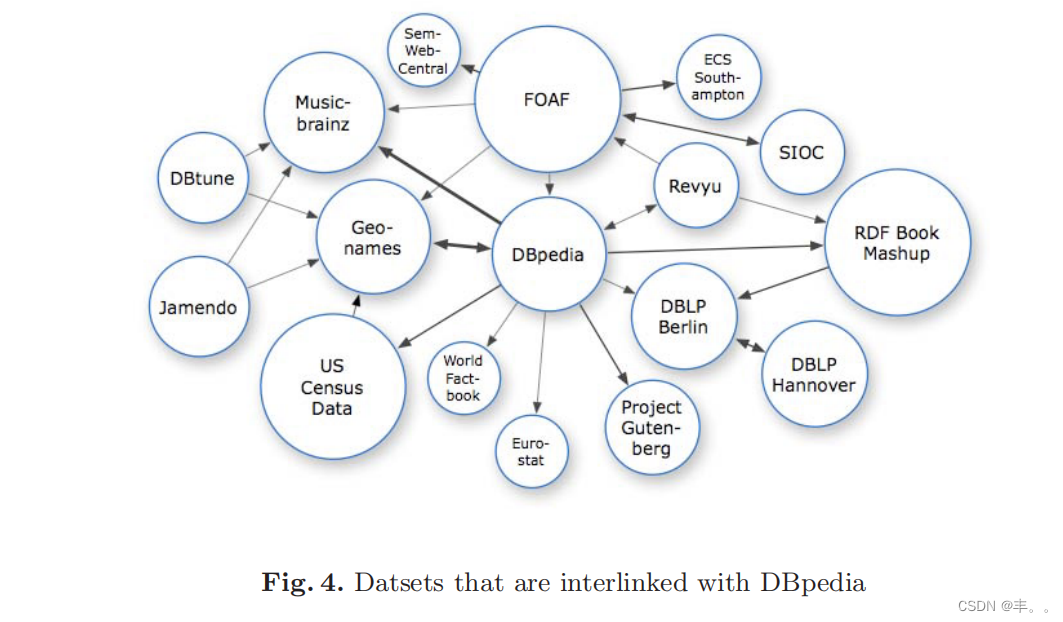
下面所示的示例RDF链接将识别釜山的DBpedia URI与Geonames提供的有关该城市的进一步数据连接起来:
< http://dbpedia.org/resource/Busan >
猫头鹰:sameAs http://sws.geonames.org/1838524/。
代理可以跟随这个链接,从Geonames URI中检索RDF,从而获得Geonames服务器发布的关于釜山的额外信息,这些信息再次包含深入Geonames数据的进一步链接。DBpedia uri也可以用来表达个人兴趣、居住地以及个人FOAF配置文件中的类似事实:
< http://richard.cyganiak.de/foaf.rdf cygri >
foaf:topic_interest http://dbpedia.org/resource/Semantic_Web;foaf:based_near http://dbpedia.org/resource/Berlin。
另一个用例是对博客文章、新闻故事和其他文档进行分类。这种方法的优点是,所有DBpedia uri都有数据支持,从而允许客户检索关于一个主题的更多信息:
< http://news.cnn.com/item1143 >
dc:主题http://dbpedia.org/resource/Iraq_War。
用户界面
DBpedia的用户界面可以从经典网页中的简单表格,浏览界面到不同类型的查询界面。本节概述了到目前为止已经实现的不同用户界面。
将DBpedia数据简单集成到网页中
DBpedia是一个有价值的通用数据来源,可以在web页面中使用。因此,如果您想要一个包含德国各州首府、非洲音乐家、Amiga电脑游戏或任何网站上的表,您可以使用针对DBpedia端点的SPARQL查询来生成这个表。维基百科是由一个大型社区保持更新的,这种表的一个很好的特性是,它们也会随着维基百科和DBpedia的变化而保持更新。这样的表既可以在客户端使用Javascript实现,也可以在服务器端使用PHP之类的脚本语言实现。在DBpedia网站12上可以找到两个Javascript生成表的例子。
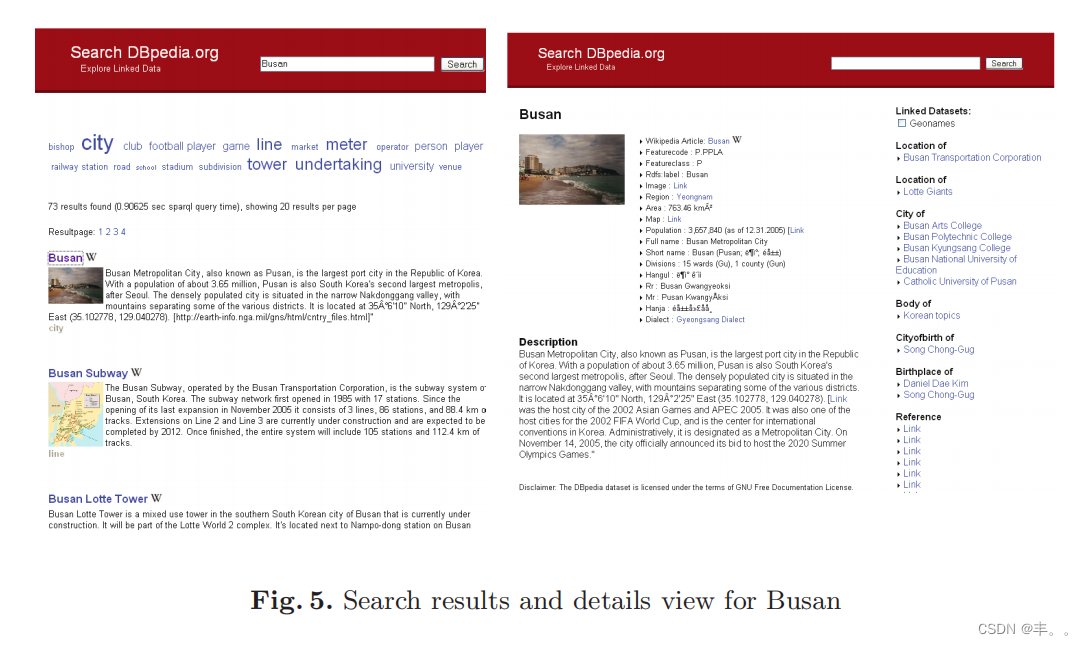
搜索DBpedia.org
Search DBpedia.org是一个示例应用程序,允许用户探索DBpedia数据集以及来自互联数据集的信息,如Geonames、RDF图书Mashup或DBLP书目。与通常在网络上发现的基于关键词的全文搜索相比,结构化数据搜索提供了有效利用数据中的关系的机会,使不同维度的搜索结果逐步缩小。这为搜索任务添加了浏览组件,并可能减少常见的“关键字命中或未命中”问题。
Search DBpedia.org会话以关键字搜索开始。第一组结果是通过直接关键字匹配计算出来的。添加相关匹配,利用实体之间的关系,深度可达两个节点。因此,搜索关键词“斯科塞斯”,将包括导演马丁·斯科塞斯,以及他的所有电影,以及这些电影的演员。
下一步就是结果排名了。我们的实验表明,重要的文章会从其他文章获得更多的传入页面链接。我们使用传入链接计数、链接来源的相关性和关系深度的组合来计算相关性排名。
在输入一个搜索词后,用户会看到一个排名结果的列表,并使用DBpedia和YAGO[16]分类的组合,从结果中发现的类构建一个标签云。每个类的权重都是通过关联结果权重和出现频率的总和来计算的。标签云使用户可以将结果缩小到特定类型的实体,比如“演员”,即使简单的关键词搜索可能没有找到任何演员。
当从结果中选择一个资源时,用户就会看到关于该资源已知的所有数据的详细视图。标签、图像和描述显示在顶部。单值和多值属性分别显示。通过跟踪数据集中的RDF链接自动检索来自互联数据集的数据,从互联数据集检索的数据与DBpedia数据一起显示。
查询DBpedia数据
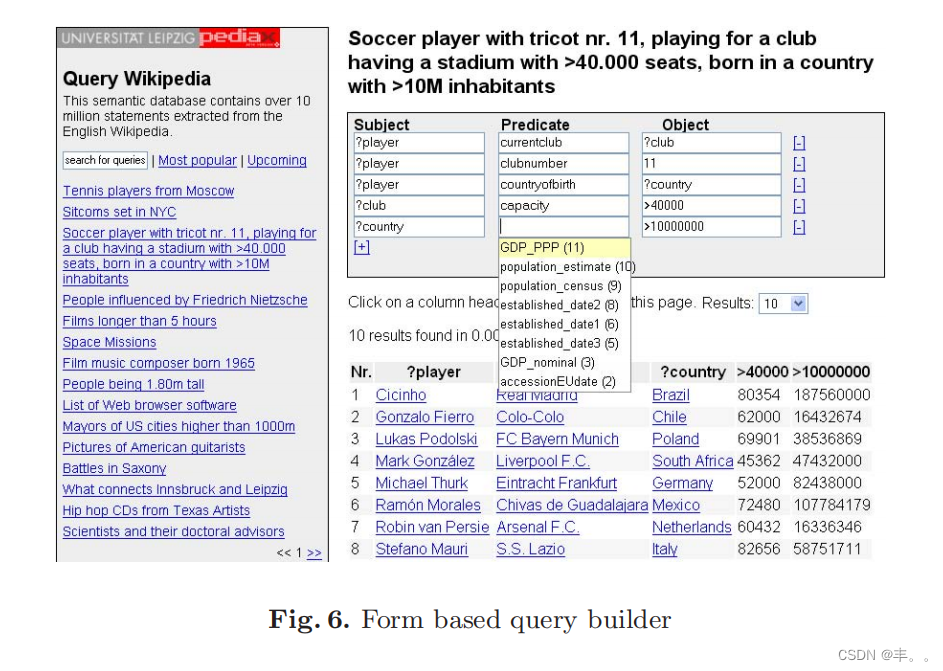
与目前可用的大多数其他语义网知识库相比,对于从维基百科提取的RDF,我们必须处理一种不同类型的知识结构——我们有一个非常大的信息模式和相当多的数据坚持这个模式。不幸的是,现有的工具大多集中于知识库的两个部分中的任何一个,即模式或数据。
如果我们有一个大的数据集和大的数据模式,单独使用集成查询引擎的详细的RDF存储并不是很有帮助。由于数据模式大,用户很难知道知识库中使用了哪些属性和标识符,因此可以用于查询。因此,在构建查询时,用户必须得到指导,并应建议合理的替代方案。
我们专门开发了一个图模式构建器,用于查询提取的维基百科内容。用户通过由多个三元组模式组成的图模式来查询知识库。对于每个三元组模式,三个表单字段捕获三元组的主语、谓语和宾语的变量、标识符或过滤器。当用户在其中一个表单字段中输入标识符名称时,前瞻性搜索会提出合适的选项。这些选项不仅通过查找匹配的标识符获得,而且通过使用当前编辑的标识符的变量执行当前构建的查询,并根据用户提供的搜索字符串开始的匹配过滤该变量返回的结果。这种方法确保,所提出的标识符确实与正在构建的图模式一起使用,并且查询实际上返回结果。此外,标识符搜索结果按使用编号排序,首先显示常用标识符。所有这些都是在后台执行的,使用的是Web 2.0 AJAX技术,因此对用户来说是完全透明的。图6显示了graph pattern builder的屏幕截图。
第三方用户界面
DBpedia项目旨在为基于维基百科信息的应用程序和mashup提供一个温床。虽然DBpedia是最近才推出的,但已经有很多第三方应用程序在使用这个数据集。例子包括:
-由卡尔斯鲁厄大学运行的SemanticMediaWiki[14,18]安装,它将DBpedia数据集与维基百科的英文版一起导入。
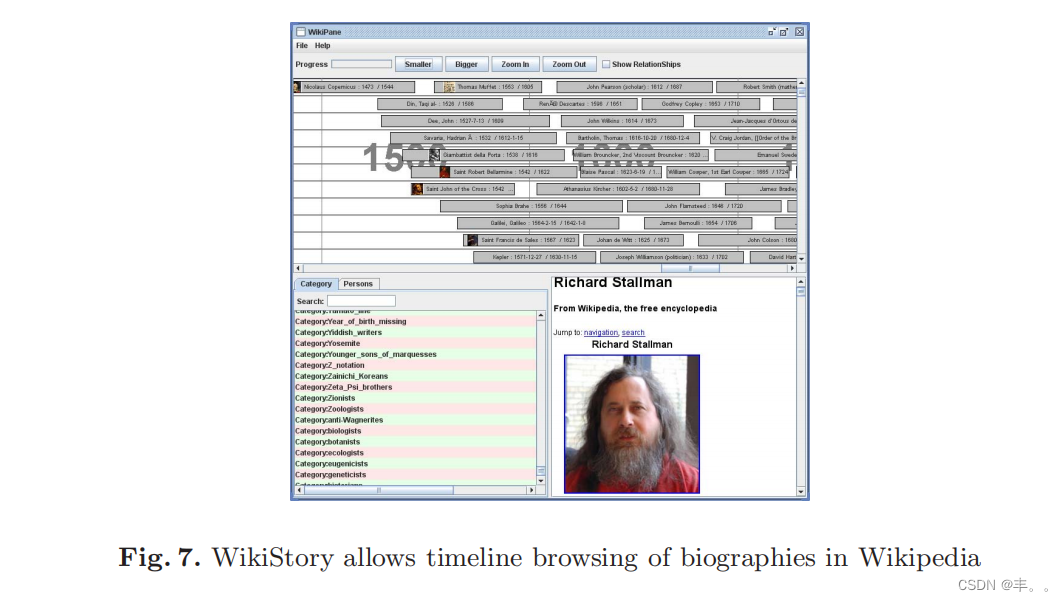
- WikiStory(见图7),它允许用户在一个大的时间轴上浏览关于人的维基百科文章。
-Objectsheet JavaScript可视化数据环境,允许基于DBpedia数据13进行电子表格计算。
相关工作
另一个从维基百科中提取结构化信息的项目是YAGO项目[16]。YAGO只从维基百科的不同信息来源中提取14种关系类型,例如subClassOf、type、familyNameOf、locatedIn。一个来源是维基百科的类别系统(for subclassof, locatedIn, diedInYear, bornInYear),另一个来源是维基百科的重定向。YAGO不像我们的方法那样执行信息框提取。为了确定(子)类关系,YAGO不使用完整的维基百科类别层次结构,而是将叶子类别链接到WordNet层次结构。
Semantic MediaWiki项目[14,18]还旨在实现wiki内信息的重用,并增强搜索和浏览设施。Semantic MediaWiki是MediaWiki软件的扩展,它允许您使用特定的语法将结构化数据添加到维基中。最终,DBpedia和Semantic MediaWiki有着相似的目标。两者都希望将维基百科中结构化信息的好处传递给用户,但使用不同的方法来实现这一目标。语义MediaWiki要求作者处理一种新的语法,覆盖维基百科内的所有结构化信息将需要将所有信息转换为这种语法。DBpedia利用了维基百科中已经存在的结构,因此不需要深入的技术或方法改变。然而,DBpedia并没有像语义MediaWiki计划的那样紧密地集成到维基百科中,因此在限制维基百科作者的语法和结构一致性和同质性方面受到了限制。
Freebase14也遵循了另一种有趣的方法。该项目旨在建立一个巨大的在线数据库,用户可以像现在编辑维基百科文章一样进行编辑。DBpedia社区与Metaweb合作,一旦Freebase公开,我们将把这两个来源的数据链接起来。
未来工作及结论
作为未来的工作,我们将首先专注于提高DB- pedia数据集的质量。我们将进一步自动化数据提取过程,以增加DBpedia数据集的通用性,并与维基百科的变化同步。与此同时,我们将继续探索DBpedia数据集的不同类型的用户界面和用例。在W3C内链接开放数据社区项目15 当DBpedia数据集作为链接数据在网络上发布时,我们将把它们与其他数据集联系起来。我们还计划利用不同语言的维基百科版本之间的协同作用,以进一步提高DBpedia的覆盖率,并为维基百科社区提供质量保证工具。例如,这样的工具可以通知维基百科作者关于一篇文章的不同语言版本中所包含的信息框内容之间的矛盾。将DBpedia与Cyc(以及它们作为背景知识的使用)等其他知识库连接起来,可能会产生对维基百科内容进行(半)自动一致性检查的进一步方法。
DBpedia是网络上开放的、免版税数据的主要来源。我们希望通过将DBpedia与进一步的数据源连接起来,它可以成为新兴数据网络的核心。