微博是一个拥有海量用户的社交媒体平台,每天都会涌现出大量的话题和热点讨论。本文将介绍如何使用Python来实现微博热点话题检测技术,通过对微博文本的分析和处理,准确地捕捉到当前最热门的话题。
1. 数据获取
为了进行微博热点话题的检测,首先需要获取微博的数据。可以使用微博开放平台的API来获取实时的微博数据,或者使用已经采集好的微博数据集。
数据获取部分,之前笔者使用的是基于scrapy的爬虫,大家也可以尝试使用微博官方的API,大概步骤:
-
注册并创建开发者账号:访问微博开放平台(https://open.weibo.com),注册成为开发者,并创建一个应用。https://open.weibo.com),注册成为开发者,并创建一个应用。https://open.weibo.com),注册成为开发者,并创建一个应用。
-
获取API访问权限:在创建的应用中,获取API的访问权限,通常包括读取用户微博、搜索微博等权限。
-
安装 Python 的请求库:在命令行中运行以下命令,安装
requests库。
笔者之前爬取的效果图如下: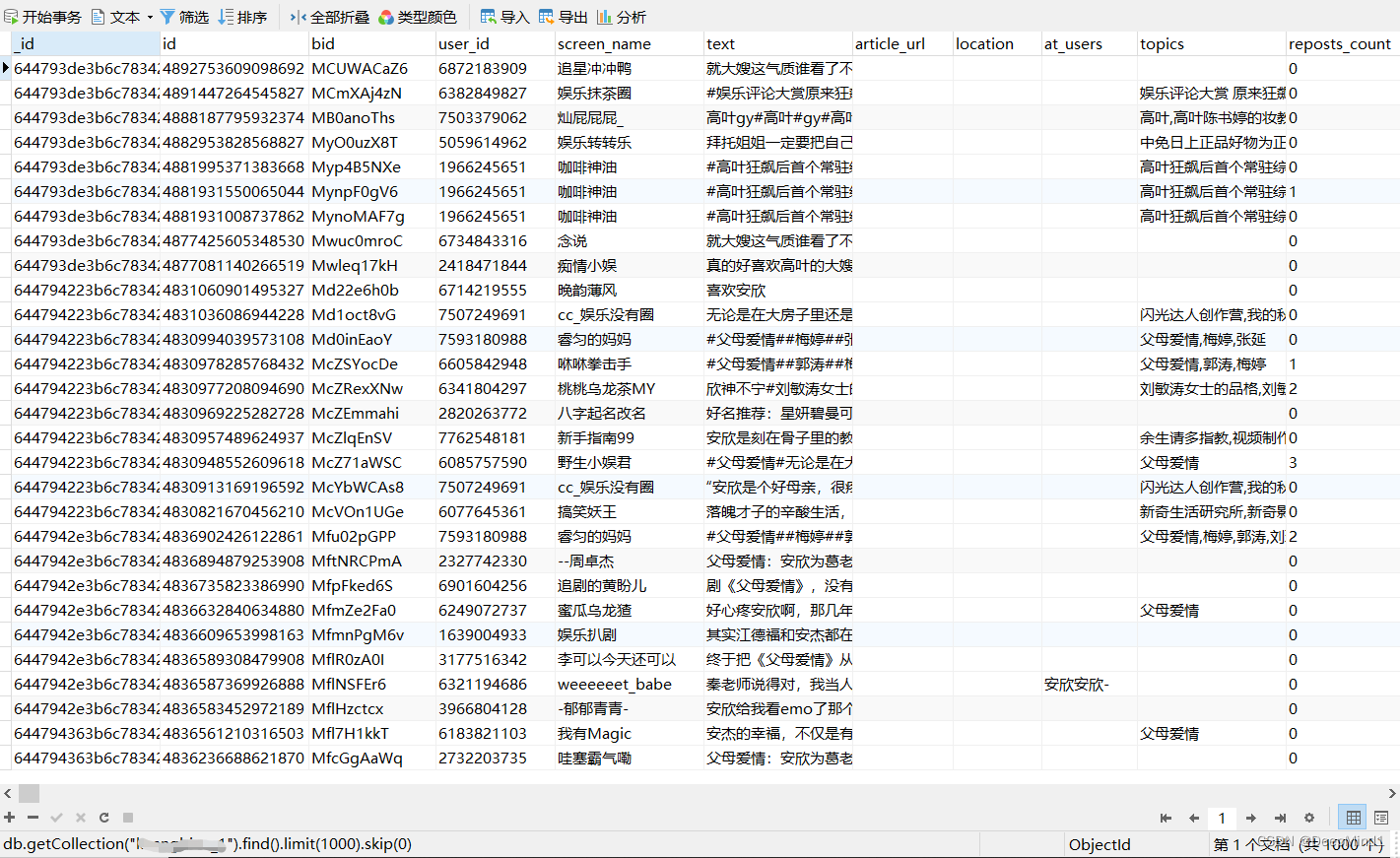
2. 文本预处理
获取到微博数据后,需要对文本进行预处理。预处理的步骤包括去除特殊字符、分词、去除停用词等。Python中有很多开源的文本处理库,如NLTK、Jieba等,可以方便地完成这些任务。
import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from collections import Counter# 定义你的停用词列表
stopwords = ["的", "是", "在", "有", "和", ...] # 此处需要你提供适合你数据的停用词# 文本预处理
def preprocess(text):seg_list = jieba.cut(text, cut_all=False) # 分词seg_list = [word for word in seg_list if word not in stopwords] # 去除停用词return " ".join(seg_list)# 加载数据
df = pd.read_csv('D:\Desktop\对应的数据文件.csv', encoding='GBK')
data = df['text'].tolist()
data = [preprocess(text) for text in data]
3. 文本特征提取
在进行话题检测之前,需要将文本转化为机器学习算法可以处理的特征向量。常用的文本特征提取方法包括词袋模型(Bag of Words)和TF-IDF(Term Frequency-Inverse Document Frequency)。Python中的Scikit-learn库提供了这些特征提取的功能。
# 特征提取
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(data)4. 话题聚类
得到文本的特征向量后,可以使用聚类算法对微博文本进行分组,将相似的微博归为一类。常用的聚类算法有K-means、层次聚类等。Python中的Scikit-learn库也提供了这些聚类算法的实现。
# 聚类
kmeans = KMeans(n_clusters=5, random_state=0, init='k-means++').fit(X)5. 话题热度计算
根据聚类结果,可以计算每个话题的热度。热度可以使用微博的转发量、评论量、点赞量等指标来衡量。通过对这些指标进行加权计算,可以得到每个话题的热度值。
# 提取主题词
order_centroids = kmeans.cluster_centers_.argsort()[:, ::-1]
terms = vectorizer.get_feature_names()# 获取每个聚类的主题词
def get_topic_words(i):return [terms[ind] for ind in order_centroids[i, :10]]# 打印每个聚类的主题词
for i in range(5):print("Cluster %d:" % i, get_topic_words(i))# 对所有聚类的主题词进行计数
topic_counter = Counter([word for i in range(5) for word in get_topic_words(i)])# 打印出现次数最多的10个主题词
print("Top 10 hot topics:")
for word, count in topic_counter.most_common(10):print("%s: %d" % (word, count))# 计算热度得分
def calculate_hot_score(cluster):# 获取该聚类的所有微博cluster_tweets = df[kmeans.labels_ == cluster]# 计算话题的出现频次frequency = len(cluster_tweets)# 计算相关微博的总评论数和总点赞数total_comments = cluster_tweets['comments_count'].sum()total_attitudes = cluster_tweets['attitudes_count'].sum()# 返回一个得分,这个得分是频次、评论数和点赞数的加权平均# 这里假设所有因素的权重都是1,你可以根据实际需要调整权重return (frequency + total_comments + total_attitudes) / 3# 计算每个聚类的热度得分
hot_scores = [calculate_hot_score(i) for i in range(5)]# 打印每个聚类的热度得分
for i, score in enumerate(hot_scores):print("Cluster %d:" % i, get_topic_words(i))print("Hot score: %f" % score)6. 结果展示
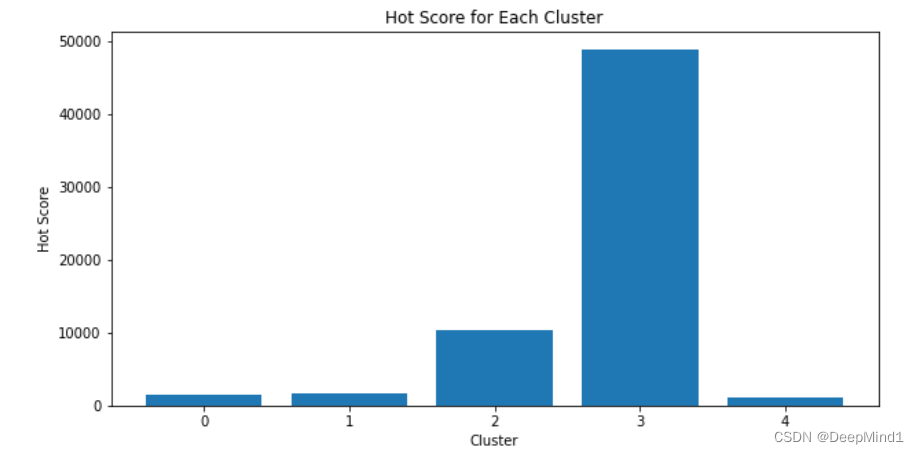
最后,将检测到的热点话题和对应的热度值进行展示。可以使用数据可视化库(如Matplotlib、Seaborn)来绘制柱状图、词云等形式,直观地展示当前的热点话题。
Cluster 0: ['挑战', '光盘', '接力', '节约粮食', '行者', '活动', '参与', 'XX大学', '东北', '干饭'] Cluster 1: ['XX大学', '东北', '绿色', '生活', '行者', '节约粮食', '干饭', '日记', '光盘', '云财管'] Cluster 2: ['学校', '快递', '东北', 'XX大学', '现在', '可以', '开学', '什么', '一下', '咱们'] Cluster 3: ['东北', 'XX大学', '开学', '有没有', '一个', '春天', '什么', '真的', '可以', '大庆'] Cluster 4: ['学姐', '学长', '复试', '专硕', '会计', '资料', '东北', 'XX大学', '上岸', '考研'] Top 10 hot topics: XX大学: 5 东北: 5 光盘: 2 节约粮食: 2 行者: 2 干饭: 2 可以: 2 开学: 2 什么: 2 挑战: 1 Cluster 0: ['挑战', '光盘', '接力', '节约粮食', '行者', '活动', '参与', 'XX大学', '东北', '干饭'] Hot score: 1483.000000 Cluster 1: ['XX大学', '东北', '绿色', '生活', '行者', '节约粮食', '干饭', '日记', '光盘', '云财管'] Hot score: 1612.666667 Cluster 2: ['学校', '快递', '东北', 'XX大学', '现在', '可以', '开学', '什么', '一下', '咱们'] Hot score: 10343.333333 Cluster 3: ['东北', 'XX大学', '开学', '有没有', '一个', '春天', '什么', '真的', '可以', '大庆'] Hot score: 48906.000000 Cluster 4: ['学姐', '学长', '复试', '专硕', '会计', '资料', '东北', 'XX大学', '上岸', '考研'] Hot score: 1007.333333

总结
本文介绍了使用Python实现微博热点话题检测技术的步骤。通过数据获取、文本预处理、文本特征提取、聚类分析和热度计算,可以准确地捕捉到当前最热门的话题。这种技术可以帮助用户迅速了解微博上的热点动态,也可用于舆情监测和社交媒体分析等领域。
希望本文能够对读者在微博热点话题检测方面提供一些启示和帮助,激发更多的创新思路和应用场景。
补充:文中使用的数据,正在上传到资源,可能会放到连接可能会放到评论中