“Cybersecurity Challenges In The Uptake Of Artifitial Intelligence in Autonomous Driving”是ENISA发布的关于自动驾驶汽车中,由于AI技术的大量应用所带来的网络安全问题的技术白皮书。
全文可以分为三大部分:第一部分是对自动驾驶汽车的软硬件,及相关AI技术的系统性介绍;第二部分讲述AI技术在自动驾驶场景下的网络安全风险;第三部分则给出了相应的应对措施建议。
1. Introduction
The main contributions of this report are summarized below:
• State-of-the-art literature survey on AI in the context of AVs.
• Mapping of AVs’ functions to their respective AI techniques.
• Analysis of cybersecurity vulnerabilities of AI in the context of autonomous driving.
• Presentation and illustration (theoretical and experimental) of possible attack scenarios against the AI components of vehicles.
• Presentation of challenges and corresponding recommendations to enhance security of AI in autonomous driving
2. AI Techniques in automotive functions
2.1和2.2章节是关于自动驾驶系统的科普知识,涵盖了软硬件系统的简介
2.1 AI in autonomous vehicle
The last decade has seen an increase of efforts towards the development of AVs. An AV is a driving system that observes and understands its environment, makes decisions to safely, smoothly reach a desired location, and takes actions based on these decisions to control the vehicle. A key enabler of this race towards fully AVs are the recent advances in Al, and in particular in ML . Designing an AV is a challenging problem that requires tackling a wide range of environmental conditions (lightning, weather, etc.) and multiple complex tasks such as:
- Road following
- Obstacle avoidance
- Abiding with the legislation
- Smooth driving style
- Manoeuvre coordination with other elements of the ecosystem (e.g. vehicles, scooters, bikes, pedestrians, etc.)
- Control of the commands of the vehicle
Usually, autonomous driving is described as a sequential perception-planning-control pipeline, each of the stages being designed to solve one specific group of tasks [50]. The pipeline considers input data, generally from sensors, land returns commands to the actuators of the vehicle. The main components of a driving-assistant as well as of an AV are broadly grouped into hardware and software components. The hardware component includes sensors, V2X facilities, and actuators for control. The software part comprises methods to implement the vehicle perception, planning, decision and control capability. Figure 3 displays typical elements of this pipeline. They are implemented by decomposing each problem into smaller tasks, and developing independent models, usually using ML , for each of these tasks.
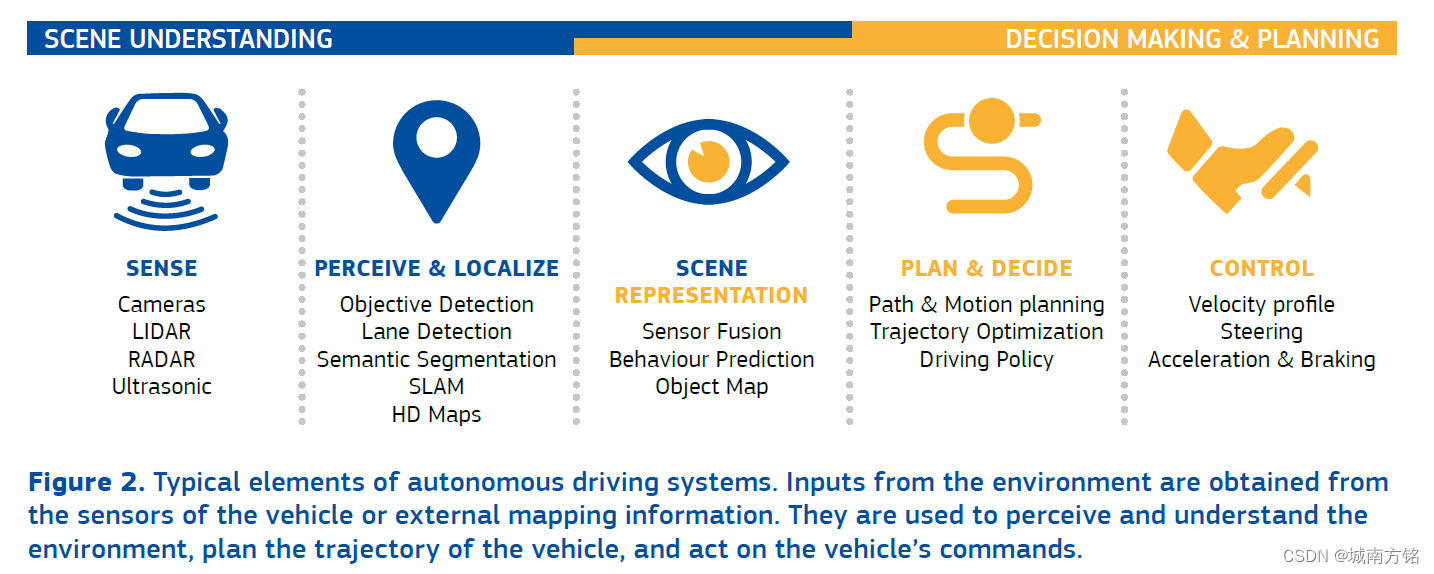
This chapter is structured as follows: First, a brief introduction to the main high-level automotive functions where Al plays an important role is given, as well as a presentation of the main hardware sensors that can be found on vehicles, and that generate the data that are processed by Al software components. After these two sections, a description of the main Al techniques commonly used is given, followed by a discussion on how these techniques are leveraged to implement the high-level functions in AVs. Finally, a summary of the chapter is presented in the form of three tables, highlighting the links between functions, hardware and software components, and techniques.
2.1.1 High-level automotive functions
Currently, fully autonomous driving solutions are being mostly experimented with prototypes. Nonetheless, vehicles with levels of automation up to level 3 are already on the road, with driving assistance functionalities relying on Al and ML. Technology-enhanced functionalities featured by commercialised vehicles that leverage the use of Al and ML are, for instance, braking assistance, smart parking, or vocal interactions with the infotainment system.
Features of AVs can be decomposed into several high-level automotive functions that are typically used by car manufacturers to advertise the autonomous capabilities of their products. As of today, the technical specifications of such functions are not uniformly defined and vary between manufacturers. In the following, we provide a non-exhaustive list of the most common automotive functions that are deemed as essential to achieve autonomous driving [10]. It is worth noting that most functions have been primarily designed to assist drivers rather than replace them (in vehicles with a level of autonomy from 1 to 3), by providing warnings, or taking control of the vehicles in limited situations. With fully developed AVs, these functions are part of the driving process and, essentially, contribute to replacing the driver1. At the end of this chapter, the following functions are considered and are mapped to specific Al tasks:
- Adaptive cruise control (ACC) consists in adjusting the speed of the vehicle in order to maintain an optimal distance from vehicles ahead. ACC estimates the distance between vehicles and accelerate or decelerate to preserve the right distance [51].
- Automatic Parking (or parking assistance) systems consist in moving the vehicle from a traffic lane into a car park. This includes taking into account the markings on the road, the surroundings vehicles, and the space available, and generate a sequence of commands to perform the manoeuvre [52].
- Automotive navigation consists in finding directions to reach the desired destination, using position data provided by GNSS devices and the position of the vehicle in the perceived environment [53].
- Blind spot / cross traffic / lane change assistance consists in the detection of vehicles and pedestrians located on the side, behind and in front of the vehicle, e.g. when the vehicle turns in an intersection or when it changes lanes. Detection is usually performed using sensors located in different points of the car [54], [55].
- Collision avoidance (or forward collision warning) systems, consist in detecting potential forward collisions, and monitoring the speed to avoid them. These systems typically estimate the location and the speed of forward vehicles, pedestrians, or objects blocking a road, and react proactively to situations where a collision might happen.
- Automated lane keeping systems (ALKS) consist in keeping the vehicle centred in its traffic lane, through steering. This includes the detection of lane markings, the estimation of the trajectory of the lane in possible challenging conditions, and the generation of actions to steer the vehicle [56].
- Traffic sign recognition consists in recognizing the traffic signs put on the road and more generally all traffic markings giving driving instructions, such as traffic lights, road markings or signs. This implies to detect from camera sensors various indicators based on shape, colours, symbols, and texts [57].
- Environmental sound detection: consists in the detection and interpretation of environmental sounds that are relevant in a driving context, such as hom honking or sirens. This requires performing sound event detection in noisy situations.
In what follows, we first analyse the standard blocks of hardware and sensor components. We then give a brief overview over the most important Al techniques and their software realization used for designing AVs. The chapter concludes by mapping automotive functions to Al functions in order to facilitate the identification of relevant vulnerabilities and cybersecurity threats in autonomous driving. By narrowing down the Al techniques that are actually used in AVs, one scopes down the problem of identifying pertinent cybersecurity threats related to the use of Al in autonomous driving.
2.2 Hardware and sensors
Humans drive cars by taking actions with hands and feet, based on decisions made considering the input received from our senses, mainly sight and hearing. Similarly, AVs rely on a variety of sensors to observe the surroundings and provide data to the Al systems of the vehicle, and on actuators to control the motion of the vehicle. The hardware components allow the vehicle to sense the outside surroundings as well as the inside environment via specific sensors, to act via the actuators that regulate the car movement, and to communicate with other agents/devices via the V2X technology.
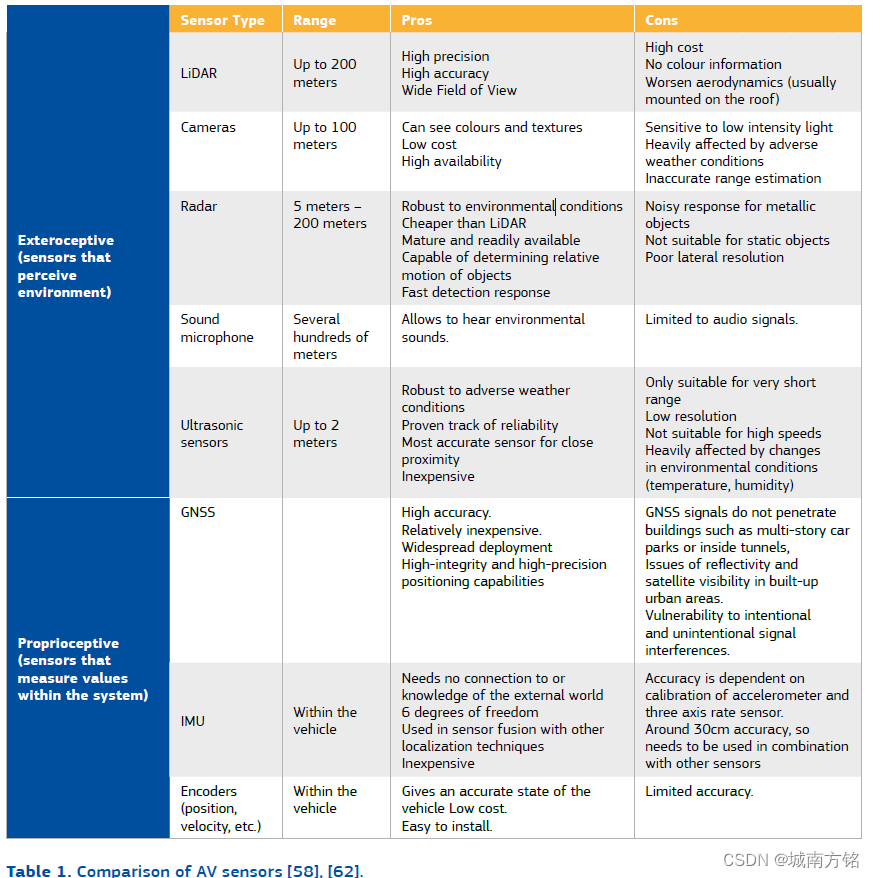
Sensors, as the primary source of information for Al systems, are a critical element of AVs. All sensors can be broadly classified in three distinct groups [S8]:
- Exteroceptive sensors are those sensors that are designed to perceive the environment that surrounds the vehicle. They are relatively new sensors present in cars, and are the eyes and ears of the car. Cameras and Light Detection and Ranging system (LIDARs) are the main vectors of information for driving purposes. Other sensors, such as Global Navigation Satellite Systems (GNSSs), Inertial Measurement Unit (IMU), radars and ultrasonic sensors, are also used to probe the environment, but tend to be limited to specific tasks (e.g. close detections, sound listening) or to add redundancy, increasing the reliability of results in the case of malfunction of a sensor.
- Proprioceptive sensors, on the other hand, are those that take measurements within the vehicle itself. They have been present in cars for decades, and are mostly used for control purposes. They include the set of analogue measurements that are encoded in digital form indicating values such as the engine’s revolution per minute (RPM), speed of the car (as measured by wheel’s rotation), direction of steering wheel, etc
- Other sensors are those sending the information that the vehicle might receive from its digital communication with other vehicles, V2V communications or V2I. They mainly concern the connected infrastructure of vehicles, and therefore they will not be discussed in the rest of the report
The integration of sensors in vehicles varies according to carmakers [59], [60] and depends on the software strategy chosen to process the streams of data. Very often, the inputs from multiple sensors are combined in a process called data fusion [61] to align all data streams before processing, as sensors are usually providing images from different natures (2D images, 3D point clouds, etc.) with different temporal and spatial resolution.
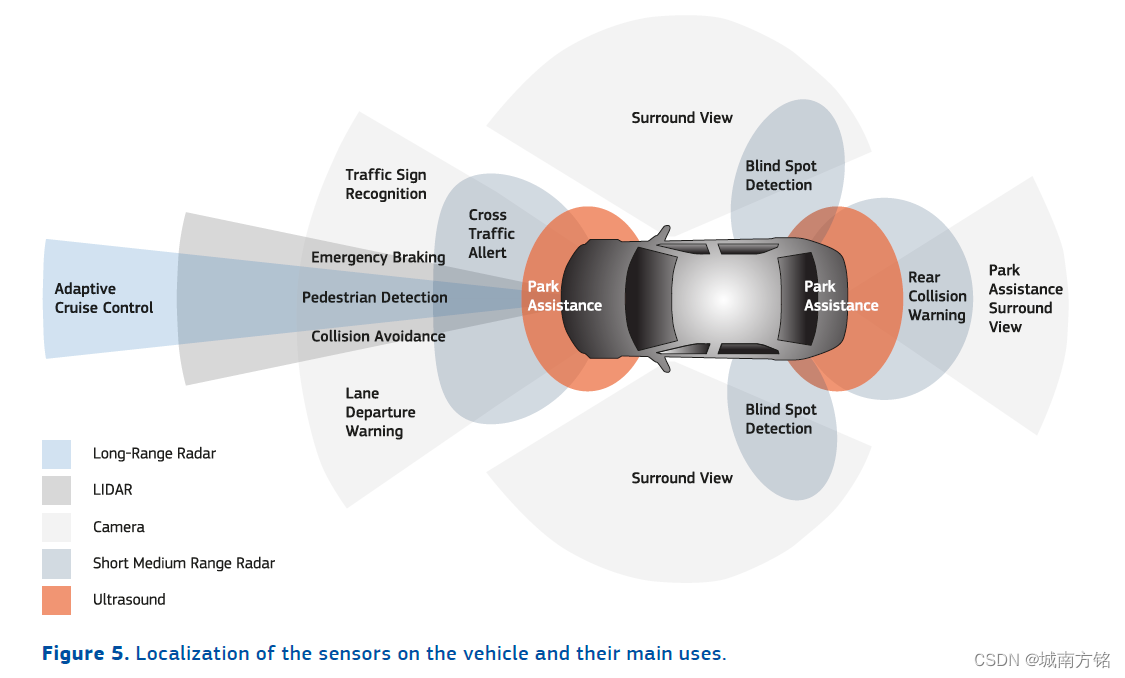
Table 1 presents the main characteristics of the most common sensors found on autonomous cars, in addition to the LIDARs and cameras. The localization of these sensors on the vehicle and their main uses are illustrated in Figure 3 .
2.2.1 LIDARs and cameras for computer vision
Cameras and LiDARs are the most widespread sensors in autonomous cars, used to reproduce and enhance human vision. Digital video cameras are able to obtain a 2D representation of the 3-dimensional world. They provide a stream (video feed, as a sequence of images) of 2D maps of points (pixels) encoding colour information. Computer stereo vision techniques can be applied using multiple cameras and/or considering the different images in relation to the known movement of the vehicle. Examples of images from cameras are depicted in Figure 4 .
A LiDAR illuminates the environments with lasers and collects the reflected light. The analysis of the signal received allows the generation of a depth map of the scene (see Figure 4). The depth map is further processed to recreate 3D maps of the environment [54] considering missing values in the acquired 3D data points, unexpected reflections due to wrong perception of surfaces, and many other issues that may appear during the acquisition in real world scenarios.
Compared to LiDARs, cameras have the advantage that they distinguish colours, allowing the recognition of elements such as road signs, traffic lights, vehicle lights or text wamings. However, cameras also exhibit certain limitations compared to LiDAR: camera vision could be impaired by certain weather conditions such as rain, fog or sudden light changes such as when a vehicle gets out of a tunnel, while these conditions would affect to a lesser degree a LiDAR system.
2.3 Al techniques
Al is generally defined as a collection of methods capable of rational and autonomous reasoning, action or decision making, adaptation to complex environments and/or to previously unseen circumstances [65]. Al was initially born as an academic discipline in the second half of the twentieth century and led since then to significant advances in the automation of some human level tasks, nonetheless without much impact beyond academic circles for a long time [66]. It is deeply rooted in the fields of computer science, discrete mathematics and statistics, with an eventful history before gaining the popularity that makes it nowadays a key domain of the current digital revolution, thanks to the tremendous performances achieved by modem systems.
Typical problems related to Al require the development of programs able to demonstrate some forms of reasoning, knowledge representation, planning, learning, and, more generally, cognitive capabilities.
These competencies are usually considered as being natural to humans but are difficult to translate explicitly into algorithms. Nowadays, from a scientific perspective, Al is actually a heterogeneous field that regroups different subfields with diverse views on how to address these problems.
Research on AVs was historically pioneered in the field of robotics, with several cars in the 1980 s, and later on, able to drive autonomously in controlled environments. Nonetheless, the complexity of real-world environments, and the necessary reliability that are required for such vehicles, has curbed their development until the significant recent progress made in ML. Since the last decade, tremendous milestones have been reached in computer vision, natural language processing or game reasoning, pushing autonomous driving a leap forward. Although some functions are still solved using traditional methods, ML is increasingly used, relying on the huge quantity of data that are collected by companies, with millions of kilometres travelled by autonomous cars under human supervision in real-world conditions or using simulated environments.
In the following, a short introduction to the relevant fields of ML for autonomous driving is provided, Besides giving the technical basis that will support the discussion in the rest of the report, the goal of this section is also to highlight the diversity of techniques that are being employed for the different tasks, and the complexity of the full processing chain.
2.3.1 Machine learning: paradigms and methodologies
ML is the scientific field dedicated to the study of models that are able to improve automatically through experience [67]. This acquisition of experience can take different forms, and is usually achieved by extracting relevant patterns from large collection of data. Machine learning algorithms are therefore able to achieve high performance for a variety of complex tasks, hard to solve using conventional programming techniques, without being explicitly instructed how to perform them. Prominent examples include recognizing faces in a picture, identifying objects in video streams, predicting the price of an asset quoted in a financial market, grouping users on an online platform based on their activities, recognizing the emotion of a person, or teaching a robot to move in an unlonown environment.
The central element of ML systems is the model that takes as inputs a set of pre-processed data, and returns a prediction. This model is usually described as a mathematical function, with a collection of parameters that have a direct influence on the mapping between the inputs and the predictions. To adapt the model to the desired task, a training stage is performed, and consists in running an algorithm that will update these parameters to fit a training dataset, ie. a list of samples serving as examples to guide the model towards the expected function. The capability to perform well on data outside the training data, called the generalization, is a desirable property of the resulting model, which is often measured by metrics such as accuracy or mean squared deviation on previously unseen data. Training a model implies applying a host of ad-hoc procedures to increase the generalization capabilities of systems. Popular techniques include data augmentation that consists in artificially increasing the amount of training data by applying random transformations on the training data, and hyperparameter optimization search that tests various settings for the training procedure. The full pipeline includes several additional steps during training and testing that are not detailed here.
2.3.1.1 Paradigms of machine learning
Three different paradigms are commonly considered in ML:
- Supervised learning makes use of large and representative set of labelled data to train the model. The underlying problem consists then to return the right label for the input data. Supervised learning includes classification, when the label is discrete (e.g. the make of a car), and regression, when the label is continuous (eg. the speed of the car). The availability of labelled data is a limiting factor for supervised learning, as labelling can be, in some contexts, expensive and time-consuming.
- Unsupervised learning (or self-leaming) consists in extracting meaningful patterns from the data without labels by reducing the natural variability of the data, while preserving the similarity or absence of similarity between examples. Unsupervised leaming is used for various purposes, such as clustering the samples (e.g. grouping individuals based on their habits) or anomaly detection (e.g. detecting a vehicle with an unusual behaviour).
- Reinforcement learning regroups a set of techniques to make models learn sequences of actions in a possibly uncontrolled and/or unknown environment. Contrary to the supervised learning setting, in which the ground-truth is given as labels, learning is guided by indications on how good an action is, given the state of the environment. Consequently, the learning process is dynamic with respect to the feedback it gets from the environment, in a trial-and-error approach.
三类常见的机器学习算法:监督学习、无监督学习和强化学习
2.3.1.2 Classical machine learning
A wide range of techniques have laid out the foundation of the field of ML coming from statistics and expert systems, such as linear regression, support vector machine (5VM), k-nearest neighbour (kNN) classifiers, or decision trees. The common point of these methods is that they usually operate on handcrafted features, whose quality can drastically change the performances of the modeL Although these techniques show limitations in complex problems such as the ones encountered in computer vision or natural language processing, they are still very popular to solve a large range of problems, in particular when the volume of data is small, when the time available for model training is limited, or if the context domain is well understood.
经典的机器学习算法:线性回归、5VM、kNN、决策树。用于解决数据量较小、模型训练时间有限或上下文已充分理解的问题。
2.3.1.3 Deep learning
Although the ideas behind neural networks are as old as the field of ML, DL techniques have disrupted the ML landscape these last years, and exported the whole field of Al outside academic circles, thanks to simultaneous progress in computing capabilities, data acquisition and storage, and ML algorithms. The advances in hardware and the digitalisation of the society have permitted to train models on high performance computing infrastructure and to collect huge datasets to do so, in addition of progress made to speed up training algorithms.
由于在计算能力、数据获取和存储,以及ML算法等领域的巨大进步,深度学习技术得以快速发展,并把AI从学术圈带到人们的现实生活中
One strength of DL is its ability to learn from raw data the most adapted representation for the considered problem, removing the need to handcraft features. DL techniques employ neural networks in layered architectures, denoted deep neural networks (DNN), allowing for flexible designs able to represent relationships between inputs and outputs. Each layer is composed of a number of units called neurons that perform simple linear combinations between the outputs of the previous layer. These stacked architectures exhibits a specialization of groups of neurons in the deepest layers, able to extract more and more complex patterns.
Although powerful, DL is not a silver bullet as it suffers from several limitations that make it impractical in some situations. First, the training of neural network models needs substantial amounts of good quality data and of computational power to be efficient. Secondly, the development of such models, in particular during the training phase, lies on strong engineering practices with limited theoretical guarantees on the overall performances. This severely hinders the understanding of the behaviour of DL models, and is a reason of their vulnerabilities. Thirdly, DNNs are notoriously known to provide accurate results but with an inherent lack of interpretability, making them acting as black boxes. The robustress of such systems with respect to unusual inputs or malicious actions is also under scrutiny by the research community.
深度学习的几个限制:1. 训练神经网络模型需要大量高质量的数据和算力。2. 这种模型的开发,尤其在训练阶段,依赖很强的工程实践,但又缺乏理论依据来保证整体性能。这使得DL模型的行为很难被理解,这也是造成DL模型漏洞的原因。3. DNN像是一个黑盒,不具备可解释性。
2.3.2 Relevant application fields in autonomous driving
2.3.2.1 Computer vision 计算机视觉
Computer vision is an interdisciplinary field, at the intersection of ML , robotics, and signal processing, concerned with extracting information from digital images and videos. This covers all stages of the processing chain, from the acquisition of images to the processing and analysis of the image, to the representation of knowledge as numerical or symbolic information. To date, computer vision is the most relevant field of ML with existing applications in AVs. As such, the most significant and well-known vulnerabilities and possible attack scenarios on Al models employed in AVs are involving computer vision techniques. A more detailed focus is then given with respect to other application fields of ML.
目前为止,计算机视觉是自动驾驶汽车应用中相关度最高的领域。自动驾驶汽车的AI模型中,最重要也是最知名的安全漏洞也是计算机视觉技术相关的。
Images can take several forms, depending on the type of hardware sensors that have been used to obtain them. Computer vision has been historically interested in the handling of standard RGB images, that represent a large proportion of applications in robotics and image processing, but has also gained more and more interest in the analysis of other forms of images such as 3D point clouds, hyperspectral images, acoustic images, to name but a few. This trend has been significantly fostered with the recent availability of large data sets. In addition to the mode of acquisition, other variables such as the size, the resolution, the quality obtained, the environment of acquisition, etc. have led to specialized sub-domains adapted to specific tasks.
计算机视觉采用的图像形式越来越多样化,从标准的RGB图像,到3D点云、高光谱影像、声像等
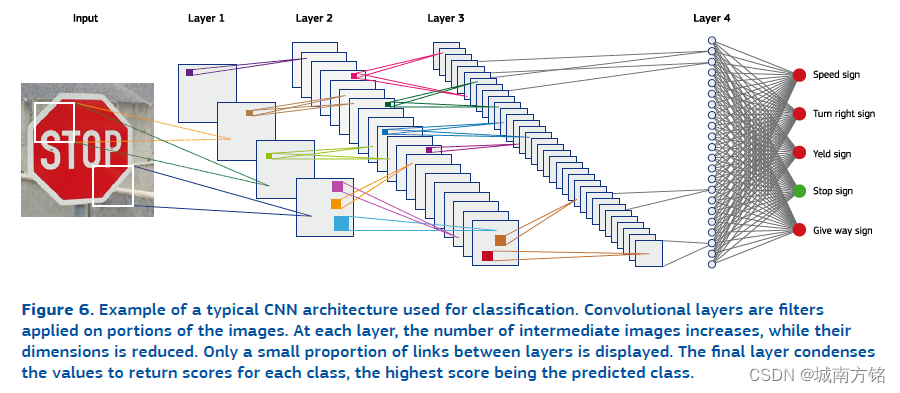
The advent of highly performant convolutional neural networks (CNN) has been a major breakthrough that has drastically changed the technical landscape in computer vision. CNNs are an evolution of DNNs specifically designed to take into account the spatial structure of images [68] by grouping the weights that are locally close. They compensate for one of the drawbacks of fully-connected networks by significantly reducing the number of parameters to learn, making learning on high-dimensional data, which is typically the case of images that are composed of millions of pixels, a more tractable problem. Convolutional layers act as a series of filters that are applied on a small portion of the image to detect a specific pattern such as edges, a specific shape, a dark area, etc, the particularity being that these filters are learned from the data. The size of the filters determines the complexity patterns, and has to be calibrated according the characteristics of the image. CNNs have been successfully used to extract, directly from the raw inputs, efficient representations that are adapted to the problem, and that take into account natural invariances that often appear in images, such as symmetries. Figure 4 illustrates a typical CNN architecture used for classification, and the basic mechanisms at play during the processing.
高性能的卷积神经网络(CNN)是计算机视觉领域的一个重大突破。CNN被成功的用于从原始图像输入中直接提取问题相关特征,并且在提取时包涵了图像中经常出现的自然不变性(如对称)。
Today, the overwhelming majority of computer vision techniques are relying in one way or another on CNNs, and more and more sophisticated approaches are considered to address always more complicated problems. In the following, the most relevant problems for autonomous driving are briefly summarized.
如今,绝大多数计算机视觉技术都或多或少的依赖CNN,以下概括了与自动驾驶最为相关的部分。
Object recognition 物体识别, in its most common form, includes two tasks: detecting and classifying objects in an image. Localization is usually achieved by assigning bounding boxes to regions of the image, while classification assigns to these regions a label from a list of pre-defined categories.
To achieve high performance in the classification task, several architectures have been built by the ML community during the last decade, employing various innovations aimed at increasing the expressive power of models, while limiting at the same time the cost of training. Among them, we can cite: AlexNet [69] is widely considered as the first breakthrough using CNNs; VGG [70] introduces the use of numerous layers, with different size of filters; GoogLeNet [71],[72] makes use of the so-called Inception module, including at the same level various filters of different sizes; ResNet [73] uses shortcut connections between layers to limit the tendency of large models to memorize the training data (also called overfitting); SqueezeNet [74] is designed to be embedded in systems with low capabilities by reducing the number of parameters.
On top of classification architectures, object detection is implemented in two competing designs: single staged and double staged. Double staged approaches split the detection procedure into two stages, region proposal and bounding box search. By far the most widely accepted state-of-the-art double stage design is the family of Fast Region-based NN (R-CNN) [75] architectures. Conversely, single stage design detectors only employ one single network architecture to classify directly pixels or regions. The “You Only Look Once” (YOLO) [76] architecture is an example of a successful single-stage detector, largely used in many recognition systems.
物体识别的分类架构目前有两种主流设计:以R-CNN (Fast region-based NN)代表的double staged design,以及以YOLO (You only look once)为代表的single staged design
Object recognition in 3D representations, such as point clouds, is becoming more popular these last years, especially with advances in autonomous driving using LiDAR and radar. Albeit less mature than its counterpart in 2D, some first standard architectures have already emerged. Among those are techniques to project the 3D point clouds into a 2D space to use one of the known 2D detectors, for example the YOLO3D architecture [77], or, those techniques that directly develop algorithms working on the 3D data, such as VoxelNet [78] or PointNet [79].
基于3D图像(如点云)的物体识别正越来越流行。其中涉及将3D点云投射到2D空间并使用2D物体识别算法的技术,如YOLO3D。也有直接基于3D点云开发物体识别的算法,如VoxelNet或PointNet。
Segmentation 分割 is an extension of object recognition that does not consider bounding boxes to delimit objects, but pixel-wise regions acting as masks over the image. A label is then assigned to each region to classify them into prescribed categories. Several types of segmentation problems have been discussed, among them, instance segmentation detects pixels of each object and assigns an identifier for each object; as for semantic segmentation, non-object characteristics, such as sky, water, horizon or textures are part of the elements to segment. In the latter case, the full image is completely segmented, resulting in a label assigned to each individual pixels, forming continuous regions. As for object recognition models, segmentation makes an intensive use of CNNs. State-of-the-art approaches include SegNet [80], EnET [81], PSPNet [82], DeepLab [83], or Mask R-CNN [84].
Segmentation分割是物体识别技术的一个延伸,与通过边界盒界定物体不同,分割使用像素级的区域作为mask覆盖到图像上,再赋予标签分类。Segmentation又分instance segmentation实例分割,semantic segmentation语义分割等。语义分割中,非物体的特征(如天空,水,地平线等)也被赋予标签,形成连续的区域。
Vehicle localization 车辆定位, often called Visual Odometry (VO), is a technique to estimate using a sequence of images captured over time by the camera mounted on the vehicle the pose of the camera, ie. its position and its orientation. A common approach consists in tracking key-point features of clear landmarks and reconstructing the complete pose from these features. Classical vo techniques still dominate the field for AV, although there have been increasingly promising results based on DNNs [85]. DL has also been built on top of classical algorithms implementing outlier rejection scheme in order to discriminate ephemeral from static parts in images [86]. While most techniques focus on 2D images, various proposals have been published to tackle the 3D pose estimation using DL [87].
车辆定位也称为视觉里程计(Visual odometry, VO),这是一种使用摄像头捕捉到的一系列图像来估算摄像头姿态(如位置和方向)的技术。一种常见的方法包括追踪清晰路标的关键特征点,并通过这些特征重构完整姿态。经典的VO技术仍然是自动驾驶汽车中的主流应用,尽管基于DNN的车辆定位技术正越来越成熟。
Tracking of objects 物体追踪 is used to determine the dynamics of moving objects. This can be seen as an additional layer on top of image recognition systems, providing for each frame of a video stream the objects present in a scene, the temporal connections between these objects, and a prediction of their future positions. Tracking systems, also referred as MOT (for Multiple Object Tracking) provide this functionality by estimating the heading and velocity of objects, and applying a motion model to predict the trajectory. Tracking is a very active field of research in the computer vision community, and has been studied for a wide range of applications and contexts [88] Techniques vary according to parameters such as the quality of the detection of objects, the type of data considered, the frame rate, or the nature of the motions involved.
物体追踪用于确定运动物体的动态性,它可以被看做是图像识别系统上的附加层,为视频流的每一帧提供场景中存在的物体、这些物体之间的瞬态连接,以及对它们未来位置的预测。
Typically, tracking is solved by assigning an identifier to objects and trying to keep this identifier consistent through successive image frames. This consistence is implemented either by using measures of similarity applied on handcrafted features based on image characteristics, such as colours or gradients [89], or by using CNNs [90]. The modelling of the dynamics is then done using sequential modelling tools to take into account the temporal dependencies between frames. The trend towards models that jointly address multiple tasks concerns also the tracking and the prediction of objects, that is often coupled with object recognition systems. For example, the “Fast and Furious” [91] architecture considers simultaneously 3D detection of objects, their tracking over time, and the forecasting of their motions.
通常的,追踪问题通过赋予物体一个标识,并在连续的图像帧里保持这个标识的一致性来解决。Fast and Furious架构同时考虑了3D物体识别、追踪和运动轨迹预测,这也是当下的趋势。
2.3.2.2 Sequence modelling 序列建模
Modelling sequential data and training predictive systems is a very important subfield of ML with high relevance for autonomous driving. Sequential data encompass data sets that result from dynamical or ordered process introducing a clear sequence and correlation between instances of the data set. Examples include time series modelling, prediction of trajectories, speech and language processing. Sequence modelling plays a significant role in prediction and planning tasks and is used in robotics and signal processing in applications concerned with interpreting continuous flows of environmental data. Classically, the field is dominated by Markov models, autoregressive modelling and dyramical linear filter systems [92], which are built around the assumption of a certain correlation length between successive elements of the series paired with a probabilistic process to model the next element.
序列建模是机器学习的一个非常重要的子领域,与自动驾驶高度相关。序列建模应用于时序建模、轨迹预测、语音文字处理,它在预测和计划类任务中扮演者非常重要的角色。
Recently, DL and unsupervised representation learning have introduced major advances into the field, mostly in form of specialized network structures, such as recurrent neural networks (RNN) [93] and modern variants such as the Long Short-Term Memory networks (LSTM) [94], able to deal with the sequential nature of data. Key advantages from DL based systems are their capability to easily discover long and short term correlations and to automatically leam representations of dynamical processes, even in complex contexts.
2.3.2.3 Automated planning 自动规划
Automated planning [95] is a rich field connected to ML at the intersection of other fields such as robotics, complex infrastructure management, decision theory, and probabilistic modelling. It is mainly concerned with the search of optimal strategies, often described as a sequence of actions that should be followed by agents evolving in complex environments, and how to perform them. There exists a wide variety of methods to find the optimal strategy in the specific context of problems that this field aims to address. In the following, we provide a brief description of methods that have been used in an automotive context.
自动规划主要是关于寻找最佳策略,所谓的策略可以被描述为在复杂环境下需要执行的一系列动作,及如何执行这些动作。
Graph-based planning 基于图表的规划 is used when systems can be represented as networks, including a wide range of applications as diverse as social relationships, transportation or telecommunication networks [96]. In its simplest form, a graph is composed of nodes, that represent the entities, and of edges, that represent a link between the entities. For planning purposes, algorithmic approaches have been used to find optimal trajectories along the edges of the graph to go from one node to another one, using pre-defined constraints. Classical algorithms coming from graph theory, such as the Dijkstra, Bellman-Ford, or Floyd algorithms [97], are popular approaches that do not require ML techniques to provide satisfactory results.
Deep Reinforcement learning 深度强化学习 provides a range of methods well suited for planning tasks [98] It involves learning mapping situations to actions so as to maximize a numerical reward signal. In an essential way, they are closed-loop problems where the learner is not told which actions to take, as in many forms of ML, but instead discovers which actions yield the most reward by trying them out. In the most interesting and challenging cases, actions may affect not only the immediate reward but also the state of the environment and, through that, all subsequent rewards. Many approaches have been developed to find the policy that is optimal, i.e the policy that returns in average the highest future reward. The use of DL architectures [99] to model the environment has enabled significant advances, with techniques such as deep Q-leaming or actor critic learning capable of scaling to previously unsolvable problems.
2.4 Al software in automotive systems
Driving in real world environments with other human-operated vehicles is far from an easy task, which requires complex socio-ethical and decision capabilities able to cope with unexpected and dangerous situations. Al software components embedded in AVs are in charge of reproducing these capabilities, by processing data gathered via the sensors and interpret them in order to decide the action to undertake (e.g. move, stop, slow down, etc). Three main types of data processing capabilities are involved:
- The perception module is responsible to collect multiple streams of data obtained from the sensors, and extract from them relevant information about the environment. This includes the contextual understanding of the scene: detection and tracking over time of vehicles (cars, trucks, bikes, etc.), pedestrians, and objects, and their tracking over time, recognition of traffic signs, traffic lights, marking, lanes, and more generally any element of interest for the driving. The perception module keeps also track of the localization of the vehicle in this environment, detecting its position and orientation with respect to the road and other agents involved in the scene.
- The planning module is in charge of the calculation of the trajectory that the vehicle will undertake, considering the route between the start location and the desired destination, as well as all the constraints the vehicle has to respect along the entire path. These constraints include the design of a safe and smooth route taking into account all possible obstacles (still objects, moving vehicles, etc) and the compliance with driving rules, but also require to take into consideration behavioural aspects due to the presence of humans in the environment
- The control module is responsible to execute the sequences of actions planned by the system by acting on the actuators (speed, steering angle, lights, etc.) to ensure that the trajectory is correctly performed.
嵌入在自动驾驶汽车中的AI软件主要有3类:perception感知、planning规划、control控制
The decomposition of the general driving activity into subtasks is a standard approach to address complex problems that enable constructors to select the right methodology for each of the subcomponents. ML has been mostly used in the tasks related to perception, to sense the surroundings and provide a useful representation of the environment. This was spurred by recent advances in computer vision that created industrial opportunities in this sector. Consequently, companies have started to invest in vehicles to collect recordings of driving situations, build up infrastructures to collect, label and process those large datasets, and hire computer vision high-level engineering teams to develop model to address the related tasks. Although solving these problems is still an active area of development, commercial products and services are already in use in modem cars to attain low to medium levels of automation. Conversely, the use of ML for planning and control purposes is still in its infancy, while improvement is going fast, supported by large investments from tech companies. In this context, behaviour modelling techniques are leveraged to learn relevant driving policies that will determine the action to undertake to achieve the trip according to the environment encountered by the vehicle. These problems are different from perception problems, and are still considered as frontier research in the academic community.
Current systems are already achieving tremendous performances in a wide range of conditions, but their capacity to generalize is limited by the extreme complexity and diversity of the world. A crucial challenge still unsolved for ML systems is the right general handling of edge cases, where an unknown situation outside of the training data distribution is encountered. It is very challenging to guarantee that an Al system will output the right results in unusual conditions, leading to potentially hazardous situations, for instance ignoring a stop sign partially covered by snow, or stopping in front of a bush slightly overhanging the side of the road.
In the rest of the section, an overview of the different tasks, and the main techniques that are employed to address them, is presented. This overview is primarily based on works published by the research community and may not reflect accurately the technology embedded in actual semi-autonomous cars, as only limited information is released by car manufacturers on this matter. In addition, perception tasks are prevalently discussed over others, as they constitute currently the main sources of vulnerabilities of Al systems.
2.4.1 Perception 感知
The perception system refers to the ability of an AV to make sense of the raw information coming in through its sensors. It aims at the creation of an intermediate level representation of the environmental state around the vehicle, and at the tracking of the evolution of this state over time. This includes, amongst others, the capability to detect, classify and identify everything that an AV potentially could encounter or has to interact with, such as the infrastructure (roads, signs, traffic lights, etc.), agents (cars, cyclists, pedestriars, etc.), or obstacles. It also consists in the construction of an internal map of the environment, allowing the vehicle to localize and other objects of agents in space and time.
The most relevant perception tasks for AVs can be ordered along the terms of scene understanding, scene flow estimation and scene representation and localization. Nowadays, much of the field is dominated by DL techniques, albeit strong influences are coming from robotics, especially for localization and mapping techniques [100], and classical time series pattem recognition filters [101].
2.4.1.1 Scene understanding 场景理解
Scene understanding encompasses all tasks that aim to provide a current picture of the immediate environment of the AV. Typical tasks include the detection and recognition of all elements present in the environment Most approaches that fall under scene understanding make use of data streams from various sensors and employ very successful computer vision based architectures. However, understanding objects in a realistic traffic environment in real time poses a number of additional complexities to the theoretically often extremely accurate computer vision systems. This requires indeed taking into account the variability of the scene:
- Variability of appearance: elements present in the environment can have a wide diversity of aspects: objects, actors and surfaces can have various shapes, colours, texture, orientation, brightness, etc.;
- Variability of environments: the environment itself varies according to various factors, including the time of the day, the season, the weather, but also societal factors (maintenance works, strikes, behaviours of agents, etc);
- Variability of meaning objects can have different meanings in different contexts or at different times (e.g. traffic signs with time or space constraints), or wrong appearances, for instance in case of reflections.
场景理解需考虑场景的可变性:外表可变性(如形状、方向、颜色、亮度),环境可变性(如时间、季节、气候、维修工人、代理人行为等),意义对象可变性(如有时间或空间限制的交通标志、错误的外表、光线反射)
Identification of roads and lanes 道路识别 This requires distinguishing drivable areas (roads, driveway, trail, etc.) from non-drivable areas (pavement, roundabouts, etc.), the different types of surface, and the various lanes present on the road indicating the direction of the traffic flow. This task has been widely investigated over decades, and has been integrated in vehicles through functions such as lane keeping assistance or lane change assistance. Therefore, such technologies generally do not rely on recent trends in ML, but rather on a wide collection of techniques based on handcrafted features [102] that have proven to be very efficient and reliable. This is done on 2 D and 3D images, and is often complemented by real street maps. Despite this, traditional methods tend to be limited to understand the challenging semantics conveyed by lanes on the road, and this task is getting more and more integrated in end-to-end DL systems. This is for instance the case of the Tesla’s Autopilot [103], whose the ADAS to detect stop lines along the road is implemented using a DL architecture.
Detection of moving agents and obstacles 移动物体和障碍识别 The detection of moving agents (pedestrians, cyclist, vehicles, etc) and obstacles (plants, objects, etc.) is mainly addressed using object detection, segmentation, and tracking techniques. Detection and classification of objects from 2D or 3D images such as camera data can be successfully tackled with computer vision architectures, providing that the training dataset is rich enough to characterize fully the diversity of environments. Recognition and segmentation techniques are used to detect drivable areas, objects, pedestrian paths or buildings.
Traffic signs and markings recognition 交通标志和标记识别 The detection and recognition of the given sign and/or the written indications is crucial to ensure a safe driving. Driving instructions are typically provided according to several vectors:
- Traffic signs, usually using a symbolic representation, are the most common driving indicators. While signs vary depending on the shape, the colour, and the pictogram drawn on it, intemational conventions have helped to achieve a degree of uniformity, despite small local variations. While image-processing approaches have been mainly taking advantage of the well-defined shape and colours of signs, DL has greatly improved the rate of detection [104]. Models based on CNNs are now regularly employed [105], taking advantage of various datasets released for this task [106].
- Traffic lights are using a position (usually top, middle, bottom) and colour (usually red, orange, red) code to indicate if the vehicle should stop, prepare to stop, or is allowed to pass. Particular cases should also be taken into account, for instance when a light is blinking. Research works are currently mostly limited by the scarcity of representative public datasets, but are nonetheless led to the development of DL systems including special processing in the colour space [107], [108]. Industrial actors have nonetheless already included traffic light recognition in their vehicles as an assistance feature [109].
- Textual indications are also an important way to convey information, in particular in situations where unanticipated rules should apply (e.g. detours, accidents, traffic jam, etc). Text can be found on traffic signs, painted on the road, or on variable-message signs. Understanding textual indications commonly requires three steps: 1) the detection of the text in the image, 2 ) the recognition of the characters, 3) the understanding of the meaning. The last step is all the more important since numerous text signs without connection with traffic indications can be found alongside roads, like advertisements or touristic information. Currently, this task is mostly done in an ad-hoc manner, without leaming involved. Text detection and recognition in natural scenes have nonetheless been an important area of research, either on static images [110] or videos [111], taking into account artefacts, such as distortions or out-of-focus texts. State-of-the-art approaches have combined convolutional and recurrent neural networks [112], to achieve text recognition and understanding. The availability of datasets [113], [114], although limited, is expected to foster the scientific community to advance research on this ongoing topic that will also benefit autonomous driving.
Previously based on handcrafted features describing images based for example on the colour or the shape, object recognition and semantic segmentation techniques are now systematically used. These techniques require nonetheless adjustments to adapt to the relatively small size of signs and markings compared to bigger objects such as vehicles, as CNNs are typically compressing the image, resulting to small objects, such as signs, to be overlooked. Recognition is also greatly affected by unusual environmental conditions, with degraded performances when the symbols are partially occluded by obstacles or stickers, or hard to distinguish due too direct sunlight or heavy precipitation.
Sound event classification 声音事件分类 Recognizing environmental sounds is an important aspect for the understanding of the driving scene: many elements, such as tire screeching, honking, or even engine throbbing, convey information about the vicinity of the vehicle, and can help anticipate hazardous situations. This is particularly true for sirens of emergency vehicles that indicate a situation where driving rules have to be adapted. Albeit visual lights are usually present, they may not be visible to the vehicle, for instance in the case of a busy intersection, and ignoring the sound alarm could have dramatic consequences. Sounds also complement the other sensors in low visibility situations.
As for images, sound processing largely makes use of DL techniques [115], either on raw data or on spectrograms (frequency representation of sound signals), even if traditional approaches are still widely used due to the long-standing work on handcrafted features relying on physical and cognitive principles. Related to AVs, few works [116] have been proposed, partly because of the small interest of the AV community on these topics compared to vision, and a lack of availability of dedicated datasets. Detecting relevant sounds in urban areas, especially in noisy situations, is nonetheless an open challenge that will play an important role in the capacity of AVs to achieve human-like performances.
2.4.1.2 Scene flow estimation 场景流估计
Scene flow estimation collects those perception tasks, which are concemed with the dynamical behaviour of the scene, mostly the movement of the objects and vehicles.
Tracking and prediction of moving agents and obstacles 追踪和预测移动物体和障碍
The most important task in scene flow understanding is to track objects and vehicles to predict their individual motion and may require modelling the behaviour of other traffic participants, which is very relevant for planning tasks. The two main challenges are the tracking of self-motion or stationary objects and the prediction of object motion and behaviour.
Tracking and predicting the motion of objects located in the immediate environment of the AVs rely evidently first on the ability to detect those objects, but pose a number of additional challenges, which led to the development of a class of tracking and prediction methods [117]. The basic object detection problem is extended through a time axis dimension, where individual objects need to be tracked frame by frame, or, conversely their likely trajectory is to be extrapolated into the future. The employed techniques usually rely on elements from sequence modelling, such as probabilistic Markov models or, increasingly, deep recurrent neural network architectures. Both, tracking and prediction - as object detection itself - are conducted using either 2D camera image data, 3D point cloud (mostly LIDAR) data, or both.
2.4.1.3 Scene representation 场景表示
Scene representation tasks involve the simultaneous mapping of the environment and continuous localization of the AV itself within the environment.
Localization 定位 It consists in estimating the position and orientation of the AV with respect to the surrounding environment. These techniques actually belong to the wider set of methods from the area of Simultaneous Localization and Mapping (SLAM), which has been addressing the same range of problems since decades for mobile robots. SLAM algorithms traditionally do not require a priori information about the environment, which allows them to be used anywhere, but the challenging environment in which vehicles evolve, especially in urbanized areas, makes the use of maps [118] a crucial element to achieve a high level of accuracy. Localization is achieved by matching maps with sensory information, such as GNSS or cameras and LIDARs outputs. The fundamental technique being used in this context is visual odometry. Various proposals have also been published to tadkle the 3D pose estimation [85].
Occupancy Maps or Occupancy Grids 占据地图和占据栅格 An occupancy grid is a type of probabilistic mask that returns for each cell of a gridded map of the environment the probability that the cell is occupied. This is another popular technique from robotics [119] that is used for localization and mapping in autonomous driving. It can be inferred from the camera and LlDAR data. Techniques for calculating the occupancy grid vary, and have been mainly based on ad-hoc methods, even if currently DL based approaches have also been used, e.g. for subsequent classification of likely objects or the road type [120], [121].
2.4.2. Planning 规划
Planning tasks comprise all the calculations needed to perform vehicle actions autonomously, from route planning to the implementation of an immediate motion trajectory in a given driving situation. They are confronted with the difficulty to evaluate correctly the system predictions: Contrary to perception tasks, where the ground-truth information is usually known and can be compared with predictions, assessing the performances of plann ing systems requires a real world testing in controlled environments, or an evaluation stage in a simulator. Even under these challenging settings, Avs are able to handle most situations, but may fail to take the right decision in the model, or the simulations. The reasoning functhe model, or the simulations. The reasoning funcautonomous agents and robotics [122], [123].
2.4.2.1 Route planning 路线规划
Route planning (or routing), also called global planning, consists in finding the best route between the current position of the vehicle and the destination that is requested by the user. It relies on GNSS coordinates and offline maps that are embedded in the vehicle. The road network is classically represented as a directed graph: nodes of the graph are way points, usually referring to intersections between roads, while edges correspond to the road segments, and are weighted to reflect the cost of traversing along this road, the cost being computed through a metric considering the distance of the segment and/or the time of travel. The problem is then to find the shortest path between two nodes of the graph. The output of route planning is then a sequence of way points that are used to generate the trajectory of the vehicle in the environment.
Several approaches have been developed to address this problem. Routing algorithms are usually relying on specialized heuristics [124] based on graph theory algorithms that have been developed to take into account the size of such graphs (usually several millions of edges) and circumvent the intractability of standard shortest-path algorithms. The efficiency of algorithmic graph solutions makes the use of Al techniques less relevant, albeit M L could be leveraged to adapt in real-time the topology of the graph with external information [125] or provide personalized routes that includes for example touristic sites [126].
2.4.2.2 Behavioural planning 行为规划
Behaviour planning implies to select what is the most appropriate driving behaviour to adopt for the vehicle, based on the representation of the environment and on the route to follow. Such a behaviour can be described as a sequence of high-level actions. As an example, if the route imposes to turn left at the following intersection, an appropriate behaviour could consist in a sequences of actions such as “Stop the vehicle before the intersection”, “Observe the behaviour of vehicles that are coming on the opposite lane and in the crossing lane”, “Detect any potential pedestrian that are about to cross the road”, and finally “Wait till the path is clear, and then turn left”. This decision-making process can be modelled by a finite state machine, where states are the different behaviours of the vehicle, and the transitions between states are governed by the perceived driving context.
One of the key tasks for behavioural modelling is the detection of the driving style of other agents. Driving style designates the various behaviours drivers can adopt while driving, classified with qualifying terms such as aggressive, sporty, calm, moderate, low-skill, or overcautious, to name but a few [127]. Recognising the behaviour adopted by a human-driven vehicle is crucial to understand its dynamics, and is in this respect closely related to the task of tracking the other moving agents. Furthermore, planning systems have to adopt themselves a driving style, possibly giving to the human user a choice between different presets, and find the right trade-off between a conservative driving that could lead to longer joumey and aggressive driving that could be unsafe and/or uncomfortable for the passengers. The learning of driving style is an important yet unexplored topic of research, mostly taking advantage of unsupervised approaches [128]-[130] to circurnvent the absence of labelled datasets. The use DL has considerably extended the range of modelling capabilities [131], using the vast amount of driving activities recorded by companies to provide simulating environments in which planning models leam to react to different driving scenarios, either by imitating human drivers [132], [133], or through deep reinforcement learning to perform safe and efficient driving [134], [135]
2.4.2.3 Motion planning 运动规划
Motion planning (or local planning) is responsible of finding the best trajectory of the vehicle in its perceived environment in accordance to the route that has been calculated and the behaviour that has been selected. This consists in the translation of high-level actions into a sequence of way points referring in the coordinates of the perceived environment. This trajectory has to take into account several constraints, such as being feasible by the vehicle (taking into account for example the current speed), being safe, lawful and respectful to other participants present in the environment, as well as ensuring a smooth driving for the passenger.
Traditional approaches have been developed in the robotics community. Typically, the environment is divided into a dynamic grid, where each cell has temporal attributes that are informed by the perception module. The objective is then to find a trajectory between two given cells under multiple constraints, relying on techniques based on graph search, sampling, or curve interpolation [117]. Recently, ML techniques have been employed for local planning, with promising results, in particular in their capacity to avoid erratic trajectories and achieve human-like motions. Generally, these approaches are addressing perception and planning at the same time, either through segmented image data including path proposals [136], or by extracting features from LIDAR point clouds [137]. DL has also been used solely for plarning, using RNNs to model sequences of waypoints of trajectories based on a dataset of human motions [138], or reinforcement leaming in simulated environments to leam a driving policy that can be extended to real-life situations [139].
ML has achieved tremendous progress in local planning, but has not yet reached a level of maturity sufficient to be implemented in commercial cars. A major limitation is indeed the difficulty to make sure that safety measures are properly learnt, as they cannot be hard-coded in the planning systems as for traditional systems. Nonetheless, their flexibility and they capacity to adapt to unknown situations, provided the context is similar to the one in which the model has been trained, are a strong argument in favour of future deployment of ML based planners.
2.4.3 Control 控制
The control system is responsible for the execution of the trajectory that has been calculated by the plarning system by applying commands for the various actuators of the vehicle at the hardware level Broadly speaking, a vehicle has two types of motions: lateral, controlled by the steering of the vehicle, and longitudinal, controlled by the gas and brake pedals.
Control techniques regroup a set of methods to monitor the dynamics of a system, in order to achieve a given action, while satisfying a set of constraints. Such systems act in a closed loop manner, with an objective value (e.g. a desired speed) prescribed to the controller, which has the ability to actuate on the systems (e.g. through braking and acceleration), while getting feedback through monitoring to ensure an optimal and stable trajectory of the dynamics of the system. Two popular approaches are Proportional-Integral-Derivative (PID) control [140] and Model predictive control (MPC) [141]. The former consists in continuously calculating the difference between the desired and the measured values of the controlled variable by tuning the relative importance between three different terms, describing corrections to apply to get an accurate and smooth trajectory. The latter relies on predictions of the changes of the controlled value, based on a model of the system. Compared to PID controller, it is costlier in terms of complexity, ics has a higher variability, or the delays between actions and feedbacks are higher.
In the case of AVs, the main difficulty lies in the high complexity of the relationships between controlled variables (such as speed or steering angle) and actual commands to actuators. Human drivers, with their experience and their understanding of the physical world, are constantly monitoring the movement of the vehicle, and the different indicators, such as the speedometer, to correct and make sure the behaviour of the vehicle is compliant with their intentions. By doing that, they integrate implicitly parameters as complex as the total weight of the vehicle, the friction forces of the tires on the road, or the wind intensity, through their sensory perception and their modelling of the environment. While it is straightforward to formalize an accurate model between the actuators and the actual behaviour of the vehicle at low speed, additional factors linked to the environment strongly increase the complexity of this model at high speed. Nonlinear control or model predictive control have to be used to take into account this complexity. To this end, ML techniques have already shown great potential to improve the predictive power of control models, albeit as of now they are not deployed in commercial vehicles.
2.4.4 Infotainment and vehicle interior monitoring
Al is not confined to driving functions, and has also been proven useful in infotainment systems and vehicle interior monitoring. These features are starting to be increasingly integrated in modem vehicles [142], [143], offering embedded hardware dedicated to voice recognition, or personal assistant controllable via vocal control and facial expressions.
Human machine interface (HMI) It provides passengers the ability to interact with the car, either to give commands to the driving or entertainment systems for instance, or to receive information, such as the current itinerary. DL is used to provide novel communication vectors, such as speech or gestures. Speech recognition embedded in vehicles are able to understand spoken commands that follows the syntax of normal spoken conversation. Gesture recognition systems are able to interpret common hand gestures, so that gesture based controls become applicable to interactive displays. Recommendation systems to anticipate the choice of users can also be included as part of HMI systems.
Vehicle interior monitoring It consists in monitoring the interior of the vehicle through sensors (e.g. cameras, microphones, temperature sensors, etc.) to ensure the general comfort of passengers. This function has been originally designed to monitor drivers’ fatigue, through the monitoring of driver behaviour. Therefore, real-time analysis of biometric factors (e.g. heart rate, respiratory rate, eye blinking, etc) could trigger a warning alarm to alert the driver. For fully AVs, this function could be used to control the level of comfort, by automatically adjusting sounds, lights, or any additional factors based on predictive models of the well-being of human passengers.
2.4.5 Current trends in Al research for autonomous driving
End-to-end approaches: A general trend in ML is the use of an end-to-end, holistic approach to tackle several problems at the same time. The rationale behind this approach is that developing separate modules tend to be inefficient in terms of computational power, but also may lead to poorer performance, as uncertainties appearing in the upstream section of the driving pipeline are propagated and amplified along all modules. Several variants of this approach exist a popular one is to consider jointly all tasks of perception or planning, or even all tasks from both modules altogether. Nonetheless, the approach relies on a wide diversity of techniques, ranging from the prediction of driving paths from camera images [136], point clouds, GNSS measurements, and or external information [137], to the prediction of steering commands from the same kind of inputs [144]. Behaviours can also be predicted in an end-to-end fashion from raw pixels [145], [146].
机器学习的总体趋势,是使用端到端的、全面的方法,来同时处理多个问题。
Simulation: The cost of data acquisition has led to the development of many simulators, in order to address large quantities of data. These simulation environments, many of them released as open-source software, also lowered the upfront investment necessary to do research on AVs, and have been the basis for numerous research works, some of them described in this report. Popular simulators include TORCS [147], CARLA [148] and AirSim [149], which take advantage of graphics engine used in video games to offer a realistic representation of the world. These simulators, as well as others [150] also include tools to customize sensors (e.g. cameras or LIDARs [151]), offer typical driving scenarios to play, and provide easy integration of \mathrm{ML} tools for quick development. Other initiatives have been launched to promote autonomous driving research towards students and tech enthusiasts, such as DeepTraffic [152].
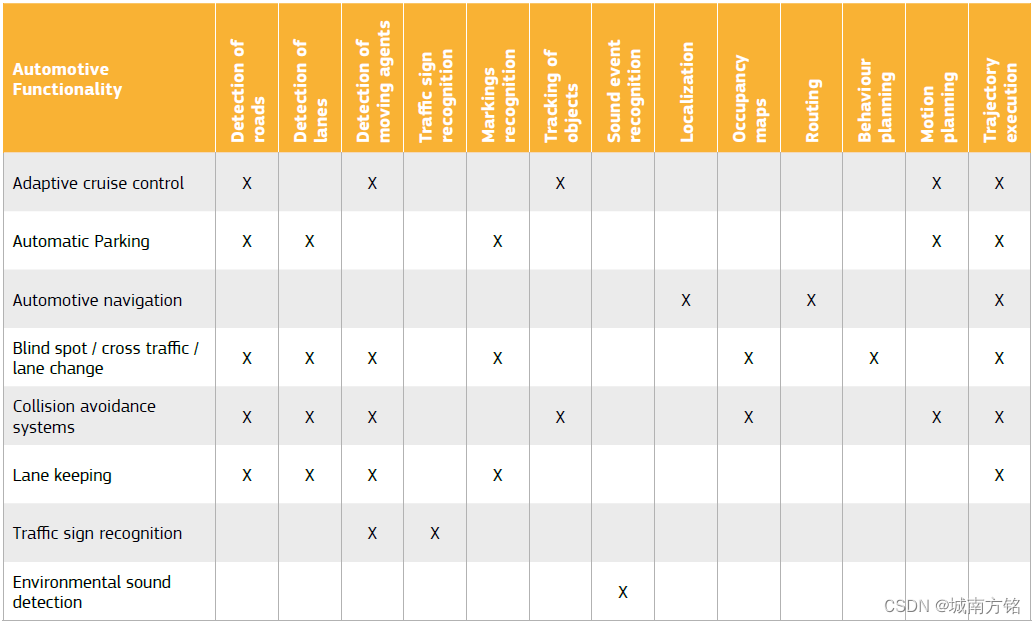
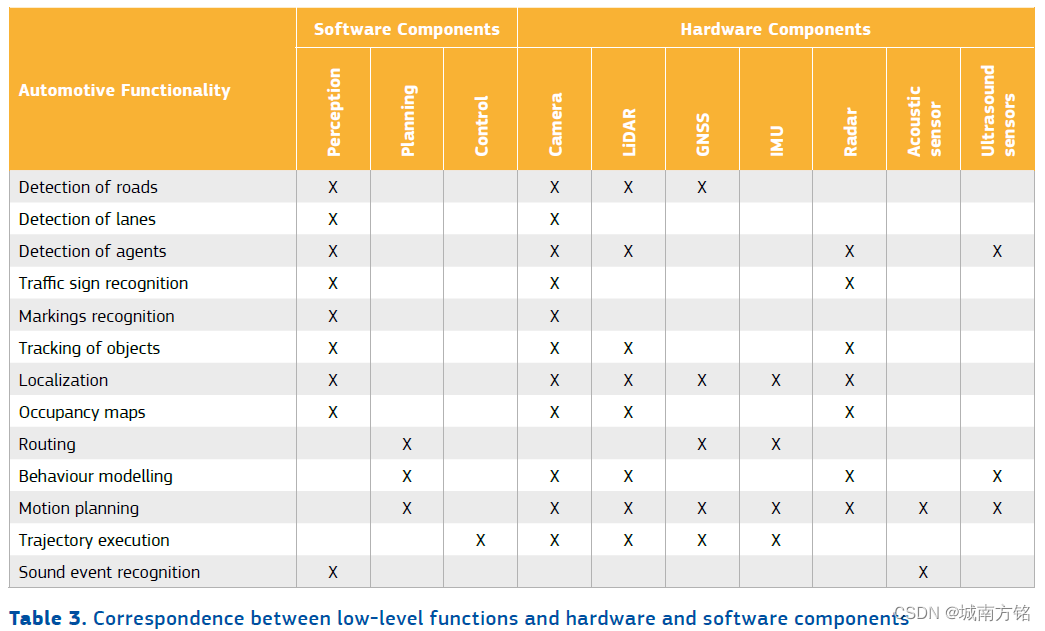
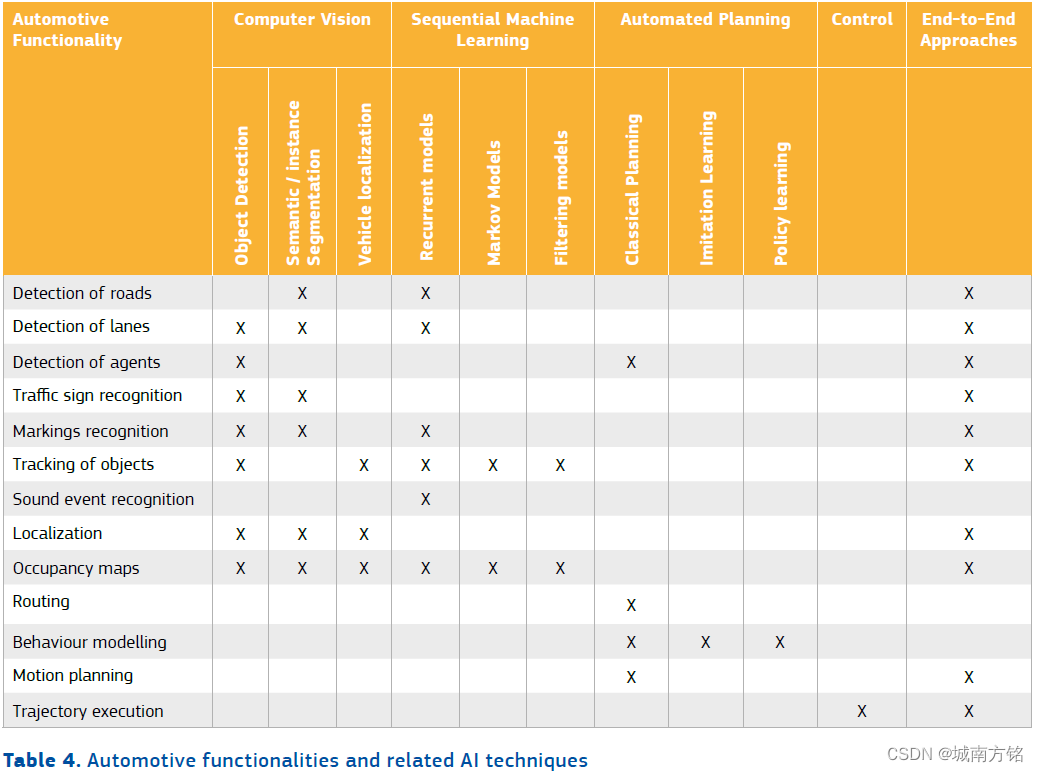
2.5 Mapping between automotive functionalities, hardware and software components and Al techniques
As a conclusion of this section, the most important key findings are summarized in the form of three tables. First, a correspondence between the high-level functionalities and the intermediate tasks is given. Then these tasks are mapped respectively with the hardware and software components that have been identified, and finally with the Al techniques.