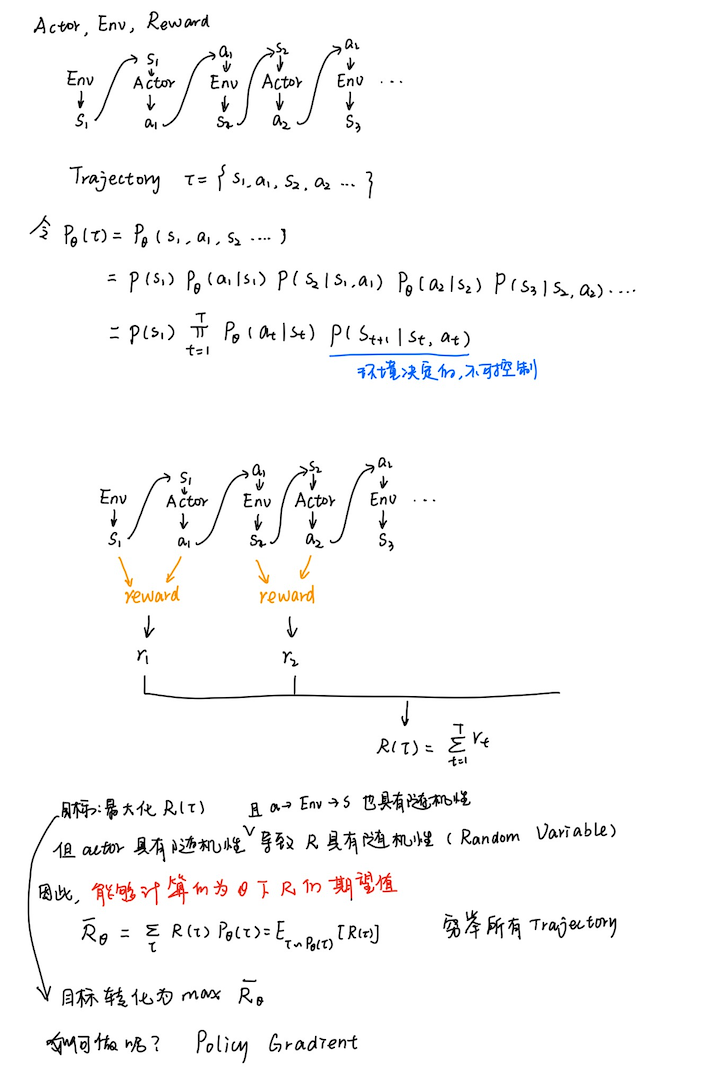
不同于value-based方法的 q π ( s , a ) q_{\pi}(s,a) qπ(s,a),policy-base方法可以解决连续的动作,因为 π ( a ∣ s ) \pi(a|s) π(a∣s)是一个连续的函数。
策略梯度




Proximal Policy Optimization(PPO)
关于[[重要性采样]]




PPO的两种算法都可以使得收集数据的模型(行为策略)和要更新的模型(目标策略)差距不大。
PPO的优化目标涉及到了重要性采样,可为什么PPO是on-policy呢?
- 虽然PPO使用了重要性采样,但是只用到了上一轮策略 θ \theta θ’的数据,PPO目标函数中添加了KL约束,行为策略和目标策略非常接近,因此,行为策略和目标策略可以认为是同一个策略,是on-policy
参考
https://datawhalechina.github.io/easy-rl/#/chapter5/chapter5
原论文
PPO实现CarPole-v1
PPO实现BipedalWalker-v3(连续动作)
https://blog.csdn.net/weixin_47471559/article/details/125593870
The 37 Implementation Details of Proximal Policy Optimization
动手学强化学习
动手学强化学习代码实现