在NVIDIA(CUDA,CUBLAS)和Intel MKL上快速实现BERT推理
直接在NVIDIA(CUDA,CUBLAS)或Intel MKL上进行高度定制和优化的BERT推理,而无需tensorflow及其框架开销。
仅支持BERT(转换器)。
基准测试
环境
• Tesla P4
• 28 * Intel® Xeon® CPU E5-2680 v4 @ 2.40GHz
• Debian GNU/Linux 8 (jessie)
• gcc (Debian 4.9.2-10+deb8u1) 4.9.2
• CUDA: release 9.0, V9.0.176
• MKL: 2019.0.1.20181227
• tensorflow: 1.12.0
• BERT: seq_length = 32

注意:应该在下面运行MKLOMP_NUM_THREADS=?来控制其线程号。其他环境变量及其可能的值包括:
• KMP_BLOCKTIME=0
• KMP_AFFINITY=granularity=fine,verbose,compact,1,0
混合精度
NVIDIA Volta和Turing GPU上的Tensor Core 和Mixed Precision可以加速cuBERT 。支持混合精度作为存储在fp16中的变量,并在fp32中进行计算。与单精度推理相比,典型的精度误差小于1%,而速度则达到了2倍以上的加速度。
API
API .h标头
Pooler
支持以下2种pooling方法。
• 标准BERT pooler,定义为:
with tf.variable_scope(“pooler”):
We “pool” the model by simply taking the hidden state corresponding
to the first token. We assume that this has been pre-trained
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
• Simple average pooler:
self.pooled_output = tf.reduce_mean(self.sequence_output, axis=1)
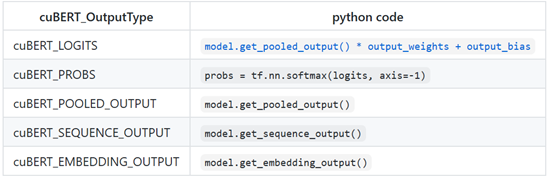
输出量
支持以下输出:
从源构建Build from Source mkdir build && cd build
if build with CUDA
cmake -DCMAKE_BUILD_TYPE=Release -DcuBERT_ENABLE_GPU=ON -DCUDA_ARCH_NAME=Common …
or build with MKL
cmake -DCMAKE_BUILD_TYPE=Release -DcuBERT_ENABLE_MKL_SUPPORT=ON …
make -j4
install to /usr/local
it will also install MKL if -DcuBERT_ENABLE_MKL_SUPPORT=ON
sudo make install
也将安装MKL
如果想运行tfBERT_benchmark进行性能比较,首先从https://www.tensorflow.org/install/lang_c安装tensorflow C API 。
运行单元测试
从 Dropbox下载BERT测试模型bert_frozen_seq32.pb和vocab.txt,然后将它们放在dir下build,运行make test or ./cuBERT_test。
thread
Cython提供的简单Python包装器,可以按如下所示在C ++构建之后构建和安装:
cd python
python setup.py bdist_wheel
install
pip install dist/cuBERT-xxx.whl
test
python cuBERT_test.py
在cuBERT_test.py中检查Python API的用法和示例,获取更多详细信息。
Java
Java包装器是通过JNA实现的 。安装maven和C ++构建后,可以按以下步骤构建:
cd java
mvn clean package # -DskipTests
当使用Java JAR,需要指定jna.library.path的位置libcuBERT.so,如果没有安装到系统路径。并且jna.encoding应像-Djna.encoding=UTF8 JVM启动脚本中一样设置为UTF8 。
在ModelTest.java中检查Java API的用法和示例,获取更多详细信息。
安装
可以按以下方式安装预构建的python二进制软件包(当前仅在Linux上与MKL一起安装):
• 下载MKL并将其安装到系统路径。
• 下载wheel package包, pip install cuBERT-xxx-linux_x86_64.whl
• 运行python -c 'import libcubert’以验证安装。
相依性Dependency
Protobuf
cuBERT是使用protobuf-c构建的,以避免版本和代码与tensorflow protobuf冲突。
CUDA
CUDA编译具有不同版本的库不兼容。
MKL
MKL是动态链接的。使用sudo make install安装cuBERT和MKL 。
Threading
假设cuBERT的典型用法是在线服务,其中应尽快处理不同batch_size的并发请求。因此,吞吐量和延迟应保持平衡,尤其是在纯CPU环境中。
vanilla class Bert类Bert由于其内部用于计算的缓冲区而不是线程安全的,因此 编写了wrapper class BertM来保存不同Bert实例的锁,以确保线程安全。 BertM会以循环方式选择一个基础Bert实例,并且同一Bert实例的结果请求可能会被其相应的锁排队。
显卡
一个Bert放在一张GPU卡上。最大并发请求数是一台计算机上可用的GPU卡数量,CUDA_VISIBLE_DEVICES如果指定,则可以控制该数量。
CPU
对于纯CPU环境,它比GPU更复杂。有2个并行级别:
- 请求级别。如果在线服务器本身是多线程的,并发请求将竞争CPU资源。如果服务器是单线程的(例如Python中的某些服务器实现),事情将会变得容易得多。
- 操作级别。矩阵运算由OpenMP和MKL并行化。最大并行被控制OMP_NUM_THREADS, MKL_NUM_THREADS和许多其他的环境变量。建议用户首先阅读在多线程应用程序中使用线程化英特尔®MKL 和建议的设置以从多线程应用程序中调用英特尔MKL例程 。
因此,引入CUBERT_NUM_CPU_MODELS,更好地控制请求级别并行性的方法。此变量指定Bert在CPU /内存上创建的实例数,其作用类似于CUDA_VISIBLE_DEVICESGPU。
• 如果CPU核心数量有限(旧的或台式机CPU,或在Docker中),则无需使用CUBERT_NUM_CPU_MODELS。例如4个CPU内核,请求级并行度为1,操作级并行度为4,应该可以很好地工作。
• 但是,如果有许多CPU核心(例如40),则最好尝试使用5的请求级并行度和8的操作级并行度。
总而言之,OMP_NUM_THREADS或MKL_NUM_THREADS定义一个模型可以使用多少个线程,并CUBERT_NUM_CPU_MODELS定义总共有多少个模型。
同样,每个请求的延迟和总体吞吐量应该保持平衡,并且与model seq_length,batch_sizeCPU核心,服务器QPS和许多其他事情有所不同。应该采用很多基准来实现最佳折衷。