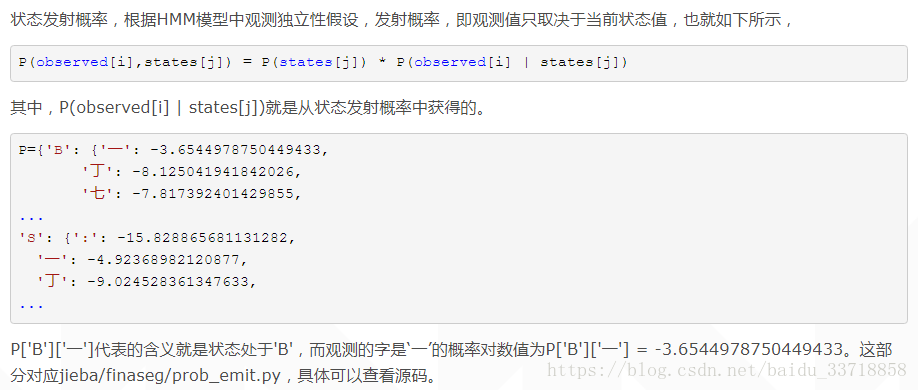
Pytorch学习记录-torchtext和Pytorch的实例1
0. PyTorch Seq2Seq项目介绍
1. 使用神经网络训练Seq2Seq
1.1 简介,对论文中公式的解读
1.2 数据预处理
我们将在PyTorch中编写模型并使用TorchText帮助我们完成所需的所有预处理。我们还将使用spaCy来协助数据的标记化。
# 引入相关库
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import random
import math
import time
SEED=1234
random.seed(SEED)
torch.manual_seed(SEED)
# 训练模型个人的基本要求是deterministic/reproducible,或者说是可重复性。也就是说在随机种子固定的情况下,每次训练出来的模型要一样。之前遇到了两次不可重复的情况。第一次是训练CNN的时候,发现每次跑出来小数点后几位会有不一样。epoch越多,误差就越多
# 确定性卷积:(相当于把所有操作的seed=0,以便重现,会变慢)
torch.backends.cudnn.deterministic=True
加载spacy的英、德库,我只能说大陆的网太慢了,德文包11mb我下了2个小时……
spacy_de=spacy.load('de')
spacy_en=spacy.load('en')
创建分词方法,这些可以传递给TorchText并将句子作为字符串接收并将句子作为标记列表返回。
在论文中,他们发现扭转输入顺序是有益的,他们认为“在数据中引入了许多短期依赖关系,使优化问题变得更加容易”。在德文(输入端)进行了扭转。
def tokenize_de(text):return [tok.text for tok in spacy_de.tokenizer(text)][::-1]
def tokenize_en(text):return [tok.text for tok in spacy_en.tokenizer(text)]# 这里增加了<sos>和<eos>
SRC=Field(tokenize=tokenize_de,init_token='<sos>',eos_token='<eos>',lower=True
)
TRG=Field(tokenize=tokenize_en,init_token='<sos>',eos_token='<eos>',lower=True
)
接下来使用英文和德文的平行语料库Multi30k dataset,使用这个语料库加载成为训练、验证、测试数据。下载地址见评论。
exts指定使用哪种语言作为源和目标(源首先),字段指定用于源和目标的字段。
train_data, valid_data, test_data=Multi30k.splits(exts=('.de','.en'),fields=(SRC,TRG))
可以对下载的数据集进行验证,前面的exts和fields做的是加标签,同时对数据集进行切分。下面对切分结果进行验证,可以看到,train_data的例子中,src是德文输入,trg是英文输出。
接下来,我们将为源语言和目标语言构建词汇表。词汇表用于将每个唯一令牌与索引(整数)相关联,这用于为每个令牌构建一个热门编码(除了索引所代表的位置之外的所有零的向量,即1)。源语言和目标语言的词汇表是截然不同的。
使用min_freq参数,我们只允许至少出现2次的标记出现在我们的词汇表中。仅出现一次令牌转换成<UNK>(未知)令牌。
要注意的是,词汇表只能从训练集而不是验证/测试集构建。这可以防止“信息泄漏”进入您的模型,为您提供人为夸大的验证/测试分数。
print(f"Number of training examples: {len(train_data.examples)}")
print(f"Number of validation examples: {len(valid_data.examples)}")
print(f"Number of testing examples: {len(test_data.examples)}")
print(vars(train_data.examples[1]))
Number of training examples: 29000
Number of validation examples: 1014
Number of testing examples: 1000
{'src': ['.', 'antriebsradsystem', 'ein', 'bedienen', 'schutzhelmen', 'mit', 'männer', 'mehrere'], 'trg': ['several', 'men', 'in', 'hard', 'hats', 'are', 'operating', 'a', 'giant', 'pulley', 'system', '.']}
SRC.build_vocab(train_data,min_freq=2)
TRG.build_vocab(train_data,min_freq=2)
print(f"Unique tokens in source (de) vocabulary: {len(SRC.vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(TRG.vocab)}")
Unique tokens in source (de) vocabulary: 7855
Unique tokens in target (en) vocabulary: 5893
最后一步是迭代器,使用BucketIterator处理。
我们还需要定义一个torch.device。这用于告诉TorchText将张量放在GPU上。我们使用torch.cuda.is_available()函数,如果在我们的计算机上检测到GPU,它将返回True。我们将此设备传递给迭代器。
当我们使用迭代器获得一批示例时,我们需要确保所有源句子都填充到相同的长度,与目标句子相同。幸运的是,TorchText迭代器为我们处理这个问题。我们使用BucketIterator而不是标准迭代器,因为它以这样的方式创建批处理,以便最小化源句和目标句子中的填充量。
device=torch.device('cpu')
print(device)
BATCH_SIZE=128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits((train_data, valid_data, test_data), batch_size = BATCH_SIZE, device = -1)
cpuThe `device` argument should be set by using `torch.device` or passing a string as an argument. This behavior will be deprecated soon and currently defaults to cpu.
The `device` argument should be set by using `torch.device` or passing a string as an argument. This behavior will be deprecated soon and currently defaults to cpu.
The `device` argument should be set by using `torch.device` or passing a string as an argument. This behavior will be deprecated soon and currently defaults to cpu.
1.3 构建Seq2Seq模型
将Seq2Seq模型分为三部分:Encoder、Decoder、Seq2Seq,每个模块之间使用接口进行操作
1.3.1 Encoder
encoder是一个2层的LSTM(原论文为4层),对于一个多层的RNN,输入句子X在底层,这一层的输出作为上层的输入。因此,使用上标来表示每一层。下面公式表示的第一层和第二层的隐藏状态 转存失败重新上传取消转存失败重新上传取消
转存失败重新上传取消转存失败重新上传取消
使用多层RNN同样也意味着需要赋予一个初始的隐藏状态转存失败重新上传取消,并且每层要输出对应的上下文向量
转存失败重新上传取消。
我们需要知道的是,LSTM是一种RNN,它不是仅仅处于隐藏状态并且每个时间步返回一个新的隐藏状态,而是每次接收并返回一个单元状态转存失败重新上传取消。
转存失败重新上传取消
我们的上下文向量现在将是最终隐藏状态和最终单元状态,即转存失败重新上传取消。将我们的多层方程扩展到LSTM,我们得到下面的公式。
转存失败重新上传取消
请注意,我们只将第一层的隐藏状态作为输入传递给第二层,而不是单元状态。
下面重点来了,encoder有哪些参数
- input_dim输入encoder的one-hot向量维度,这个和输入词汇大小一致
- emb_dim嵌入层的维度,这一层将one-hot向量转为密度向量
- hid_dim隐藏层和cell状态维度
- n_layersRNN的层数
- dropout是要使用的丢失量。这是一个防止过度拟合的正则化参数。
教程中不讨论嵌入层。在单词之前还有一个步骤 - 单词的索引 - 被传递到RNN,其中单词被转换为向量。
嵌入层使用nn.Embedding,带有nn.LSTM的LSTM和带有nn.Dropout的dropout层创建。
需要注意的一点是LSTM的dropout参数是在多层RNN的层之间应用多少丢失,即在层转存失败重新上传取消输出的隐藏状态和用于输入的相同隐藏状态之间。 layer
转存失败重新上传取消。
在forward方法中,我们传入源句子转存失败重新上传取消,使用嵌入层将其转换为密集向量,然后应用dropout。然后将这些嵌入传递到RNN。当我们将整个序列传递给RNN时,它会自动为整个序列重复计算隐藏状态!您可能会注意到我们没有将初始隐藏或单元状态传递给RNN。这是因为,如文档中所述,如果没有将隐藏/单元状态传递给RNN,它将自动创建初始隐藏/单元状态作为全零的张量。
RNN返回:输出(每个时间步的顶层隐藏状态),隐藏(每个层的最终隐藏状态,转存失败重新上传取消,堆叠在彼此之上)和单元格(每个层的最终单元状态) ,
转存失败重新上传取消,叠加在彼此之上)。
由于我们只需要最终隐藏和单元格状态(以制作我们的上下文向量),因此只返回隐藏和单元格。
每个张量的大小在代码中留作注释。在此实现中,n_directions将始终为1,但请注意,双向RNN(在教程3中介绍)将具有n_directions为2。
class Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):super(Encoder,self).__init__()self.input_dim=input_dimself.emb_dim=emb_dimself.hid_dim=hid_dimself.n_layers=n_layersself.dropout=dropoutself.embedding=nn.Embedding(input_dim,emb_dim)self.rnn=nn.LSTM(emb_dim,hid_dim,n_layers,dropout=dropout)self.dropout=nn.Dropout(dropout)def forward(self, src):embedded=self.dropout(self.embedding(src))outputs, (hidden,cell)=self.rnn(embedded)return hidden ,cell
1.3.2 Decoder
Decoder同样也是一个两层的LSTM。
Decoder只执行一个解码步骤。第一层将从前一个时间步,接收隐藏和单元状态,并通过将当前的token 喂给LSTM,进一步产生一个新的隐藏和单元状态。后续层将使用下面层中的隐藏状态,,以及来自其图层的先前隐藏和单元状态,。这提供了与编码器中的方程非常相似的方程。
另外,Decoder的初始隐藏和单元状态是我们的上下文向量,它们是来自同一层的Encoder的最终隐藏和单元状态
接下来将隐藏状态传递给Linear层,预测目标序列下一个标记应该是什么。
Decoder的参数和Encoder类似,其中output_dim是将要输入到Decoder的one-hot向量。
在forward方法中,获取到了输入token、上一层的隐藏状态和单元状态。解压之后加入句子长度维度。接下来与Encoder类似,传入嵌入层并使用dropout,然后将这批嵌入式令牌传递到具有先前隐藏和单元状态的RNN。这产生了一个输出(来自RNN顶层的隐藏状态),一个新的隐藏状态(每个层一个,堆叠在彼此之上)和一个新的单元状态(每层也有一个,堆叠在彼此的顶部) )。然后我们通过线性层传递输出(在除去句子长度维度之后)以接收我们的预测。然后我们返回预测,新的隐藏状态和新的单元状态。
class Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):super(Decoder,self).__init__()self.emb_dim=emb_dimself.hid_dim=hid_dimself.output_dim=output_dimself.n_layers=n_layersself.dropout=dropoutself.embedding=nn.Embedding(output_dim,emb_dim)self.rnn=nn.LSTM(emb_dim,hid_dim,n_layers,dropout=dropout)self.out=nn.Linear(hid_dim,output_dim)self.dropout=nn.Dropout(dropout)def forward(self, input,hidden,cell):input=input.unsqueeze(0)embedded=self.dropout(self.embedding(input))output, (hidden,cell)=self.rnn(embedded,(hidden,cell))prediction=self.out(output.squeeze(0))return prediction,hidden ,cell
1.3.3 Seq2Seq
最后一部分的实现,seq2seq。
- 接收输入/源句子
- 使用Encoder生成上下文向量
- 使用Decoder生成预测输出/目标句子
再看一下整体的模型image.png
确定Encoder和Decoder每一层的数目、隐藏层和单元维度相同。
我们在forward方法中做的第一件事是创建一个输出张量,它将存储我们所有的预测,转存失败重新上传取消。
然后,我们将输入/源语句转存失败重新上传取消/ src输入编码器,并接收最终的隐藏和单元状态。
解码器的第一个输入是序列的开始(<sos>)令牌。由于我们的trg张量已经附加了<sos>标记(当我们在TRG字段中定义init_token时一直回来),我们通过切入它来得到转存失败重新上传取消。我们知道我们的目标句子应该是多长时间(max_len),所以我们循环多次。在循环的每次迭代期间,我们:
- 将输入,先前隐藏和前一个单元状态(转存失败重新上传取消
)传递给Decoder。
- 接收预测,来自Decoder下一个隐藏状态和下一个单元状态(转存失败重新上传取消
)
- 将我们的预测,转存失败重新上传取消
/输出放在我们的预测张量中,
转存失败重新上传取消/ outputs
- 决定我们是否要“教师强制”。
- 如果我们这样做,下一个输入是序列中的groundtruth下一个标记,转存失败重新上传取消
/ trg [t]
- 如果我们不要,下一个输入是序列中预测的下一个标记,转存失败重新上传取消
- 如果我们这样做,下一个输入是序列中的groundtruth下一个标记,
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder, device):super(Seq2Seq,self).__init__()self.encoder = encoderself.decoder = decoderself.device = deviceassert encoder.hid_dim == decoder.hid_dim, \"Hidden dimensions of encoder and decoder must be equal!"assert encoder.n_layers == decoder.n_layers, \"Encoder and decoder must have equal number of layers!"def forward(self, src,trg,teacher_forcing_ratio=0.5):# src = [src sent len, batch size]# trg = [trg sent len, batch size]# teacher_forcing_ratio是使用教师强制的概率# 例如。如果teacher_forcing_ratio是0.75,我们75%的时间使用groundtruth输入batch_size=trg.shape[1]max_len=trg.shape[0]trg_vocab_size=self.decoder.output_dimoutputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device)hidden, cell=self.encoder(src)input=trg[0,:]for t in range(1, max_len):output, hidden, cell = self.decoder(input, hidden, cell)outputs[t] = outputteacher_force = random.random() < teacher_forcing_ratiotop1 = output.max(1)[1]input = (trg[t] if teacher_force else top1)return outputs
1.4 训练模型
首先,我们将初始化我们的模型。如前所述,输入和输出维度由词汇表的大小定义。编码器和解码器的嵌入尺寸和丢失可以不同,但是层数和隐藏/单元状态的大小必须相同。
然后我们定义编码器,解码器,然后定义我们放置在设备上的Seq2Seq模型。
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc=Encoder(INPUT_DIM,ENC_EMB_DIM,HID_DIM,N_LAYERS,ENC_DROPOUT)
dec=Decoder(OUTPUT_DIM,DEC_EMB_DIM,HID_DIM,N_LAYERS,DEC_DROPOUT)
model=Seq2Seq(enc,dec,device)
def init_weights(m):for name, param in m.named_parameters():nn.init.uniform_(param.data, -0.08, 0.08)model.apply(init_weights)
Seq2Seq((encoder): Encoder((embedding): Embedding(7855, 256)(rnn): LSTM(256, 512, num_layers=2, dropout=0.5)(dropout): Dropout(p=0.5))(decoder): Decoder((embedding): Embedding(5893, 256)(rnn): LSTM(256, 512, num_layers=2, dropout=0.5)(out): Linear(in_features=512, out_features=5893, bias=True)(dropout): Dropout(p=0.5))
)
def count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)print(f'The model has {count_parameters(model):,} trainable parameters')
The model has 13,899,013 trainable parameters
optimizer = optim.Adam(model.parameters())
PAD_IDX = TRG.vocab.stoi['<pad>']
criterion = nn.CrossEntropyLoss(ignore_index = PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):model.train()epoch_loss = 0for i, batch in enumerate(iterator):src = batch.srctrg = batch.trgoptimizer.zero_grad()output = model(src, trg)#trg = [trg sent len, batch size]#output = [trg sent len, batch size, output dim]output = output[1:].view(-1, output.shape[-1])trg = trg[1:].view(-1)#trg = [(trg sent len - 1) * batch size]#output = [(trg sent len - 1) * batch size, output dim]loss = criterion(output, trg)print(loss.item())loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()epoch_loss += loss.item()return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):model.eval()epoch_loss = 0with torch.no_grad():for i, batch in enumerate(iterator):src = batch.srctrg = batch.trgoutput = model(src, trg, 0) #turn off teacher forcing#trg = [trg sent len, batch size]#output = [trg sent len, batch size, output dim]output = output[1:].view(-1, output.shape[-1])trg = trg[1:].view(-1)#trg = [(trg sent len - 1) * batch size]#output = [(trg sent len - 1) * batch size, output dim]loss = criterion(output, trg)epoch_loss += loss.item()return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):elapsed_time = end_time - start_timeelapsed_mins = int(elapsed_time / 60)elapsed_secs = int(elapsed_time - (elapsed_mins * 60))return elapsed_mins, elapsed_secs
N_EPOCHS = 2
CLIP = 1best_valid_loss = float('inf')for epoch in range(N_EPOCHS):start_time = time.time()train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
# valid_loss = evaluate(model, valid_iterator, criterion)end_time = time.time()epoch_mins, epoch_secs = epoch_time(start_time, end_time)# if valid_loss < best_valid_loss:
# best_valid_loss = valid_loss
# torch.save(model.state_dict(), 'tut1-model.pt')print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
# print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
8.671906471252441
8.567961692810059
8.38569450378418
7.892151832580566
7.042192459106445
6.31839656829834
6.088204383850098
5.77440881729126
5.662734508514404
5.574016571044922
。。。
在这里我做了处理,因为显存的问题,被迫把数据和模型都放在cpu上跑了,速度奇慢,所以我把评价和模型保存部分注释掉了。看来要尽快搞定基础的,然后选一个云平台了……
作者:我的昵称违规了
链接:https://www.jianshu.com/p/dbf00b590c70
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。

![[JS]在ACM模式下获取输入](/images/no-images.jpg)
![[JS][dfs]题解 | #迷宫问题#](https://img-blog.csdnimg.cn/9ec953d1e7db4c6a9d77550be1f1236d.png)