前言
本文翻译自UG474第二章,主要对7系列FPGAs CLB结构进行详细介绍。这些细节对设计优化和验证很有帮助。
CLB 排列
CLB 在 7 系列 FPGA 中按列排列。 7 系列是基于 ASMBL架构提供的独特柱状方法的第四代产品。ASMBL 架构 Xilinx 创建了高级硅模块块 (ASMBL) 架构,以支持具有针对不同应用领域优化的各种功能组合的 FPGA 平台。通过这项创新,Xilinx 提供了更多的器件选择,使客户能够选择具有适合其特定设计的特性和功能组合的 FPGA。下图提供了不同类型的基于列的资源的高级描述。
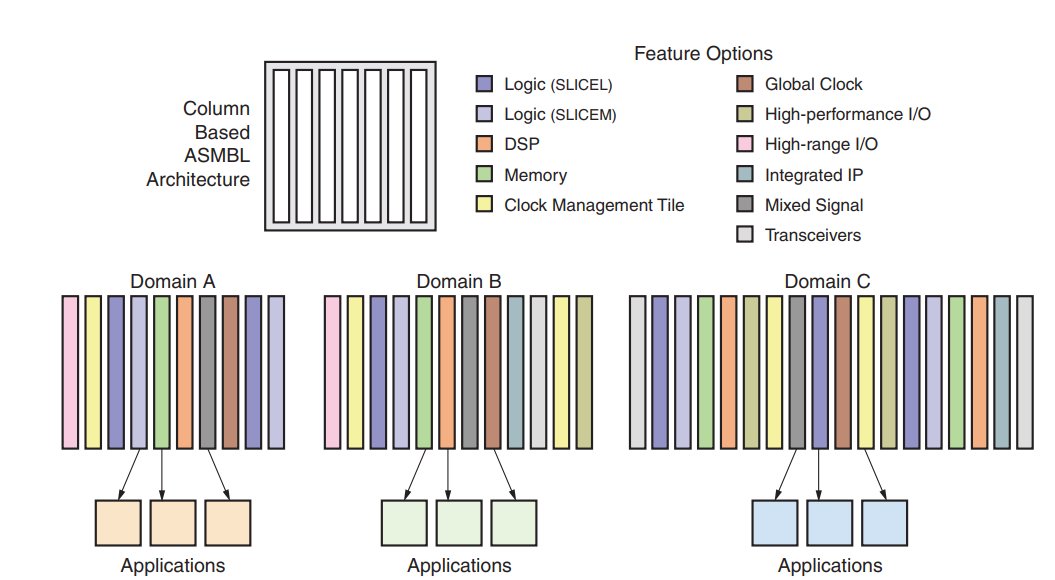
ASMBL 架构通过以下方式突破了传统的设计障碍:
- 消除了几何布局约束,例如 I/O 数量和阵列大小之间的依赖关系。
- 通过允许将电源和接地放置在芯片上的任何位置来增强片上电源和接地分布。
- 允许不同的集成IP 块独立于彼此和周围资源进行扩展。
CLB Slices
CLB 元素包含一对 Slice,每个 Slice 由四个 6 输入 LUT 和八个存储元素组成。
- SLICE(0) – CLB 底部和左列中的切片
- SLICE(1) – CLB 顶部和右列中的切片
这两个切片彼此之间没有直接连接,并且每个切片 slice 被组织为一列。 列中的每个切片都有一个独立的进位链。
Xilinx 工具使用以下定义指定切片:
- 后跟数字的“X”标识一对中每个切片的位置以及切片的列位置。 “X”号从底部开始按顺序 0、1(第一个 CLB 列)计数切片; 2、3(第二个CLB列);
- 后跟数字的“Y”标识一行切片 一个 CLB 中的数字保持不变,但从一个 CLB 行到下一个 CLB 行,从底部开始依次递增。
下图显示了位于芯片左下角的四个 CLB。

CLB/Slice 配置
下表总结了一个 CLB 中的逻辑资源。 每个 SLICEM LUT 都可以配置为查找表、分布式 RAM 或移位寄存器。
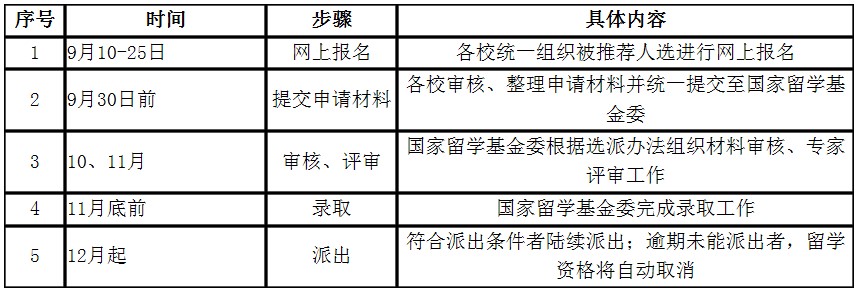
| Slices | LUTs | Flip-Flops | Arithmetic and Carry Chains | Distributed RAM | Shift Registers |
|---|---|---|---|---|---|
| 2 | 8 | 16 | 2 | 256 bits | 128 bits |
仅 SLICEM,SLICEL 没有分布式 RAM 或移位寄存器。
Slice 描述
每个 CLB 可以包含两个 SLICEL 或一个 SLICEL 和一个 SLICEM。
每个 Slice 包含:
- 四个逻辑函数发生器(查找表)
- 八个存储元件 (这里应该代表的为如FF的,存储器,该器件可以拓展成触发器、移位寄存器等功能。)
- 宽功能多路复用器
- 进位逻辑
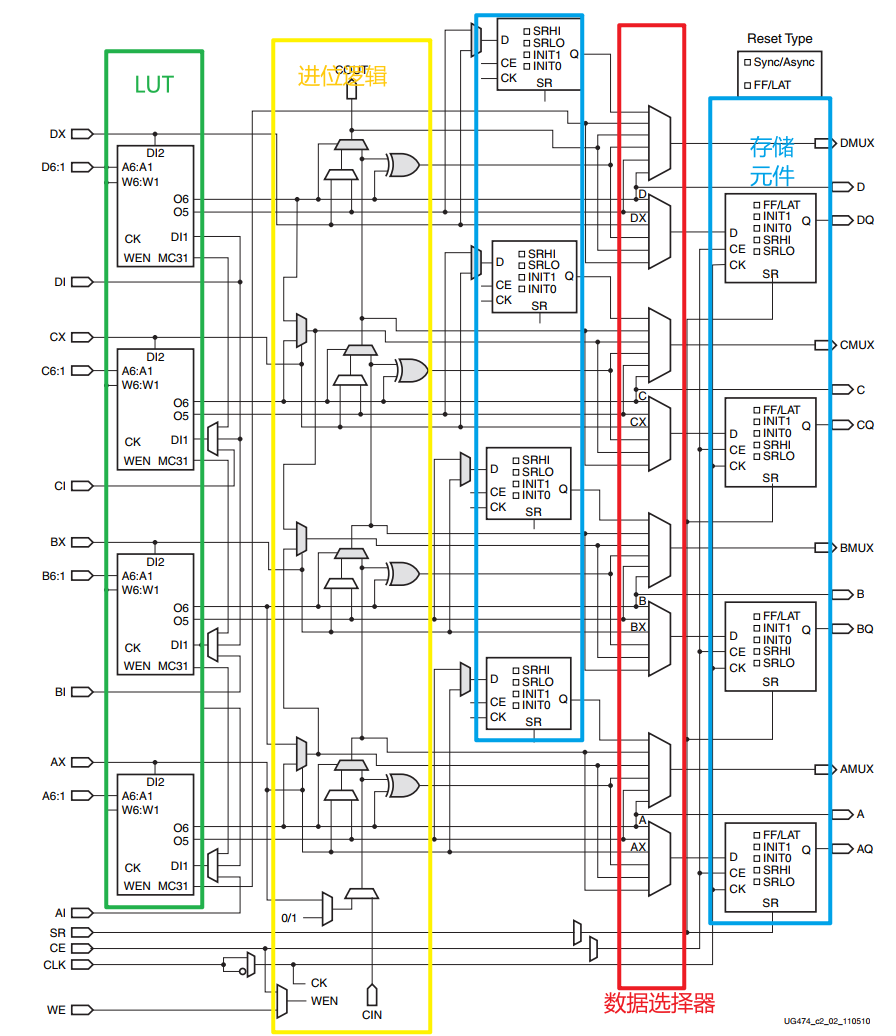
所有 Slice 都使用这些元件来提供逻辑、算术和 ROM 功能。此外,一些 slice 支持两个附加功能:使用分布式 RAM 存储数据和使用 32 位寄存器移位数据。 支持这些附加功能的切片称为 SLICEM; 其他的称为 SLICEL。 SLICEM表示所有切片中的元素和连接的超集,如下图所示。
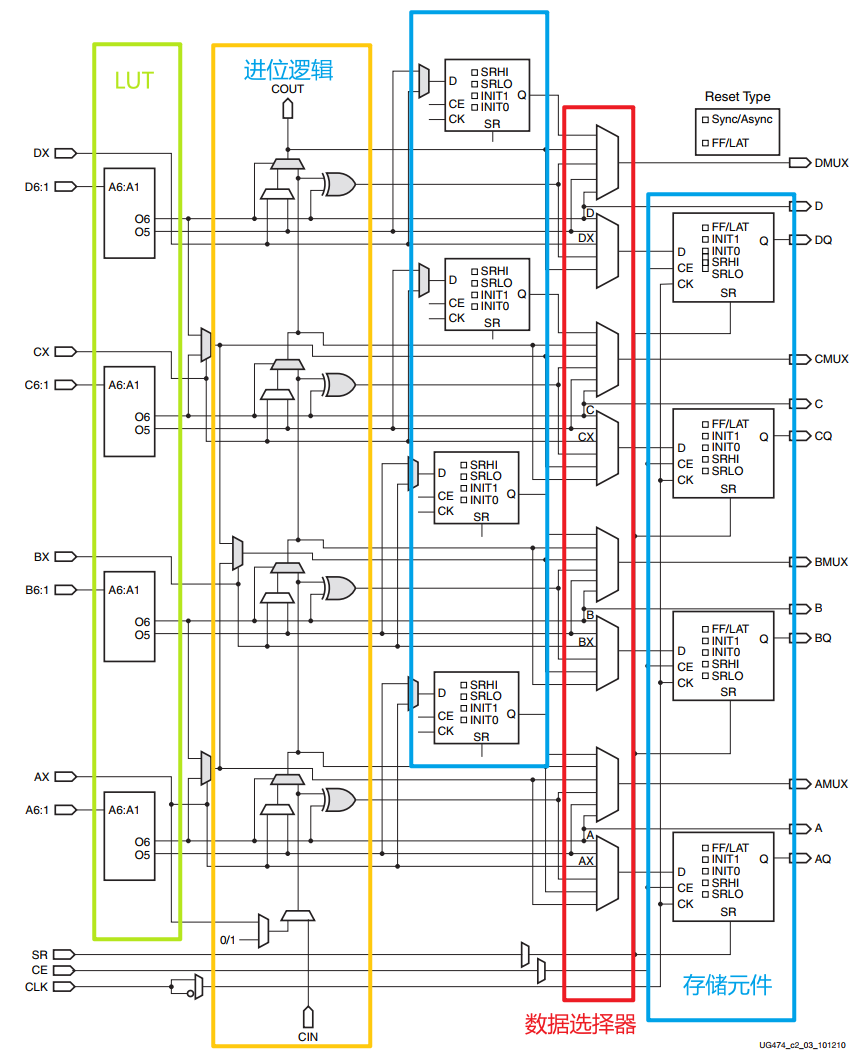
SLICEL 框图如下所示。
查找表 (LUT)
7 系列 FPGA 中的函数发生器实现为六输入查找表 (LUT)。片中的四个函数发生器(A、B、C 和 D)中的每一个都有六个独立的输入(A 输入 - A1 到 A6)和两个独立的输出(O5 和 O6)。 函数发生器可以实现:
- 任意定义的六输入布尔函数。
- 两个任意定义的五输入布尔函数,只要这两个函数共享公共输入。
- 两个任意定义的 3 和 2 输入或更少的布尔函数。
一个六输入功能使用:
- A1-A6 输入
- O6 输出
两个五输入或更少的功能使用:
- A1–A5 输入
- A6 驱动为高电平
- O5 和O6 输出
通过LUT 的传播延迟与所实现的功能无关。来自函数发生器的信号可以:
- slice的输出 (通过 A、B、C、D 输出用于 O6 或 AMUX、BMUX、CMUX、DMUX 输出用于 O5)
- 从 O6 输出进入 XOR 专用门
- 输入进位 - 来自 O5 输出的逻辑链
- 从 O6 输出进入进位逻辑多路复用器的选择线
- 馈入存储元件的 D 输入
- 从 O6 输出转到 F7AMUX/F7BMUX 宽多路复用器
除了基本 LUT,slice还包含三个多路复用器(F7AMUX、F7BMUX 和 F8MUX)。 这些多路复用器用于组合多达四个函数发生器,以在一个 Slice 中提供七个或八个输入的任何功能。
- F7AMUX:用于从LUT A 和B 生成七个输入函数。
- F7BMUX:用于从LUT C 和D 生成七个输入函数。
- F8MUX:用于组合所有LUT 以生成八个输入函数。
可以使用多个slice 来实现具有超过 8 个输入的功能。 片之间没有直接连接以在 CLB 内形成大于 8 个输入的函数发生器。
存储元素
每个片有八个存储单元。四个可以配置为边缘触发的D 型触发器或电平敏感的锁存器。存储单元的输入D可以通过AFFMUX、BFFMUX、CFFMUX或者DFFMUX 的 LUT 输出直接驱动,或者通过绕过函数发生器的旁路通道切片输入绕过函数发生器通过 AX、 BX、 CX 或者 DX 输入驱动。当配置为锁存器时,当 CLK 低时,锁存器是透明的。
还有四个额外的存储元件只能配置为边缘触发的 D 型触发器。D 输入可以由 LUT 的 O5输出驱动,也可以通过 AX、 BX、 CX 或 DX 输入驱动 BYPASS 片输入。当原始的四个存储元素配置为锁存器时,不能使用这四个额外的存储元素。
下图显示了一个片中的只有寄存器和寄存器/锁存器配置。

控制信号
控制信号时钟(CLK)、时钟使能(CE)和设置/复位(SR)对一个片区的所有存储元件是共同的。 一个片断中的所有存储元件共同使用。当一个片断中的一个触发器启用了SR或CE,片断中使用的其他触发器也会启用SR或CE。 当一个片中的一个触发器启用了SR或CE,该片中使用的其他触发器也通过公共信号启用了SR或CE。只有CLK 信号具有可编程的极性。任何放在时钟信号上的反相器都会被自动吸收。 吸收。CE和SR信号为高电平有效。
这些初始化选项适用于存储元件:
- SRLOW :当CLB SR信号被断言时,同步或异步复位。
- SRHIGH:当CLB SR信号被断言时,同步或异步设置。
- INIT0:上电时异步复位或全局设置/复位。
- INIT1:上电时异步设置或全局设置/复位。
| SR | SRVAL | Function |
|---|---|---|
| 0 | SRLOW (default) | No Logic Change |
| 1 | SRLOW (default) | 0 |
| 0 | SRHIGH | No Logic Change |
| 1 | SRHIGH | 1 |
SRHIGH和SRLOW可以为切片中的每个存储元素单独设置。同步(SYNC)或异步(ASYNC)设置/复位(SRTYPE)的选择不能为片中的每个存储元素单独设置。不能为片中的每个存储元素单独设置。
配置后的初始状态或全局初始状态是由单独的INIT0和 INIT1属性定义。默认情况下,设置SRLOW属性设置INIT0,设置SRHIGH属性设置INIT1。SRHIGH属性设置INIT1。7系列器件可以设置INIT0和INIT1,与SRHIGH和SRLOW无关。SRHIGH和SRLOW。
寄存器或四个存储元件的设置和复位功能的配置选项 能够作为锁存器运作的寄存器或四个存储元素的设置和复位功能的配置选项是:
- 无设置或复位
- 同步设置
- 同步复位
- 异步设置(预置)
- 异步复位(清除)
分布式RAM(仅在SLICEM中可用)
SLICEM中的函数发生器(LUT)可以作为一种同步RAM资源来实现,称为分布式RAM元件。一个SLICEM中的多个LUT可以以各种方式组合,以存储更多的数据。在一个SLICEM中,RAM元素是可以配置的,以实现这些配置:
- 单端口32 x 1位RAM
- 双端口32 x 1位RAM
- 四端口32 x 2位RAM
- 简单双端口32 x 6位RAM
- 单端口64 x 1位RAM
- 双端口64 x 1位RAM
- 四端口64 x 1位RAM
- 简单双端口64 x 3位RAM
- 单端口128 x 1位RAM
- 双端口128 x 1位RAM
- 单端口256 x 1位RAM
分布式RAM模块是同步(写)资源。同步读取可以用同一片中的一个触发器来实现。通过使用这个触发器,分布式RAM的性能得到了改善,因为减少了进入触发器的时钟到输出值的延迟。然而,增加了一个额外的时钟延时。分布式元件共享相同的时钟输入。对于写操作,由SLICEM的CE或WE引脚驱动的写启用(WE)输入必须被设置为高电平。
下表显示了每个分布式RAM配置所占用的LUT数量(每个片区4个)。
| RAM | Description | Primitive | Number of LUTs |
|---|---|---|---|
| 32 x 1S | Single port | RAM32X1S | 1 |
| 32 x 1D | Dual port | RAM32X1D | 2 |
| 32 x 2Q | Quad port | RAM32M | 4 |
| 32 x 6SDP | Simple dual port | RAM32M | 4 |
| 64 x 1S | Single port | RAM64X1S | 1 |
| 64 x 1D | Dual port | RAM64X1D | 2 |
| 64 x 1Q | Quad port | RAM64M | 4 |
| 64 x 3SDP | Simple dual port | RAM64M | 4 |
| 128 x 1S | Single port | RAM128X1S | 2 |
| 128 x 1D | Dual port | RAM128X1D | 4 |
| 256 x 1S | Single port | RAM256X1S | 4 |
分布式RAM的配置包括:
- 单端口
- 用于同步写和异步读的共同地址端口:读和写地址共享同一地址总线
- 双端口
- 一个端口用于同步写和异步读:一个函数发生器与共享的读写端口地址相连
- 一个端口用于异步读:第二个函数发生器的A输入与第二个只读端口地址相连,WA输入与第一个读/写端口地址共享
- 简单的双端口
- 一个端口用于同步写(没有数据输出/从写端口读出)。
- 一个用于异步读取的端口
- 四端口
- 一个端口用于同步写和异步读
- 三个端口用于异步读
公共写端口W6:W1(WA[6:1]在下面的数字中)总是由D LUT的输入使用D[6:1]进行物理驱动。读取端口对于四个LUT中的每一个都是独立的。因此D LUT总是有效的单端口,即使DPRAM64被选为LUT配置。其他三个LUT总是有效的双端口,尽管当读和写地址连接在一起时可以选择SPRAM32。
图 2-6 至图 2-14 说明了占用一个SLICEM的各种分布式RAM配置的例子。
图 2-6 给出了占用一个SLICEM的32 X 2 四端口RAM配置的例子。当使用x2配置时(如图2-6中的32 X 2四端口),A6和WA6被软件驱动为高电平,以保持O5和O6独立。

图 2-7 给出了占用一个SLICEM的32 X 6 双端口RAM配置的例子。

图 2-7 给出了占用一个SLICEM的64 X 1 单端口RAM配置的例子。

如果四个单端口64 x 1位模块分别如图 2-8 所示构建,则四个RAM64X1S基元可以占据一个SLICEM,只要它们共享相同的时钟、写使能和共享读写端口地址输入。这种配置相当于一个64 x 4位的单端口分布式RAM。

如果两个双端口64 x 1位模块分别如图 2-9 所示构建,那么两个RAM64X1D基元可以占用一个SLICEM,只要它们共享相同的时钟、写使能和共享读写端口地址输入。这种配置相当于一个64 x 2位的双端口分布式RAM。
图 2-7 给出了占用一个SLICEM的 64 X 1 四端口RAM配置的例子。

实现深度大于64的分布式RAM配置需要使用宽功能复用器(F7AMUX、F7BMUX和F8MUX),如图 2-12 至图 2-14 所示。
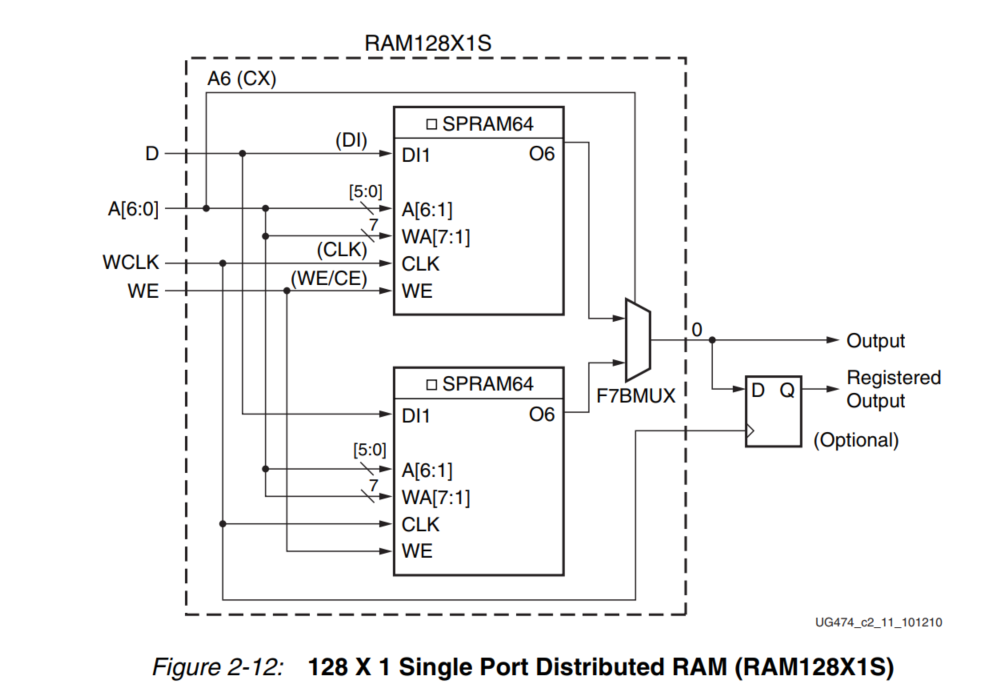
如果两个单端口128 x 1位模块如图 2-12 所示,两个RAM128X1S基元可以占用一个SLICEM,只要它们共享相同的时钟、写启用和共享读写端口地址输入。这种配置相当于128 x 2位单端口分布式RAM。
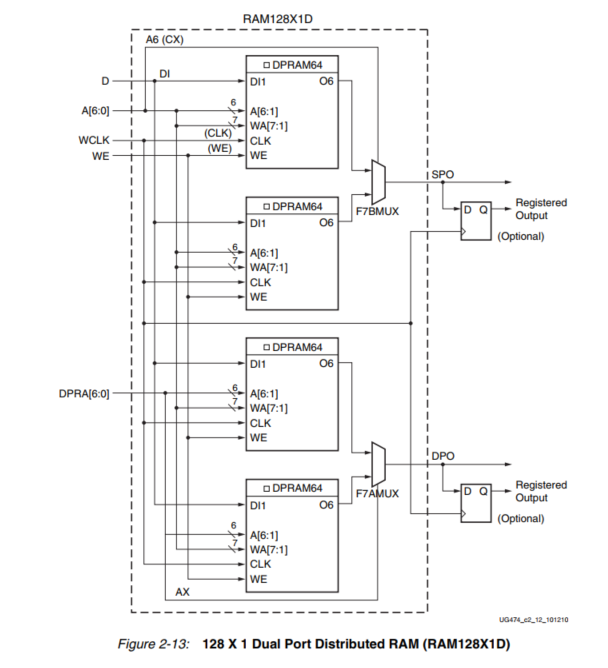

比所提供的例子更大的分布式RAM配置需要一个以上的SLICEM。片与片之间没有直接的连接,无法在CLB内或片与片之间形成更大的分布式RAM配置。
分布式RAM的数据流
同步写操作
同步写操作是一个具有高电平写入功能(WE)的单时钟沿操作。当WE为高电平时,输入(D)被加载到地址A的内存位置。
异步读操作
输出由双端口模式的单端口模式输出SPO的地址A决定,或者双端口模式的DPO输出的地址DPRA。每次一个新的地址被应用到地址引脚上,在访问LUT的时间延迟后,该地址的内存位置的数据值就可以在输出端得到。这种操作是异步的,与时钟信号无关。
分布式RAM总结
下面是对分布式RAM特性的总结:
- 在SLICEM中可以使用单端口和双端口模式
- 写操作需要一个时钟沿
- 读取操作是异步的(Q输出)
- 数据输入有一个设置到时钟的时间延迟
只读存储器(ROM)
SLICEM和SLICEL的每个功能发生器都可以实现一个64 x 1位的ROM。有三种配置可供选择: ROM64X1、ROM128X1和ROM256X1。ROM的内容在每个器件配置中都被加载。下表显示了每种ROM配置大小所占用的LUT的数量。
| ROM | Number of LUTs |
|---|---|
| 64 x 1 | 1 |
| 128 x 1 | 2 |
| 256 x 1 | 4 |
移位寄存器(仅在SLICEM中可用)
一个SLICEM函数发生器也可以被配置成一个32位移位寄存器,而不使用片上的触发器。以这种方式使用,每个LUT可以将串行数据延迟1至32个时钟周期。shiftin D(DI1 LUT引脚)和shiftout Q31(MC31 LUT引脚)线路将LUT级联起来,形成更大的移位寄存器。这样,一个SLICEM中的四个LUT级联起来,产生的延迟可达128个时钟周期。也可以在一个以上的SLICEM中组合移位寄存器。片断之间没有直接的连接来形成更长的移位寄存器,LUT B/C/D的MC31输出也不能使用。由此产生的可编程延迟可以用来平衡数据管道的时间。
移位寄存器的应用包括:
- 延迟或延时补偿
- 同步FIFO和内容可寻址存储器(CAM)。
移位寄存器的功能包括:
- 写入操作:与一个时钟输入(CLK)和一个可选的时钟使能(CE)同步
- 对Q31的固定读访问
- 动态读访问
- 通过5位地址总线,A[4:0]执行:LUT地址的LSB是未使用的,软件会自动将其连接到逻辑高电平。
- 32位中的任何一位都可以通过改变地址而被异步读出(在O6 LUT输出,在基元上称为Q)。
- 这种能力在创建较小的移位寄存器(小于32位)时非常有用。例如,在构建 13 位移位寄存器时,将地址设置为第 13 位。
- 一个存储元件或触发器可用于实现同步读取。触发器的时钟到输出决定了整体延迟,并提高了性能,但会增加一个额外的时钟延时周期。
- 不支持移位寄存器的设置或复位。
图 2-15 是一个32位移位寄存器的逻辑框图。

图 2-16 展示了一个占用一个函数发生器的移位寄存器配置实例。
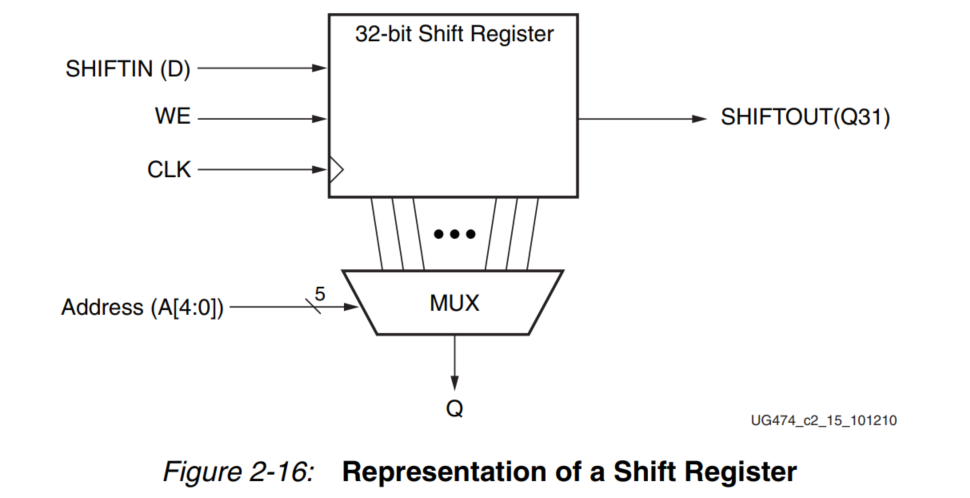
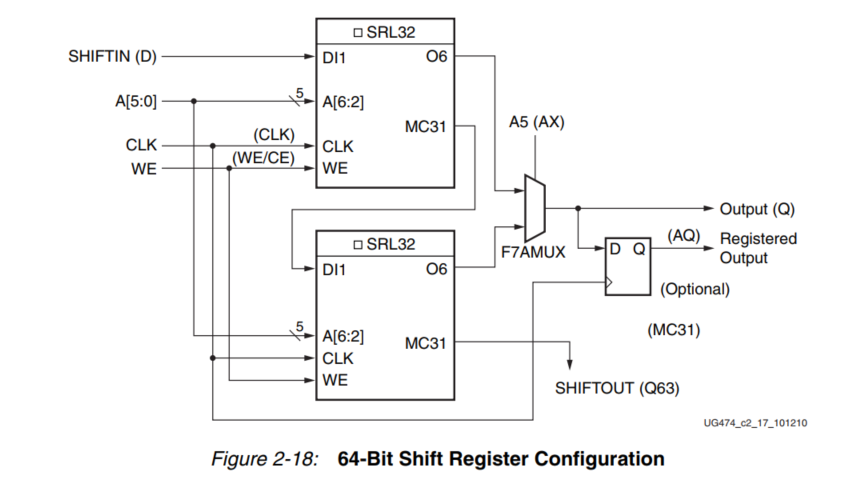
图2-17显示了两个16位移位寄存器。图中的例子可以用一个LUT来实现。

如前所述,MC31输出和移位寄存器之间的专用连接允许将一个移位寄存器的最后一位连接到下一个移位寄存器的第一位,而不需要使用LUT O6输出。更长的移位寄存器可以通过动态访问链中的任何位来建立。移位寄存器链 和 F7AMUX、F7BMUX 和 F8MUX 多路复用器允许在一个SLICEM中实现多达128位的可寻址移位寄存器。
图 2-18 至图 2-20 说明了各种可以占用一个SLICEM的移位寄存器配置实例。

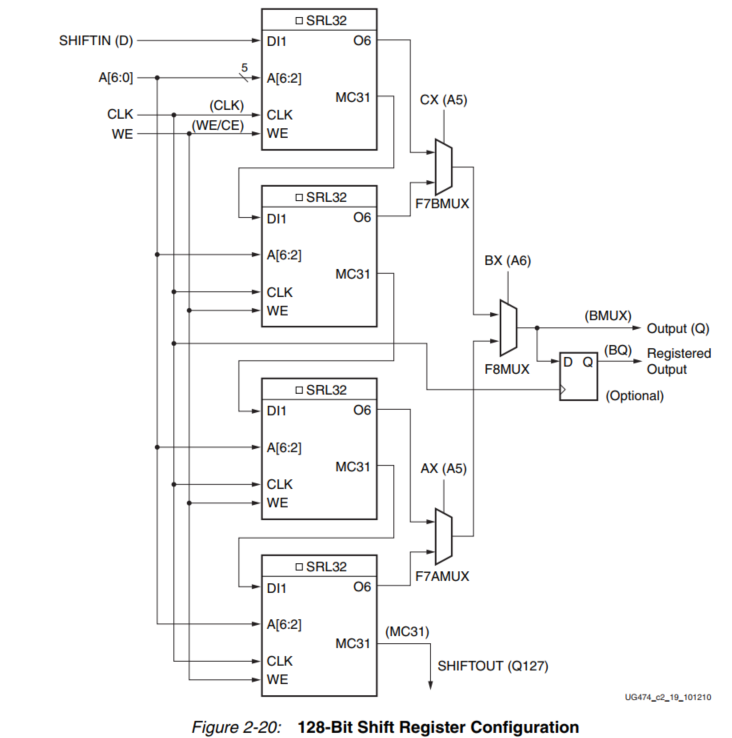
有可能在一个以上的SLICEM上创建超过128位的移位寄存器。但片与片之间没有直接的连接来形成这些移位寄存器。
移位寄存器数据流
移位操作
移位操作有以下特点:
- 在单个时钟沿上操作
- 由一个高电平的时钟使能器使能
- 输入 ( D ) 被加载到移位寄存器的第一个位上
- 每个位也被移到下一个最高位的位置上
- 在一个可级联的移位寄存器配置中,最后一位被移出到MC31的输出端
- 由5位地址端口(A[4:0])选择的位出现在Q输出上
动态读操作
在动态读操作中:
- Q输出是由5位地址决定的
- 每次一个新的地址被应用到5位输入的地址引脚上,在访问LUT的时间延迟后,新的位位置值就可以在Q输出上得到。
- 这种操作是异步的,与时钟和时钟使能信号无关
静态读操作
在静态读操作中:
- 如果5位地址是固定的,Q输出总是使用相同的比特位置
- 这种模式在一个LUT中实现了从1到32位的任何移位寄存器长度
- 移位寄存器的长度为(N+1),其中N为输入地址(0-31)。
- Q输出与每个移位操作同步变化
- 前一个位被移到下一个位置,并出现在Q输出上
移位寄存器总结
下面是对移位寄存器的总结:
- 一个移位操作需要一个时钟沿
- 对LUT的Q输出的动态长度的读操作是异步的
- 对LUT的Q输出的静态长度的读操作是同步的
- 数据输入有一个设置到时钟的时间延迟
- 在一个可级联的配置中,Q31输出总是包含最后的比特值
- 每次移位操作后,Q31输出同步变化
多路复用器
7系列FPGA中的函数发生器和相关多路复用器可以实现以下功能:
- 使用一个LUT的4:1多路复用器:每个slice有四个4:1 MUX
- 使用两个LUT的8:1复用器:每个slice有两个8:1 MUX
- 使用四个LUT的16:1复用器:每个slice有一个16:1 MUX
这些宽输入多路复用器是通过专用的F7AMUX、F7BMUX和F8MUX多路复用器在一级逻辑(或LUT)中实现。这些多路复用器允许在一个片断中最多有四个LUT的组合。宽的多路复用器也可用于创建两个LUT中最多13个输入或四个LUT中27个输入的通用功能(一个片)。尽管多路复用器的输出是组合式的,但它们可以被寄存在CLB存储元件中。
4:1 多路复用器
每个LUT都可以被配置成一个4:1的MUX。4:1 MUX可以在同一个片中用一个触发器实现。如图2-21所示,在一个slice中最多可以实现四个4:1 MUX。

8:1 多路复用器
每个slice都有一个F7AMUX和一个F7BMUX。这两个MUX结合两个LUT的输出,形成一个组合函数,最多可以有13个输入(或8:1 MUX)。如下图所示,在一个片中最多可以实现两个8:1的MUX。
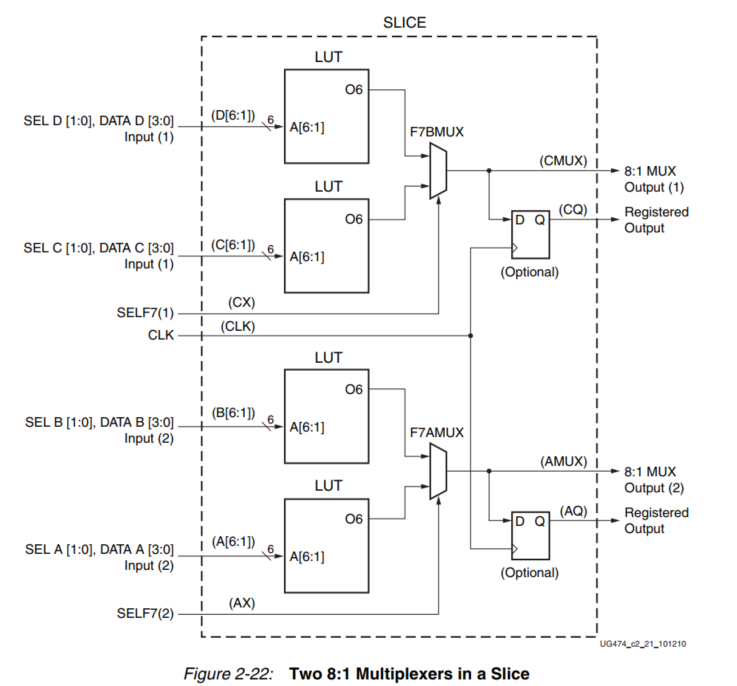
16:1 多路复用器
每个片断都有一个F8MUX。F8MUX将F7AMUX和F7BMUX的输出结合起来,形成一个最多27个输入的组合函数(或一个16:1 MUX)。一个片区只能实现一个16:1的MUX,如下图所示。
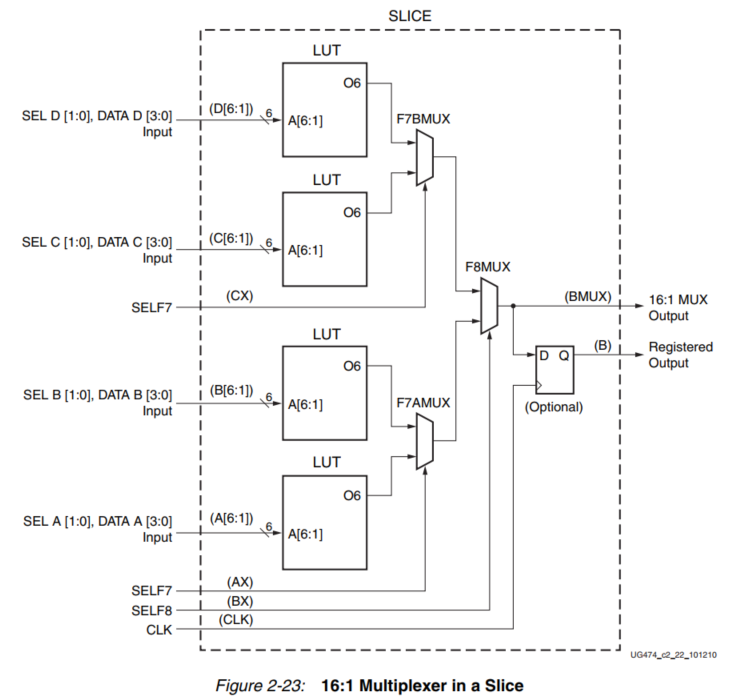
可以在一个以上的SLICEM上创建宽于16:1的多路复用器。但切片之间没有直接的连接来形成这些宽的多路复用器。
运算逻辑
除了函数发生器外,还提供了专用的快速查找进位逻辑,以便在片中进行快速算术加减。一个7系列FPGA CLB有两个独立的进位链。进位链可以级联,形成更宽的加/减逻辑。
进位链向上运行,每片的高度为4位。对于每一个比特,都有一个进位复用器(MUXCY)和一个专用的XOR门,用于将操作数与选定的提携比特相加/相减。专用的进位路径和进位多路复用器(MUXCY)也可用于级联函数发生器,以实现宽逻辑功能。
下图显示了带有相关逻辑的进位链的silce。
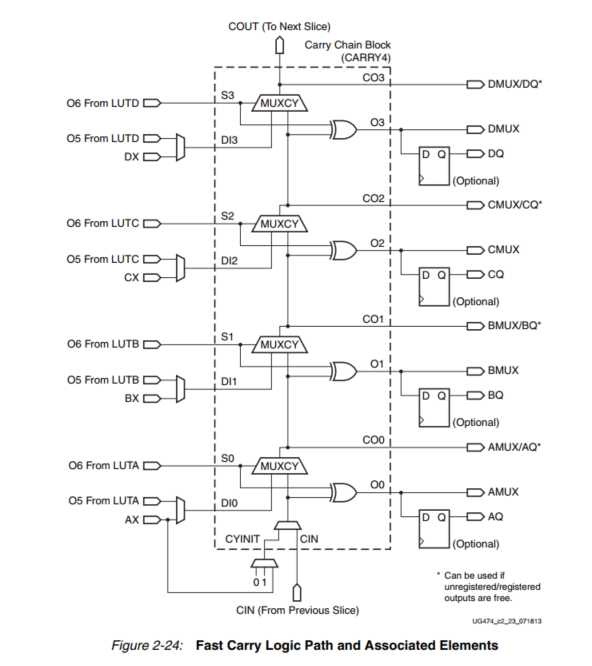
进位链与函数发生器一起使用超前进位逻辑。有10个独立的输入和8个独立的输出:
- 输入
- S - S0至S3
- 超前进位逻辑的 "传播 "信号
- 来源于一个函数发生器的O6输出
- DI - DI1到DI4
- 超前进位逻辑的 "生成 "信号
- 源自函数发生器的O5输出。用于创建一个乘法器
- 或者一个片断的BYPASS输入(AX、BX、CX或DX)。创建一个加法器/累加器
- CYINIT
- 进位链中第一个位的CIN,0表示加法,1代表减法,AX输入用于动态的第一个进位。
- CIN:级联片,形成一个较长的进位链。
- S - S0至S3
- 输出
- O - O0到O3:计算加/减法的总和。
- CO输出 - CO0 至 CO3:计算每一位的进位,CO3连接到一个slice的COUT输出,通过级联多个片断形成一个更长的进位链。
加法器的传播延迟随操作数的位数线性增加,因为更多的进位链被级联。进位链可以用一个存储元件或一个触发器在同一个片中实现。
运算逻辑级联只受限于片列的高度。在使用堆叠硅互连(SSI)技术的器件中,进位逻辑不能跨越上级逻辑区域(SLR)级联。
reference
- UG474