Zero系列三部曲:Zero、Zero-Offload、Zero-Infinity
- Zero
- Introduction
- Zero DP
- 流程图详解
- Zero-R
- Zero-Offload
- Zero- Infinity
- reference
Zero
Introduction
以数据并行为例,在训练的时候,首先把模型参数在每个GPU上复制一份,然后把batch的数据平均拆开分配到多个GPU上进行计算,计算完再返回来合并。
当把1B参数精度为fp32的模型加载进需要4G,fp16需要2G,int 8 则需要1G。目前训练的模型都是采用fp32\16混合精度训练,由于Nvidia的显卡在float16上的计算速度要比float32快几倍。但是如果只使用float16训练,会产生一些局限性,当由于精度不够,在累加梯度的时候,可能好几个很小的数相加还是很小,导致梯度消失,反之也是如此。于是现在的主流方法是采用混合的训练方法,首先以float16前向计算计算loss,当在计算梯度的时候,会把float16为转换为float32完成计算,然后在转换为16位完成后续的反向传播,这样似乎很好的解决了问题,速度、精度、稳定性三者兼得。
实则不是如此,目前在训练大模型的时候,一般默认采用Adam优化器,它对lr不是那么敏感,方便调参,首先看下面图回顾一下Adam的计算流程:
- 首先对整个batch梯度求和平均,然后利用动量法的思想对梯度平滑。
- 与SGDM不同,还会对梯度权重做限制,让所有权重和为1。
- 然后计算梯度方差。
位(bit)是二进制中的基本单位,它是指计算机内存中存储信息的最小单位,一个位只能存储0或1。字节(byte)是计算机中的常用存储单元,它表示8个二进制位的集合。因此,1字节等于8位。
一个float32的模型参数有32个bit,1byte=8bit,一个float32参数就是4byte。
1024byte=1kb
假设模型参数为¥,那么GPU就需要存储float16模型参数2¥,梯度2¥,由于采用混合精度训练,还需要float32的模型参数4¥用来计算梯度,由于用的adam,还需要维护4¥的动量与4¥的梯度方差,那么加在一起就是(2+2+(4+4+4))¥。
但是其中的4+4+4只有在参数更新的时候才会起作用,于是作者的就想从这里找突破口。
Zero DP
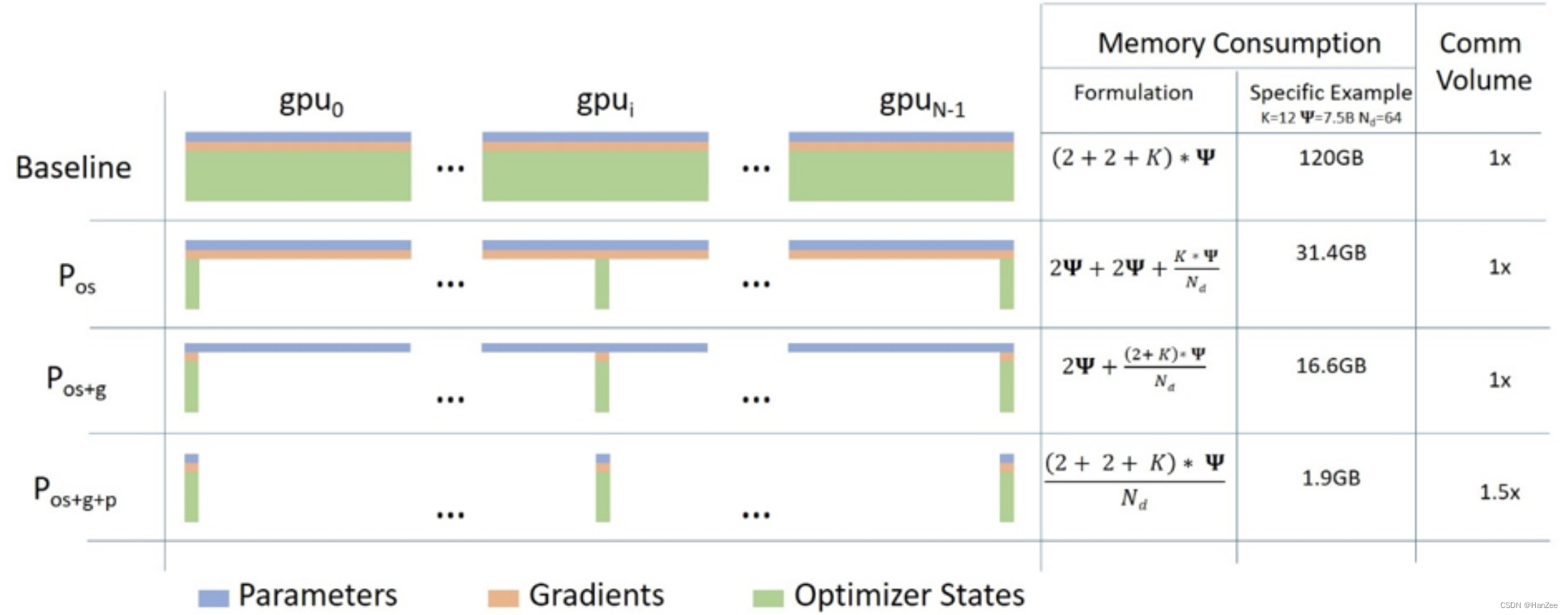
作者采取三个方法优化内存,Pos、Pg、Pp。
大体思路都是一样的,把每个模型的参数、梯度、优化器状态分别平均分给所有的模型,当时计算需要用到其他卡的内容是,通过GPU之间的通讯传输,以通讯换内存。
其中前两个方法不增加通讯成本,第三个方法会增加GPU之间的通信成本。
流程图详解
微软官方视频介绍
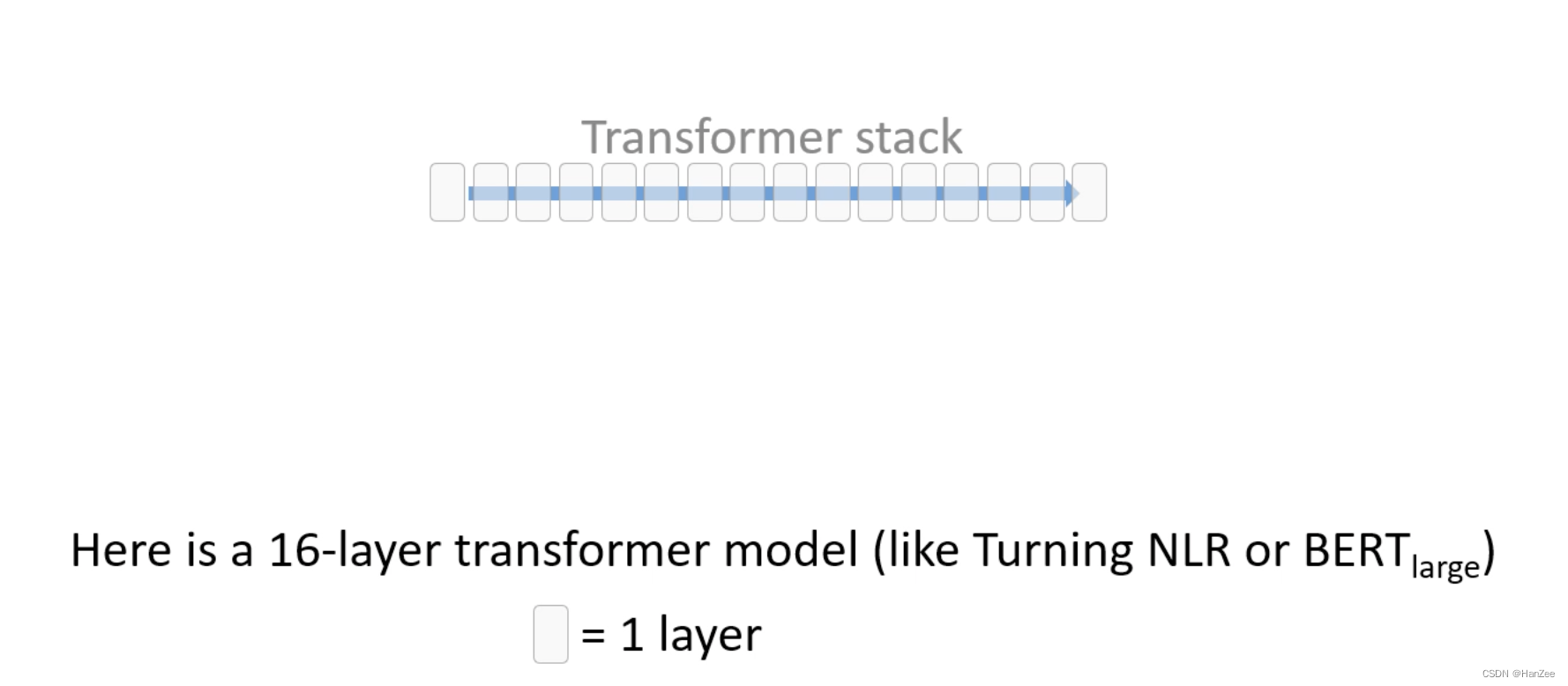
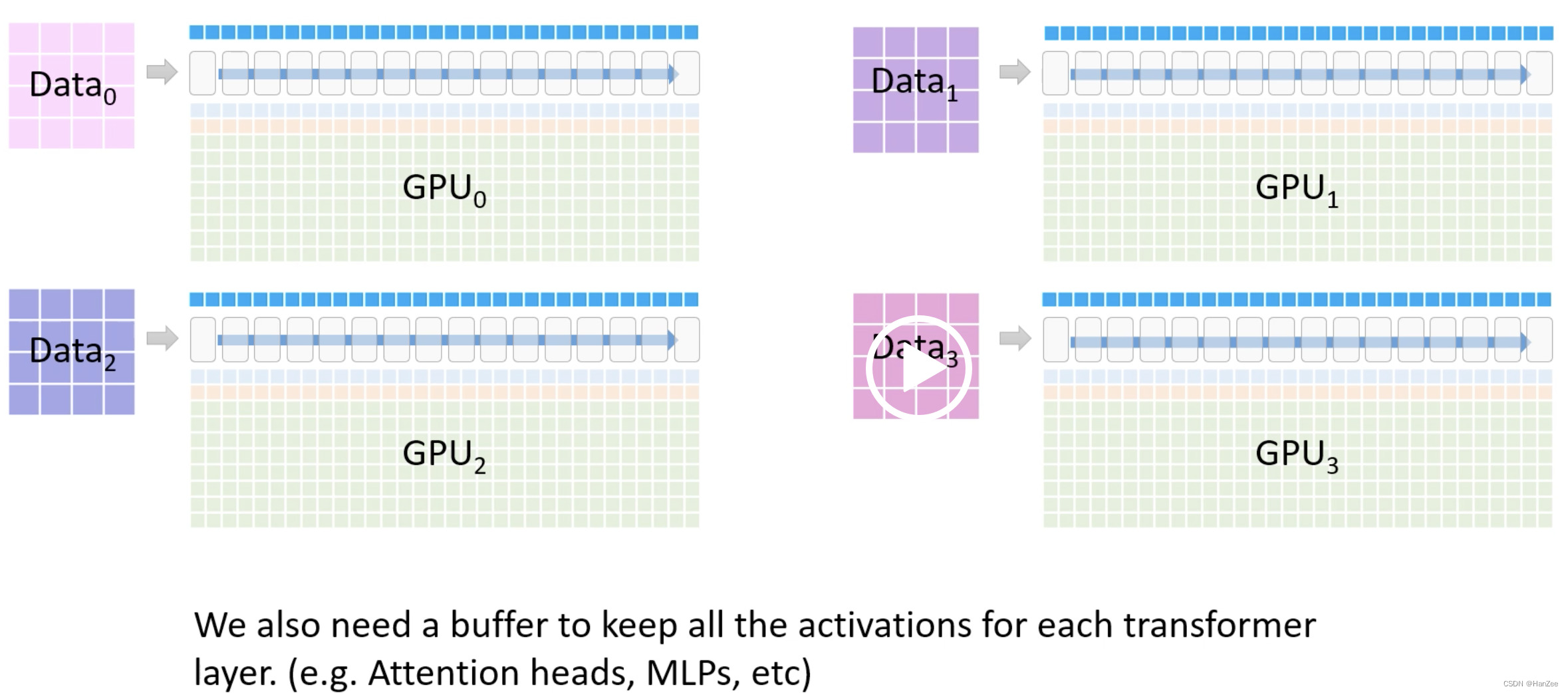
这表示一个Transformer block,每个白色方块代表1个layer。
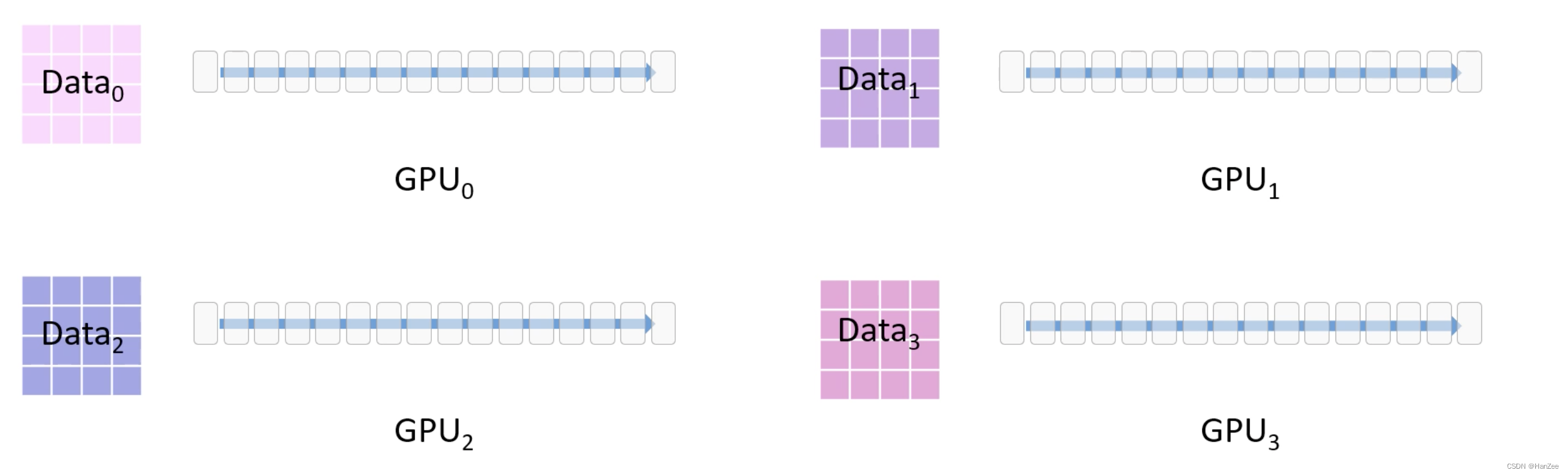
现在有粉色的数据集与四块GPU

以数据并行的方式先把数据分成四份放入GPU
其中每个transformer block下面对应两列 彩色的小方块,表示block占用的内存。
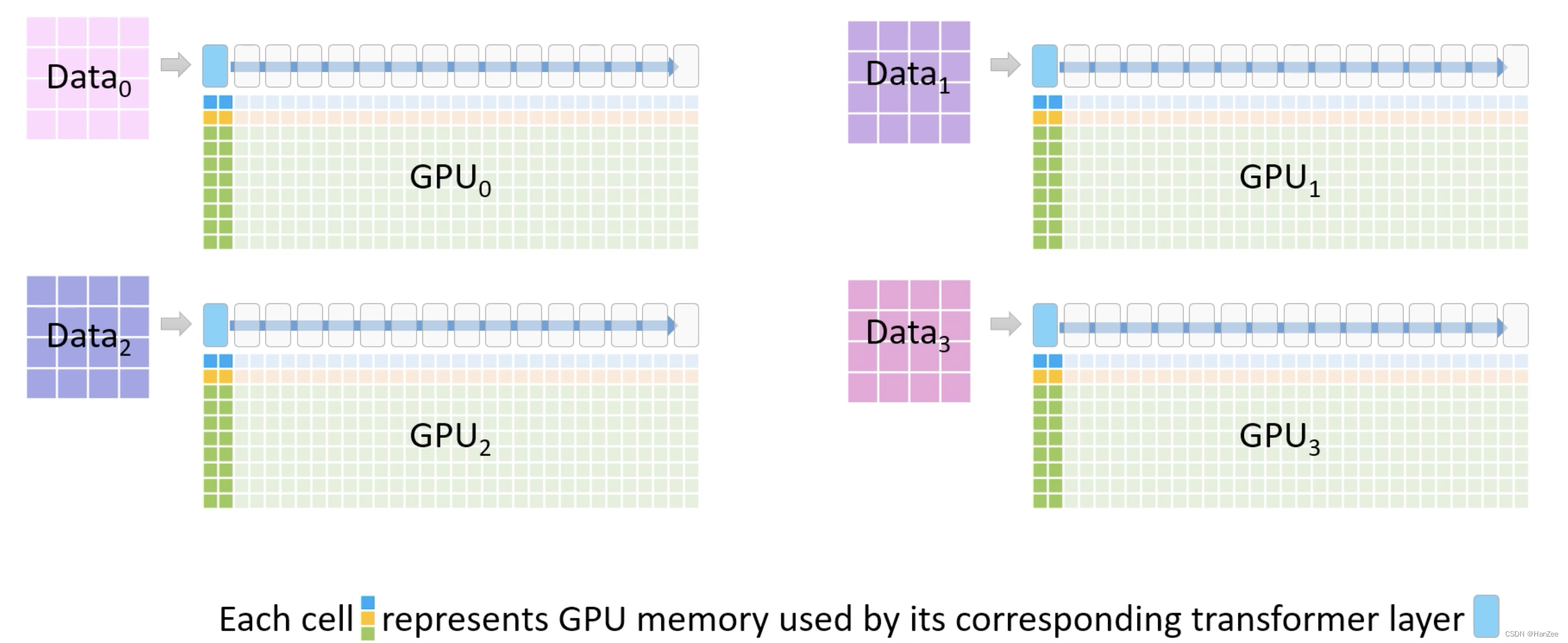
其中蓝色表示fp16参数,橙色表示fp16梯度,绿色表示Adam state
block上面的蓝色表示储存activations的 buffer
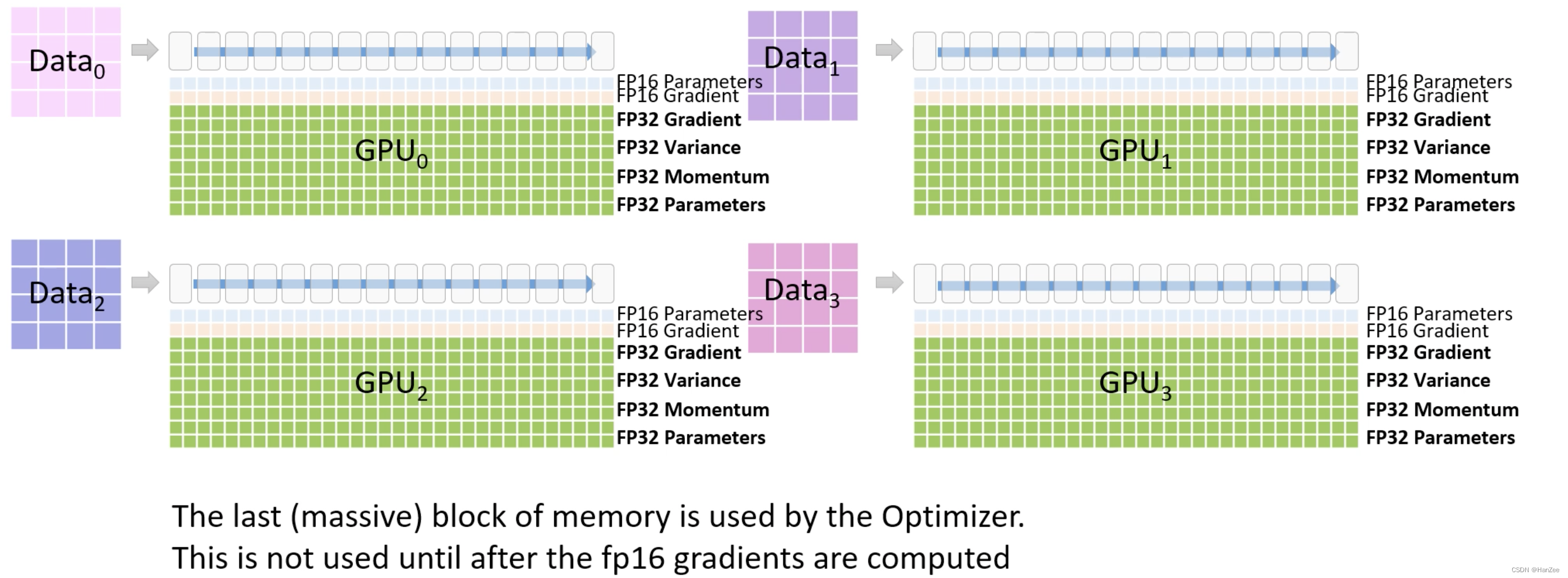
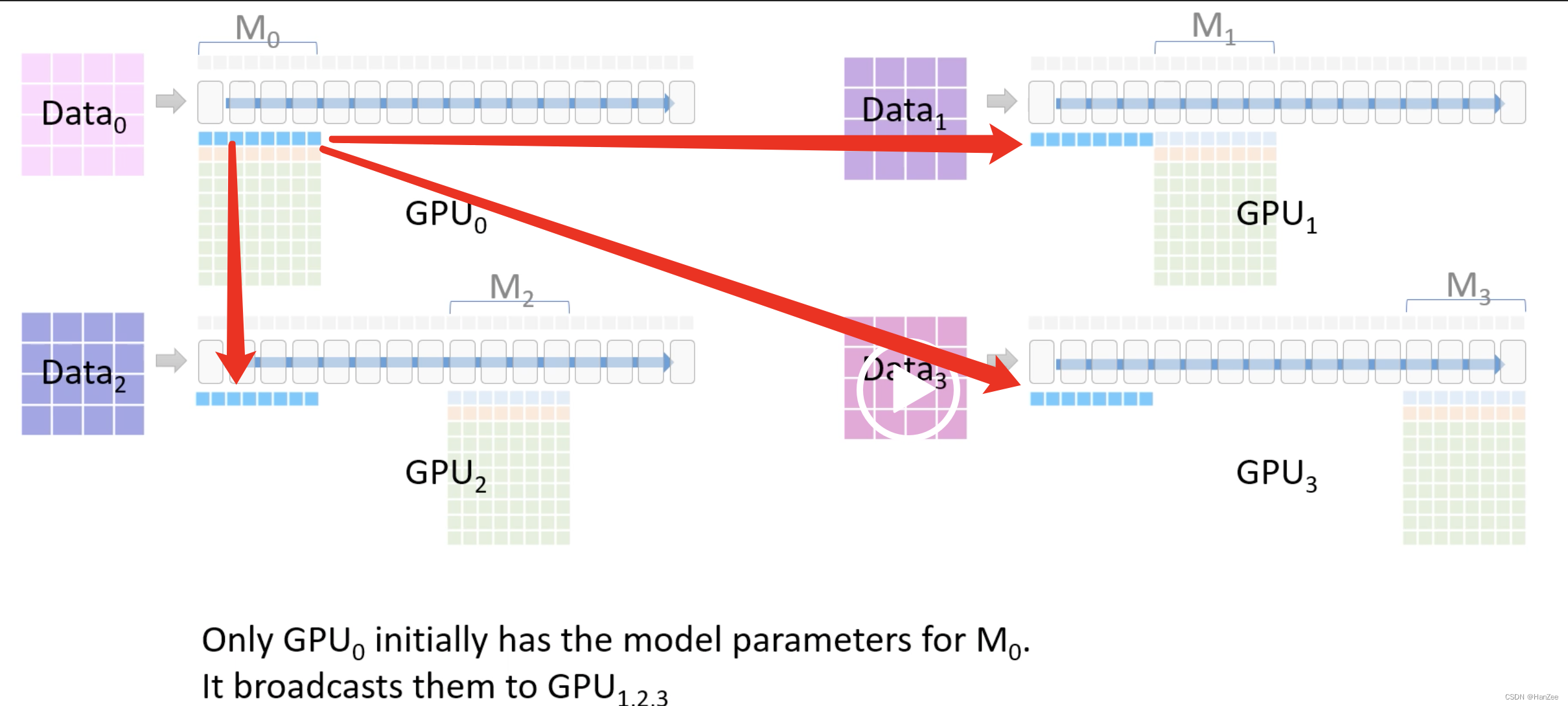
通过上面所说的Zero三个阶段把模型各个模型占用内存分为四块,每个GPU只保留其中一块,计作M0、M1、M2、M3

在前向传播的过程中,首先把M0的蓝色部分(也就是模型fp16参数)传送给其他GPU,它们的区别就是没gpu上的数据不同
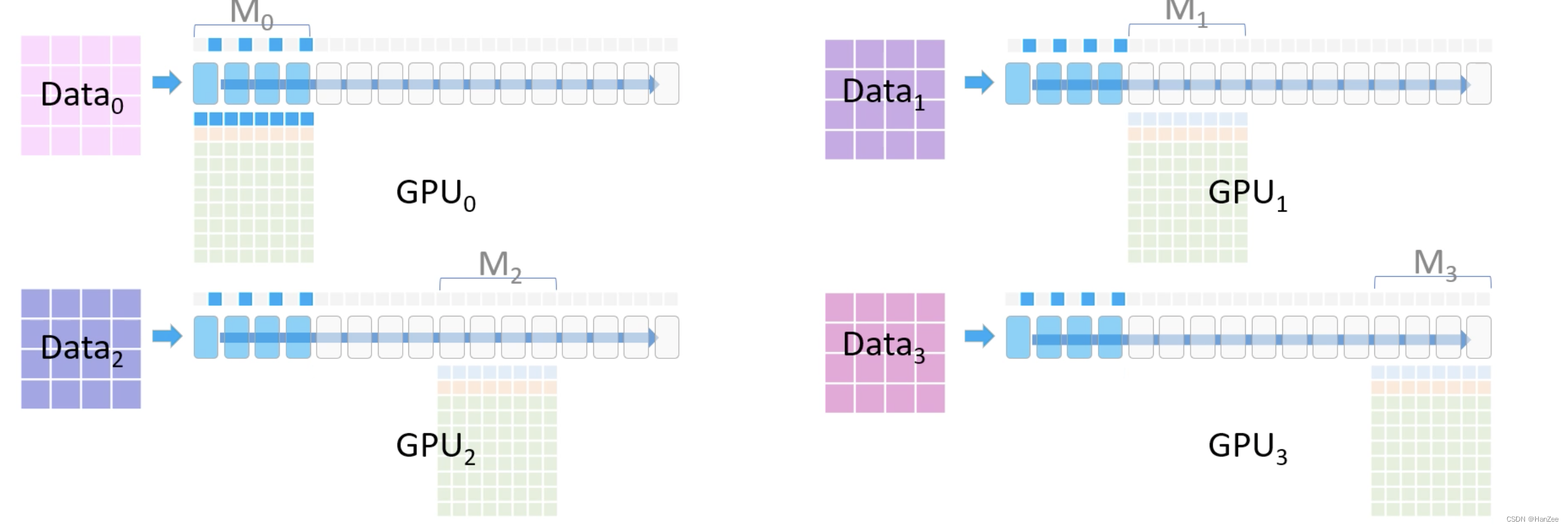
完成这部分的前向计算后,删除参数,继续后面的前向计算。
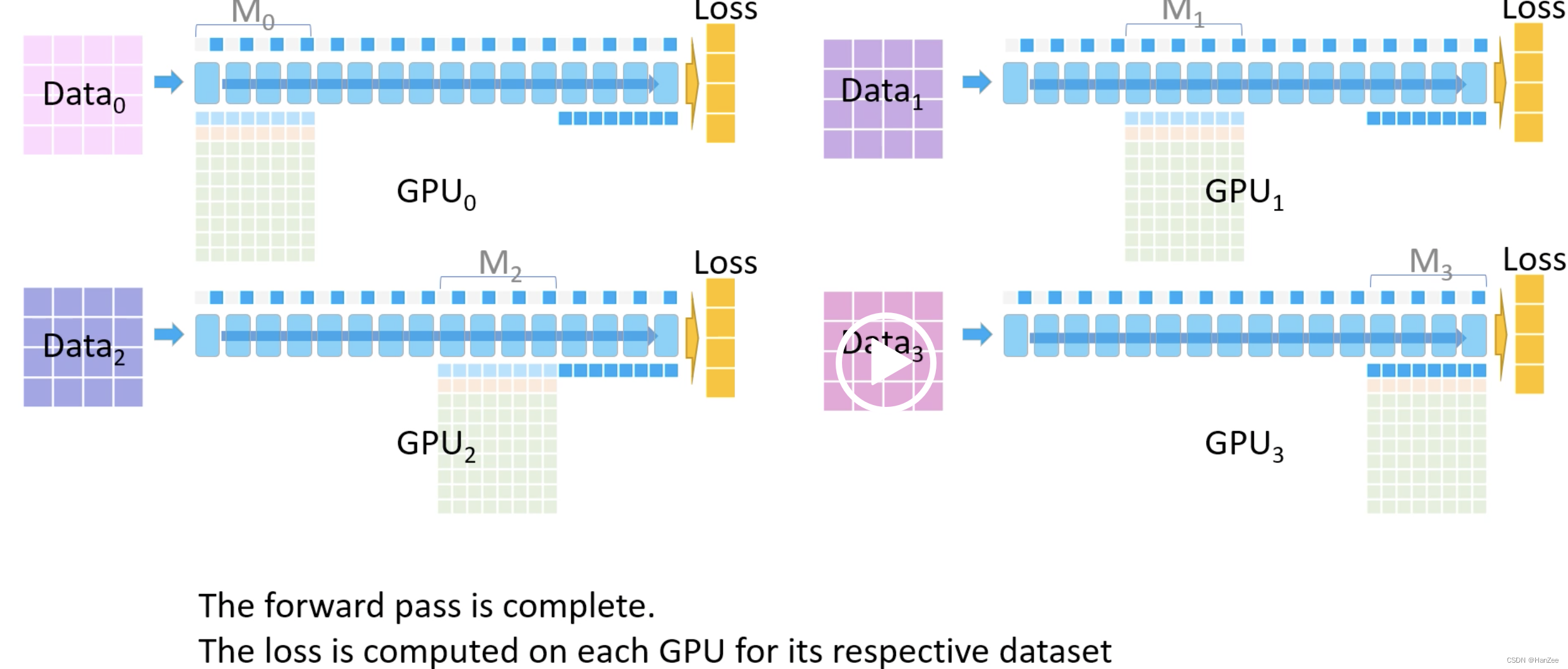
在计算最后一块的前向计算后,模型参数先不删除,完成前向计算后,每个GPU分别计算各自的Loss
然后开始执行反向传播,每个GPU首先计算M3对应的梯度,然后GPU012把对应的梯度传送给GPU3,GPU3将梯度累加。
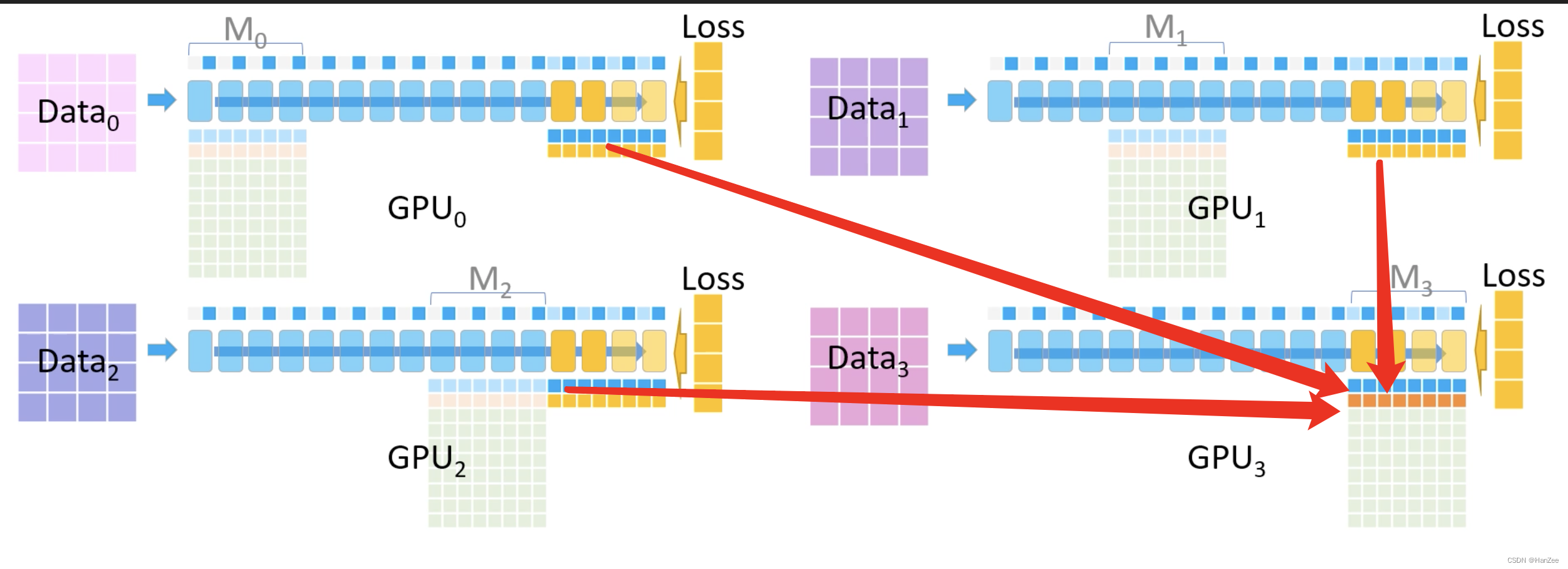
然后其他GPU删除各自M3位置上的激活函数、参数、梯度,只保留GPU3的。
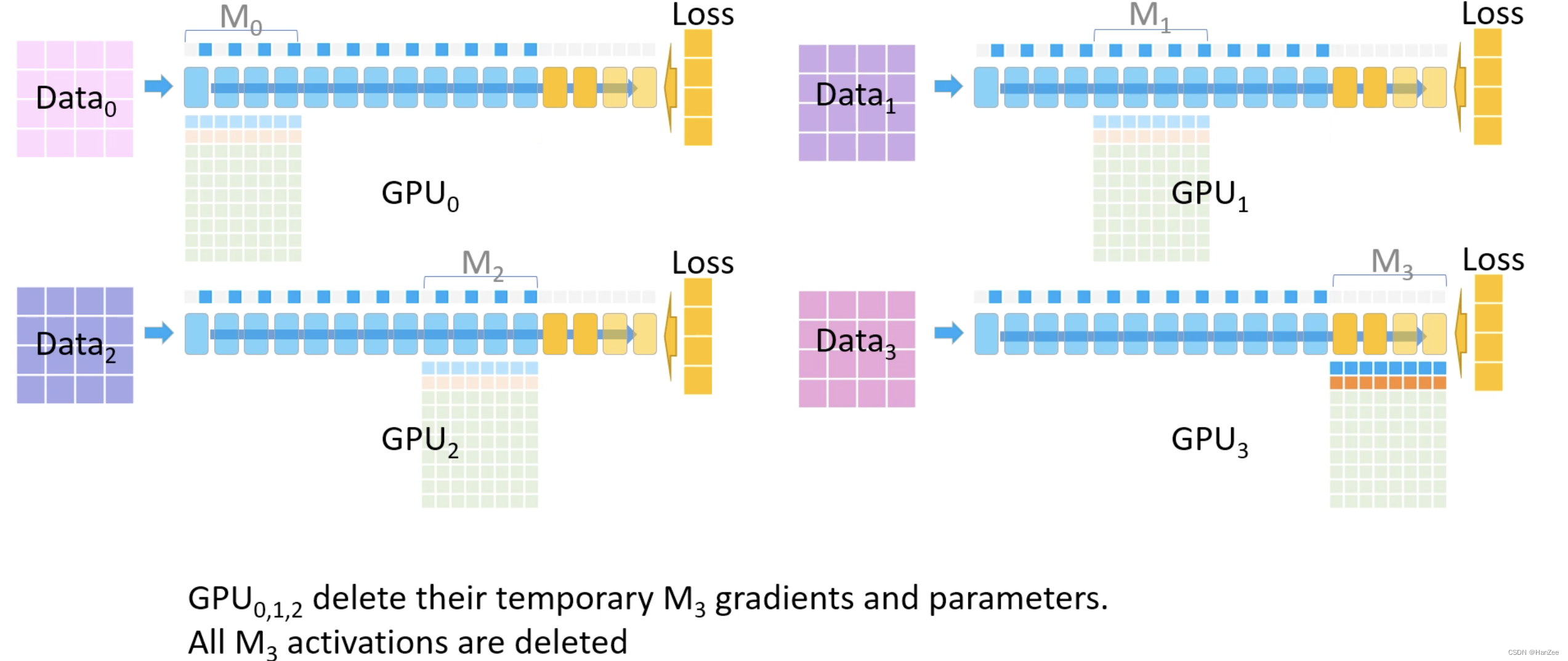
然后继续反向传播,用同样的方法:传递参数、计算梯度、传递梯度、累加梯度、删除不需要的activations、weight、gradient.
完成上述操作后,现在每个GPU都有对用的部分参数与全局的梯度,开始更新参数通过Adam,首先把一些转换fp32 的参数、梯度、动量。
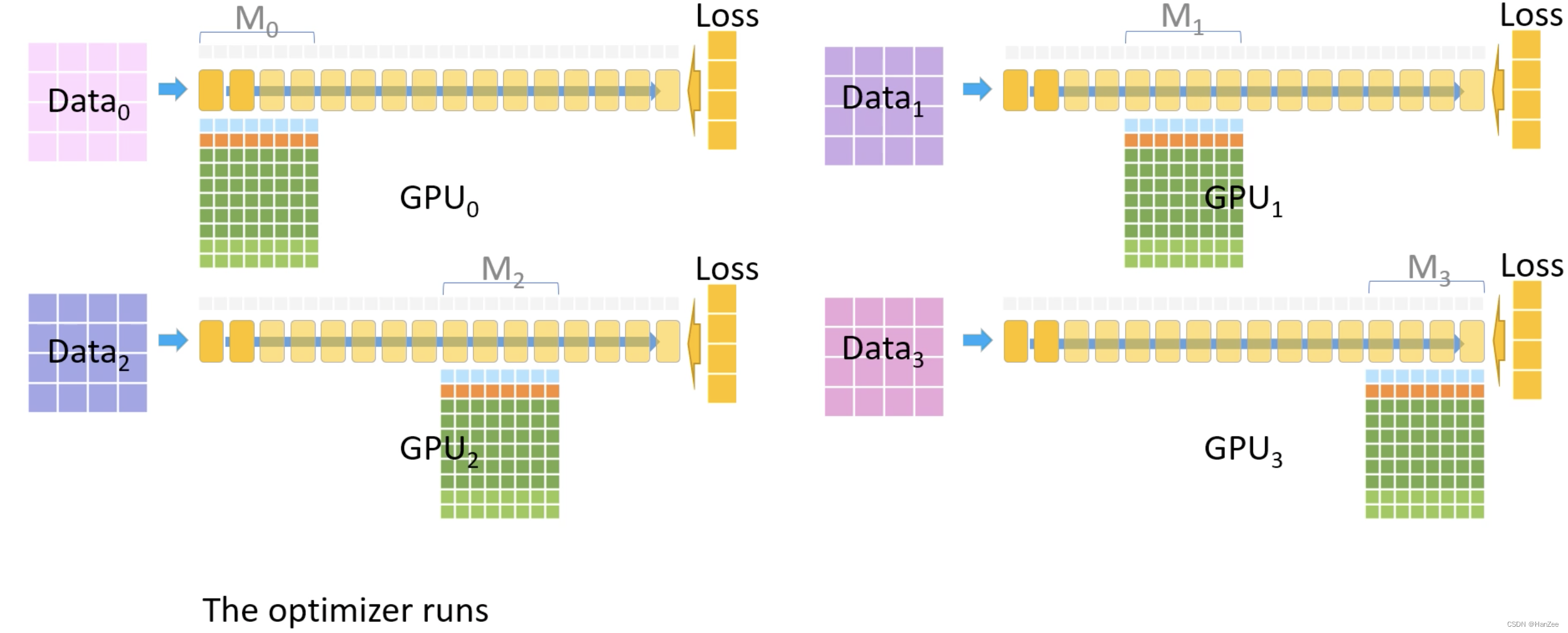
然后把更新完成的fp32参数转换成fp16,然后传替换上面的第一层的参数。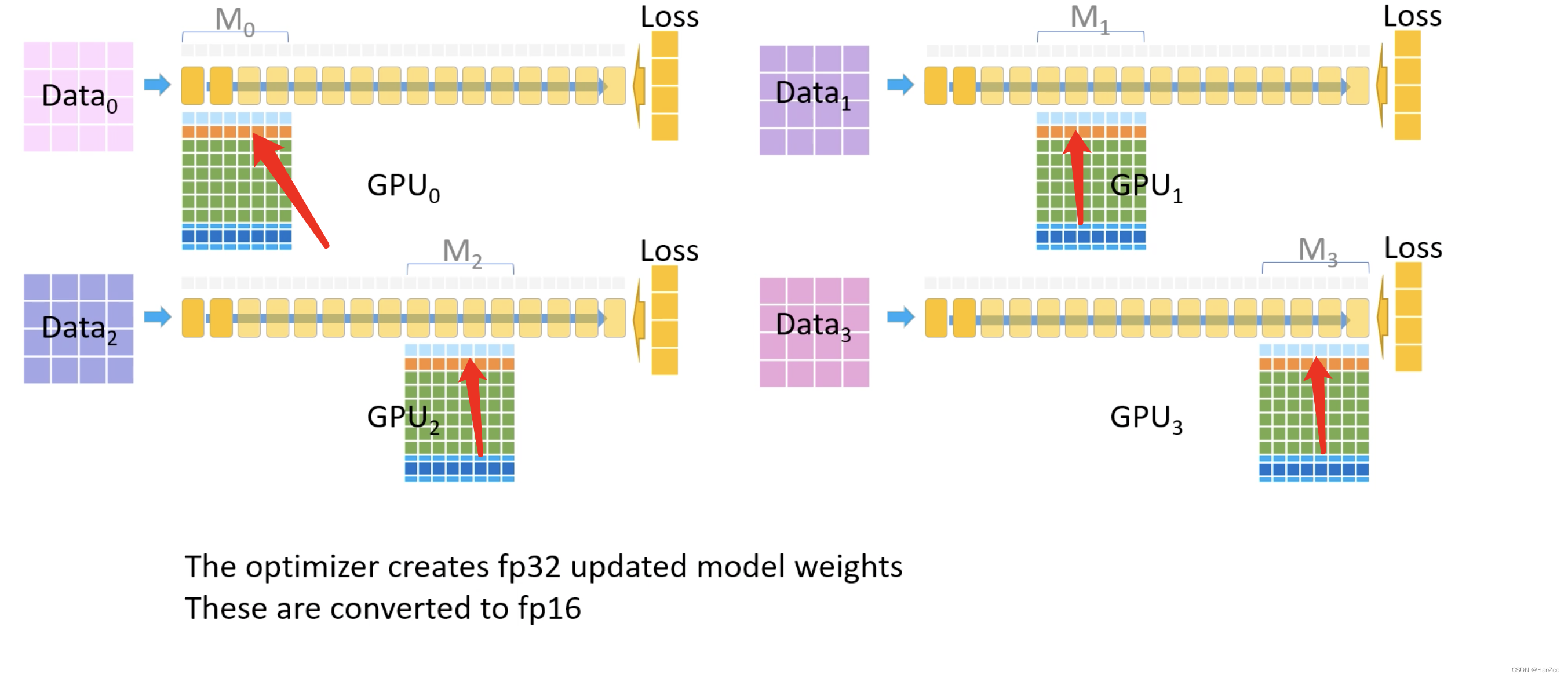
Zero-R
激活函数:在前向传播计算完成激活函数之后,对把激活值丢弃,由于计算图还在,等到反向传播的时候在此计算激活值,算力换内存。或者采取一个与cpu执行一个换入换出的操作。
临时缓冲区:模型训练过程中经常会创建一些大小不等的临时缓冲区,比如对梯度进行AllReduce啥的,解决办法就是预先创建一个固定的缓冲区,训练过程中不再动态创建,如果要传输的数据较小,则多组数据bucket后再一次性传输,提高效率。
内存碎片:显存出现碎片的一大原因是时候gradient checkpointing后,不断地创建和销毁那些不保存的激活值,解决方法是预先分配一块连续的显存,将常驻显存的模型状态和checkpointed activation存在里面,剩余显存用于动态创建和销毁discarded activation复用了操作系统对内存的优化,不断内存整理。
Zero-Offload
参数不够、内存来凑!
上面Zero3的流程,我们用下面的图来表示,⭕️表示state,正方形表示计算图,箭头表示数据流向、M表示模型参数,float2half表示32位转16位
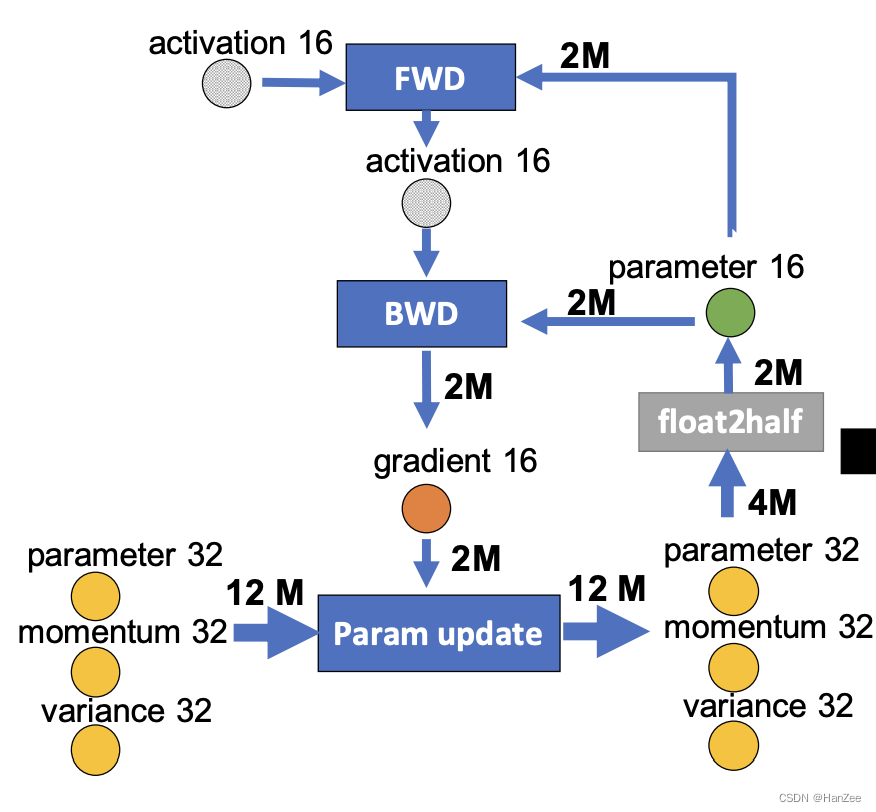
zero-offload要做的事就是把一步切开,放入cpu中,如下图:
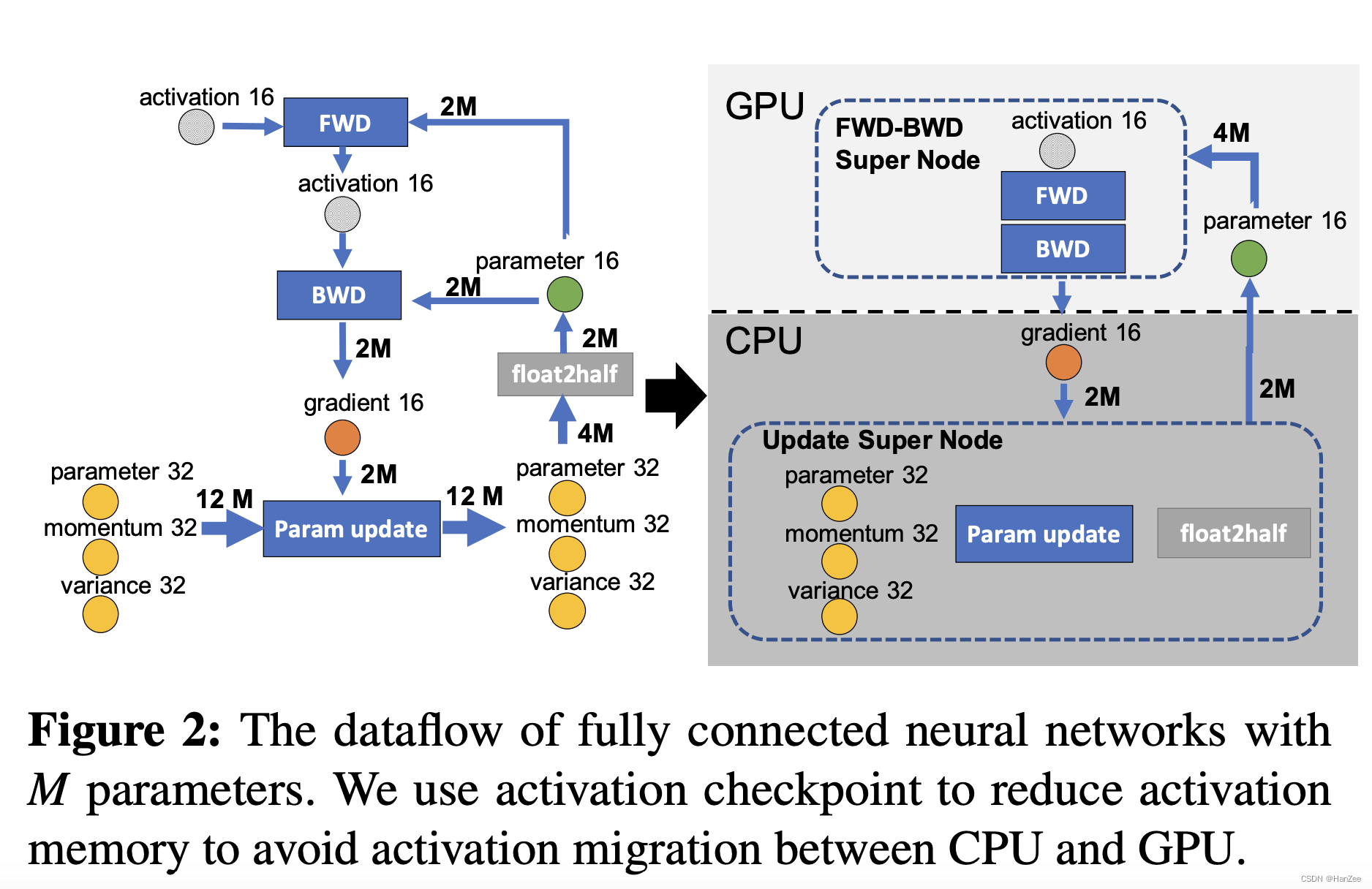
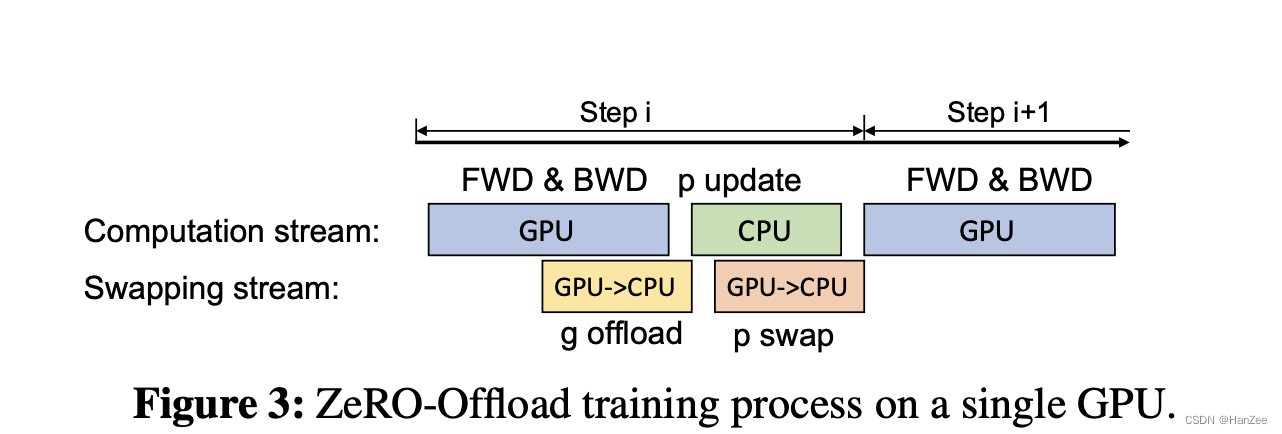
CPU与GPU通信数据是很大的,切开的只是传播gradient16的时候,这样保证传播数据量最小。前向传播,反向传播在GPU上,更新参数在cpu上。
同时
GPU在计算梯度的同时也在把计算好的梯度传递给CPU,当计算梯度完成时,CPU也同时获得了所有的梯度,CPU更新参数的过程也是如此,动态同步更新参数。
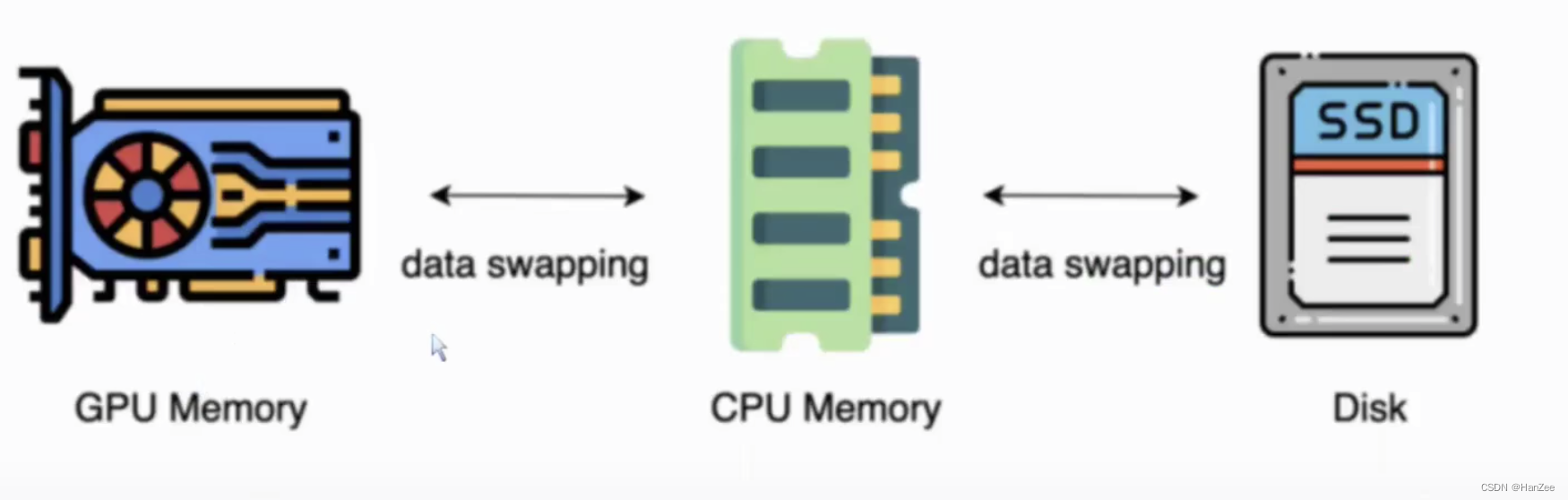
Zero- Infinity
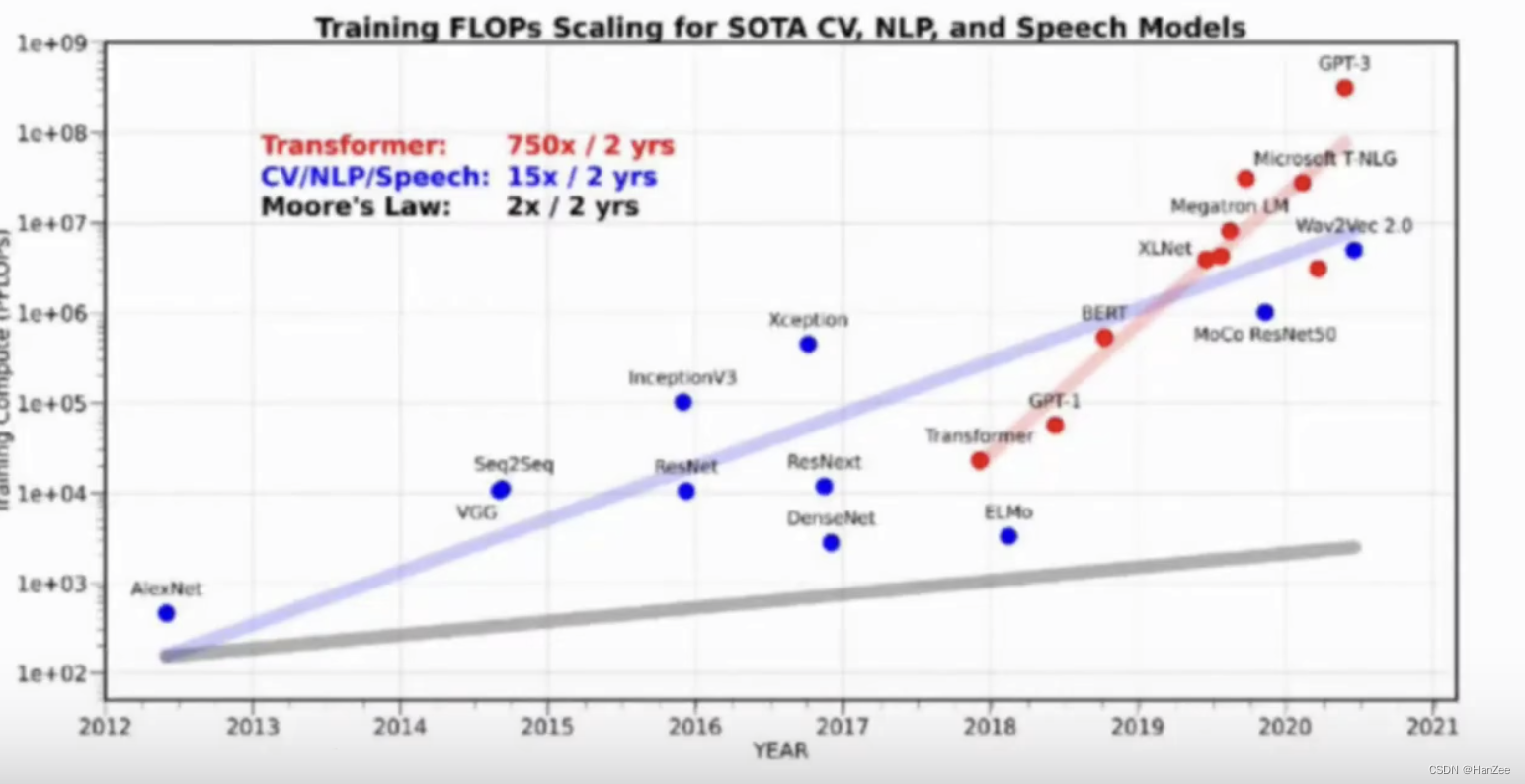
背景:显卡的显存赶不上模型参数的增长
reference
https://arxiv.org/pdf/2101.06840.pdf
https://arxiv.org/abs/1910.02054
https://arxiv.org/pdf/2104.07857.pdf