计算机视觉研究院专栏
作者:Edison_G
传统的目标检测方法通常需要大量的训练数据,并且准备这样高质量的训练数据是劳动密集型的(工作)。在今天分享中,研究者提出了少量样本的目标检测网络,目的是检测只有几个训练实例的未见过的类别对象

公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
源代码|回复“最佳检测”获取
1
前景概要
传统的目标检测方法通常需要大量的训练数据,并且准备这样高质量的训练数据是劳动密集型的(工作)。在今天分享中,研究者提出了少量样本的目标检测网络,目的是检测只有几个训练实例的未见过的类别对象。新提出的方法核心是注意力RPN和多关系模块,充分利用少量训练样本和测试集之间的相似度来检测新对象,同时抑制背景中的错误检测。
为了训练新的网络,研究者已经准备了一个新的数据集,它包含1000类具有高质量注释的不同对象。据我们所知,这也是第一个数据集专门设计用于少样本目标检测。一旦新网络被训练,研究者可以应用目标检测为未见过的类,而无需进一步的训练或微调。新提出的方法是通用的,并且具有广泛的应用范围。研究者证明了新方法在不同的数据集上的定性和定量的有效性。
解决的问题
少量support的情况,检测全部的属于target目标范畴的前景。
2
背景
现有的物体检测方法通常严重依赖大量的注释数据,并且需要很长的训练时间。这激发了少量样本物体检测的最新发展。鉴于现实世界中物体的光照,形状,纹理等变化很大,少量样本学习会遇到挑战。尽管已经取得了重要的研究和进展,但是所有这些方法都将重点放在图像分类上,而很少涉及到很少检测到物体的问题,这很可能是因为转移从少样本分类到少样本目标检测是一项艰巨的任务。
仅有少数样本的目标检测的中心是如何在杂乱的背景中定位看不见的对象,从长远来看,这是新颖类别中一些带注释的示例中对象定位的一个普遍问题。潜在的边界框很容易错过看不见的物体,否则可能会在后台产生许多错误的检测结果。我们认为,这是由于区域提议网络(RPN)输出的良好边界框得分不当而导致难以检测到新物体。这使得少样本目标检测本质上不同于少样本分类。另一方面,最近用于少样本物体检测的工作都需要微调,因此不能直接应用于新颖类别。
在今天分享的文章中,作者解决了少样本目标检测的问题:给定一些新颖目标对象的支持图像,我们的目标是检测测试集中属于目标对象类别的所有前景对象,如下图所示。

3
FSOD: A Highly-Diverse Few-Shot Object Detection Dataset
进行少量学习的关键在于,当新颖的类别出现时,相关模型的泛化能力。因此,具有大量对象类别的高多样性数据集对于训练可以检测到看不见的对象的通用模型以及执行令人信服的评估是必要的。但是,现有的数据集包含的类别非常有限,并且不是在一次性评估设置中设计的。因此,我们建立了一个新的少样本物体检测数据集。我们从现有的大规模对象检测数据集构建数据集以进行监督学习。但是,由于以下原因,这些数据集无法直接使用:
不同数据集的标签系统是在某些具有相同语义的对象用不同的词注释的地方不一致;
由于标签不正确和缺失,重复的框,对象太大,现有注释的很大一部分是嘈杂的;
他们的训练/测试组包含相同的类别,而对于少样本设置,我们希望训练/测试组包含不同的类别,以评估其在看不见的类别上的普遍性。
为了开始构建数据集,首先从中总结标签系统。我们将叶子标签合并到其原始标签树中,方法是将相同语义(例如,冰熊和北极熊)的叶子标签归为一类,并删除不属于任何叶子类别的语义。然后,我们删除标签质量差的图像和带有不合适尺寸的盒子的图像。具体而言,删除的图像的框小于图像尺寸的0.05%,通常框的视觉质量较差,不适合用作支持示例。接下来,我们遵循几次学习设置,将我们的数据分为训练集和测试集,而没有重叠的类别。如果研究人员更喜欢预训练阶段,我们将在MS COCO数据集中按类别构建训练集。然后,我们通过选择现有训练类别中距离最大的类别来划分包含200个类别的测试集,其中距离是连接is-a分类法中两个短语的含义的最短路径。其余类别将合并到总共包含800个类别的训练集中。总而言之,我们构建了一个包含1000个类别的数据集,其中明确地划分了类别用于训练和测试,其中531个类别来自ImageNet数据集,而469来自开放图像数据集。
数据集分析
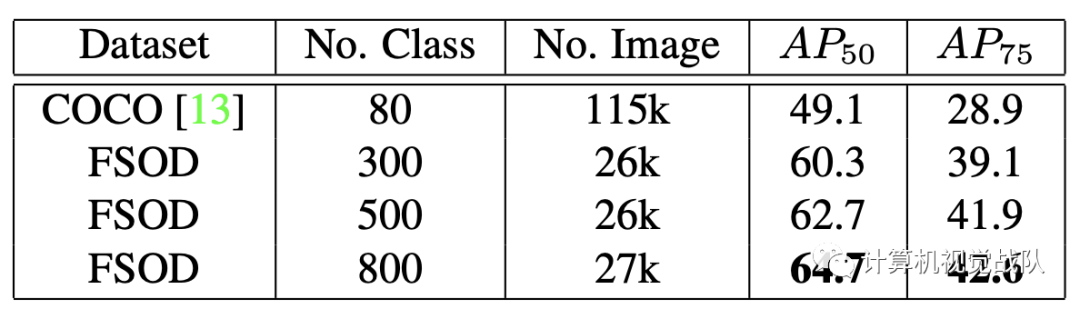
数据集是专为几次学习和评估新颖类别模型的通用性而设计的,该模型包含1000个类别,分别用于训练和测试集的800/200分割,总共约66,000张图像和182,000个边界框。下表和下图显示了详细的统计信息。我们的数据集具有以下属性。
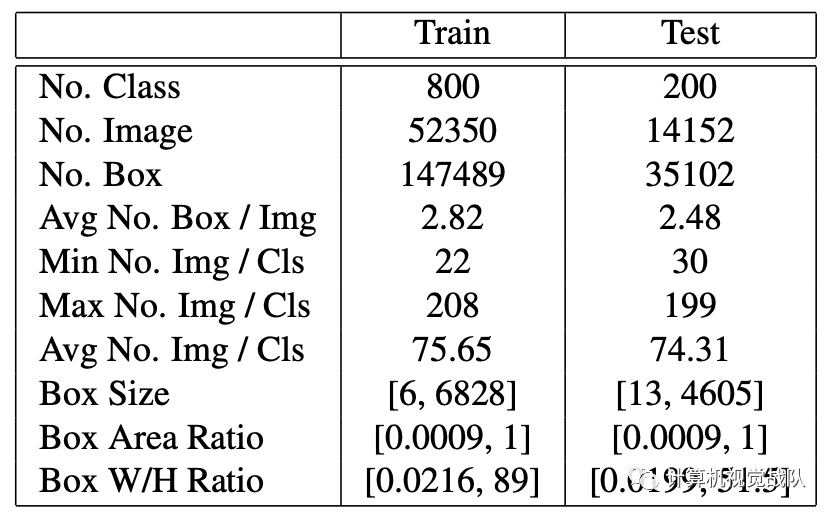

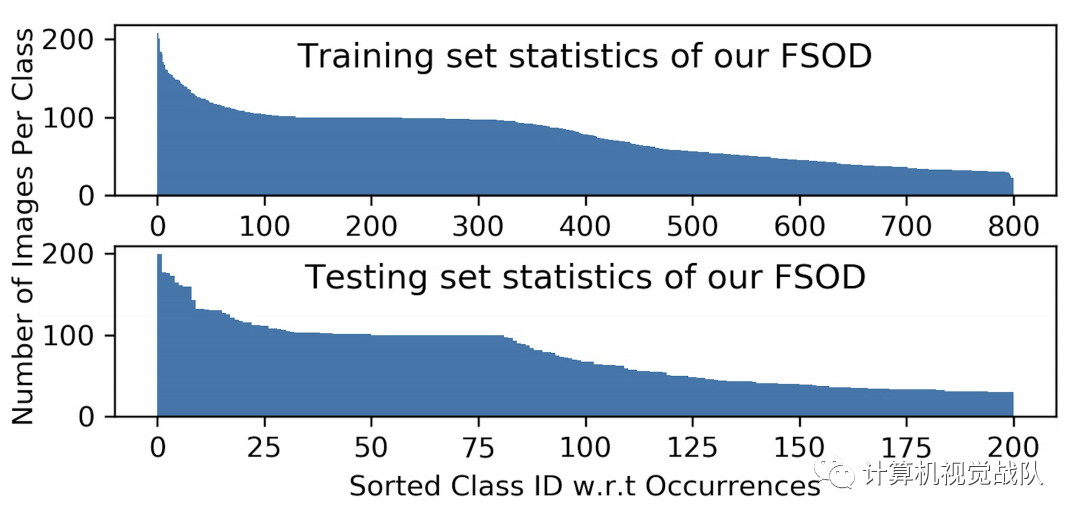
类别高度多样性
包含了83中父类语义,例如哺乳动物,衣服,武器等,这些语义进一步细分为1000个叶子类别。我们的标签树如上图所示。由于严格的数据集划分,我们的训练/测试集包含了非常不同的语义类别的图像,因此给要评估的模型带来了挑战。
4
新框架分析
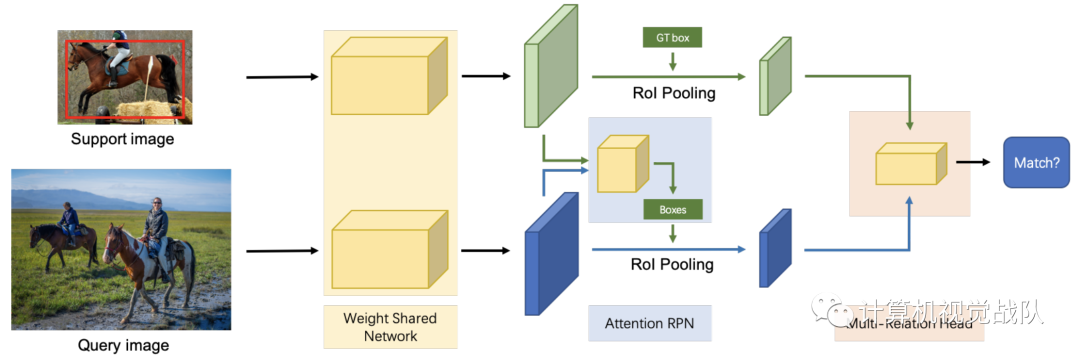
在RPN前加一个attention,在检测器之前加了3个attention,然后还是用到了负support训练。具体来说,我们构建了一个由多个分支组成的权重共享框架,其中一个分支用于查询集,另一个分支用于支持集(为简单起见,我们在图中仅显示了一个支持分支)。权重共享框架的查询分支是Faster R-CNN网络,其中包含RPN和检测器。我们利用此框架来训练支持和查询功能之间的匹配关系,使网络学习相同类别之间的常识。在该框架的基础上,我们引入了一种新颖的注意力RPN和具有多关系模块的检测器,用于在支持框和查询框之间产生准确的查询解析。
Attention-Based Region Proposal Network
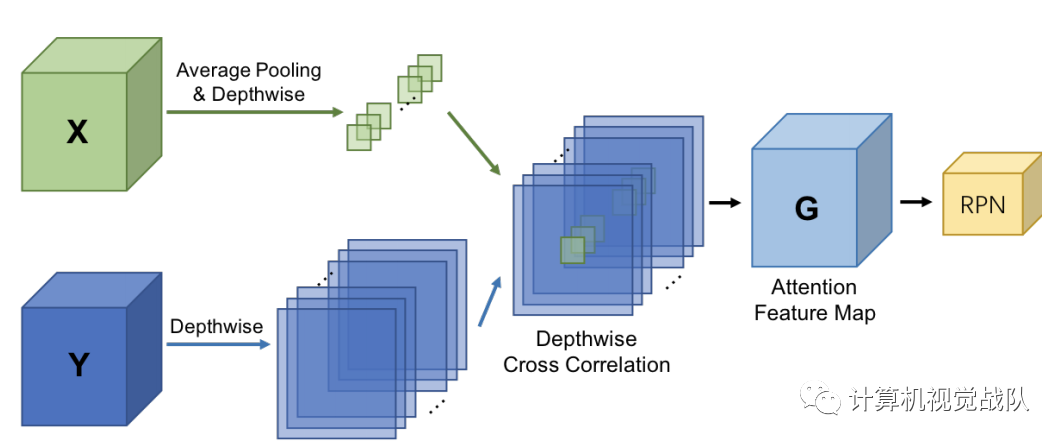
没有support,RPN就没有目标,后面的子分类就搞不清楚这么多的不相关目标。使用support信息就能过滤掉大部分的背景框,还有那些不是匹配的类别。通过在RPN中用attention机制来引入support信息,来对其他类的proposal进行压制。通过逐深度的方法计算二者特征值的相似性,相似性用来生成proposal。相似度定义如下:

其中GGG是attention特征图,X作为一个卷积核在query的特征图上滑动,以一种逐深度(取平均)的方式。使用的是RPN的底部特征,ResNet50的res4-6,发现设置S=1表现很好,这说明全局特征能提供一个好的先验G用3×3的卷积处理,然后接分类和回归层。
Multi-Relation Detector
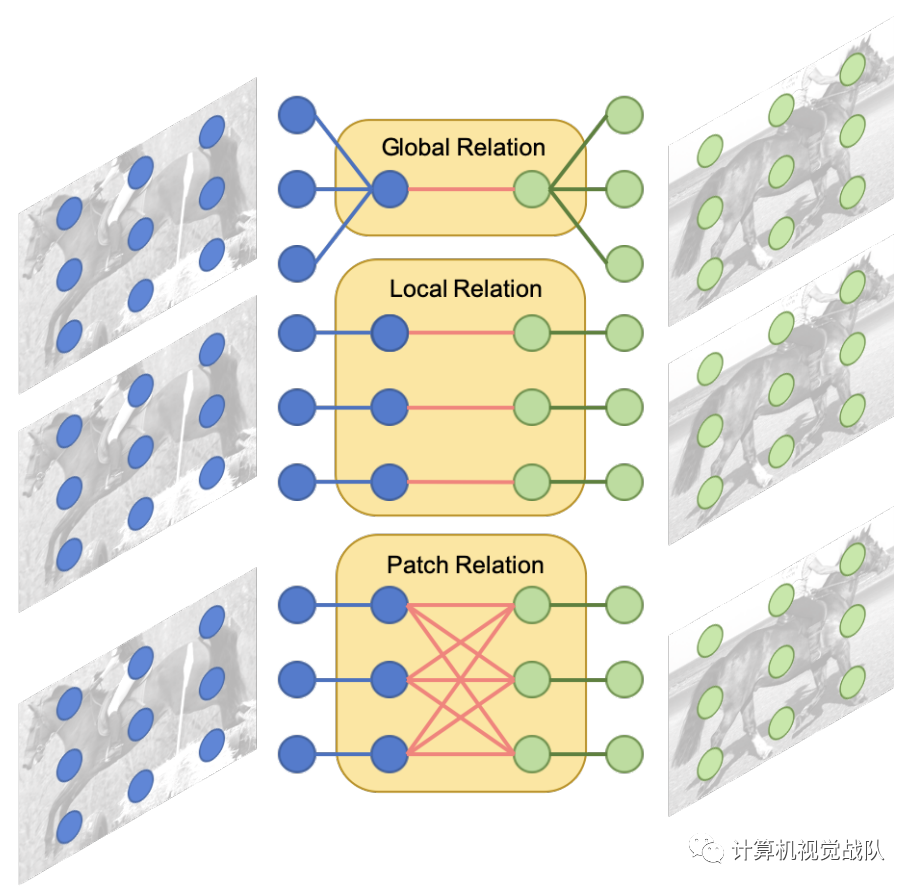
不同的关系模块建模查询和支持图像之间的不同关系。全局关系模块使用全局表示来匹配图像;局部关系模块捕获像素到像素的匹配关系;补丁关系模块对一对多像素关系进行建模。
该检测器包括三个注意模块,分别是要学习的全局关系模块在深度嵌入的全局匹配中,局部相关模块学习支持和查询建议之间的像素级和深度互相关,而补丁关系模块则学习深度非线性度量以用于补丁匹配。我们通过实验证明,三个匹配的模块可以相互补充以产生更高的性能。
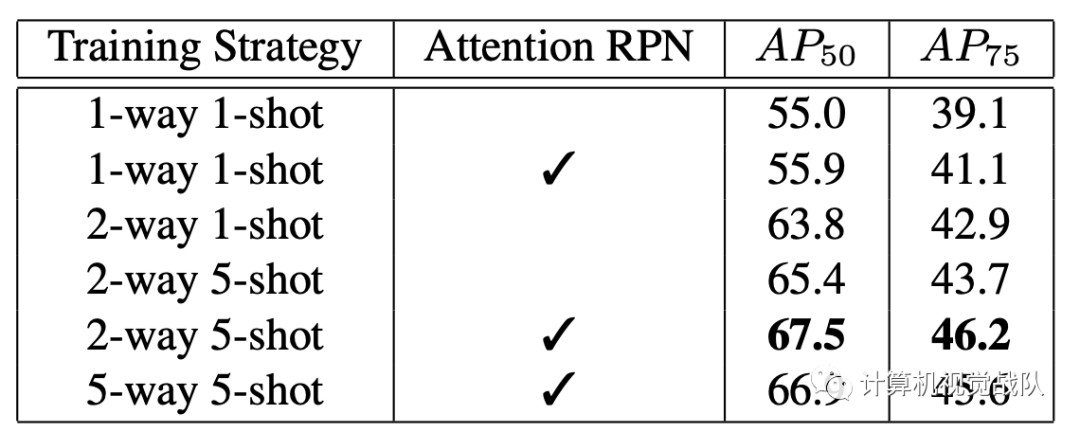
需要哪些关系模块?我们遵循RepMet中提出的Kway N-shot评估协议来评估我们的关系模块和其他组件。表2显示了我们在FSOD数据集的简单1-way 1-shot训练策略和5-way 5-shot评估下对我们提出的多关系检测器的模型简化测试。
此后,我们对FSOD数据集上的所有模型简化测试使用相同的评估设置。对于单个模块,本地关系模块在AP50和AP75评估中均表现最佳。出人意料的是,尽管补丁关系模块对图像之间更复杂的关系进行建模,但其性能比其他关系模块差。我们认为,复杂的关系模块使模型难以学习。当组合任何两种类型的关系模块时,我们获得的性能要优于单个关系模块。通过组合所有的关系模块,我们获得了完整的多重关系检测器,并获得了最佳性能,表明三个提出的关系模块相互补充,可以更好地区分目标与不匹配的对象。因此,以下所有实验均采用完整的多关系检测器。
Two-way Contrastive Training Strategy

2次对比训练三联体和不同的匹配结果。在查询图像中,只有正支持与目标基本事实具有相同的类别。匹配对包括正面支持和前景建议,非匹配对具有三类:(1)正面支持和背景建议;(2)负面支持和前景建议;(3)负面支持和负面建议。选择训练策略:
哪个RPN更好?
我们根据不同的评估指标评估注意力RPN。为了评估提案质量,我们首先评估常规RPN和建议的RPN超过0.5 IoU阈值的前100个提案的召回率。我们关注的RPN具有比常规RPN更好的召回性能(0.9130对0.8804)。然后,我们针对这两个RPN评估整个ground truth框的平均最佳重叠率(ABO)。注意RPN的ABO为0.7282,而常规RPN的相同度量为0.7127。这些结果表明,关注RPN可以生成更多高质量的建议。
上表进一步比较了在不同训练策略下具有注意力RPN的模型和具有常规RPN的模型。在AP50和AP75评估中,注意力RPN的模型始终表现出比常规RPN更好的性能。在AP50 / AP75评估中,注意力RPN在1-way 1-shot训练策略中产生0.9%/ 2.0%的收益,在2-way 5-shot训练策略中产生2.0%/ 2.1%的收益。这些结果证实,我们注意力的RPN会产生更好的建议并有益于最终的检测预测。因此,在我们的完整模型中采用了注意力RPN。
5
实验结果
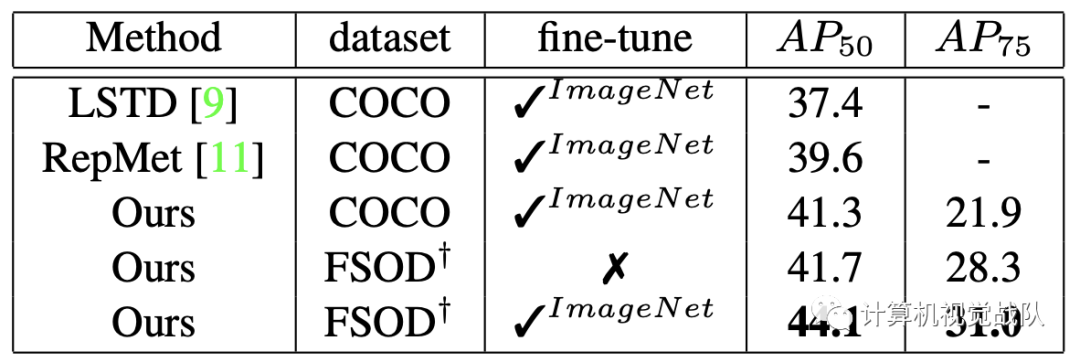
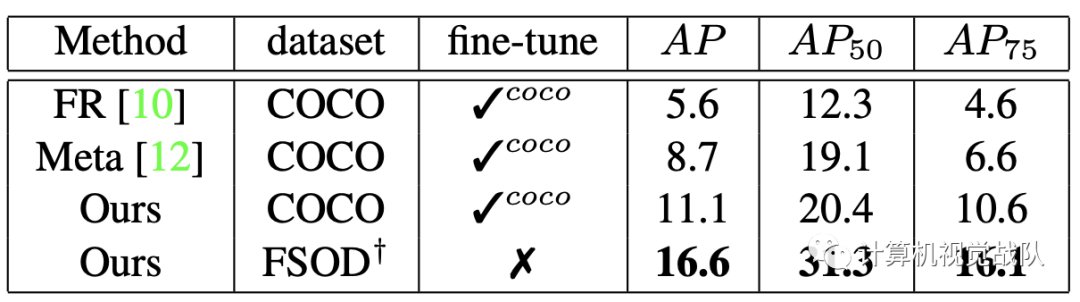

实验可视化


© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
源代码|关注回复“最佳检测”获取
往期推荐
🔗
半监督辅助目标检测:自训练+数据增强提升精度(附源码下载)
目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载)
目标检测新框架CBNet | 多Backbone网络结构用于目标检测(附源码下载)
CVPR21最佳检测:不再是方方正正的目标检测输出(附源码)
Sparse R-CNN:稀疏框架,端到端的目标检测(附源码)
利用TRansformer进行端到端的目标检测及跟踪(附源代码)
细粒度特征提取和定位用于目标检测(附论文下载)
特别小的目标检测识别(附论文下载)
目标检测 | 基于统计自适应线性回归的目标尺寸预测
目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载)
SSD7-FFAM | 对嵌入式友好的目标检测网络,为幼儿园儿童的安全保驾护航
目标检测新方式 | class-agnostic检测器用于目标检测(附论文下载链接)
干货 | 利用手持摄像机图像通过卷积神经网络实时进行水稻检测(致敬袁老)
CVPR 2021 | 不需要标注了?看自监督学习框架如何助力目标检测