NVIDIA GPU A100 Ampere(安培)架构深度解析
文章目录
- NVIDIA GPU A100 Ampere(安培)架构深度解析
- 1. NVIDIA A100 Highlights
- 1.1 NVIDIA A100对比Volta有20x性能的性能提升。
- 1.2 NVIDIA A100的5个新特性
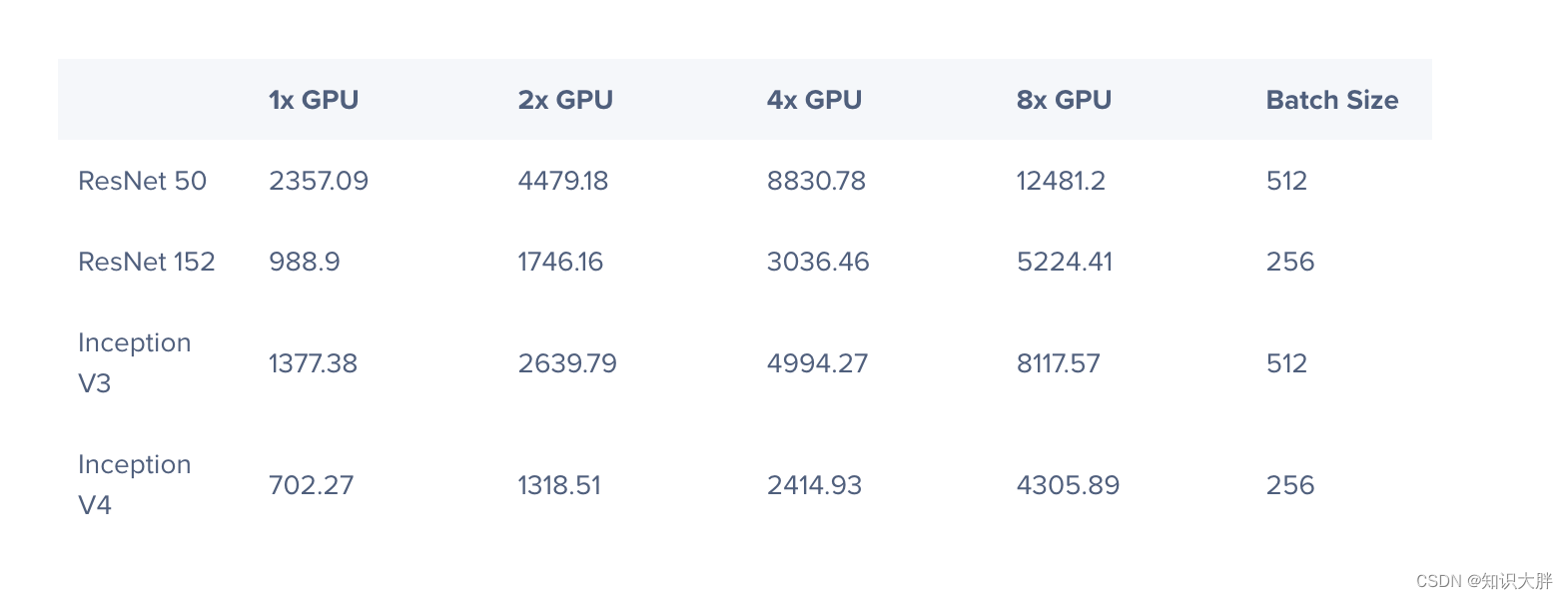
- 1.3 AI加速:使用BERT-LARGE进行训练、推理
- 1.4 A100 HPC 加速
- 1.5 GA100 架构图
- 1.6 GA100 SM架构
- 1.7. A100芯片特性总结
- 2. Elastic GPU
- 2.1 A100 NVLINK BANDWIDTH
- 2.2 NVLink和NVSwitch实现技术和工作原理
- 2.3 DGX A100
- 2.4 SCALE-OUT: MIG (MULTI-INSTANCE GPU)
- 3. Tensor Core
- 3.1 TF32 & BF6 DETAILS
- 4. 性能优化 key features
- 4.1 结构稀疏性
- 4.2 计算数据压缩
- 4.3 L2 Cache驻留控制
- 4.4 从global Memory到share memory的异步拷贝
- 5.参考资料
1. NVIDIA A100 Highlights
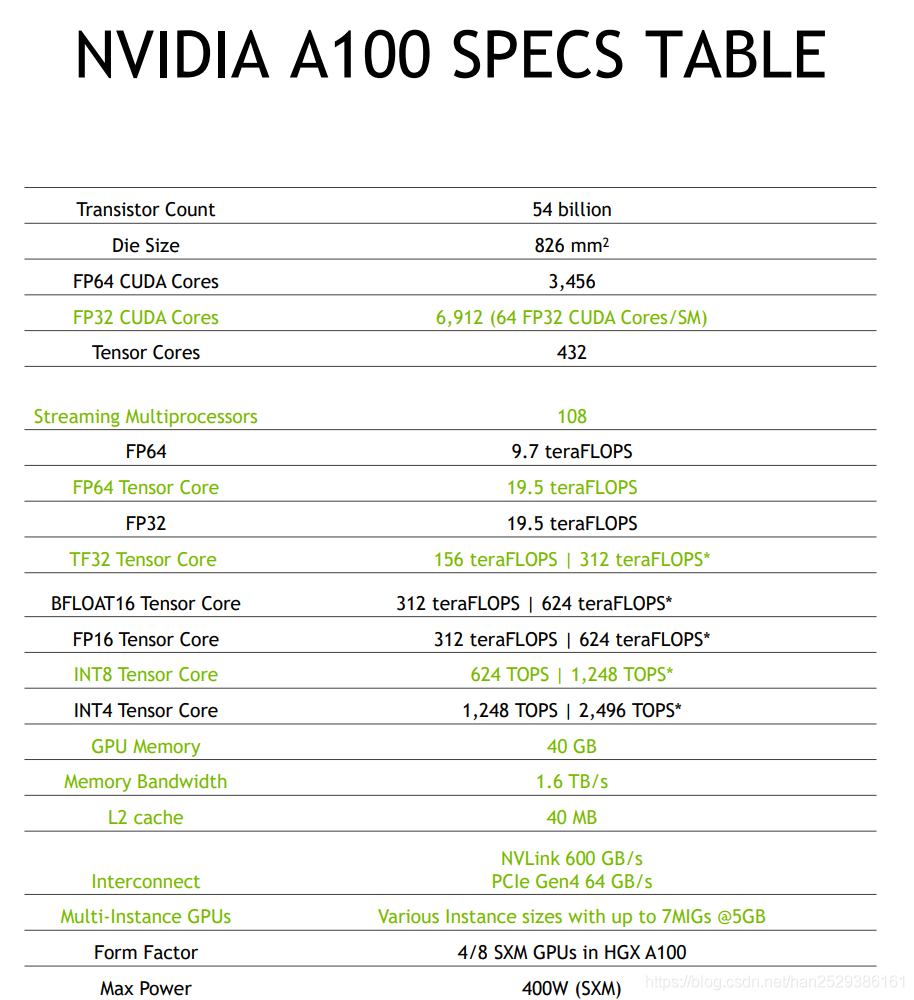
NVIDIA A100 SPECS TABLE
1.1 NVIDIA A100对比Volta有20x性能的性能提升。

1.2 NVIDIA A100的5个新特性
- World’s Largest 7nm chip 54B XTORS, HBM2
- 3rd Gen Tensor Cores Faster, Flexible, Easier to use 20x AI Perf with TF32
- New Sparsity Acceleration Harness Sparsity in AI Models 2x AI Performance
- New Multi-Instance GPU Optimal utilization with right sized GPU 7x Simultaneous Instances per GPU
- 3rd Gen NVLINK and NVSWITCH Efficient Scaling to Enable Super GPU 2X More Bandwidth

1.3 AI加速:使用BERT-LARGE进行训练、推理

1.4 A100 HPC 加速
与NVIDIA Tesla V100相比,A100 GPU HPC应用程序加速 。

HPC apps detail:
- AMBER based on PME-Cellulose,
- GROMACS with STMV (h-bond),
- LAMMPS with Atomic Fluid LJ-2.5,
- NAMD with v3.0a1 STMV_NVE
- Chroma with szscl21_24_128,
- FUN3D with dpw,
- RTM with Isotropic Radius 4 1024^3,
- SPECFEM3D with Cartesian four material model
- BerkeleyGW based on Chi Sum
1.5 GA100 架构图
NVIDIA GA100由多个GPU处理群集(GPC),纹理处理群集(TPC),流式多处理器(SM)和HBM2内存控制器组成。

A100 GPU的构架名称为GA100,一个完整GA100架构实现包括以下单元:
- 8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU
- 64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU
- 4 third-generation Tensor Cores/SM, 512 third-generation Tensor Cores per full GPU
- 6 HBM2 stacks, 12 512-bit memory controllers
基于GA100架构的A100 GPU包括以下单元:
- 7 GPCs, 7 or 8 TPCs/GPC, 2 SMs/TPC, up to 16 SMs/GPC, 108 SMs
- 64 FP32 CUDA Cores/SM, 6912 FP32 CUDA Cores per GPU
- 4 third-generation Tensor Cores/SM, 432 third-generation Tensor Cores per GPU
- 5 HBM2 stacks, 10 512-bit memory controllers
A100 GPU具体设计细节如下:
- GA100架构一共拥有6个HBM2的内存,每个HBM2内存对应两个内存控制器模块。但A100实际设计的时候内存为40GB,只有5个HBM2模块,对应10个内存控制器。
- 与V100相比,A100内部拥有两个L2 Cache,因此能提供V100 2倍多的L2 Cache带宽。
- GA100拥有8个GPC,每个GPC中拥有8个TPC(GPC:图形处理集群、TPC:纹理处理集群),每一个TPC包含2个SM,因此一个完整的GA100芯片应该包含 8*8*2=128个SM。但现在发布的A100 Spec中只包含108个SM,因此目前的A100并不是一个完整的Full GA100构架芯片。
1.6 GA100 SM架构
新的A100 SM大大提高了性能,建立在Volta和Turing SM体系结构中引入的功能的基础上,并增加了许多新功能和增强功能。
A100 SM架构如下图所示。Volta和Turing每个SM具有八个Tensor Core,每个Tensor Core每个时钟执行64个FP16 / FP32混合精度融合乘加(FMA)操作。
A100 SM包括新的第三代Tensor内核,每个Tensor Core每个时钟执行256个FP16 / FP32 FMA操作。A100每个SM有四个Tensor Core,每个时钟总共可提供1024个密集的FP16 / FP32 FMA操作,与Volta和Turing相比,每个SM的计算能力提高了2倍。
下图显示了新的A100(GA100)SM架构。

1.7. A100芯片特性总结
- 第三代Tensor Cores的特性:
- BF16和TF32的混合精度计算
- Double precision FP64 DFMA
- 结构化稀疏
- 1.555GB/s的HBM2 memory bandwidth, 与Tesla V100相比增加了73%。
- 192 KB的共享内存和L1数据缓存组合,比V100 SM大1.5倍。
- shared memory and L2 cache都进行了增大, 40 MB的L2 Cache比V100大7倍。 借助新的partitioned crossbar结构(2个L2 Cache),A100 L2缓存提供了V100的L2缓存读取带宽的2.3倍。
- 新的异步复制指令将数据直接从全局存储器加载到共享存储器中,可以绕过L1高速缓存,并且不需要使用中间寄存器文件(RF)。
- Hardware JPEG decoder
- 多实例GPU (MIG)
- 第三代NVLINK and NVSWITCH
2. Elastic GPU
- Scale-up: 纵向扩展,解决更大的问题。3rd Gen NVLINK, NVSWITCH, DGX A100, DGX POD/SUPERPOD
- Scale-out: 横向扩展,解决更多的问题。MIG (Multi-instance GPU)
注释:
Scale Up是指垂直方向上的扩展。一般对单一设备节点而言,Scale Up是当某个计算节点(机器)添加更多的CPU,GPU设备,存储设备,使用更大的内存时,应用可以很充分的利用这些资源来提升自己的效率从而达到很好的扩展性。
Scale Out是指水平方向上的扩展。一般对分布式设备节点(数据中心)而言,Scale out指的是当添加更多的机器时,应用仍然可以很好的利用这些机器的资源来提升自己的效率从而达到很好的扩展性。
2.1 A100 NVLINK BANDWIDTH

A100 NVLINK有12个Link口,每个Link有4个signal pairs,每个signal pairs的带宽为50Gbit/s,因此每个Link的单路带宽为50GBit/s * 4 / 8 = 25GByte/s。Link中有in/out双路,因此一个Link的总带宽为50GB/s。
2.2 NVLink和NVSwitch实现技术和工作原理
下图展示了CPU和GPU内部数据流和控制流是如何传输的。
GPU通过PCIe总线与CPU相连,白色走线表示控制流,CPU通过PCIe I/O口控制data和kernel work执行,然后GPC通过XBAR访问L2 Cache或者HBM2内存数据,最后输出的result也是通过XBAR和PCIe传回CPU。

当一个GPU想要通过PCIe的方式访问另一个GPU的HBM时,其控制流和数据流如下图所示。
数据流从GPU1 HBM -> GPU1 XBAR -> GPU1 PCIe -> GPU0 PCIe -> GPU0 XBAR -> GPU0 GPC。通常当数据量很大时,PCIe带宽会出现堵塞。

使用NVLink做同样的事,访问其他GPU HBM数据时,如下图所示:
数据流从 GPU1 HBM -> GPU1 XBAR -> GPU1 NVLink端口 -> GPU0 NVLink端口 -> GPU0 XBAR -> GPU0 GPC。
不用通过PCIe链路,也不会出现拥塞的情况。实际上两个GPU的NVLink之间由NVSwitch相连,图中没有画出。
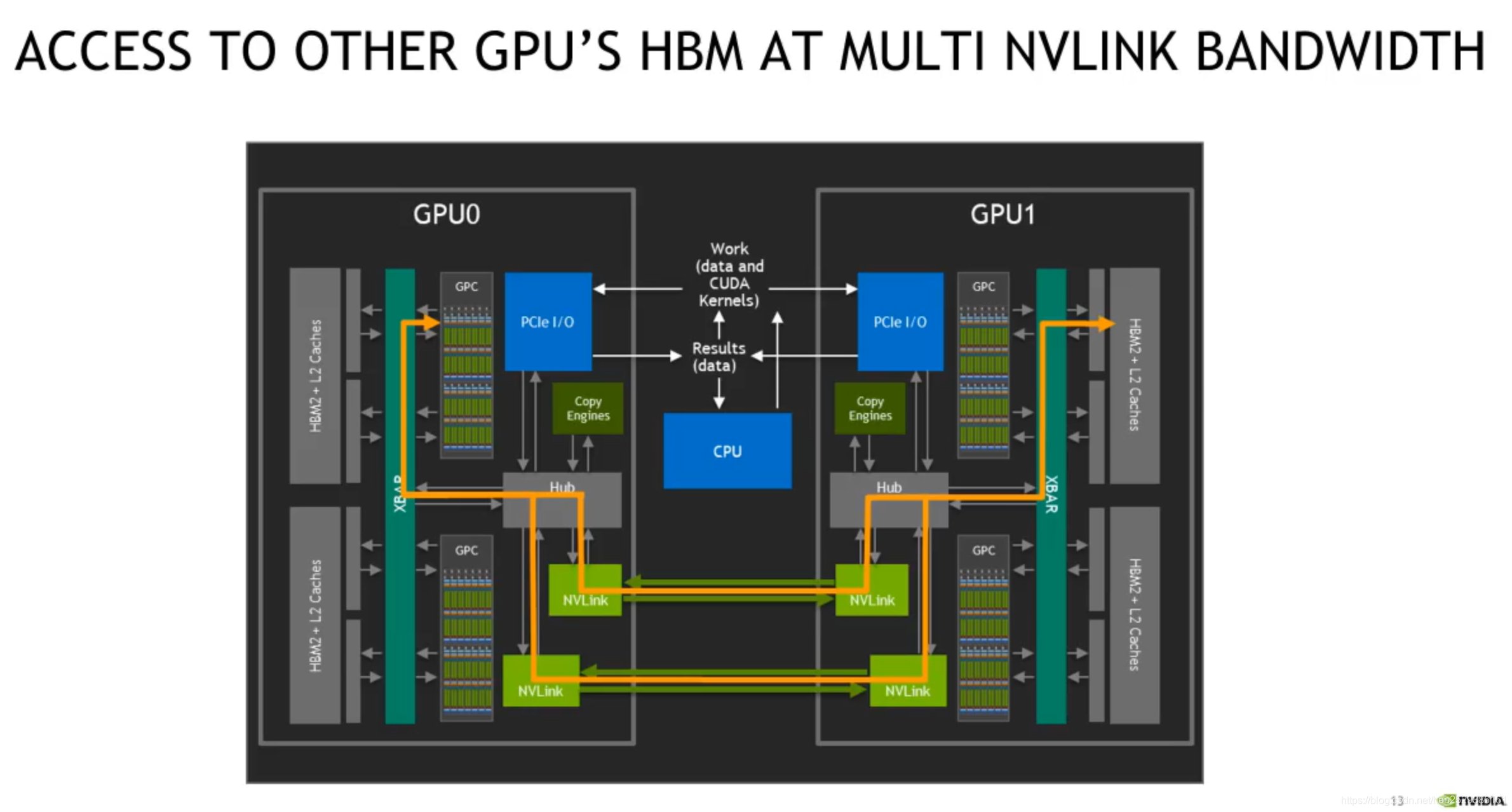
从上面可以看出,NVLink和NVSwitch的工作原理就是把两个GPU的XBAR连接在一起了。因此,NVIDIA经常说的将多个GPU通过NVLink和NVSwitch能组成一个巨大的GPU,这并不是一个比喻,实际上底层的确是这样实现的。
2.3 DGX A100

DGX A100的拓扑结构如下图所示:

DGX A100的拓 A100有8个A100 GPU,每个A100 GPU拥有12个NVLink端口,每个GPU拿出2个Link端口与一个NVSwitch连接,一共连接了6个NVSwitch。
-
下层:DGX A100有8个A100 GPU,每个A100 GPU拥有12个NVLink端口,每个GPU拿出2个Link端口与一个NVSwitch连接,一共连接了6个NVSwitch。
-
上层:通过PEX Switch链接了200G的NIC和NVMe。
2.4 SCALE-OUT: MIG (MULTI-INSTANCE GPU)
传统GPU的内部架构:

MIG的目的是使虚拟的每个GPU实例都拥有上面类似的架构。 MIG功能可以将单个GPU划分为多个GPU分区,称为GPU实例。
创建GPU实例可以认为是将一个大GPU拆分为多个较小的GPU,每个GPU实例都具有专用的计算和内存资源。每个GPU实例的行为就像一个较小的,功能齐全的独立GPU,其中包括预定义数量的GPC,SM,L2缓存片,内存控制器和Frame buffer。注意:在MIG操作模式下,每个GPU实例中的单个GPC启用了7个TPC(14个SM),这使所有GPU切片具有相同的一致计算性能。
“Compute Instances ”是一个组,可以配置在GPU实例内创建的不同级别的计算能力,封装可以在GPU实例中执行的所有计算资源(如:GPC,Copy Engine,NVDEC等)。默认情况下,将在每个GPU实例下创建一个 Compute Instances,从而公开GPU实例中可用的所有GPU计算资源。可以将GPU实例细分为多个较小的 Compute Instances,以进一步拆分其计算资源。

下面是 pre-A100 GPU和A100 MIG的对比。

pre-A100 GPU每个用户独占SM、Frame Buffer、L2 Cache。

A100 MIG将GPU进行物理切割,每个虚拟GPU instance具有独立的SM、L2 Cache、DRAM。

下面是MIG 配置多个独立的GPU Compute workloads。每个GPC分配固定的CE和DEC。A100中有5个decoder。
当1个GPU instance中包含2个Compute instance时,2个Compute instance共享CE、DEC和L2、Frame Buffer。

Compute instance使多个上下文可以在GPU实例上同时运行。


3. Tensor Core
3.1 TF32 & BF6 DETAILS
如今,用于AI训练的默认数学是FP32,没有张量核心加速。NVIDIA Ampere架构引入了对TF32的新支持,使AI培训默认情况下可以使用张量内核,而无需用户方面的努力。非张量操作继续使用FP32数据路径,而TF32张量内核读取FP32数据并使用与FP32相同的范围,但内部精度降低,然后生成标准IEEE FP32输出。TF32包含一个8位指数(与FP32相同),10位尾数(与FP16相同的精度)和1个符号位。


4. 性能优化 key features
4.1 结构稀疏性
借助A100 GPU,NVIDIA引入了细粒度的结构稀疏性,这是一种新颖的方法,可将深度神经网络的计算吞吐量提高一倍。
Tensor Core的细粒度结构化稀疏度
- 50%细粒度的稀疏度
- 2:4模式:每个连续的4块中必须有2个值必须为0
应对3个挑战:
-
准确性:保持原始未修剪网络的准确性
-
中等稀疏级别(50%),细粒度
-
Training:显示可在任务和网络上工作的配方
Speedup:
- 专业的Tensor Core支持稀疏数学
- 结构化:有助于有效利用内存


NVIDIA开发了一种简单而通用的配方,用于使用这种2:4结构化的稀疏模式来稀疏深度神经网络进行推理 。首先使用密集权重对网络进行训练,然后应用细粒度的结构化修剪,最后使用其他训练步骤对剩余的非零权重进行微调。基于跨视觉,对象检测,分割,自然语言建模和翻译的数十个网络的评估,该方法几乎不会导致推理准确性的损失。
A100 Tensor Core GPU包括新的Sparse Tensor Core指令,该指令会跳过具有零值的条目的计算,从而使Tensor Core计算吞吐量翻倍。图9显示了Tensor Core如何使用压缩元数据(非零索引)将压缩权重与适当选择的激活进行匹配,以输入到Tensor Core点积计算中。


结构化稀疏带来的性能提升如下图所示:

使用结构化稀疏来训练神经网络需要经过三个步骤:

4.2 计算数据压缩
因为模型中有ReLU层的存在,模型数据中包含大量的稀疏矩阵或0值。压缩这些稀疏矩阵可以节省内存空间和带宽。

通过Allocating compressible memory——用cuMemMap + cuMemCreate(驱动程序API)替换cudaMalloc,并使用CU_MEM_ALLOCATION_COMP_GENERIC。

对于一个memory bound问题,可以考虑使用数据压缩功能,性能可提升75%。

下面是使用nsight,可以看到是否使用了数据压缩的功能。


4.3 L2 Cache驻留控制
L2 Cache是介于Global Memory和SMs之间的缓存,如果kernel访问Global Memory数据都能被L2 Cache命中,那么程序的整体性能会有很大提升。

L2 Cache拥有40MB大小,拿出L2缓存的一部分作为持久数据访问,最大可以分配30MB的持久L2 Cache。持久访问在L2缓存中的驻留优先级高于其他数据访问。

可以使用accessPolicyWindow将全局内存区域与L2 Cache的持久区域进行映射。映射的目的是这部分的global memory中的数据可以尽可能的被保存在L2 持久Cache中。因此在流或CUDA图中启动的内核在global memory标记的数据区域上具有持久性属性。

使用完L2 持久Cache后,可以用一下方法释放掉。

4.4 从global Memory到share memory的异步拷贝
下面是传统的将数据从global Memory拷贝到share memory的过程。

复制过程如下,其缺点是:
- 浪费寄存器以及占用寄存器带宽
- 必须等到数据load才能继续操作
- 浪费L1/SHM带宽

现在直接绕过L1或者寄存器,直接走L1或者L2 cache进行拷贝到SHM。

这样,前后对比的代码如下:这样可以直接将数据从global Memory拷贝到share memory 。

下图是两种拷贝的性能对比,这种异步拷贝性能远远大于同步拷贝。

对于多阶段的pipeline拷贝和计算,可以overlap掉memory copy的时间。

其目的是pipeline一边拷贝着数据,一边处理着上一波拷贝好的数据。

多阶段的异步拷贝pipeline的代码如下,其核心是一边拷贝,一边计算拷贝好的数据,以达到overlap掉拷贝数据时间的目的。

5.参考资料
- https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdf
- https://devblogs.nvidia.com/nvidia-ampere-architecture-in-depth/
- https://apposcmf8kb5033.h5.xiaoeknow.com/content_page/eyJ0eXBlIjoxMiwicmVzb3VyY2VfdHlwZSI6NCwicmVzb3VyY2VfaWQiOiJsXzVlYzNkOTM1OTQwOGJfWExTeWUyYXMiLCJwcm9kdWN0X2lkIjoiIiwiYXBwX2lkIjoiYXBwb1NDTWY4a2I1MDMzIiwiZXh0cmFfZGF0YSI6MH0