Linux进程内存分布

验证地址空间排布
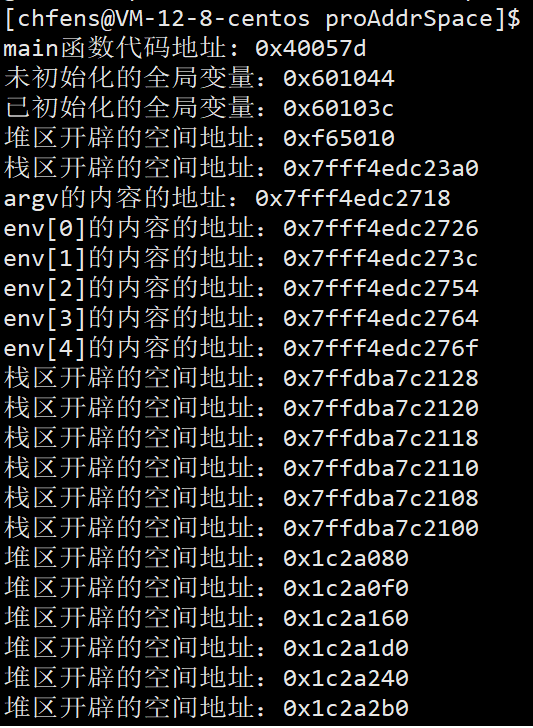
结论:堆区向地址增大的方向增长,栈区向地址减少的方向增长。局部变量通常保存在栈上,先定义的先入栈,地址是比较高的,后定义的则地址小。
static变量
作用域不变,生命周期改变,如何改变?
编译器会把静态变量放到全局区。静态变量和全局变量的存在同一块空间的,但是只有在函数内才可见。
进程地址空间
每一个进程被运行的时候,操作系统都会为其创建进程地址空间,也会建立各自的页表。虚拟地址空间是物理地址的映射。
如何管理地址空间?
先描述再组织。进程地址空间实际上也是内核中的一个数据结构,mm_struct。
虚拟地址和物理地址之间会有一个页表用于建立映射关系。
mm_struct和vm_area_struct
mm_struct是虚拟地址空间,vm_area_struct是用于划分区域的。
task_struct里有一个mm_struct指针指向虚拟地址空间结构体。
mm_struct里有一个vm_area_struct指针指向mmap,维护了虚拟地址空间的各个区域,来划分每一个区域(栈、堆、代码区)的起点与终点。
unsigned long total_vm, locked_vm, shared_vm, exec_vm;unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;unsigned long start_code, end_code, start_data, end_data;unsigned long start_brk, brk, start_stack;unsigned long arg_start, arg_end, env_start, env_end;
标识每个区域的起始和终止地址范围。
这里的地址作为页表的K值来与物理地址建立映射。
页表是进程加载到程序的时候自动建立的。通过页表的K值找到实际物理内存里的数据。
程序是如何被加载变成进程的?
程序被编译后,还没被加载,此时程序内部有地址和区域吗?
有!链接就是把程序内部函数的地址和库中函数的地址关联起来。
编译后区域已经划分好了,变量放在对应的区域。除了堆区和栈区是加载到内存之后才有的。
进程本身中的代码也会有地址,但是这个地址是虚拟地址,在页表中作为K值,经过映射,加上偏移量,就能找到实际占用操作系统资源的地址。
比如程序中函数的代码的地址在程序中已经确定,为0x100,加载到内存后,这个地址加上了偏移量10000,放在了内存上的代码区。进程开始后,运行到这里,就要到物理内存中的0x10100中去找。编译后代码的位置已经确定,放到内存中又是一回事,因此要加上偏移量放到物理内存上。
fork的返回值
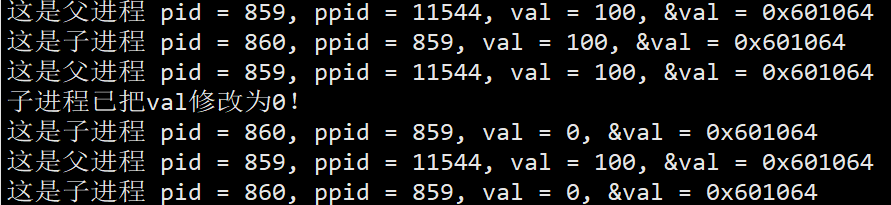
修改子进程val后父进程的val不变,同一地址的变量会有两个值?
很显然,在C/C++中的地址并不是内存物理上的地址,而是操作系统提供的虚拟地址,操作系统不允许直接读取物理内存。虚拟地址是一样的,但是物理地址是不一样的。
val是父进程的栈空间中的变量,fork函数return会被执行两次,return的本质就是通过寄存器赋值。当父子各自执行return,会发生写时拷贝。
写时拷贝
进程具有独立性,为了保证进程间数据独立,进程间不相互干扰,会有数据的写时拷贝,得到一张新的页表。在上面的程序中,变量的物理地址实际就不同了,因此数据也是不同的。
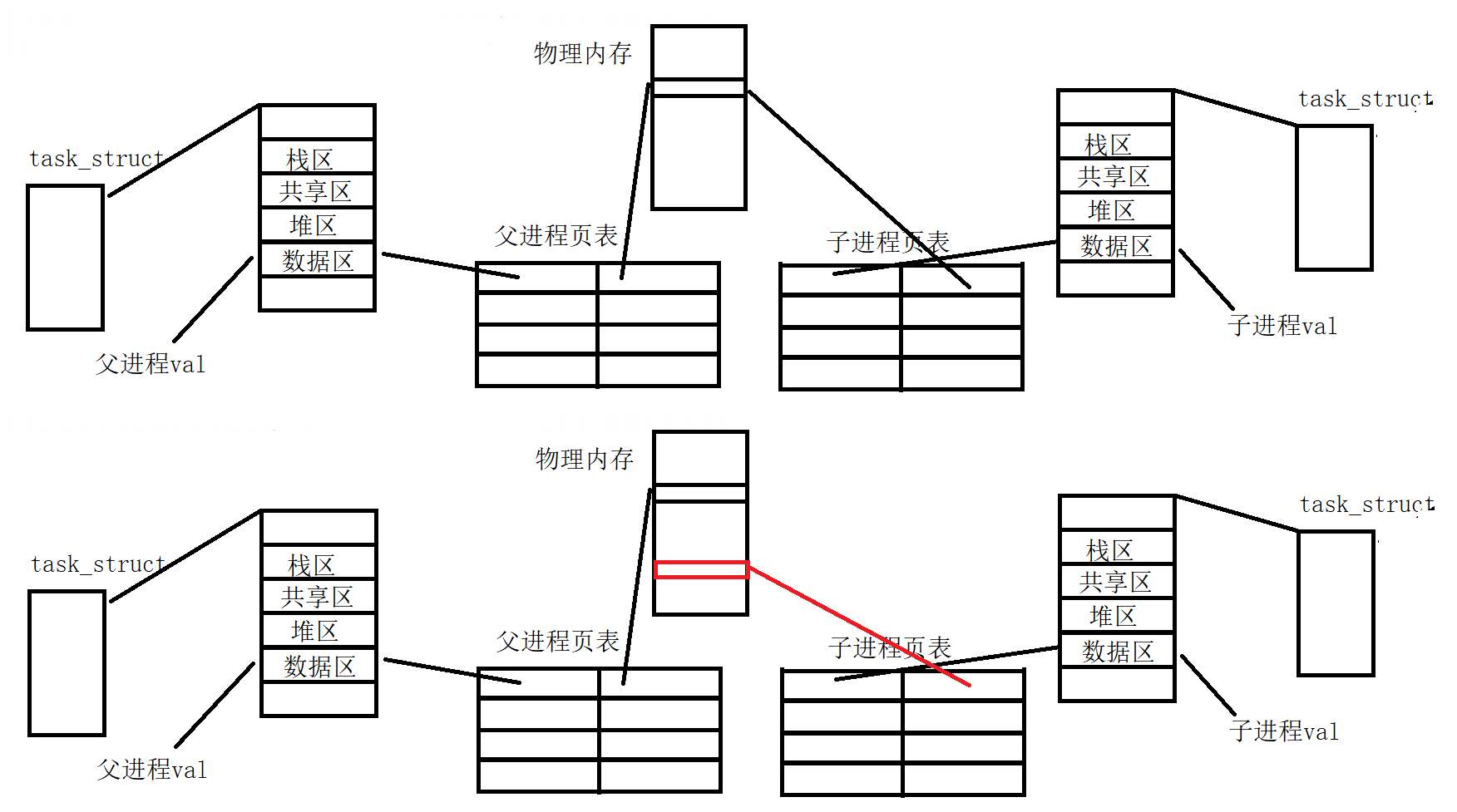
为什么要写时拷贝?
为什么不创建子进程的时候就写时拷贝?
在数据被修改的时候再深拷贝,而不是一开始就全部拷贝下来,因为可能数据都是只读的,可以节省空间。
最理想的是:只拷贝父进程中会被修改的数据,但是这是无法预测的,因此只能采用写时拷贝这种方式妥协。
代码会不会有写时拷贝?
如果涉及程序替换的时候就会。
为什么要有进程地址空间?
保证进程的独立性
有了自己的虚拟空间之后,就不会有任何系统级别的越界问题存在了。对某一地址空间进行操作之前需要先通过页表映射到物理内存,而页表只会映射属于各个进程自己的物理内存。
解耦了虚拟地址和物理地址
每个进程都认为拥有相同的空间范围,认为自己在独占内存,包括进程地址空间的构成和内部区域的划分顺序等都是相同的,编写程序的时候就只需关注虚拟地址,而无需关注数据在物理内存当中实际的存储位置。
进一步完善进程的独立性以及合理分配内存空间(当实际需要使用内存空间的时候再在内存进行开辟),并能将进程调度与内存管理进行解耦或分离。
比如Linux下向系统malloc申请空间时,系统不会立即真实分配,而只是修改vm_area中的起点和终点,因为怕用户占着不用浪费资源,而是在用户调用到的时候再立刻申请,建立页表映射关系。