英伟达近期发布了名为霍普的下一代GPU架构以及最新的H100 GPU。
H100&Hopper
- GPU SPC
- NVIDIA DEVELOPER
- NVIDIA GPU H100
- CUDA
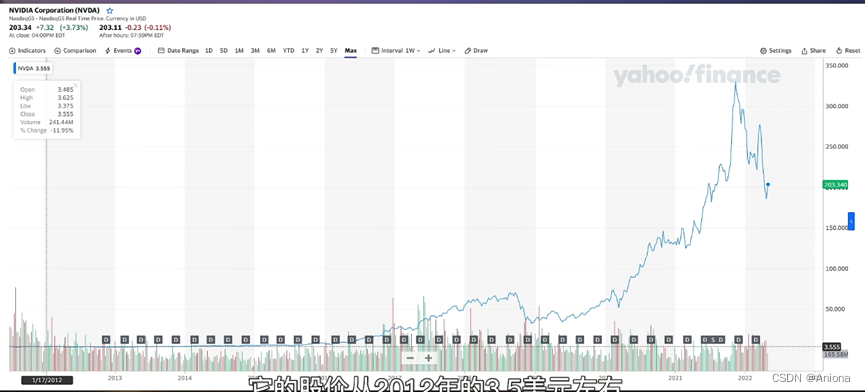
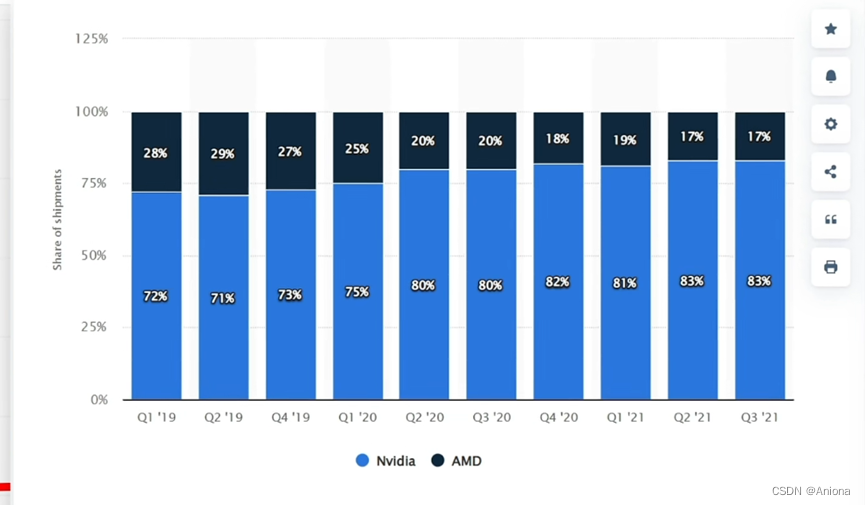
事实上GPU的发展一直保持着非常告诉的推进,从开始的开普勒到上一代安培,再到最新的霍普,10年里GPU在AI应用里的性能提升超过了300倍。
GPU SPC
AI的发展和GPU的发展其实是交织在一起不断螺旋前进的过程,这个特点贯穿了英伟达GPU发展的整个阶段.GPU的全名叫Graphic Processing Unit(图形处理器),GPU本行是做图形图像处理的。一张图片是由很多的像素点组成,图片显示就是将显示器中的像素点一个一个显示出来,至于显示的先后顺序并不重要,因此GPU最大的特点就是包含成百上千个计算核心,让每个核心处理一个像素点,这样就可以在同一事件完成一张图片里所有像素点的处理。
GPU的这种基于大量计算核心的结构,也是它与中央处理器CPU的最大区别。CPU像一个知识渊博的大教授,各种微积分都会做,但是工资非常高,而且培养这种人才非常难,而GPU就像一群只会加减乘除的小学生,但是对于大量简单运算来说,用几十个小学生算的速度肯定要快过一个大教授,所以GPU擅长做计算密集并且可以大量并行执行的应用,深度学习和AI应用就符合这个特点,比如神经网络里有大量相互独立的神经元,可以用来做并行运算,而且AI应用里最常见的卷积运算,本质上就是简单的乘法和加法。
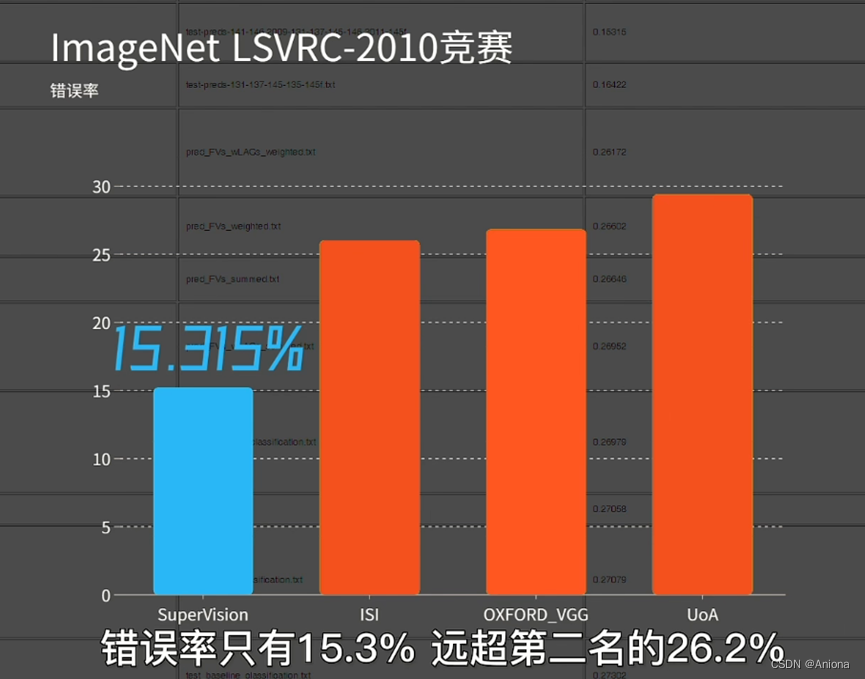
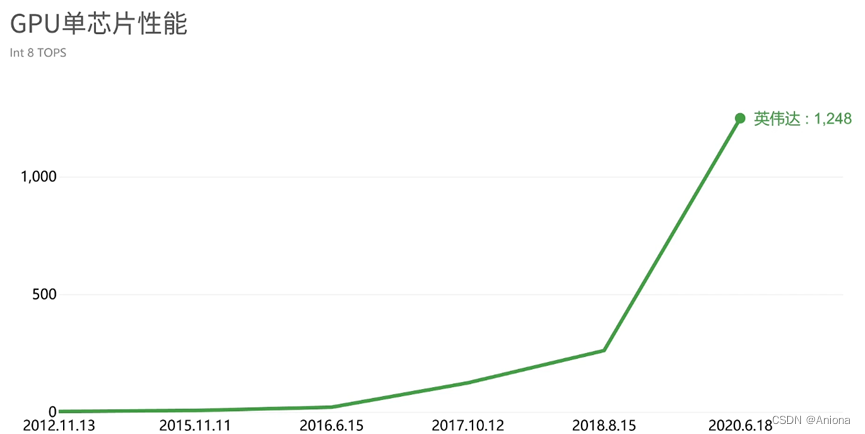
2012年,被称作“神经网络之父”和“深度学习鼻祖”的多伦多大学教授杰弗里辛顿和他的博生生Alex发表了AlexNet,就是利用深度学习加GPU的方案,一度获得了ImageNet LSVRC-2010竞赛的冠军,错误率15.3%,第二名26.2%。同年英伟达发布了名叫“开普勒”的GPU,由此开始了GPU在AI时代的升级之路,在去年年底的DAC会议上,英伟达首席科学家Bill Dally做了主题演讲,提到从2012年的开普勒到2020年的安培,GPU的单芯片性能在8年里提升了317倍,之所以能取得这样的性能提升,主要有两个方面的原因。
首先不可忽视的是半导体制造工艺的进步,从28nm到7nm再到H100的4nm工艺至少跨越了6-7代,也就是说,即使芯片架构保持不变,单靠工艺升级的红利,性能也会有好几倍的提升。
这部分功劳属于台积电和三星这样的芯片制造厂商。
NVIDIA DEVELOPER
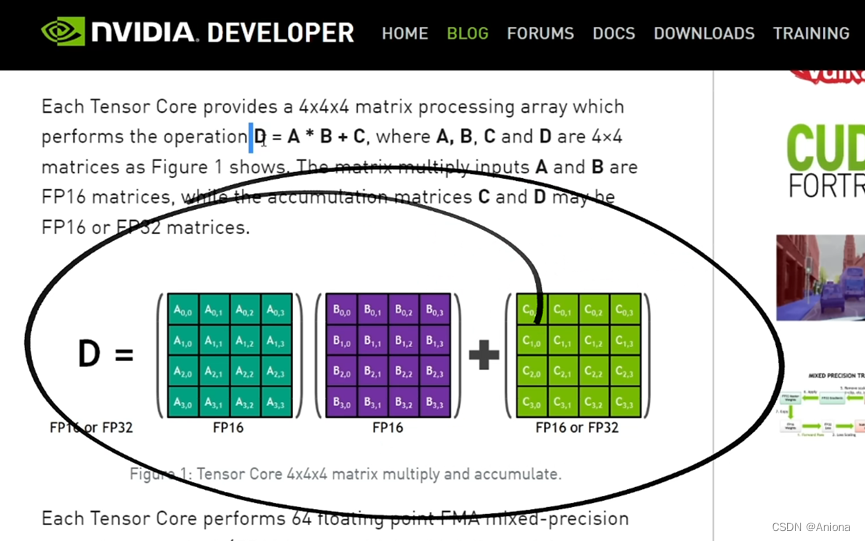
取得性能提升另一个非常终于的原因,就是英伟达在自己芯片架构上的优化。首先是最典型的张量核心,是专门用来优化计算矩阵相关的乘法-累加运算的,这部分运算就是AI算法里最常见的运算形式。这就像装机的时候如果CPU是性能瓶颈,就可以换个更强的CPU,如果主板是瓶颈,就换个更好的主板,总之打通瓶颈之后系统性能自然就提升了。
第二个架构优化是在GPU里支持更低精度的数据运算,比如从开普勒的32位浮点到图灵开始支持8位整型的AI推理,这是因为研究AI算法的人发现,推理的时候降低运算精度虽然会导致准确度下降,但这种损失可以忽略不计,这个发现意味着我们可以通过选择更低的精度来换取几乎免费的算力提升。
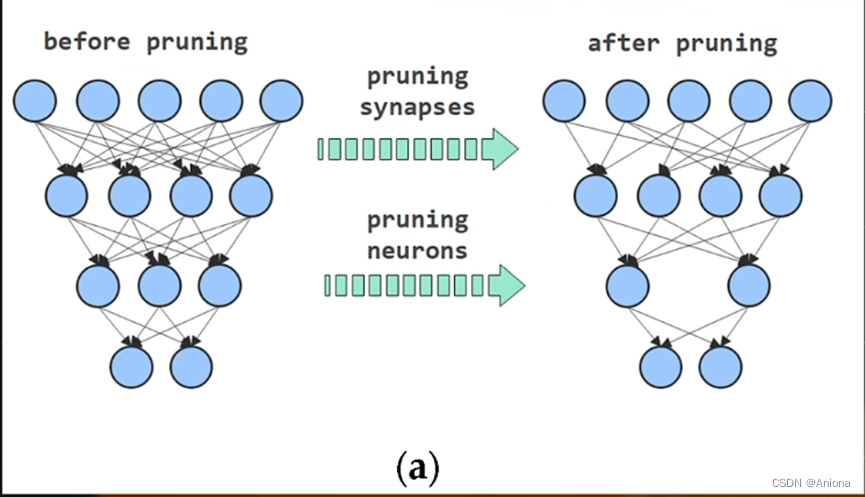
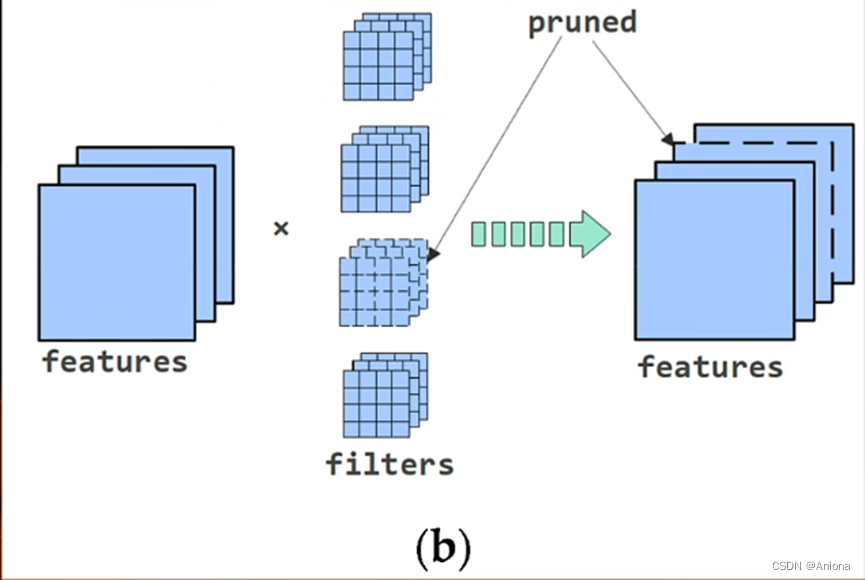
第三个架构优化技术就是结构化剪枝技术,剪枝是MIT的韩松教授提出的一种AI模型的压缩技术,他发现在AI模型中,神经元之间的联系有着不同的紧密程度,剪掉一些不那么终于的连接,基本上不会影响模型的精度,但运算量就大大减少了,该方法理论上简单直接,但硬件的角度来看,真正实现该方法有一定难度,但最重要的就是如何高效的处理剪枝带来的带来的稀疏性,在2020年发布的安培架构里,英伟达引入了对结构化剪枝和稀疏张量核心的支持。
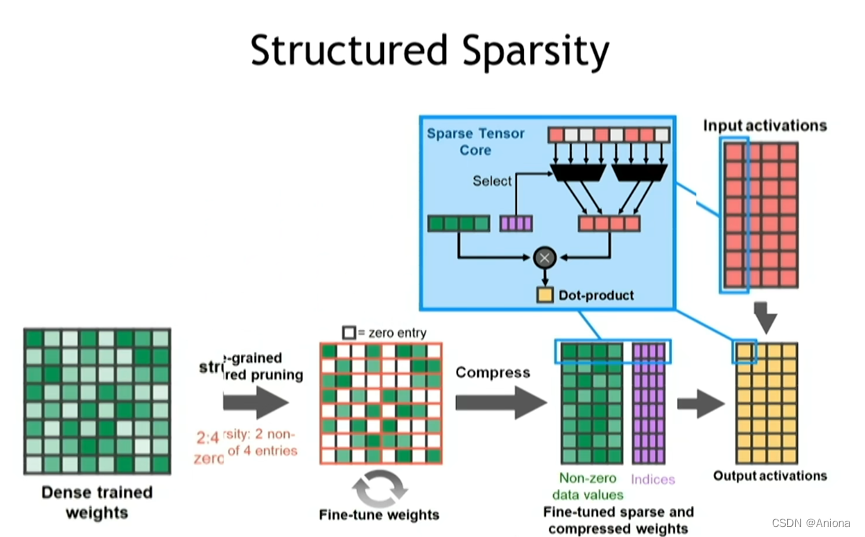
可以通过设置一定的约束条件,保证权重矩阵中被剪枝的元素满足一定的分布规律,从而能够有效的将剪枝带来的稀疏性转化为更高的AI模型处理效率。AI的算法与芯片这两条发展主线是螺旋交替前进的,一个发展到了一定程度会拽着另一个发展起来甚至更快,这样才能开启下一个阶段。
在距离开普勒GPU发布10个念头的时候,下一步该如何发展。接下来英伟达霍普就发布了。
NVIDIA GPU H100
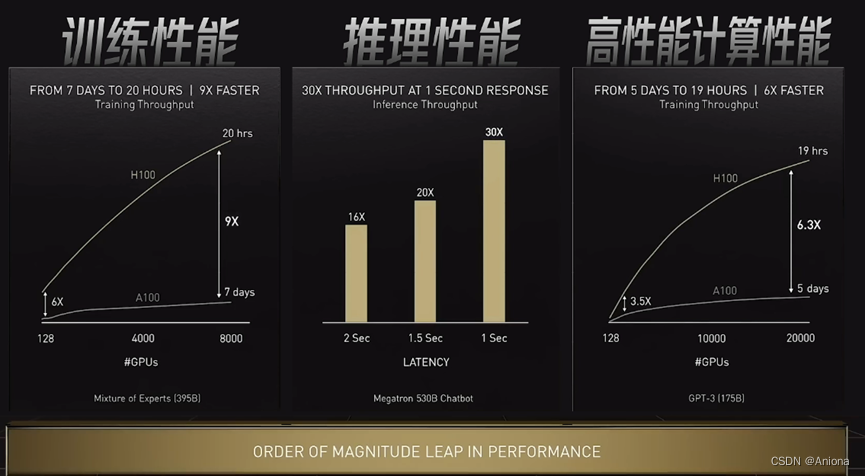
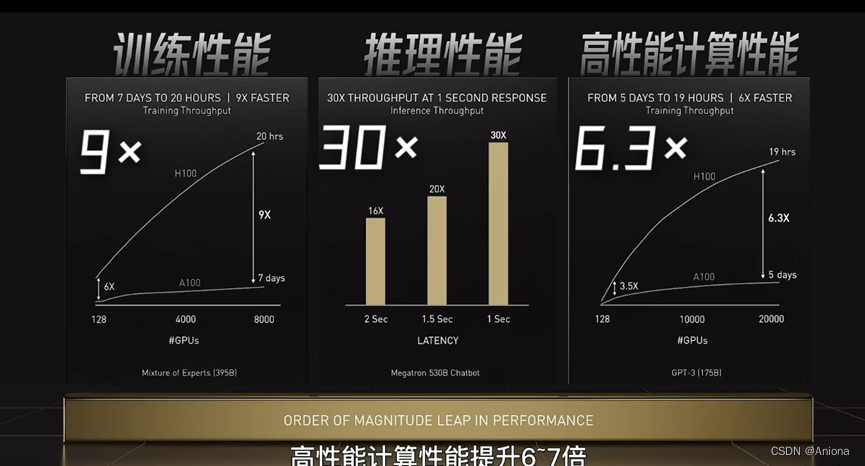
和前一代基于安培架构的A100相比,基于霍普架构的H100在执行AI训练和推理任务时,性能高达9倍和30倍的提升,这方面提升的主要原因有三个,分别是低精度运算,专用电路和动态编程。
首先,霍普支持8位浮点数运算,主要针对的还是推理领域,但是研究者逐渐意识到,除了推理,在大部分的训练任务的时候,过高的数据精度也不是必须的,所以如果把支持的浮点数精度从前一代的FP16下探到FP8,此项改变提升了一倍的算力,此外霍普引入了更多的专用电路,从某种意义上来说所有的芯片的设计其实都是专用和通用的权衡。专用电路取代一定的通用电路能让芯片在处理一些特定任务的时候高效得多,因为专用芯片就是为了这些任务而设计。
这样一来,就意味着芯片的应用场景和这些具体的任务捆绑起来了,苹果的M1芯片其实就是很有代表性的例子,通过大量采用专用电路,M1在视频剪辑这些特定任务里性能拔群,而苹果之所以要堆硬件区发力这个领域,是因为视频剪辑内容创作就是苹果电脑最重要的应用场景,专业的摄像师音乐家程序员买苹果电脑就是用来做这个,所以是否牺牲通用性,背后反映的是一家公司对于某种技术或某种市场的预期和把握。
回到英伟达新发布的Hopper(霍普)和H100,它继承了对Transformer这种神经网络模型的专用硬件支持,和卷积神经网络CNN相比,Transformer是神经网络模型里的一个势头非常猛的“新人”,2017年,当时在Google工作的Ashish Vaswani等人发表了一篇论文《Attention is all you need》,第一次提出了Tranformer网络体系结构,Tranformer完全基于注意机制,完全不需要递归和卷积。被引用40000+次数,体现了Transformer模型的巨大影响力,这篇文章的一作和三作Ashish和Niki,前不久离开Google去创业研究通用人工智能了。
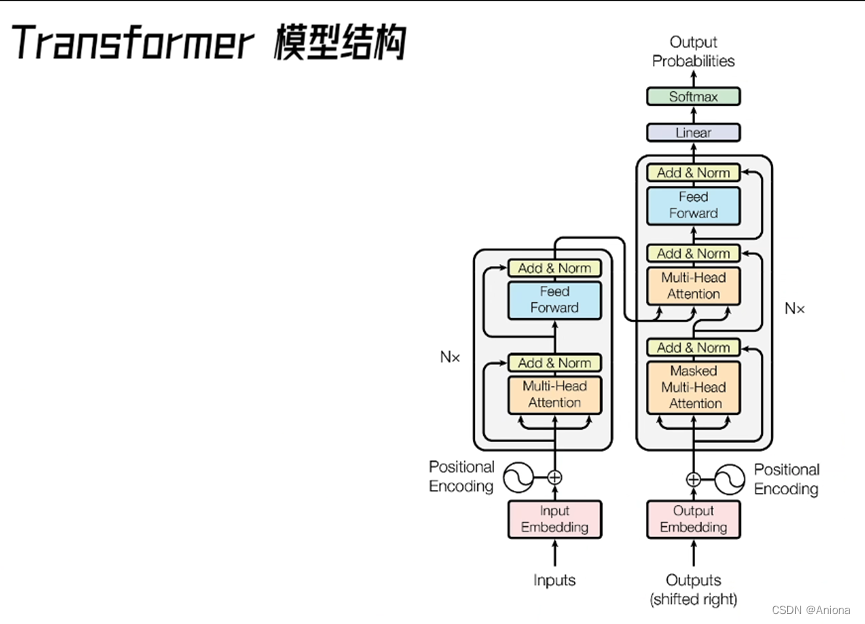
它的强大影响力主要因为它基于注意力机制,有很强的通用性,它不仅在自然语言处理NPL相关的任务中有突出表现,更启发了很多性能非常有优异的网络模型,比如BERT/GPT-3等等,近年来在语义识别,机器翻译许多这些NLP的子领域里取得的研究进展都与Transformer息息相关。
天下没有免费的午餐,处理Transformer模型通常会伴随着巨大的运算量,比如GPT-3模型里参数数量已经达到1750亿个,这么大的运算量就给传统的芯片硬件带来了巨大的压力,所以Transformer一方面有着极大的影响力,另一方面又需要更强的运算能力,所以英伟达选择开发专用的计算引擎来加速Transformer相关的运算。在这个引擎中,一个重要的特点是它对混合精度的支持,它背后的原理是即使在同一个Transformer模型中,不同层的运算对于计算精度敏感性是不同的。
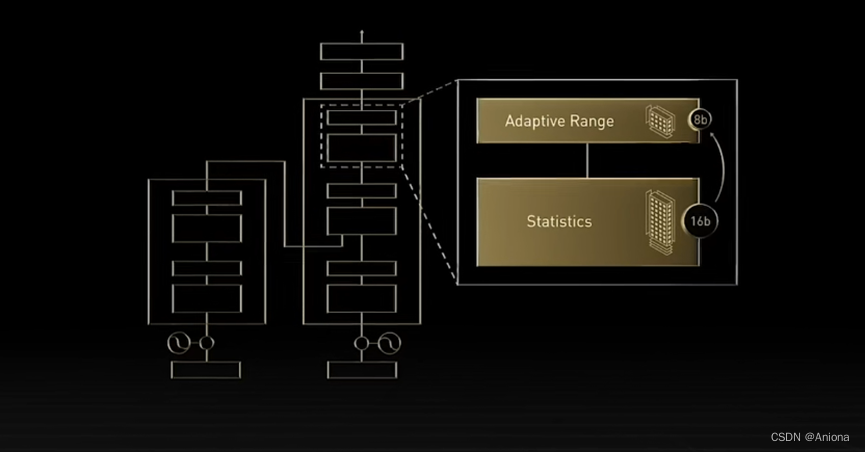
也就是说,即使不用高运算精度来训练整个模型,最终得到的模型质量并不一定差,所以英伟达的整个Transformer引擎可以自动化地选择合适的计算精度,对于精度敏感的层就用FP16进行计算,反之就用FP8来处理。当然了,除了H100的Transformer Engine,学术界也有很多针对Transformer的硬件加速器研究,比如2020和2021年在计算机领域顶会HPCA上发表的A3和SpAtten这两篇文章讲的都是这方面的内容。

Hopper的第三个主要特点就是引入了一组新的指令集DPX,用它来支持动态编程,主要用来解决一些复杂的数学问题,比如在数学里有个非常有名的旅行商问题,最早是英国的数学家在19世纪提出来的,旅行商要在不同城市之间往来做生意,这些城市之间的距离是固定的,如何选择最短路径,让旅行商能够拜访所有的城市一次而且最后回到出发的城市呢?
最简单的方法是穷举法,但如果城市数量很多,穷举的事件就会非常长,对于这类问题我们就可以使用东莞太规划的方法,把问题逐渐划分成几个简单的子问题,然后通过递归的方式得到解答,之前动态编程通常是通过CPU或者FPGA来完成的,但这次通过DPX指令集,让Hopper成为了英伟达的第一个动态支持编程的GPU架构。
CUDA
从开普勒到安培再到霍普,回顾了英伟达GPU十年的发展轨迹,AI本身和芯片硬件的发展是不断交替前进的,更重要的软件部分英伟达也构建了成熟的CUDA软件生态,因为CUDA的易用性和通用性。