文章目录
- 本文参考
- UIE理论部分
- step0、UIEX原始模型使用
- 网页体验
- 本机安装使用
- 环境安装
- 使用docker的环境安装
- 快速开始
- step1、UIEX模型微调(小样本学习)
- 数据标注(label_studio)
- 导出数据转换
- 微调训练:
- 评估:
- 定制模型一键预测
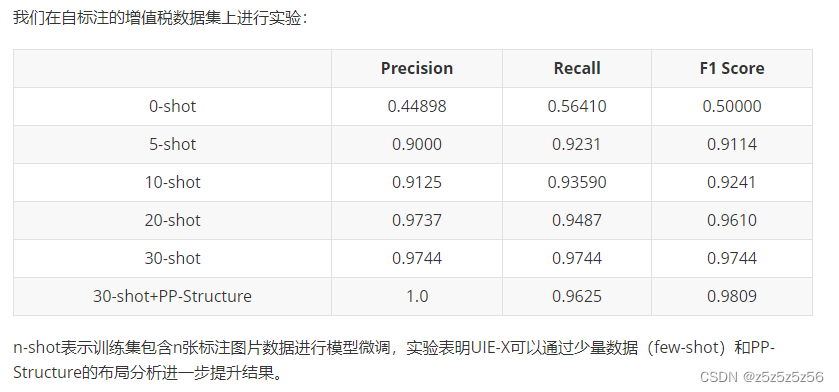
- 微调模型对比
- step2、服务化部署
- step3、提升推理速度
- 模型量化
- 更换模型
- fast-tokenizer
- 提高batch_size(没用)
大模型时代来咯!讲究的就是一个通用!
本文记录我使用PaddleNLP中UIE做增值税发票信息提取的过程,同理适用于任何图片信息提取
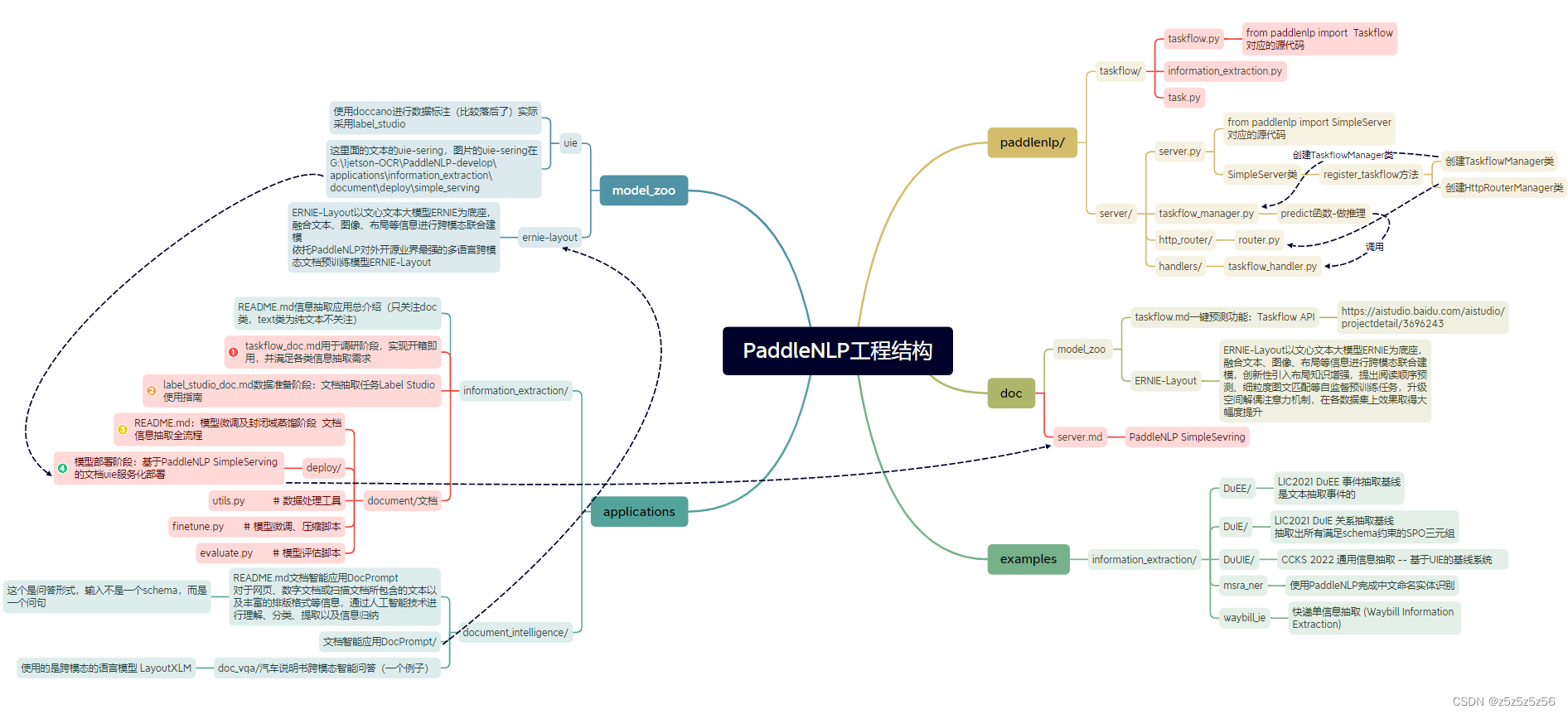
首先上个图镇场子,里面红底的就是做图片信息提取,所需要重点关注的文件
本文参考
-
项目
PaddleNLP:https://github.com/PaddlePaddle/PaddleNLP
其中UIE部分:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
发票信息提取使用的UIEX:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction/document -
教程/文档
跨模态文档通用信息抽取模型UIE-X来了
uie的简单介绍b站视频【AI快车道|通用信息抽取技术与产业应用实战】 https://www.bilibili.com/video/BV1Q34y1E7SW/?share_source=copy_web&vd_source=679c63061dfbdf7484b5a4a666d4b9e1
AI快车道PaddleNLP系列直播课https://aistudio.baidu.com/aistudio/education/group/info/24902
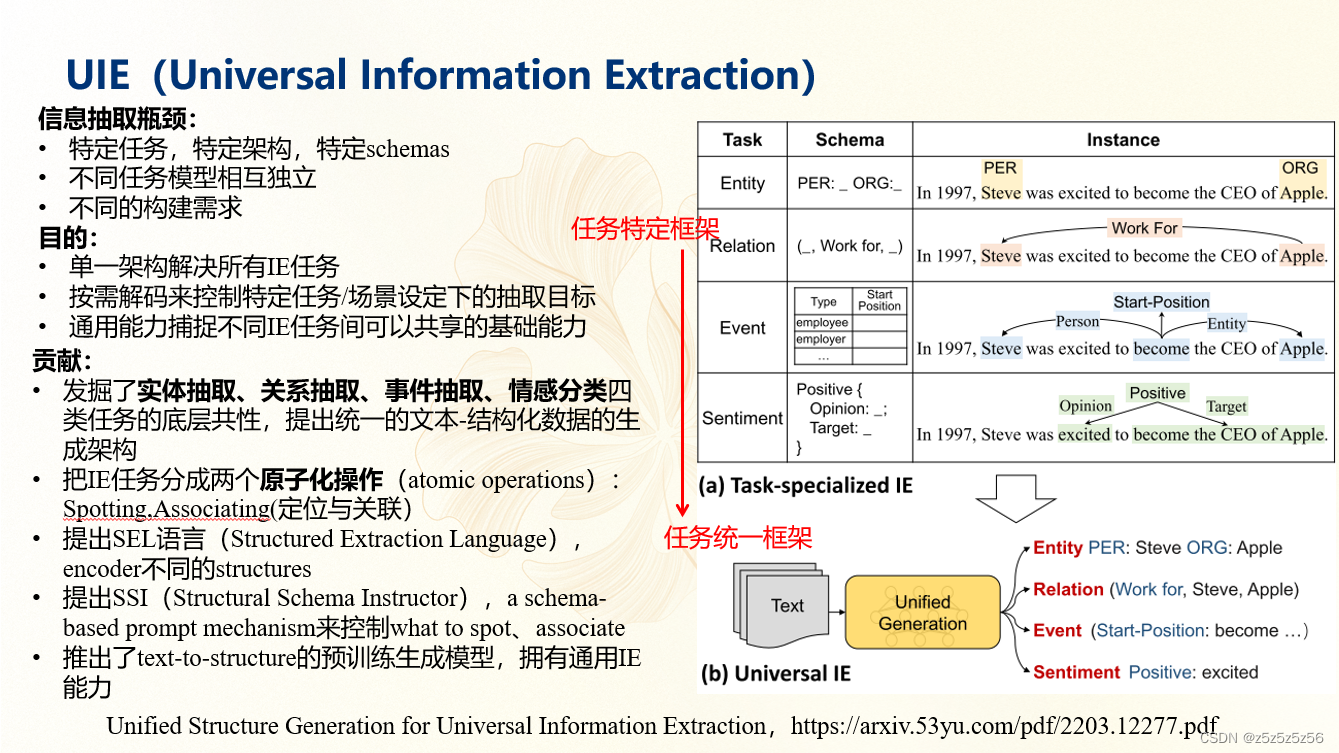
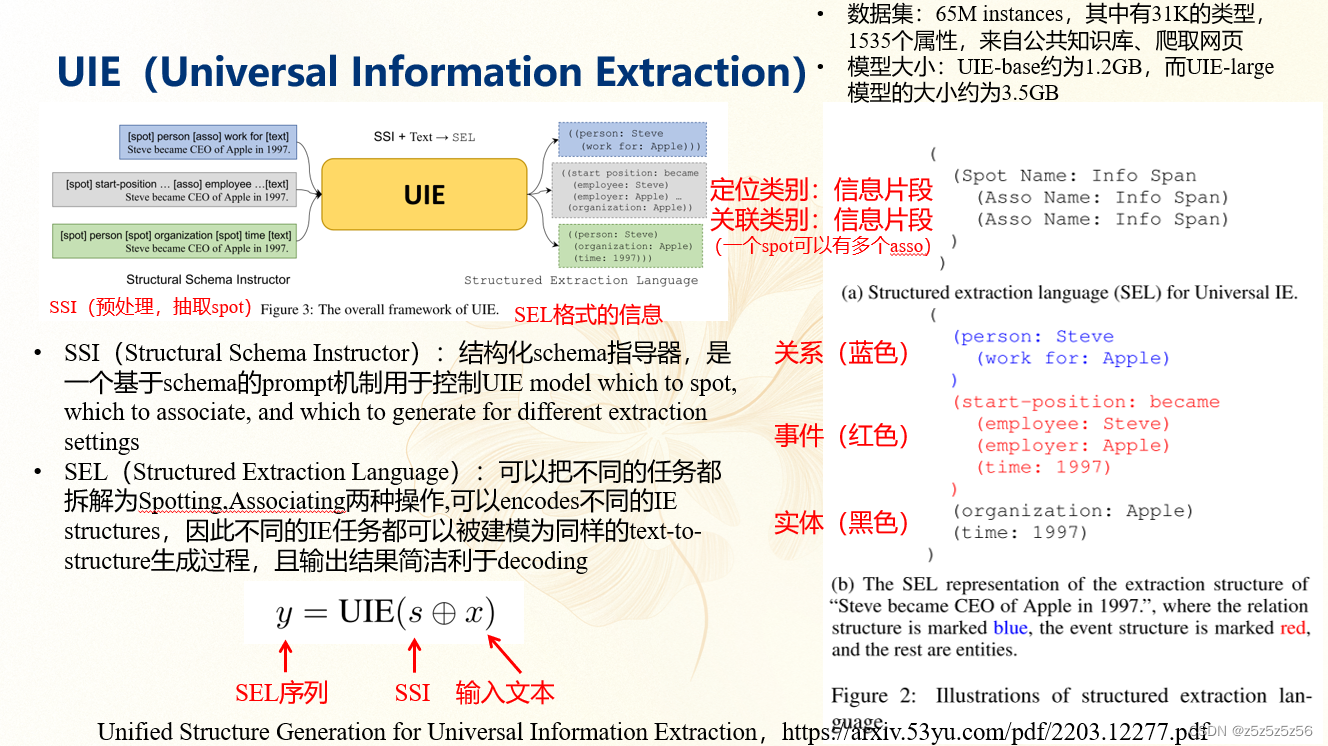
UIE(Universal Information Extraction)
UIE理论部分
-
UIE原始论文
论文阅读笔记
-
Paddle-UIE-X
UIE(Universal Information Extraction):Yaojie Lu等人在ACL-2022中提出了通用信息抽取统一框架UIE。该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。为了方便大家使用UIE的强大能力,PaddleNLP借鉴该论文的方法,基于ERNIE 3.0知识增强预训练模型,训练并开源了首个中文通用信息抽取模型UIE。该模型可以支持不限定行业领域和抽取目标的关键信息抽取,实现零样本快速冷启动,并具备优秀的小样本微调能力,快速适配特定的抽取目标。
来源:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
官方大佬对UIEX的解释:https://zhuanlan.zhihu.com/p/592422623
paddle基于论文中的UIE做了修改,论文中的UIE是对text文本字段进行实体抽取、关系抽取、事件抽取、情感分析四种任务处理的,Paddle全新升级UIE-X,除已有纯文本抽取的全部功能外,新增文档抽取能力,具体来说paddle就是在前面增加了paddleOCR的det和rec功能,图片转化为识别出来的文本,再送入进行UIE,再结合布局分析等功能做了优化。UIE-X把这个功能端到端打通了。使用起来非常方便
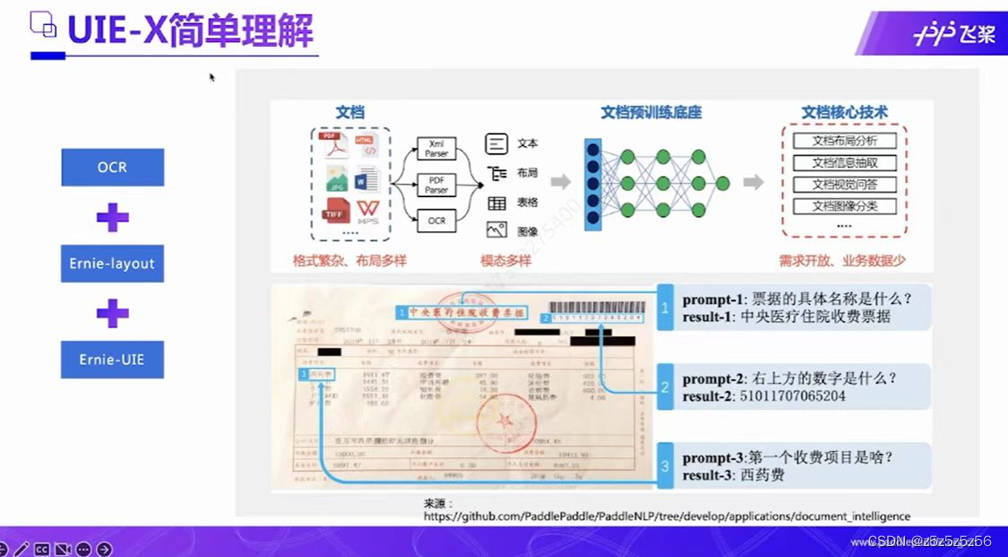
step0、UIEX原始模型使用
网页体验
🤗Huggingface hub 正式兼容 PaddleNLP 预训练模型,支持 PaddleNLP Model 和 Tokenizer 直接从 🤗Huggingface hub 下载和上传,欢迎大家在 🤗Huggingface hub 体验 PaddleNLP 预训练模型效果
网页直接体验UIEX原始模型:https://huggingface.co/spaces/PaddlePaddle/UIE-X
输入schema,点击submit即可
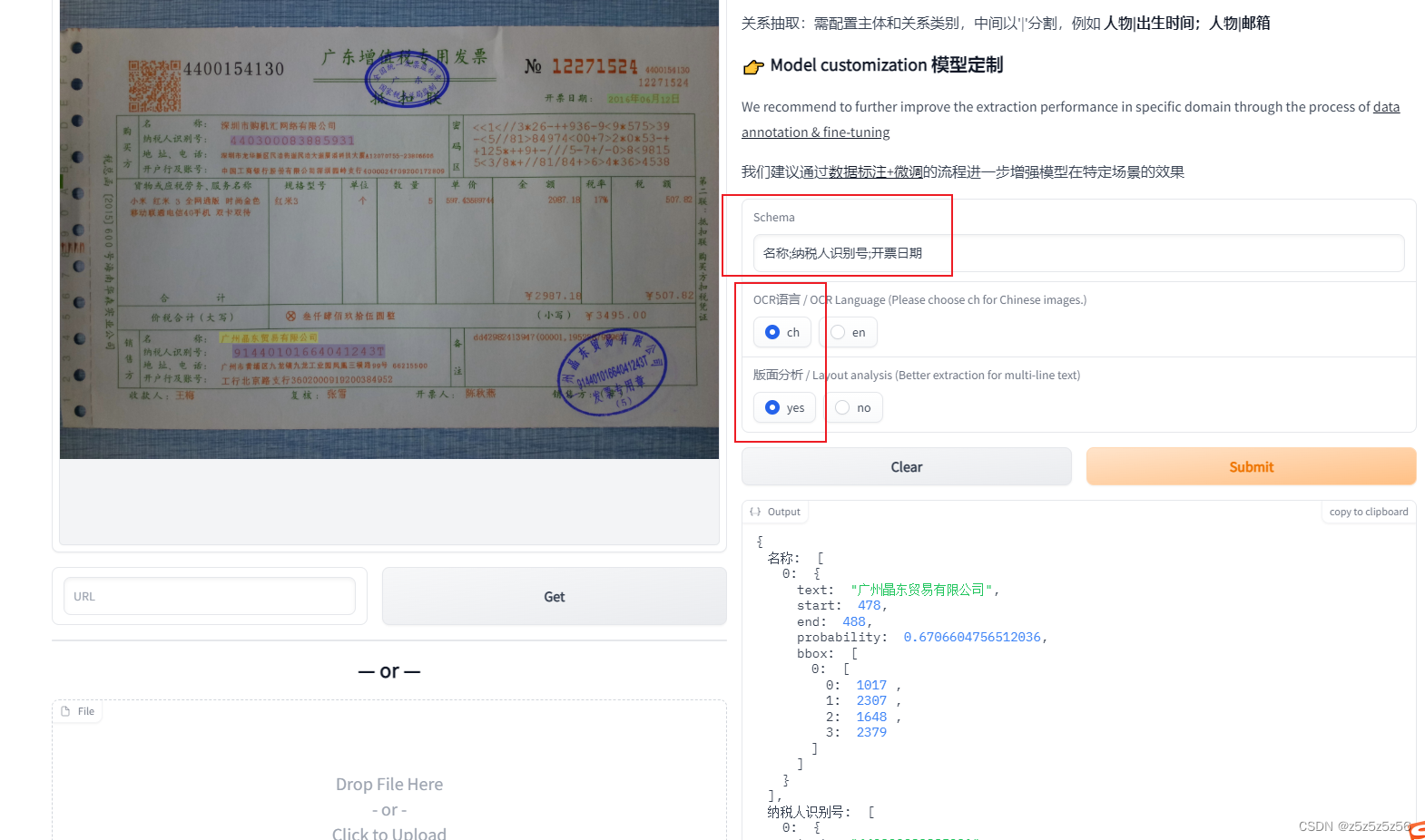
本机安装使用
环境安装
基本都是使用一键预测功能:Taskflow API去做使用的,安装包,引入库,然后就三行代码,就可以使用了,封装得很完善
安装
环境依赖
- python >= 3.7
- paddlepaddle >= 2.3
pip安装pip install --upgrade paddlenlp或者可通过以下命令安装最新 develop 分支代码:
pip install --pre --upgrade paddlenlp -f https://www.paddlepaddle.org.cn/whl/paddlenlp.html更多关于PaddlePaddle和PaddleNLP安装的详细教程请查看get_started。
来源:https://github.com/PaddlePaddle/PaddleNLP#readme
使用docker的环境安装
对于环境依赖,可以直接pull预安装 PaddlePaddle 的镜像,再在docker里面安装paddlenlp
nvidia-docker pull registry.baidubce.com/paddlepaddle/paddle:2.4.2-gpu-cuda11.2-cudnn8.2-trt8.0
#以端口号6666对外提供SSH,挂载物理机data文件夹到虚拟机hdd文件夹
nvidia-docker run --name paddle_docker -it -v /data/:/hdd -p 6666:22 registry.baidubce.com/paddlepaddle/paddle:2.4.2-gpu-cuda11.2-cudnn8.2-trt8.0 /bin/bash
apt-get update
#docker自启动
docker update --restart=always paddle_docker快速开始
这里以信息抽取-命名实体识别任务,UIE模型为例,来说明如何快速使用PaddleNLP:
- text类信息提取
PaddleNLP提供一键预测功能,无需训练,直接输入数据即可开放域抽取结果:
>>> from pprint import pprint
>>> from paddlenlp import Taskflow>>> schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
>>> ie = Taskflow('information_extraction', schema=schema)
>>> pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!"))
[{'时间': [{'end': 6,'probability': 0.9857378532924486,'start': 0,'text': '2月8日上午'}],'赛事名称': [{'end': 23,'probability': 0.8503089953268272,'start': 6,'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],'选手': [{'end': 31,'probability': 0.8981548639781138,'start': 28,'text': '谷爱凌'}]}]
- 图片类信息提取(使用uie-x)
import paddlenlp, paddleocr
print(paddlenlp.__version__)
print(paddleocr.__version__)from pprint import pprint
from paddlenlp import Taskflow
schema = ["购买方名称", "购买方纳税人识别号", "货物", "规格型号", "税率", "标题", "发票号码", "销售方名称", "销售方识别号", "销售方开户行账号"]
ie = Taskflow("information_extraction", schema=schema, model="uie-x-base")
pprint(ie({"doc": "./fp1.jpg"}))
直接在/root/目录下运行,第一次运行会在根目录生成.paddlenlp和.paddleocr的隐藏文件夹,用于存储自动下载的uie和ocr模型,然后开始推理
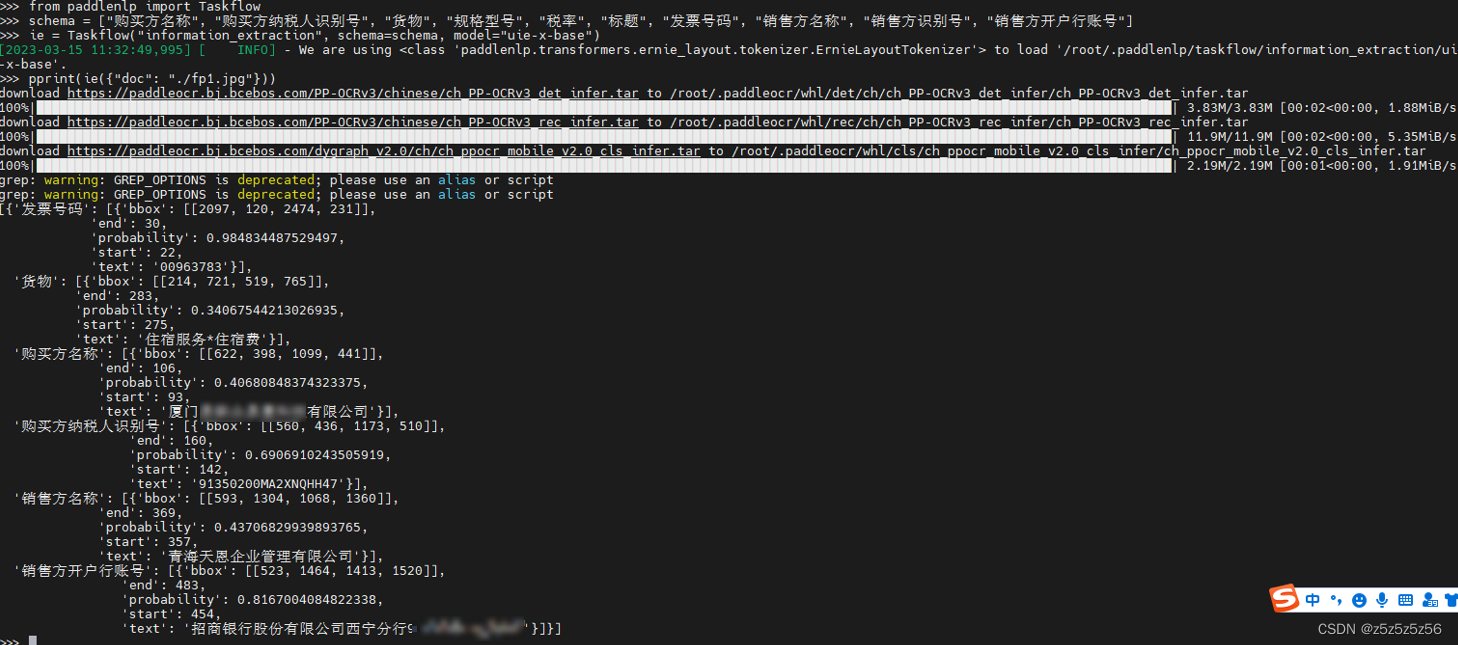
有一些字段没有显示的,应该就是没有找到,下面只显示的是找到的,可是但凡显示出来的准确度都很高,可以说效果真的很牛,就是密码区一直不认
大概可以得出的结论是:只要图像上靠近且有明显键值对的,都可以识别,只有那种键值对不明显,或者只有值没有键的信息,才会难以提取,才会需要微调。
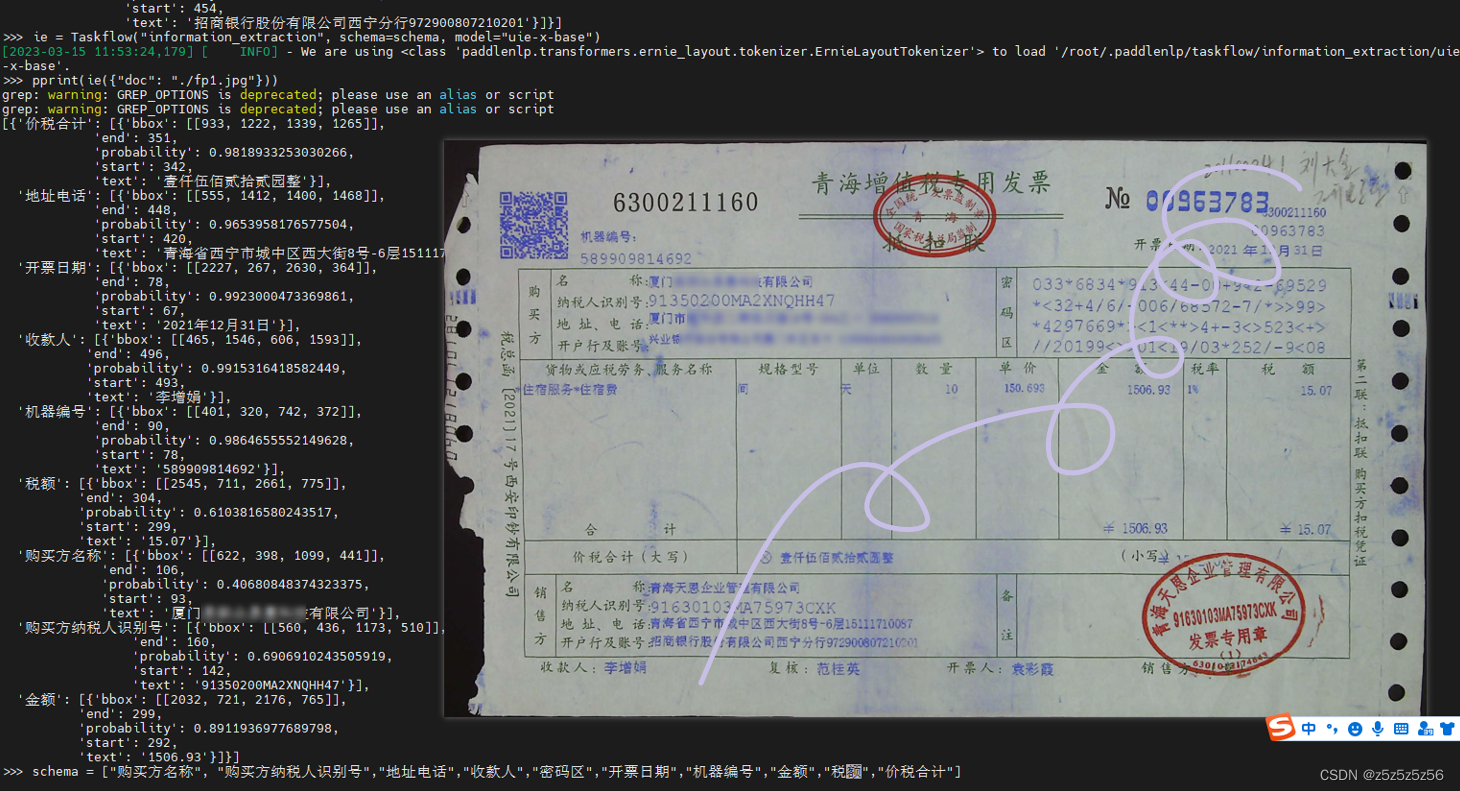
测试到这里我就觉得这个方案是可行的了,所以打算基于UIEX做小样本学习,实际上除了发票,对于任何图片信息提取场景,根据它的介绍少量学习都能带来大幅提升,经过我的测试确实如此
step1、UIEX模型微调(小样本学习)
按https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction/document进行模型微调,教程写的挺清楚了,我这里说一些其他的注意点
数据标注(label_studio)
这是本地启动服务网页使用的,为了方便数据获取,就在win装,因为我的基本环境烂了,会有一些奇怪报错:django.db.utils.OperationalError: no such function: JSON_VALID所以我在anaconda里面新建py39环境,可以正常运行
pip install label-studio#我安装的是1.7.2,教程里的1.6.0有bug
pip install -U label-studio
label-studio start
-
这个地方,一定得是image或者text,不能是ocr什么的,在后面数据处理转换json文件为paddle数据集的时候,只认image/test,如果换成其他的会不识别报错
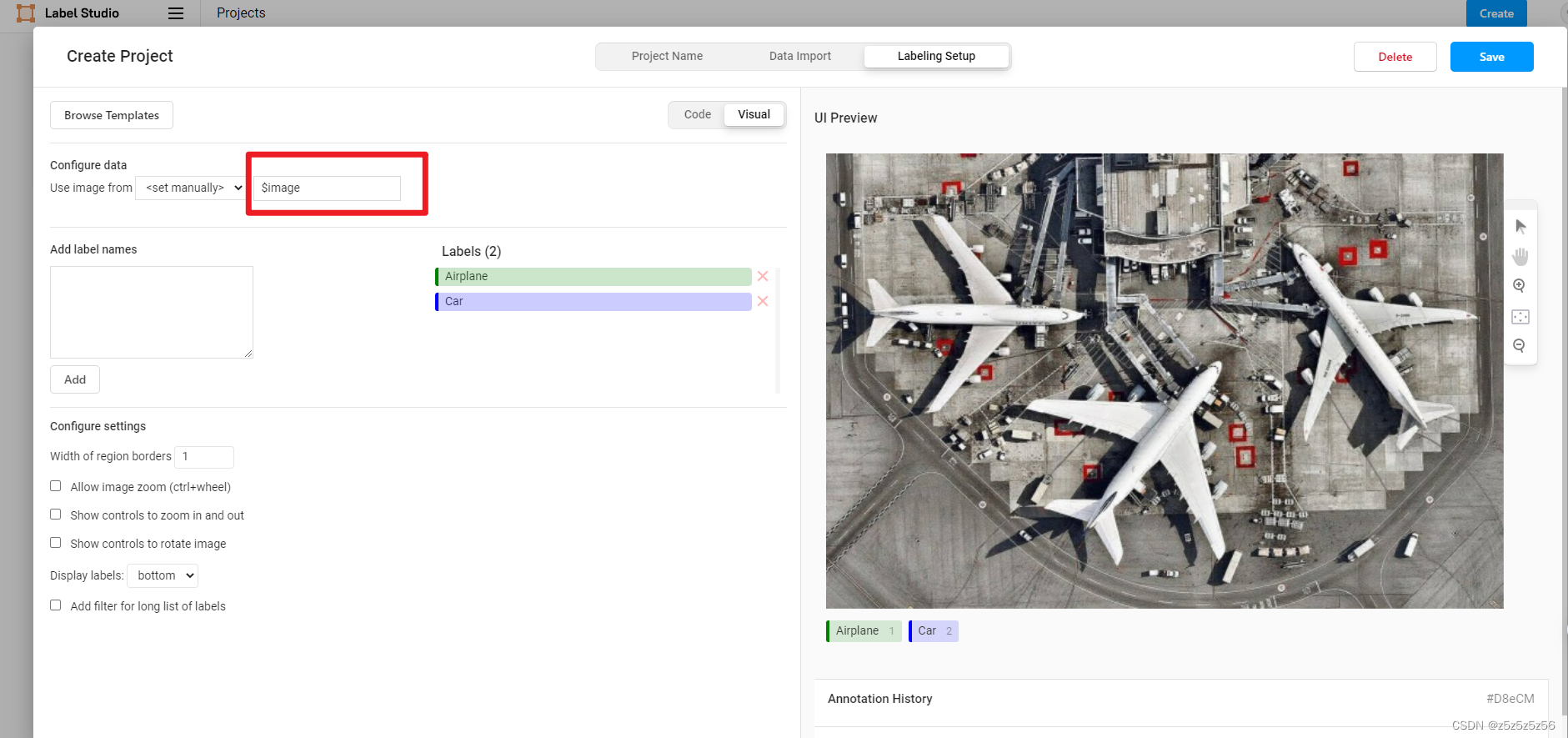
-
标注的时候,框要偏大一点,不能恰恰好贴着文字,不然会导致提取信息的时候漏掉前面几个字符
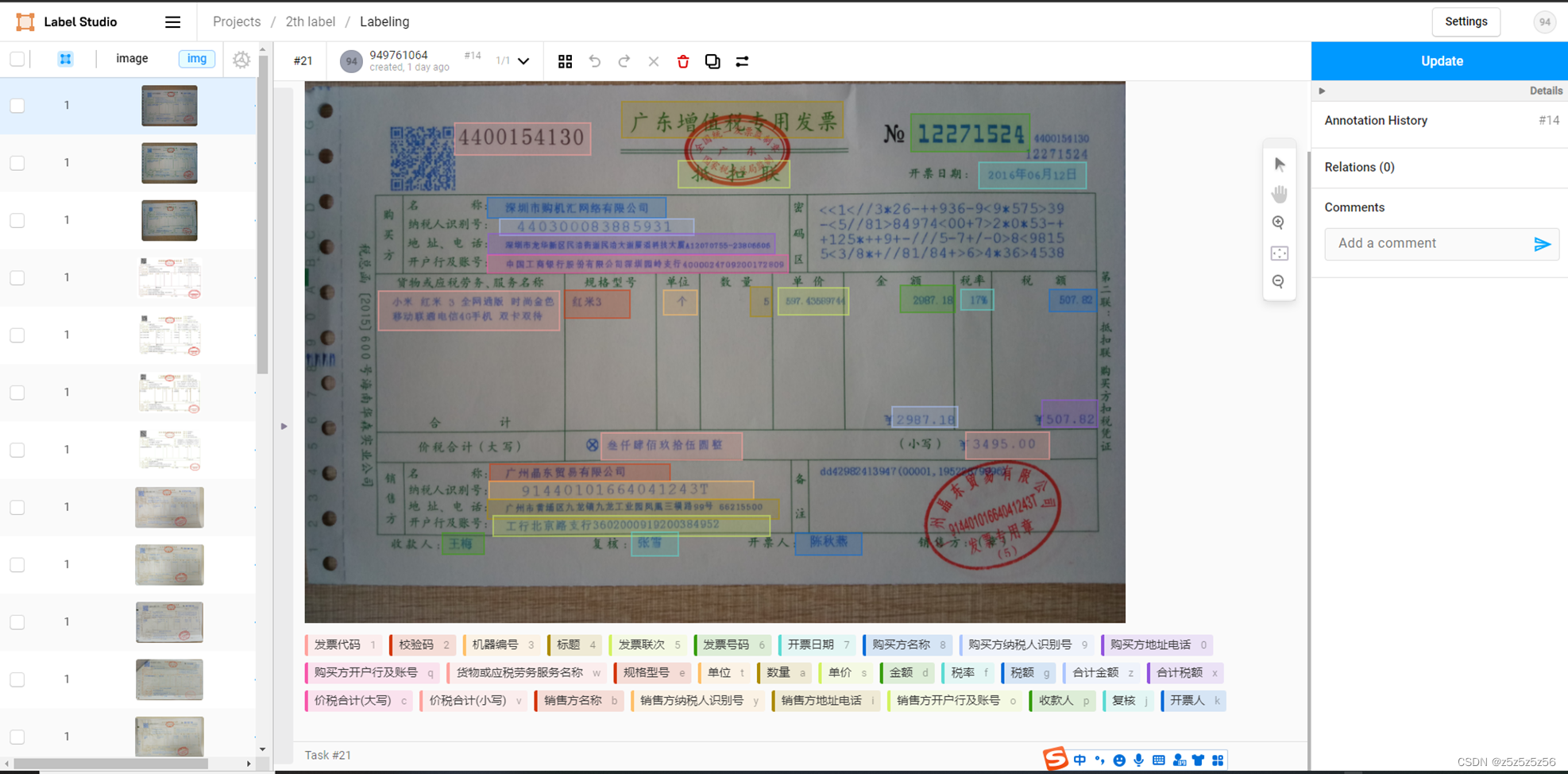
直到后来我label多了我才意识到,原始模型的可视化就是在教我怎么label最完美:都要向前框一点,包括冒号
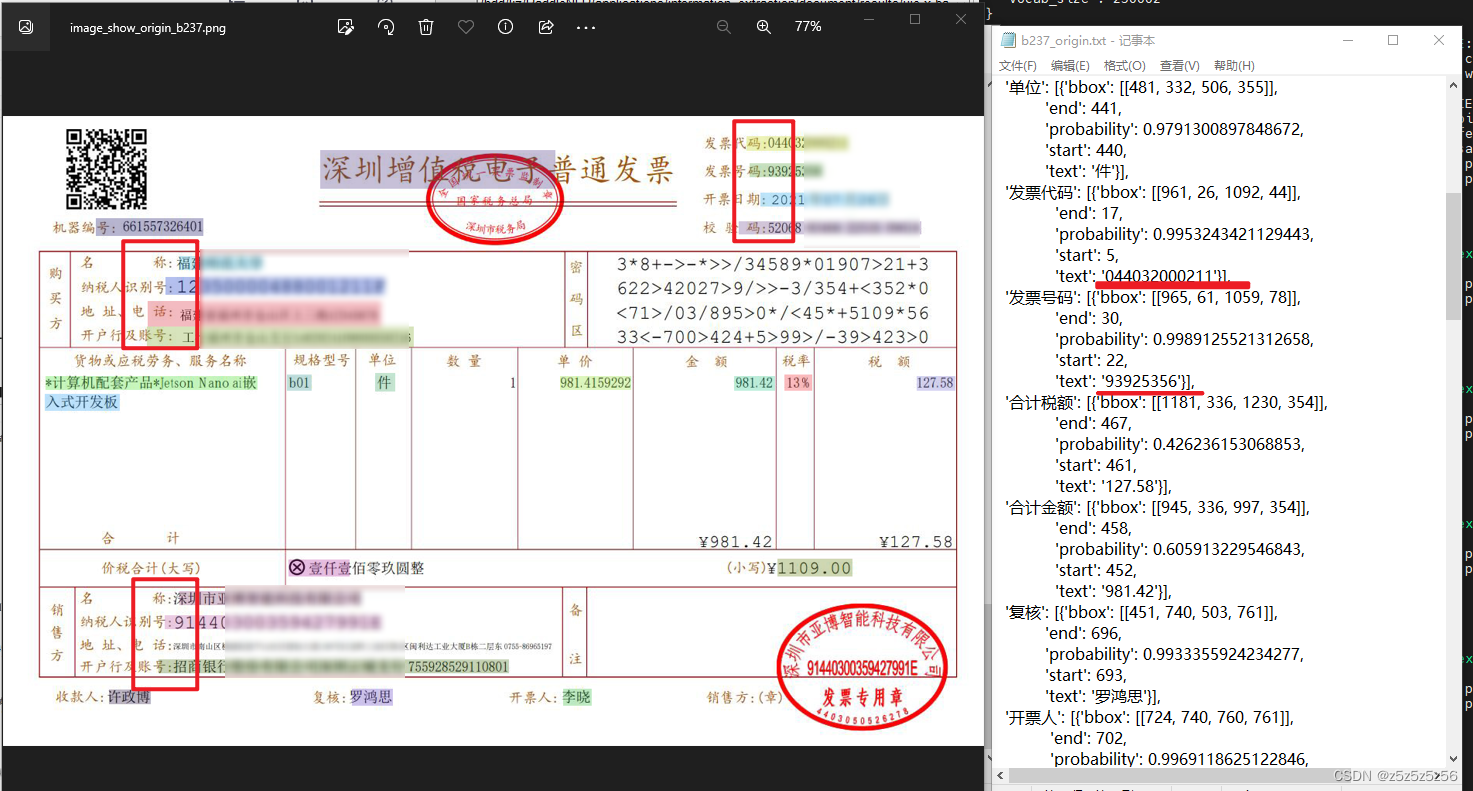
导出数据转换
ext:抽取式任务,实体收取和关系抽取都是抽取
python label_studio.py --label_studio_file ./document/data/label_studio.json --save_dir ./document/data --splits 0.8 0.1 0.1 --task_type ext
微调训练:
我在3090Ti上训练的速度基本是数据集增加一张图片,训练耗时增加一分钟,我标10张图片用了9分钟,标40张图片用了50分钟
模型大小:“uie-x-base“ 1.05G,训练过程占用显存情况:20G/24G
python finetune.py --device gpu --logging_steps 5 --save_steps 25 --eval_steps 25 --seed 42 --model_name_or_path uie-x-base --output_dir ./checkpoint/model_best --train_path data/train.txt --dev_path data/dev.txt --max_seq_len 512 --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --num_train_epochs 10 --learning_rate 1e-5 --do_train --do_eval --do_export --export_model_dir ./checkpoint/model_best --overwrite_output_dir --disable_tqdm True --metric_for_best_model eval_f1 --load_best_model_at_end True --save_total_limit 1
评估:
python evaluate.py --device "gpu" --model_path ./checkpoint/model_best --test_path ./data/dev.txt --output_dir ./checkpoint/model_best --label_names 'start_positions' 'end_positions' --max_seq_len 512 --per_device_eval_batch_size 16 --debug True
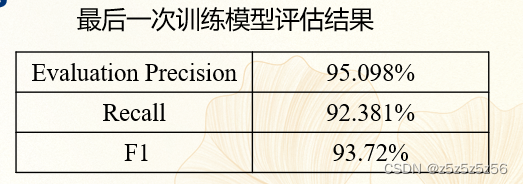
定制模型一键预测
我写了一个脚本,来同时执行原始模型和微调模型在同一张图片上的表现,同时可视化和输出识别结果到txt,以便对比:
import pprint
from paddlenlp import Taskflow
from paddlenlp.utils.doc_parser import DocParser
import os
import sys
import time#输入图片名参数
doc_path = str(sys.argv[1])
print(doc_path)
#发票联次,包括发票联,抵扣联,记账联# schema = ['发票代码', '校验码', '标题', '发票联次', '发票号码', '开票日期', '购买方名称', '购买方纳税人识别号', '购买方地址电话', '购买方开户行及账号', '密码区', '货物或应税劳务服务名称', '规格型号', '单位', '数量', '单价', '金额', '税率', '税额', '合计金额', '合计税额', '价税合计(大写)', '价税合计(小写)', '销售方名称', '销售方纳税人识别号', '销售方地址电话', '销售方开户行及账号', '收款人', '复核', '开票人', '备注', '销售方(章)', '机器编号']
schema = ['发票代码', '校验码', '标题', '发票联次', '发票号码', '开票日期', '购买方名称', '购买方纳税人识别号', '购买方地址电话', '购买方开户行及账号', '货物或应税劳务服务名称', '规格型号', '单位', '数量', '单价', '金额', '税率', '税额', '合计金额', '合计税额', '价税合计(大写)', '价税合计(小写)', '销售方名称', '销售方纳税人识别号', '销售方地址电话', '销售方开户行及账号', '收款人', '复核', '开票人', '机器编号']my_ie = Taskflow("information_extraction", model="uie-x-base", schema=schema, task_path='./checkpoint/model_best',layout_analysis=True)
ie = Taskflow("information_extraction", model="uie-x-base", schema=schema,layout_analysis=True)filename=os.path.basename(doc_path).split('.')[0]start_time=time.time()
my_results = my_ie({"doc": doc_path})
end_time=time.time()
print('self inference time(s):',end_time-start_time)start_time=time.time()
results = ie({"doc": doc_path})
end_time=time.time()
print('origin inference time(s):',end_time-start_time)
# pprint(results)if os.path.exists('./results/'+filename):pass
else:os.mkdir('./results/'+filename)print('mkdir ','./results/'+filename)# 结果可视化
save_path_self='./results/'+filename+'/'+'image_show_self_'+filename+'.png'
DocParser.write_image_with_results(doc_path,result=my_results[0],save_path=save_path_self)save_path_origin='./results/'+filename+'/'+'image_show_origin_'+filename+'.png'
DocParser.write_image_with_results(doc_path,result=results[0],save_path=save_path_origin)#保存结果
with open('./results/'+filename+'/'+filename+'_self.txt','w') as f:f.write(str(str(pprint.pformat(my_results))))f.close()
with open('./results/'+filename+'/'+filename+'_origin.txt','w') as f:f.write(str(str(pprint.pformat(results))))f.close()print('finished')
推理就是
λ 8be5100f3bf1 /hdd/PaddleNLP/applications/information_extraction/document python testuie_self.py data/testimages/b78.jpg
微调模型对比
总体来说微调模型相比原始模型提升很大,有学习到标记的信息,并且可以区分购买方和销售方

左边一列是微调后的,右边的原始UIE-X-base

但也有问题:比如会认密码区但不跨行,只有第一行(还不如不要),对于密码区,盖章识别,二维码识别,我就去掉了,不设schema,这些需要额外优化
我在3090Ti上推理一张的时间是5s左右,说实话还是挺慢的,后面再补充提升推理速度的问题
step2、服务化部署
这个部分可以用https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction/document/deploy/simple_serving
结合PaddleNLP-develop\docs\server.md进行部署,教程讲的很清楚了
或者使用百度新出的专门用来部署的工具FastDeploy:https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/vision/ocr/PP-OCR/serving
client和server的简单关系:

我就讲一些坑:
作为服务器端的环境,如果是docker,要以--net=host进行创建,例如我之前使用的
nvidia-docker run --name paddle_docker -it -v /data/:/hdd -p 6666:22 registry.baidubce.com/paddlepaddle/paddle:2.4.2-gpu-cuda11.2-cudnn8.2-trt8.0 /bin/bash
是默认–net=bridge,以桥接形式对外提供,不是–net=host,所以无法对外提供服务化部署
应该:
nvidia-docker run --name paddle_serving_docker -it -v /data/:/hdd --net=host registry.baidubce.com/paddlepaddle/paddle:2.4.2-gpu-cuda11.2-cudnn8.2-trt8.0 /bin/bash
#开启进入
sudo docker start paddle_serving_docker
sudo docker exec -it paddle_serving_docker /bin/bash
#安装基本环境
pip install paddlenlp
python3 -m pip install paddleocr
#Server服务启动
paddlenlp server server:app --workers 1 --host 10.24.83.40 --port 8189step3、提升推理速度
模型量化
可以用PaddleSlim试一下
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression
更换模型
因为其原理是经过OCR将图片转化为text再输入UIE模型,所以实际上其他size的UIE模型也能用,但会损失精度
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
| 模型 | 结构 | 语言 |
|---|---|---|
uie-base (默认) | 12-layers, 768-hidden, 12-heads | 中文 |
uie-base-en | 12-layers, 768-hidden, 12-heads | 英文 |
uie-medical-base | 12-layers, 768-hidden, 12-heads | 中文 |
uie-medium | 6-layers, 768-hidden, 12-heads | 中文 |
uie-mini | 6-layers, 384-hidden, 12-heads | 中文 |
uie-micro | 4-layers, 384-hidden, 12-heads | 中文 |
uie-nano | 4-layers, 312-hidden, 12-heads | 中文 |
uie-m-large | 24-layers, 1024-hidden, 16-heads | 中、英文 |
uie-m-base | 12-layers, 768-hidden, 12-heads | 中、英文 |
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction#readme
| 模型名称 | 使用场景 | 支持任务 |
|---|---|---|
uie-baseuie-mediumuie-miniuie-microuie-nano | 面向纯文本场景的抽取式模型,支持中文 | 具备实体、关系、事件、评论观点等通用信息抽取能力 |
uie-base-en | 面向纯文本场景的抽取式模型,支持英文 | 具备实体、关系、事件、评论观点等通用信息抽取能力 |
uie-m-baseuie-m-large | 面向纯文本场景的抽取式模型,支持中英 | 具备实体、关系、事件、评论观点等通用信息抽取能力 |
uie-x-base | 面向纯文本和文档场景的抽取式模型,支持中英 | 支持纯文本场景的全部功能,还支持文档/图片/表格的端到端信息抽取 |
然而,经过测试uie-x-base (12L768H)本身就大概是基于uie-m-base (12L768H)进行改进的,二者模型大小差不多,但是!uie-m原始模型的推理时间3s左右,几乎减半,但是其效果也非常差!
而除了uie-m之外的其他模型不支持中英双语,就更用不了了
结论:无法更换其他模型做图片推理,其他模型都是text推理用,没有图片布局分析效果很差
fast-tokenizer
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
TaskFlow的一个参数
use_fast: 使用C++实现的高性能分词算子FastTokenizer进行文本预处理加速。需要通过pip install fast-tokenizer-python安装FastTokenizer库后方可使用。默认为False。更多使用说明可参考FastTokenizer文档。
提高batch_size(没用)
Q&A里面的,但是我实测16和256一样都是5s……
end