位图
文章目录
- 位图
- set
- Reset
- Test
- 整体代码
- 位图应用
给定40亿个不重复、没排序的无符号整数,再给一个无符号整数,如何快速判断一个数是否在这40亿个数中???
首先想到的是归并排序+二分查找。排序可以排,但是通过文件指针去查找会很慢。
其次是set和哈希表。set自动可以排序且在红黑树中查找速度也很快。但要把40亿个整数加上红黑树的节点(三叉链外加颜色)放进内存里,内存明显不够,不可取;哈希表同样是把40亿个整数外加节点放进内存里,内存明显不够,也不可取。
那么既然要把40亿个整形放进内存里,判断在或者不在,用1标记在用0标记不在。1个比特位就能满足标记1或0。用直接定址法。1个char类型-1个字节-8个比特位。无符号整数有42亿9千万个,全部用比特位来代表的话就只需要512M。这种方法可行。用char类型来开辟空间,那么第一个char就能存储07,第二个char就能存储815,第三个。。。。。。

set
把要set的值通过/8找到对应的char(小位图),再通过%8找到对应的位置,把该位置标记成1即为该值存在于这堆数中
void Set(size_t x)//把x值对应的标记为置为1{//计算x位于哪一个char上// size_t i = x / 8;size_t i=x >> 3;//相当于x/8//计算x位于哪个bit上size_t j = x % 8;_bit[i] |= (1 << j);}
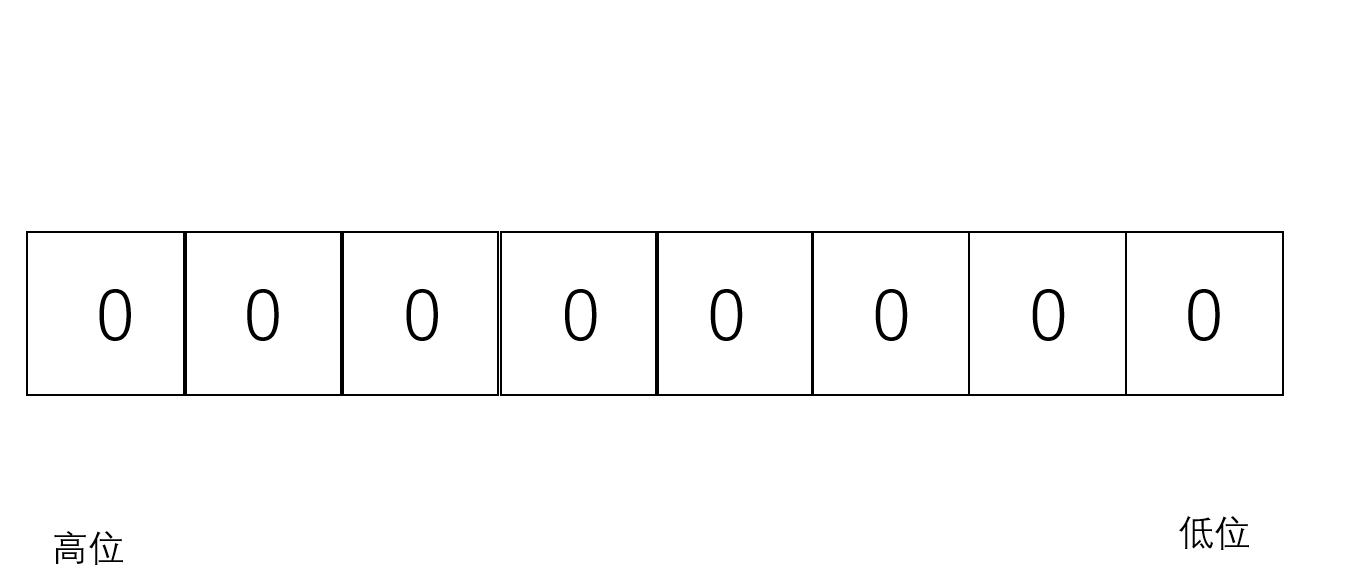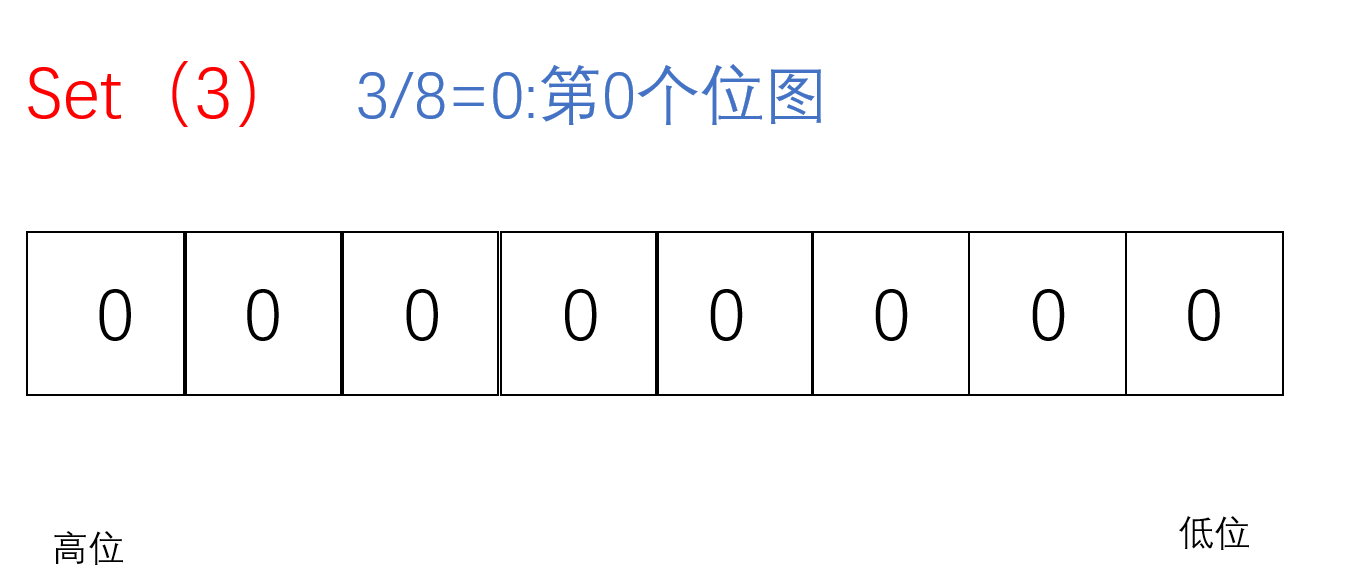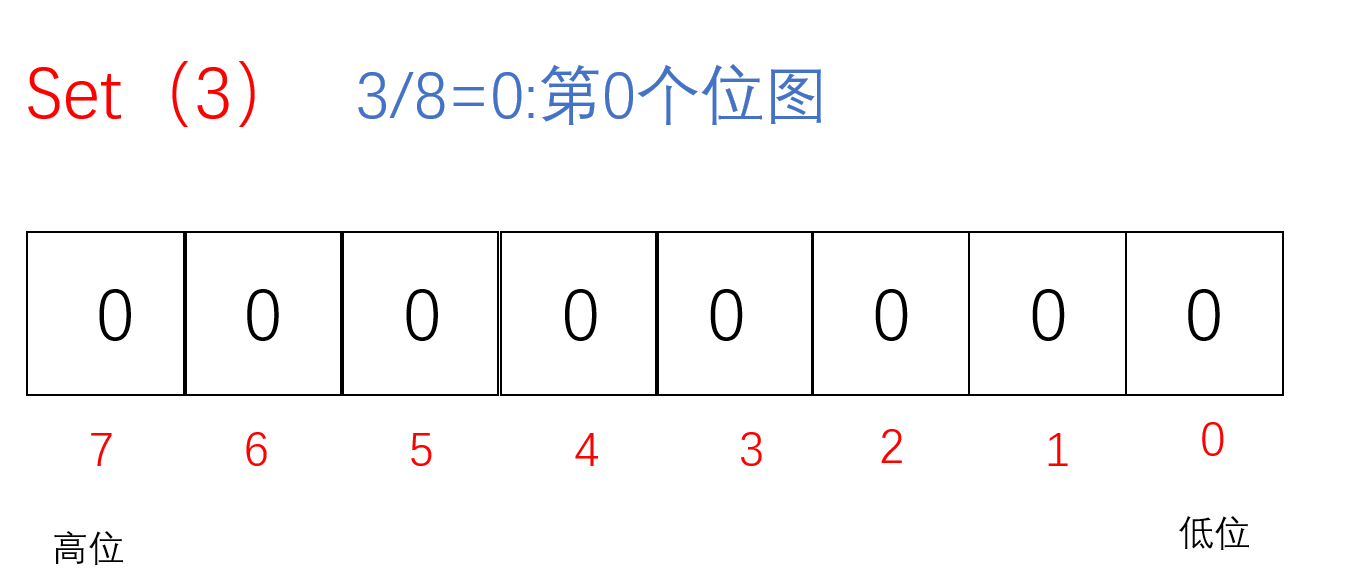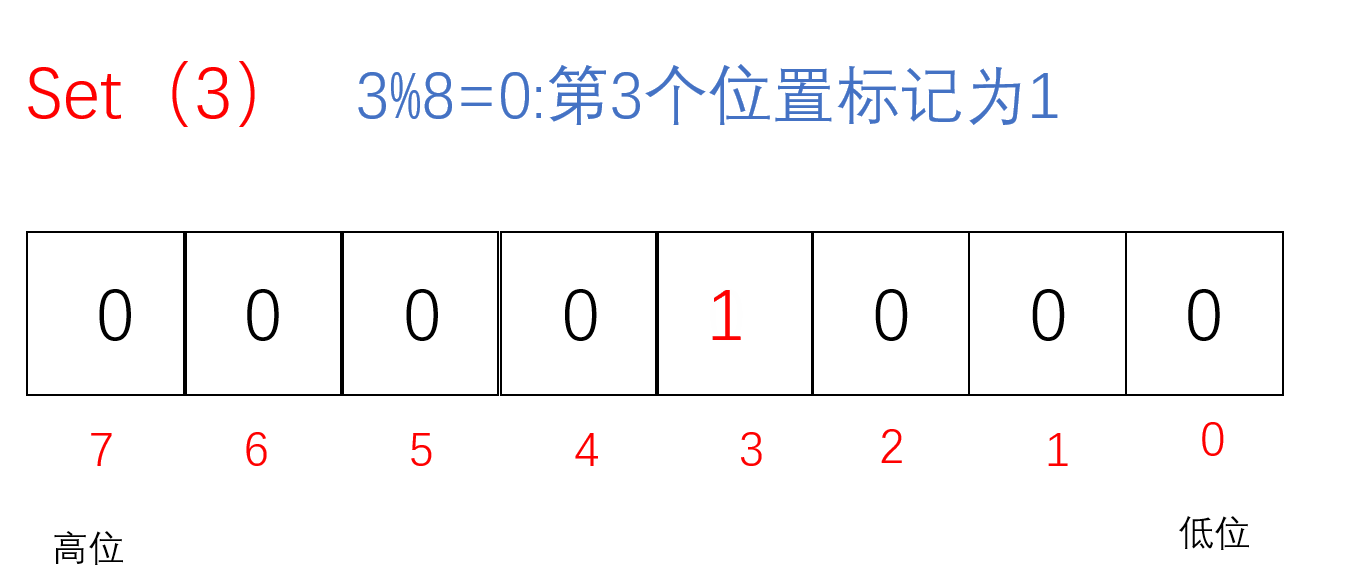
Reset
把要Reset的值通过/8找到对应的char(小位图),再通过%8找到对应的位置,把该位置标记成0即把该值从这堆数中抹去
void ReSet(size_t x)//把x值对应的标记置为0{//计算x位于哪一个char上//size_t i = x / 8;size_t i = x >> 3;//相当于x/8//计算x位于哪个bit上size_t j = x % 8;_bit[i] &= (~(1 << j));}
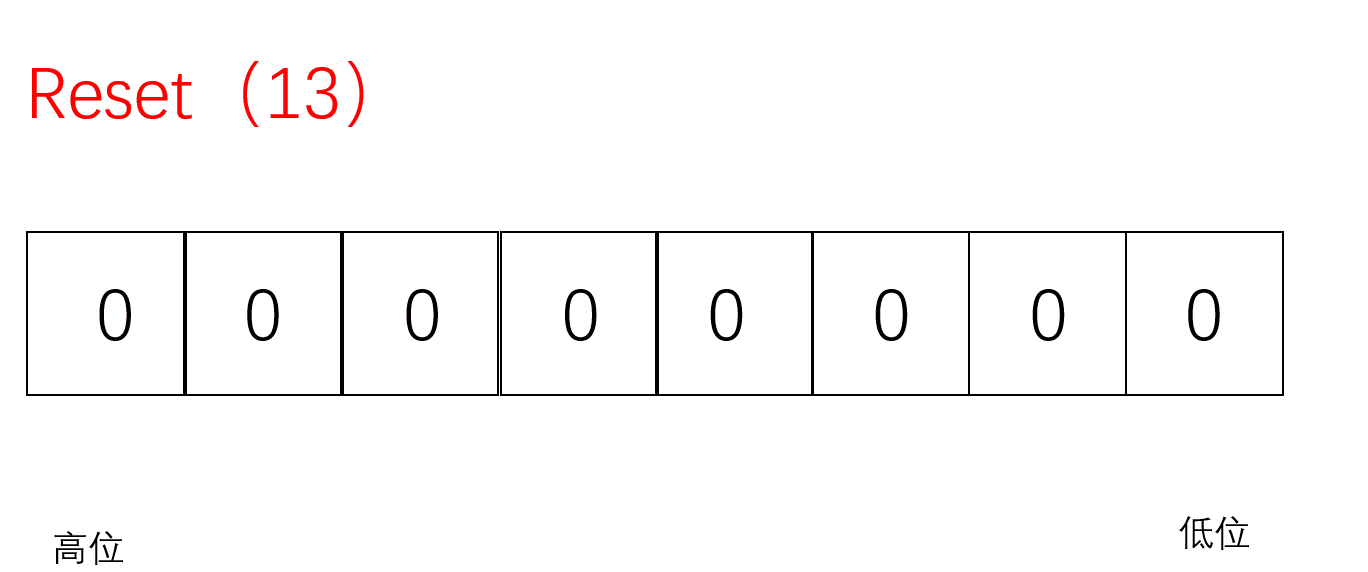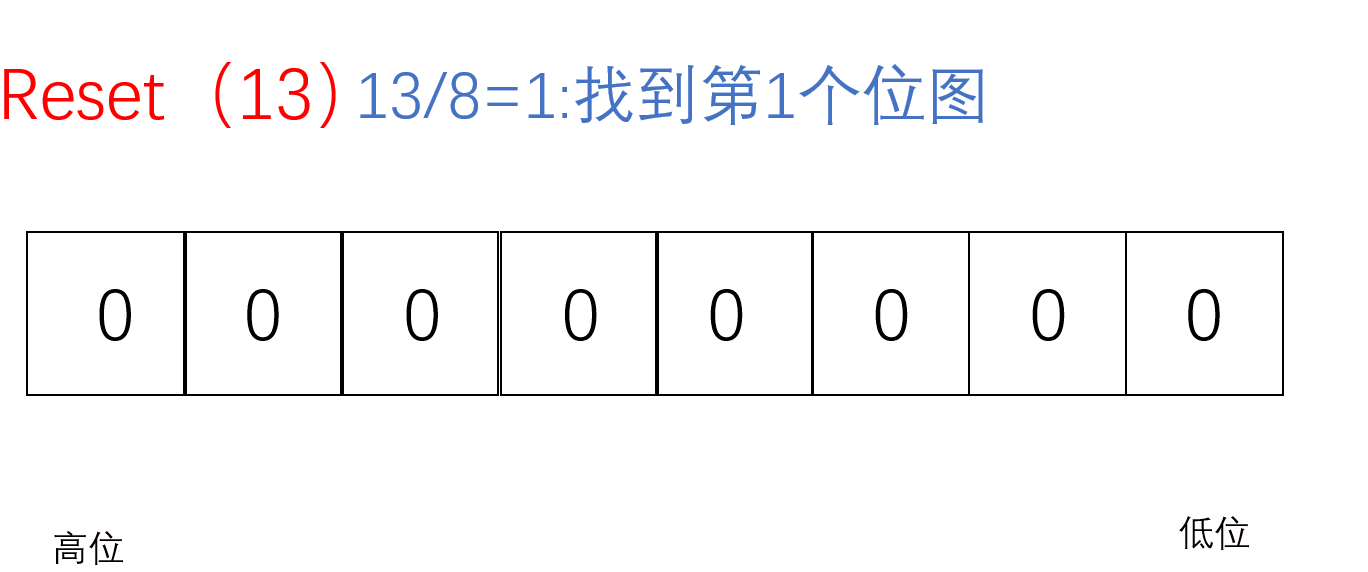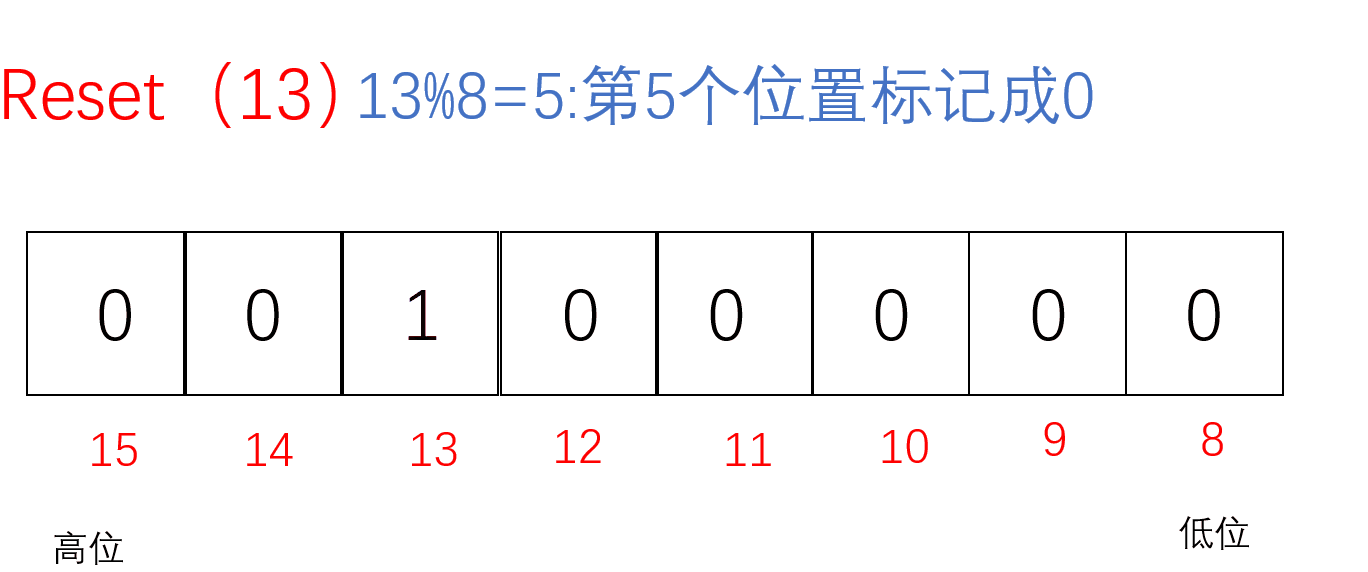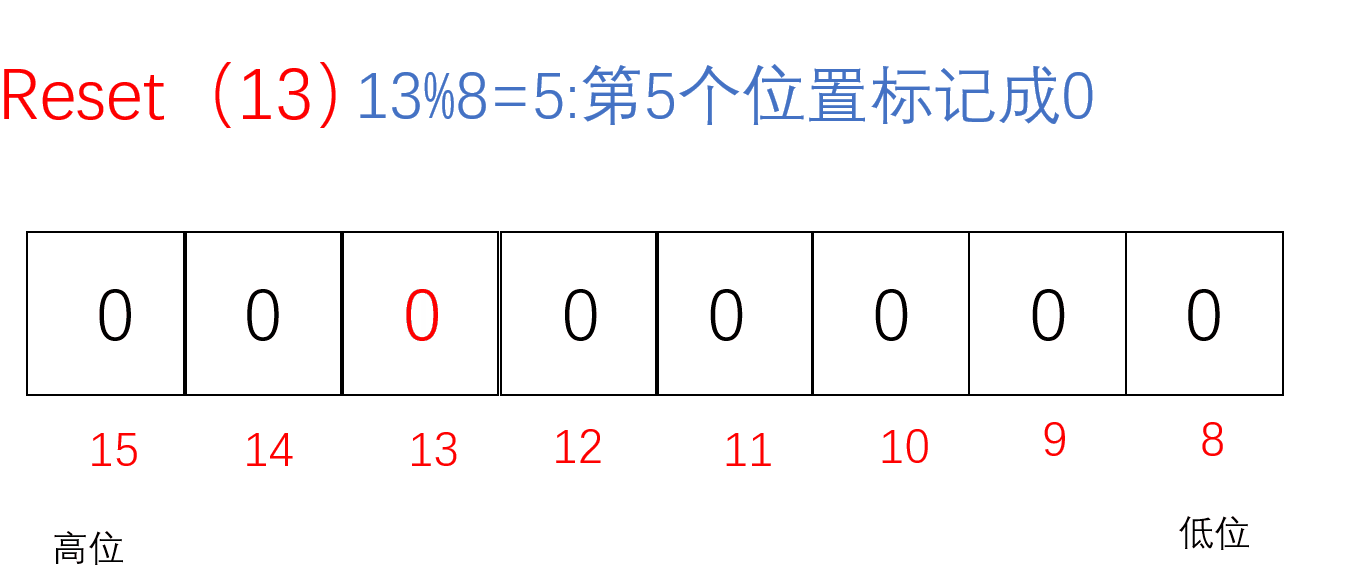
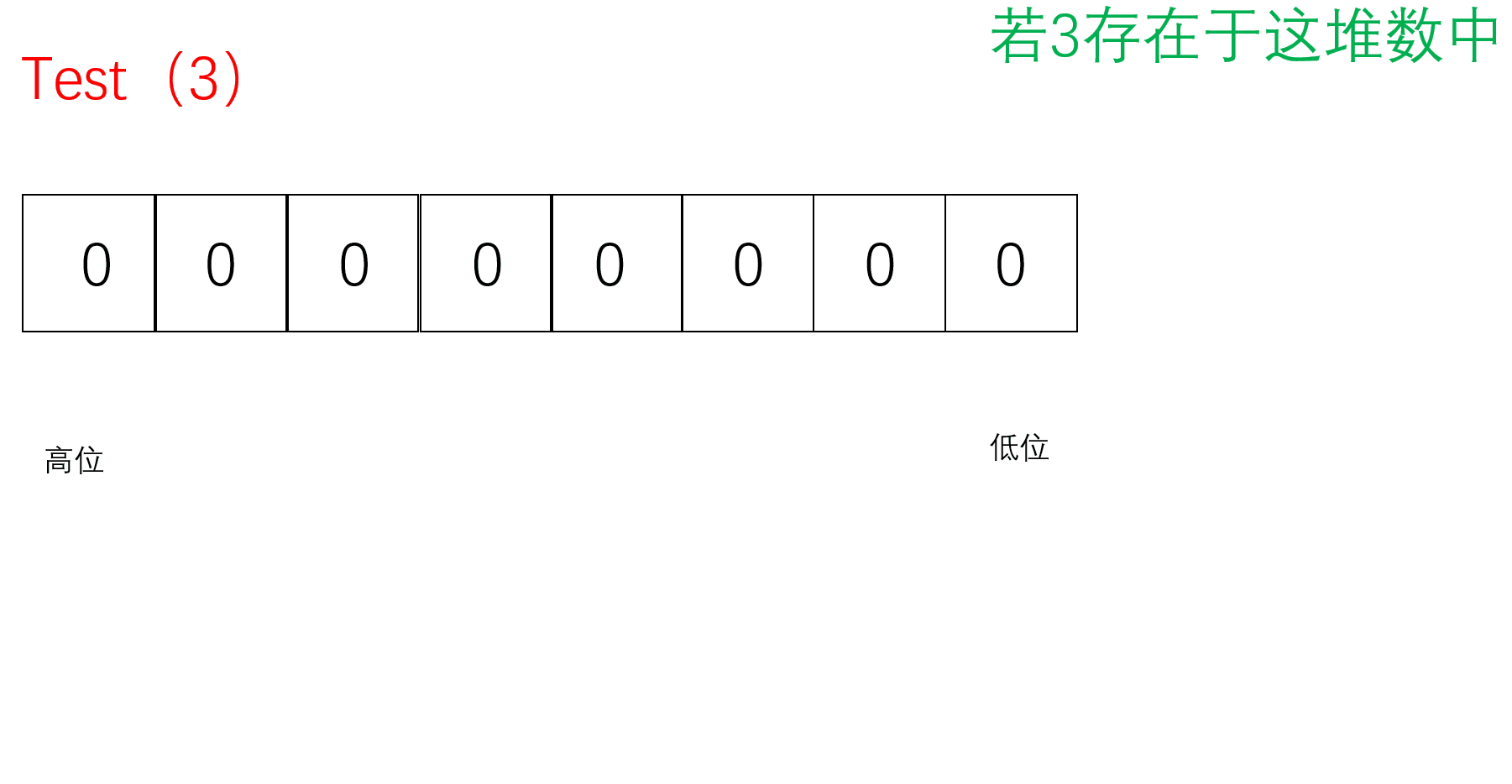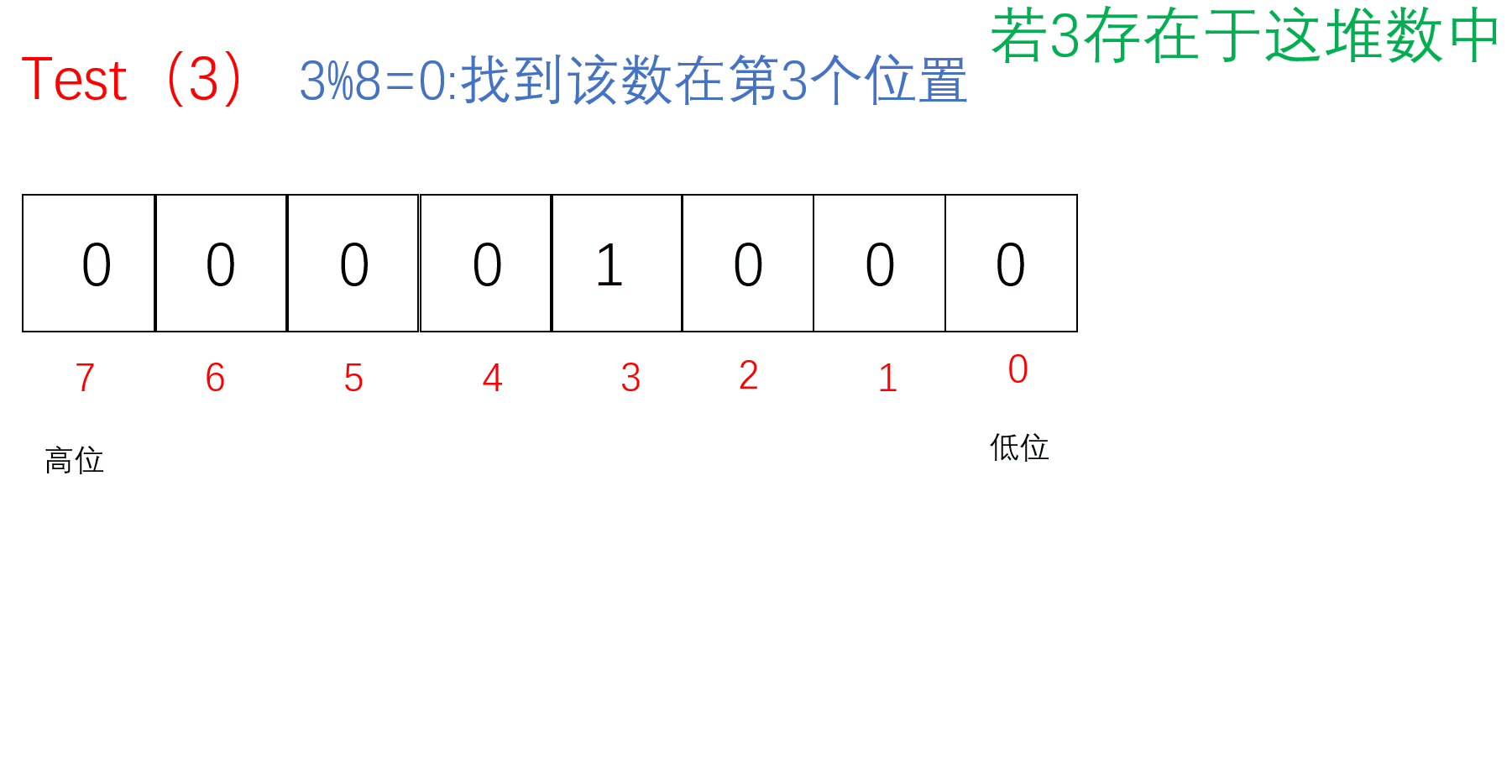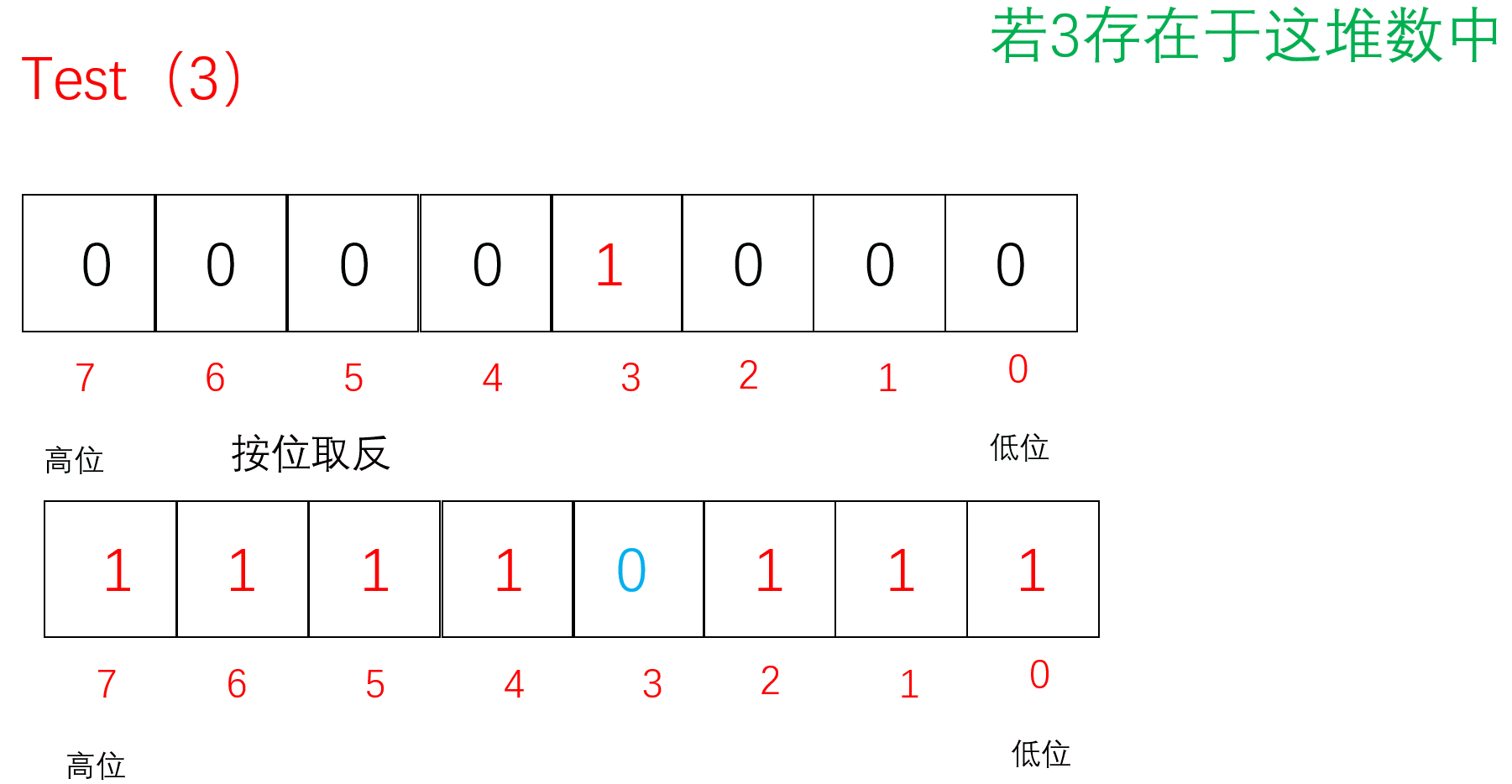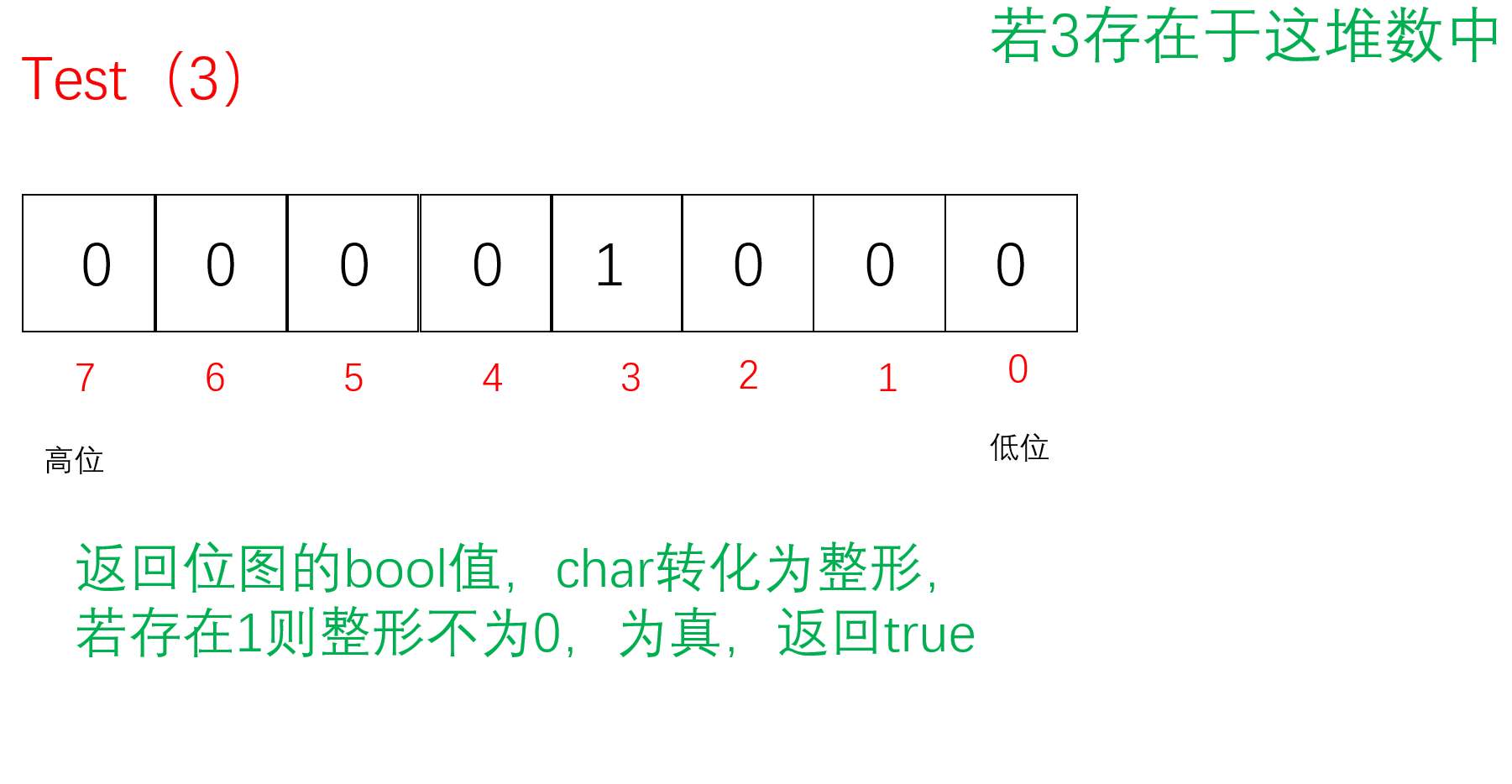
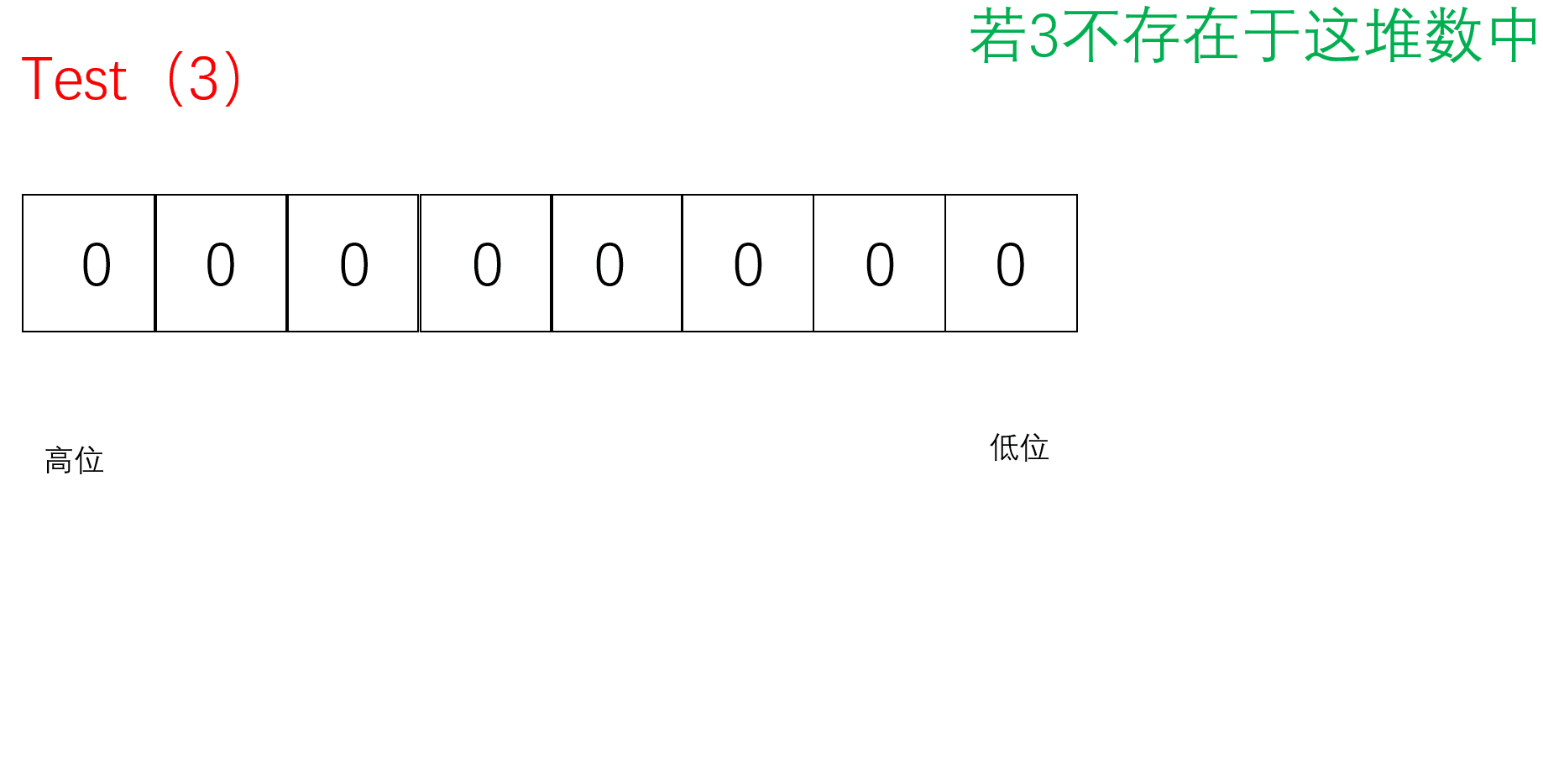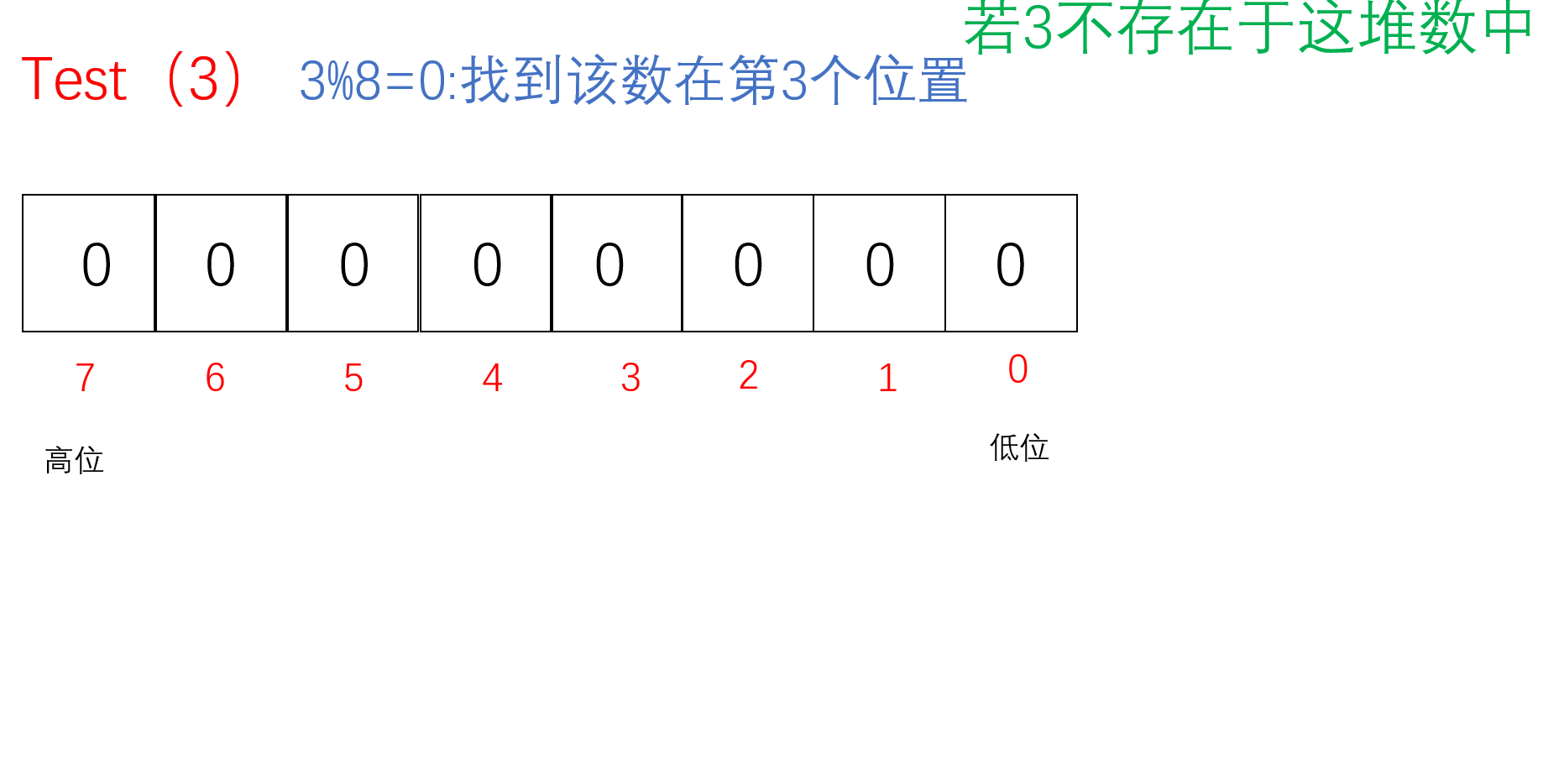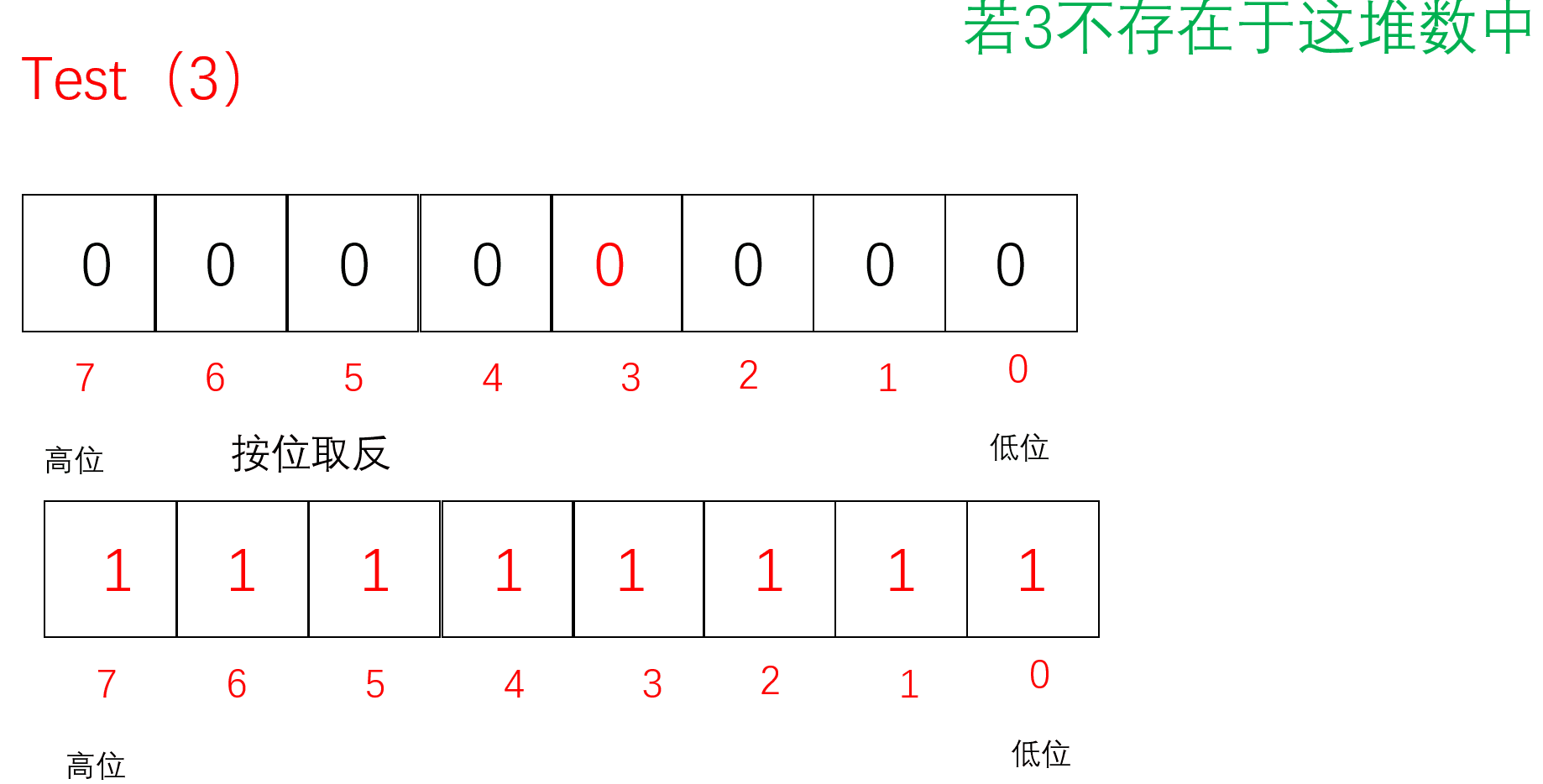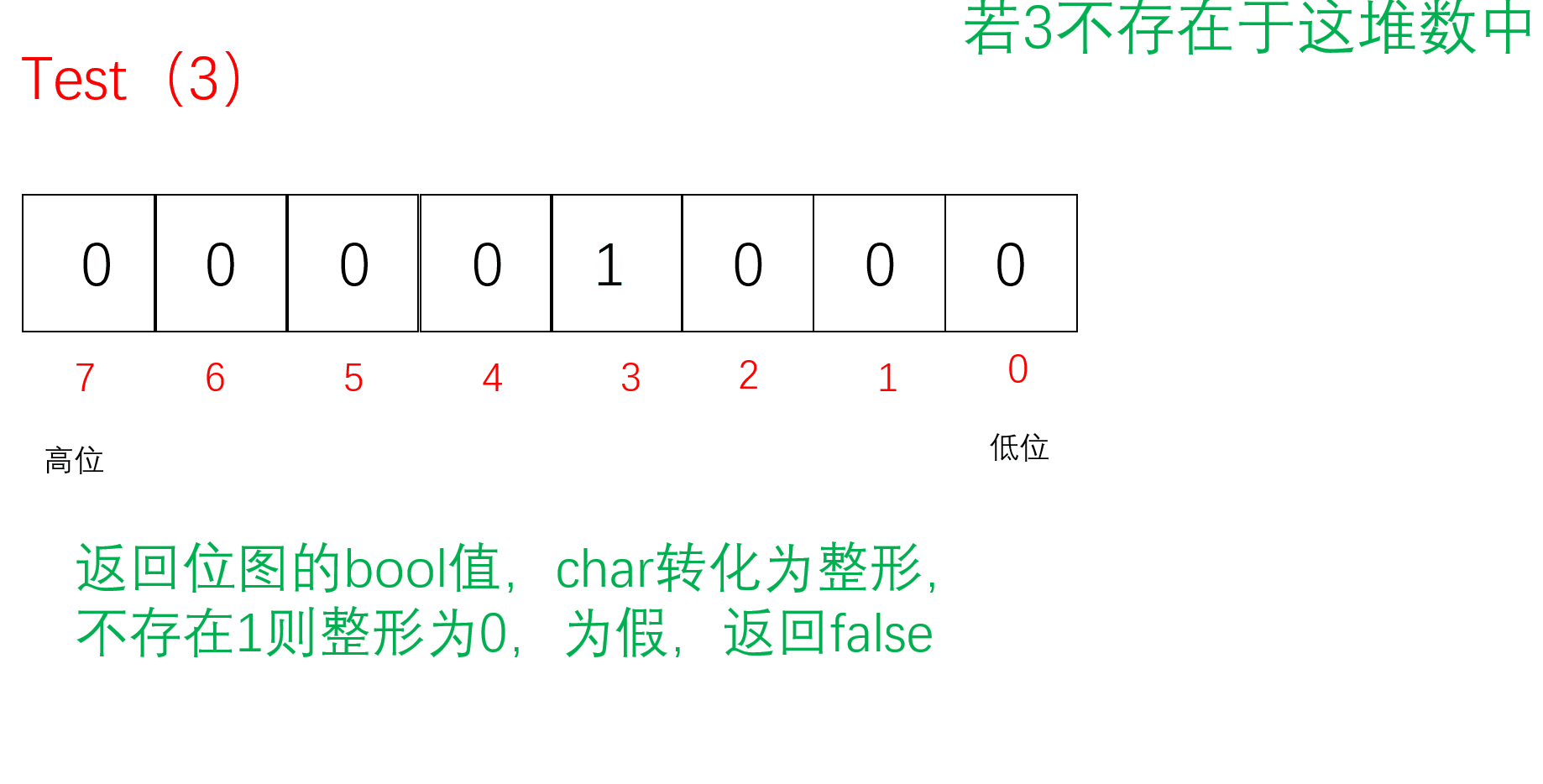
Test
把要Reset的值通过/8找到对应的char(小位图),再通过%8找到对应的位置。先按位取反原来的位图,再把原来的位图与取反的位图按位与,若存在1则为非0,为真返回true;若不存在则没有1全0,为假,返回false;
bool Test(size_t x)//判断x是否在这堆数里面{//计算x位于哪一个char上//size_t i = x / 8;size_t i = x >> 3;//相当于x/8//计算x位于哪个bit上size_t j = x % 8;return _bit[i] & (1 << j);}
整体代码
template<size_t N>//用非类型模板参数---N为要往位图里存储多少个数class BitSet{public:BitSet(){//_bit.resize(N >> 3) + 1);_bit.resize(N / 8 + 1);//多开一个}void Set(size_t x)//把x值对应的标记为置为1{//计算x位于哪一个char上// size_t i = x / 8;size_t i=x >> 3;//相当于x/8//计算x位于哪个bit上size_t j = x % 8;_bit[i] |= (1 << j);}void ReSet(size_t x)//把x值对应的标记置为0{//计算x位于哪一个char上//size_t i = x / 8;size_t i = x >> 3;//相当于x/8//计算x位于哪个bit上size_t j = x % 8;_bit[i] &= (~(1 << j));}bool Test(size_t x)//判断x是否在这堆数里面{//计算x位于哪一个char上//size_t i = x / 8;size_t i = x >> 3;//相当于x/8//计算x位于哪个bit上size_t j = x % 8;return _bit[i] & (1 << j);}vector<char> _bit;};
当开最大的整形数时,内存也只占512M左右

库里面也有
bitset
位图应用
- 快速查找某个数据是否在一个集合中
- 排序+去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
给两个文件,分别有100亿个整数,我只有1G内存,如何找到两个文件的交集???
把文件1的数据放进位图1,把文件2的数据放进位图2,然后逐个遍历位图1的数据同时遍历位图2。当两个位图的数据的标记位都是1时,说明该数据即存在文件1也存在文件2,这个数据就是两个文件的交集。逐个遍历两个位图,找出相同的数据即可。

//测试
void testBitset(){BitSet<100> bs1;BitSet<100> bs2;int path1[] = { 1,2,3,4,5 };int path2[] = { 1,3,5 };for (auto e : path1){bs1.Set(e);}for (auto e : path2){bs2.Set(e);}for (size_t i = 0; i < 100; i++){if (bs1.Test(i) && bs2.Test(i))//11{cout << i << endl;}}}
一个文件有100亿个int,1G内存,设计算法找出次数不超过2次的所有整数
用两个位图来记录出现的数据次数。出现0次就是00,出现1次就是01,出现2次就是10,出现3次或以上就是11。记录两个位图标记位为01,10的数据。
浅搓了个代码
template<size_t N>class twoBitset{public:void Set(size_t x){if (!bs1.Test(x) && !bs2.Test(x))//两个位图都是0---数据出现0次{//00->01bs2.Set(x);}else if (!bs1.Test(x) && bs2.Test(x))//第一个位图是1,第二个位图是0---数据出现1次{//01->10bs1.Set(x);bs2.ReSet(x);}else //两个位图都是1---数据出现2次{//10->11bs2.Set(x);}//else//出现3次及以上//{// break;//}}void Printones(){for (size_t i = 0; i < N; i++){if (!bs1.Test(i) && bs2.Test(i))//01{cout << i << endl;}else if (bs1.Test(i) && !bs2.Test(i))//10{cout << i << endl;}}}private:BitSet<N> bs1;BitSet<N> bs2;};
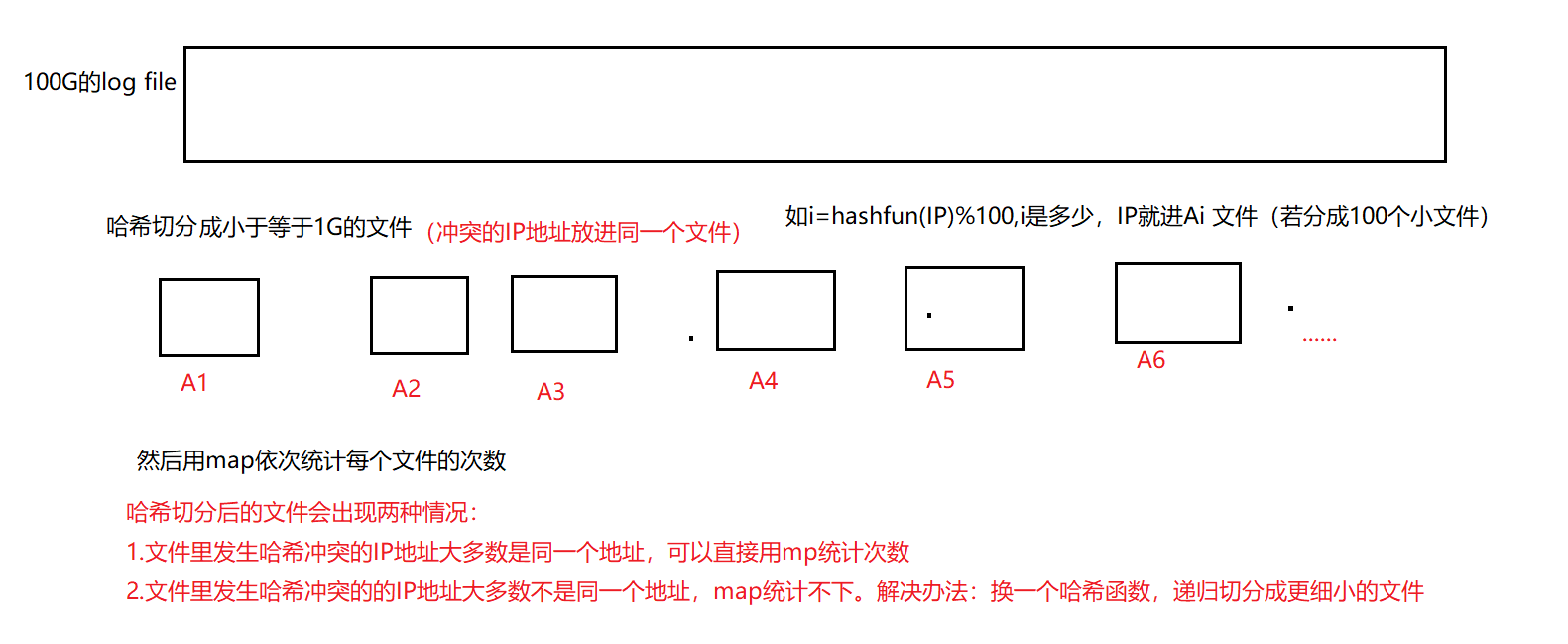
给一个超过100G的log file,log中存着IP地址,设计算法找到出现次数最多的IP地址
先通过哈希函数哈希切分这个100G的文件,然后冲突的IP地址放进同一个小文件里;接着用map依次统计每个文件的相同IP的次数,统计完一个clear掉map统计下一个。
此时小文件有两种情况,一是小文件里大部分冲突的IP都是重复的,此时直接用map可以统计次数。二是小文件里大部分冲突的IP都是不重复的,此时用map统计不下,使用mp的insert时会插入失败,即没内存去new节点了,new失败会抛异常,这时需要换个哈希函数,对这个小文件再次通过哈希切分,分成更细小的文件。