作者 | Python
预训练语言模型(PLM)刷GLUE,SuperGLUE,甚是常见;那ChatGPT等大语言模型(LLM)刷什么榜呢?现在常用的榜单,例如MMLU评测了57个学科知识,Big-Bench评测204个推理任务。而这次,清华大学提出KoLA评测基准,从掌握和利用世界知识的角度,衡量大语言模型的表现。
KoLA基于19个关注实体、概念和事件的任务。参考了Bloom认知体系,KoLA从知识的记忆、理解、应用和创造4个层级,从深度而非广度去衡量大语言模型处理世界知识的能力。实验结果表明,GPT-4虽然很强,但依然未能霸榜,在知识创造层次的测试中仅排第三名。那究竟是怎么一回事儿呢?让我们来看看吧。
论文题目:
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
论文链接:
https://arxiv.org/pdf/2306.09296.pdf
评测榜单:
https://kola.xlore.cn
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
Hello, GPT4!
KoLA评测
KoLA的评测任务如下图所示。整体而言,根据知识的认知层级,分成知识记忆(KM),知识理解(KU),知识应用(KA),知识创造(KC)四个层级。

知识记忆
知识记忆主要是之前的knowledge probing任务,包括:
-
1-1/2 High/Low-Freq:Wikidata5M中选取三元组,用谓词模板转化为句子,让大模型预测客体(尾实体)。其中尾实体是从2000个最高频实体中选出(1-1),或选择低频实体(1-2)。
-
1-3 ETM(表格里笔误):从新语料中选取理论上之前没有出现过的三元组,做类似的客体预测。
知识理解
知识记忆主要是之前的信息抽取任务,包括:
-
2-1/2/3 COPEN-CSJ/CPJ/CiC:采用COPEN数据集,要求大模型选择与给定概念最相似的感念,判断概念属性相关断言的正误,选择合适的概念补全上下文。
-
2-4 FewNERD:小样本实体识别数据集
-
2-5 DocRED:文档级关系抽取数据集(未公开的测试集)
-
2-6/7 MAVEN/MAVEN-ERE:事件检测、事件关系抽取数据集(未公开的测试集)
-
2-8 ETU:从新语料中,类似DocRED,构建文档级关系抽取
知识应用
知识应用旨在考察模型利用知识解决特定的推理任务的能力。这里更关注事实推理,而非之前工作关注的数学推理等。包括:
-
3-1 HotpotQA:多跳抽取式问答数据集
-
3-2 2WikiMultihopQA:类似的多跳问答,问题通过模板构建,确保不能被单跳解答,但却不够自然。
-
3-3 MuSiQue:类似的多跳问答,避免了推理捷径和模板构建的问题。
-
3-4 KQA Pro:类似的多跳问答,包含了更复杂的逻辑推理。
-
3-5 KoRC:需要文档联合知识库进行推理,涉及隐式推理能力。
-
3-6 ETA:从新语料中,类似KoRC构建问答数据。
知识创造
知识创造旨在考察模型利用现有的知识合理推断和创造知识的能力,通过生成内容的连贯性和正确性来考察。包括:
-
4-1/4-2 Encyclopedia/ETC:根据史料、新闻和科幻小说续写后续可能发生的事件。4-1基于维基百科,4-2基于新语料。
为了更客观地自动评价知识创造,本文提出了一种新的基于对比的方法。具体而言,记大模型生成的为,人工标注的为,人工从R中抽取的知识部分为,大模型基于K和原始输入生成的为,评价结果为三组相似度的均值:。相比直接对比,另外两项将创造知识与生成文本分开测量,更精细。
赛季制+新旧语料组合
为确保公平,KoLA采用赛季制,一个季度为一个赛季。任务的语料分为历史语料(Known,来自维基百科,选用Wikidata5M)和创建90天内的新语料(Enolving,第一赛季来自新闻和科幻小说)。
因为大语言模型经常通过记忆来作弊(参见只给大模型LeetCode编号,也能解题!),并且大模型的测试效果对测试集与训练集语料的来源时间较为敏感(参见谷歌训了28个15亿参数模型,说明数据对大模型训练的影响)。而这里所采用的维基百科语料是几乎所有大模型都会拿来训练的,而考虑到模型训练所需的时间,90天内的语料几乎不可能被大模型拿来训练。因此,这两类语料可以分别考察大模型对已知语料的处理能力和对新语料的泛化能力。
标准化分数
考虑到不同的数据集敏感度不同,对分数先计算标准化得分。(编者按:比如之前刷GLUE时有些少监督数据集非常敏感,动不动就是十几个百分点的差别。)类似我们考四六级,针对每个数据集,将所有测试的模型表现调整为标准正态分布,并将所有分数线性缩放到0~100的区间。
实验结果
实验对比了21个模型,包括13个开源模型,与8个只提供API的模型,例如CHatGPT。在在知识记忆与理解层级上的实验结果如下图表示:

可以看到,开源的模型的能力一般相较GPT-4等模型而言要明显差一些,这在知识应用与创造层级上也能观察到。然而,GPT-4即使在这两个层级上的表现都取得了第一,小分也并未霸榜。在标黄的分数上,GPT-4依然技不如人。甚至,在下图中,GPT-4在知识创造层级上的平均表现仅排第三,落后于GPT-3.5与InstructGPT。

其它结论:
-
对于没有Instruction Tuning的模型(如GPT-J and BLOOM),知识记忆(KM)的能力与模型规模之间有强相关性(斯皮尔曼系数0.79)。
-
Instruction Tuning 对大模型的高级能力提升更明显。比如知识应用(KA),斯皮尔曼系数小/大模型分别是0.02,0.53。
-
但在低级能力上,经过Instruction Tuning,模型表现与规模之间的相关性反而下降了,观察到了智商税。例如知识记忆(KM)的斯皮尔曼系数降到0.34。
-
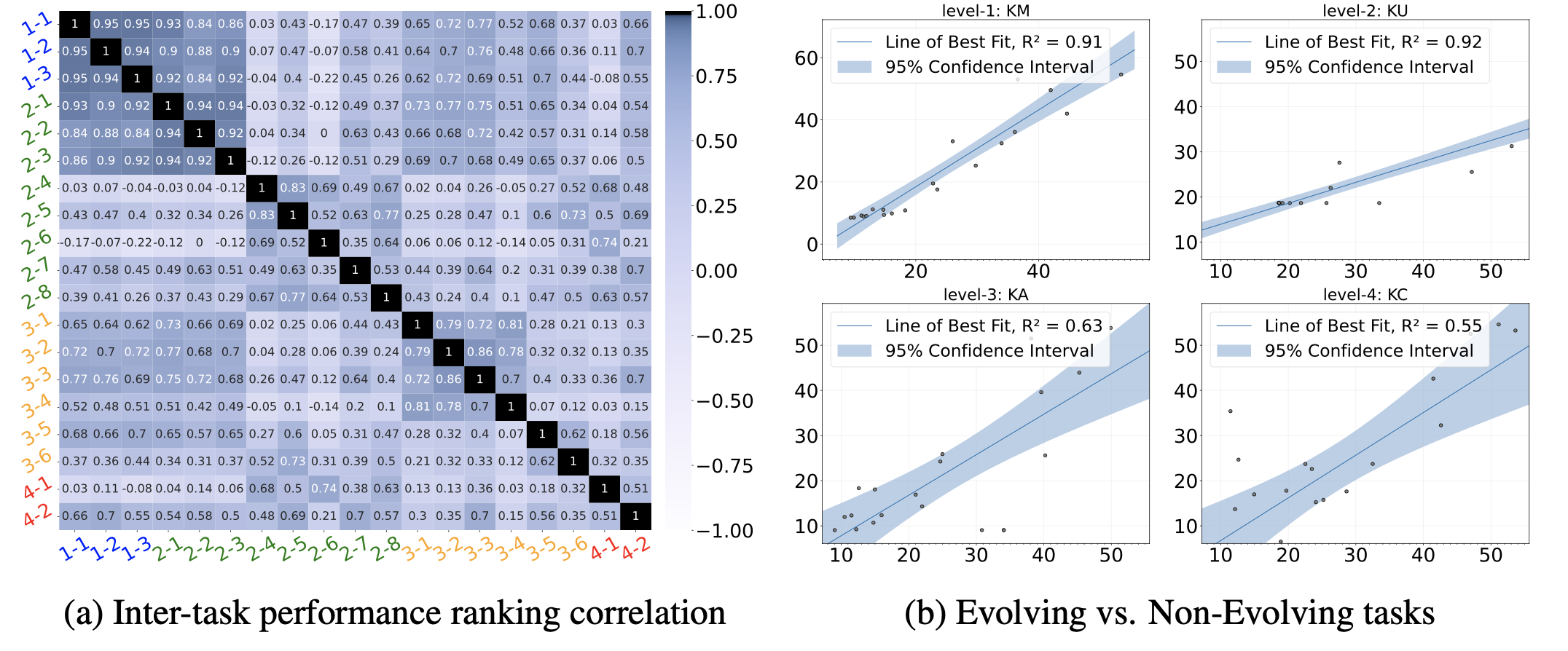
相同层级的任务间相关性较高,说明层级设置合理。
-
知识记忆(KM)与后续任务表现相关性较高(例如2-1~2-3,3-1~3-5),显示高层级能力依赖知识记忆。
-
新兴语料上的表现与旧语料上,模型表现具有明显的相关性,体现出模型在利用相似的能力完成任务。
-
高层级任务上,新旧语料模型的表现差要比低层级任务更小。说明低层级任务模型可以通过记忆来取得更好的成绩,但在更难的任务上主要还是需要能力的运用。
结束语
清华大学的KoLA将大模型的评价与认知层级联系起来,为大模型研究提供了新的思路。虽然GPT-4并未成功霸榜所有小分,但以GPT-4为代表的不开源模型在评价中还占有很明显的优势。我们普通研究者还需要联合起来,踔厉奋发,砥砺前行,共同推动开源社区的发展,才可能打破OpenAI等大公司的技术垄断。