1.k8s的功能
自动装箱:
基于容器对应用运行环境的资源配置要求自动部署应用容器
自我修复
当容器失败时,会对容器进行重启
当所部署的 Node 节点有问题时,会对容器进行重新部署和重新调度
当容器未通过监控检查时,会关闭此容器直到容器正常运行时,才会对外提供服务
水平扩展
通过简单的命令、用户 UI 界面或基于 CPU 等资源使用情况,对应用容器进行扩缩容
服务发现
用户不需使用额外的服务发现机制,就能够基于 Kubernetes 自身能力实现服务发现和负载均衡
滚动更新
可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新
版本回退
可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退
密钥和配置管理
在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署。
存储编排
自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要
存储系统可以来自于本地目录、网络存储(NFS、Gluster、Ceph 等)、公共云存储服务
批处理
提供一次性任务,定时任务;满足批量数据处理和分析的场景
再引用刘超大神的一个总结.可以看到k8s对目前的微服务设计简直量身定做

2.k8s的模块组成
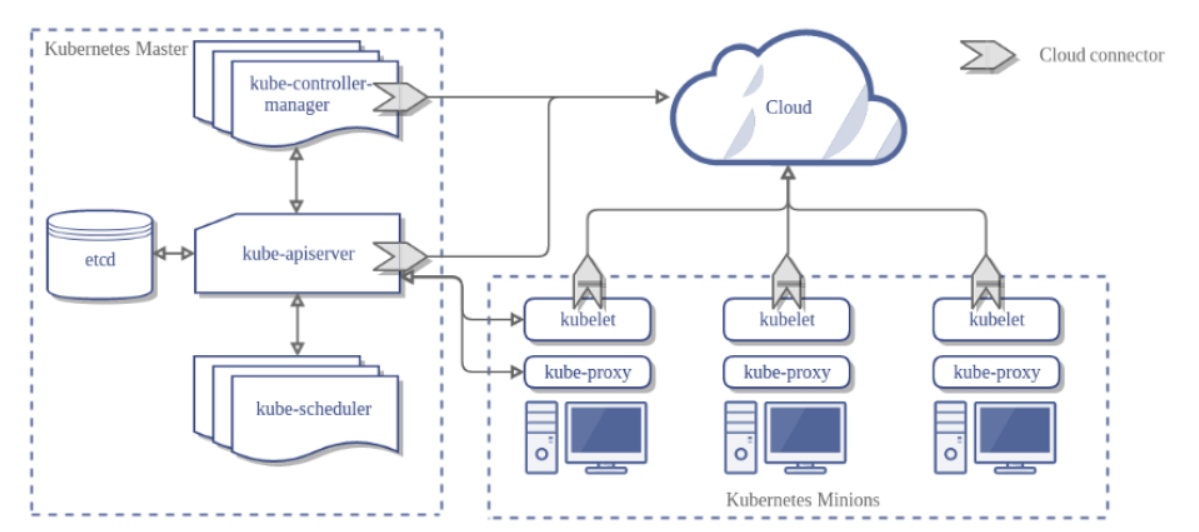
1.etcd, 底层存储
2.api-server. 请求入口. 用户可以请求apiserver,对资源进行增删改查. 是唯一连接etcd的组件.对scheduler/kubelet/proxy都提供了watch/list接口.
3.kube-scheduler. 调度器,监听apiserver中的数据(etcd),将服务调度到合适的node.
4.controller-manager 资源的监控器.例如deploymentController,ServiceController等等.可以确保你的资源维持在你想要的状态.例如你的 DeploymentController会确保一直有3个pod运行.
4.kubelet. 接受master的指令(例如创建pod),上报本机服务的状态.
5.kube-proxy 网络组件,保证网络通讯.
3.概念
1.pod
为什么需要pod.因为业务进程间一般不会是孤零零的,很多时候要共享同一个网络栈,存储等.但是容器是单进程模型.容器的1号进程就是应用进程本身.
因此出现了pod,pod本质上是一组共享了某些资源的容器。是一个逻辑概念.Kubernetes 真正处理的,还是宿主机操作系统上 Linux 容器的 Namespace 和 Cgroups,而并不存在一个所谓的 Pod 的边界或者隔离环境。具体的说:Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume
$ docker run --net=B --volumes-from=B --name=A image-A ...
貌似这样也可以,但是问题是,需要先有b再有a才行.
所以,在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起.
Pod的状态:
Pending。这个状态意味着,Pod 的 YAML 文件已经提交给了 Kubernetes,API 对象已经被创建并保存在 Etcd 当中。但是,这个 Pod 里有些容器因为某种原因而不能被顺利创建。比如,调度不成功。
-
Running。这个状态下,Pod 已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行中。因此,当一个pod中包含多个容器.只有全部
-
Succeeded。这个状态意味着,Pod 里的所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见。
-
Failed。这个状态下,Pod 里至少有一个容器以不正常的状态(非 0 的返回码)退出。这个状态的出现,意味着你得想办法 Debug 这个容器的应用,比如查看 Pod 的 Events 和日志。
-
Unknown。这是一个异常状态,意味着 Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver,这很有可能是主从节点(Master 和 Kubelet)间的通信出现了问题。
livenessProbe
怎么判断容器是否存活,如果你什么都不配置,那么就是按照容器的判断了,镜像拉下来,进程起来了,还在,就说明是存活的.但是有时候不严谨,例如hang住了.
因此:
配置 livenessProbe,是为pod里的容器设置的!!. 针对的是容器.pod只是个逻辑概念.当你的pod里存在多个容器,那么就可以针对每个容器,设置不同的健康检查策略.

restartPolicy
Always:在任何情况下,只要容器不在运行状态,就自动重启容器(默认)
OnFailure: 只在容器异常时才自动重启容器.
Never: 从来不重启容器。
注意:这里是针对容器.而不是pod.
pod状态,pod中容器的状态,restartPolicy的关系?
1.如果是单容器的pod,设置restartPolicy=true,那么只要异常就会重启,因此一直running;如果restartPolicy=never,那么就是failed
2.如果是多容器的pod,例如有3个容器,2个运行,1个异常,那么pod的状态是running,ready一栏显示 2/3. 即使你设置了restartPolicy=Never.除非你所有的容器都挂掉了.
readinessProbe
readinessProbe 检查结果的成功与否,决定的这个 Pod 是不是能被通过 Service 的方式访问到,而并不影响 Pod 的生命周期.例如一个web程序启动后.需要去数据库读取数据到内存,初始化之后才能接受请求. 那如果我们配置在liveness的话,如果初始化时间一长,就会重启..因为已经异常了.或者如果程序hang住了,此时应该不接受流量.
2.Deployment 和 ReplicaSet
rs: yaml文件由 pod数目+pod定义. rsController会保证running的pod始终保持在设置的数量上.通过rs实现了水平扩展/收缩.
deployment:yaml文件由 pod数目+pod定义.deployment实现了水平扩展/收缩和滚动发布.


从上面看,rs已经实现了pod的水平扩展.而deployment是rs的父集.k8s中,deployment直接操作的也是rs.而非pod.
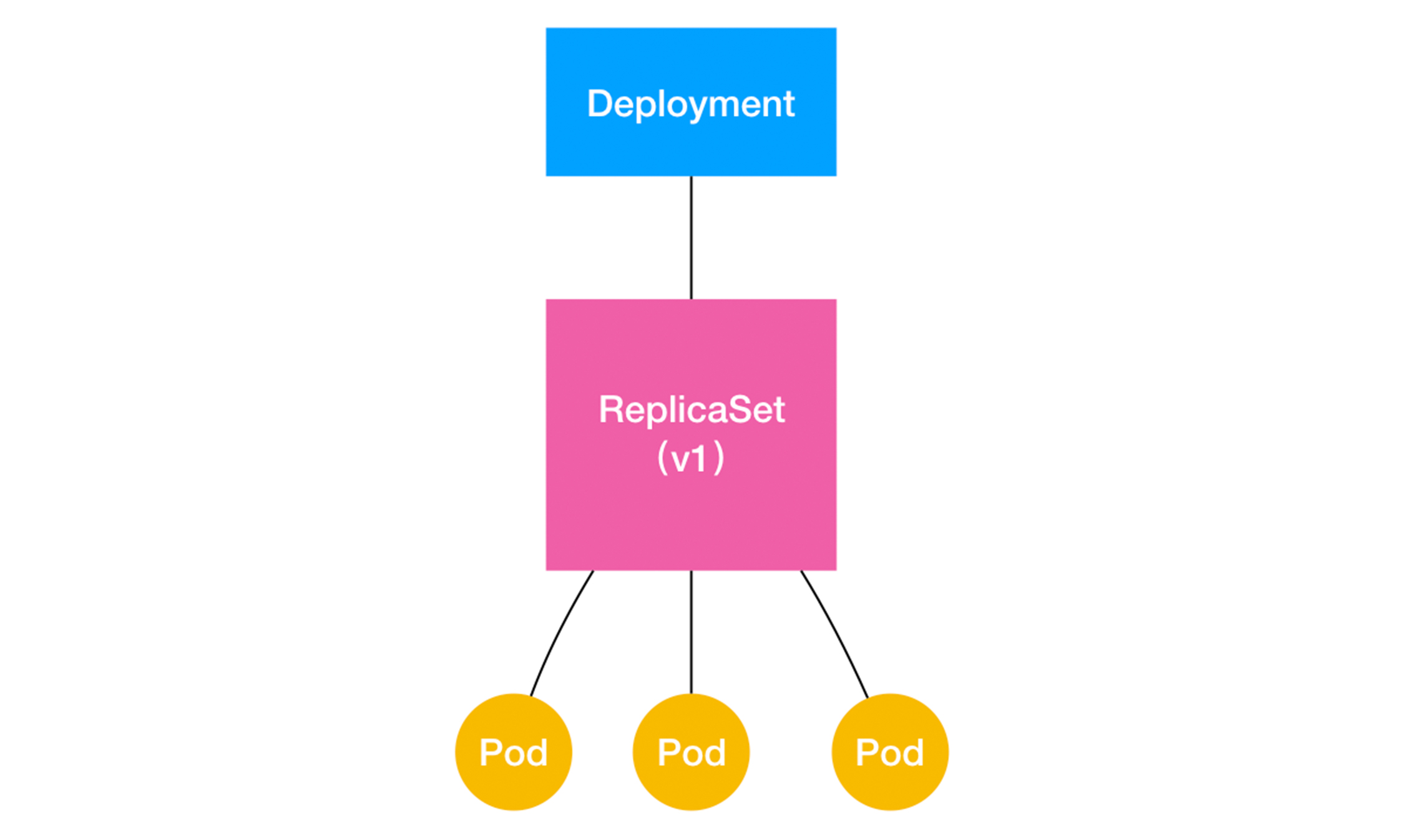
怎么实现水平扩展?deployment对象直接操作rs对象,通过修改对应的pod数量就可以实现.这个很简单.

怎么实现滚动更新?
控制两个rs对象.其中有几个参数可以控制滚动的快慢以及速率.
DESIRED:在任何时间窗口内,只有指定比例的 Pod 处于离线状态,默认25%

3.volume
EmptyDir Volume:
EmptyDir 是 Kubernetes 中最简单的卷了,当我们为一个 Pod 设置一个 EmptyDir 类型的卷时,其实就是在当前 Pod 对应的目录创建了一个空的文件夹,这个文件夹会随着 Pod 的删除而删除。
Projected Volume:
投射数据卷,也就是把数据投射到 容器内.
1.secret
例如你想把数据库密码存放起来,然后pod启动的时候,再设置到容器里.分为两个步骤.
a.编写secret对象
b.pod中引入相应的secret数据

注意:如果etcd中的值发生变化,容器中的值会变化吗?
会的.那么谁去监听和更新呢?node里的proxy负责的是网络.那么肯定就是kubelet了.
2.configMap
和secret类似,只不过没有进行加密
3.DownloadApi
把当前pod的一些信息投射到容器,当然是启动前就能确定的.
4.ServiceAccountToken
特殊的secret,apiServer访问时,需要一些用户校验的
Kubernetes 其实在每个 Pod 创建的时候,自动在它的 spec.volumes 部分添加上了默认 ServiceAccountToken 的定义,然后自动给每个容器加上了对应的 volumeMounts 字段。这个过程对于用户来说是完全透明的。这样,一旦 Pod 创建完成,容器里的应用就可以直接从这个默认 ServiceAccountToken 的挂载目录里访问到授权信息和文件。这个容器内的路径在 Kubernetes 里是固定的,即:/var/run/secrets/kubernetes.io/serviceaccoun.一般在开发插件时使用.
pv和pvc
为什么需要pv和pvc. 开发人员其实只关注我需要多少存储空间,具体这些存储空间存在本机还是云上,存在a目录还是b目录.是什么底层存储引擎.不太关注.
这些让运维去搞就行了.因此pv和pvc也是为了把功能解耦,职责解耦.
注意:
pv和pvc是一一对应的

4.service
为什么需要service?
1.pod的ip是不固定的 2.pod之间需要负载.
service本质是什么?
是一组pod的抽象.例如pod上都打了service=a,那么可以定义一个service,选取规则是 service=a.
那么service怎么访问呢?
clusterIp(通过一个vip,内部访问内部)

有点丑的.主要步骤
a.创建service对象,api-server会分配一个vip 10.0.1.175
b.kube-proxy监听到etcd的变化,更改iptables配置,大概就是,请求某个vip,会分发到3个节点,且概率相同.
//请求10.0.1.175,目标端口是80的包,要经过KUBE-SVC-NWV5X2332I4OT4T3这个规则
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
//KUBE-SVC-NWV5X2332I4OT4T3共有三条规则
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR//第一个规则,
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
注意这里要进行DNAT的转换.也就是要访问10.0.1.175时,会将目的地址改为pod地址.
这样导致的一个后果就是.每台机器上的kube-proxy都要维护很多pod的iptables规则.例如有新的service增加了,那么又要维护一套vip--->pod的规则.而写规则是kube-proxy写的(也就是再用户态).
频繁的刷规则,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中
那么怎么优化呢?
使用IPVS.ipvs其实原理也是操作netfilter,然后修改目标地址为pod地址.只不过 1.内部数据结构是用的hash 2.工作在内核态
c.当k8s内部机器.访问vip时,根据iptables配置,会路由到某一个pod上. 注意,只有在集群内部访问时,才可以.
(从外部访问内部)
nodeport(端口)
(38 | 从外界连通Service与Service调试“三板斧”-极客时间)
clusterIp有一个缺点,就是只能在机器内部访问,例如你在一台外部机器上,想访问服务,就访问不了了.
nodePort为每个Node映射了一个端口,对外暴露

1.创建service时,指定type为nodePort.指定node对外暴露的端口和映射的pod的端口.同时,也会创建一个vip.
2.kube-proxy监听到service后,添加iptables规则. node.port--->vip--->podIp
loadbalance(适用于公有云)
1.创建service,配置type=loadbalance,此时k8s会调用公有云的一个接口(CloudProvider),并且把被代理的 Pod 的 IP 地址配置给负载均衡服务做后端
5.ingress
刚刚说了,service想要暴露给外部,可以创建loadBalance方式.but,每个service都创建一个loadbalance吗?这个可是云服务给你提供的,太浪费了.我们希望有一个全局的负载均衡器,当访问/user/a时,可以调用到svc_user的服务,当访问/login时,可以调用到svc_login的服务.
这种全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的 Ingress 服务。可以理解为 service的service.ingress就是对反向代理的抽象.
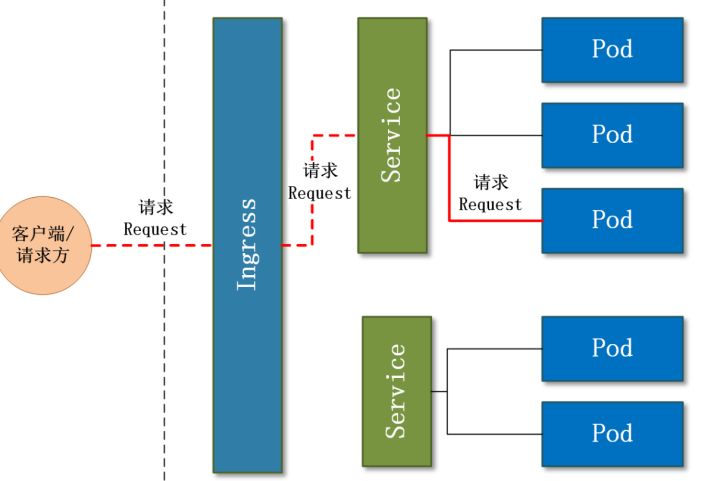
一个ingress对象
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: cafe-ingress
spec:
tls:
- hosts:
- cafe.example.com
secretName: cafe-secret
rules:
- host: cafe.example.com
http:
paths:
- path: /tea
backend:
serviceName: tea-svc
servicePort: 80
- path: /coffee
backend:
serviceName: coffee-svc
servicePort: 80
上面的含义,host为cafe.example.com的请求,当path为/tea时,请求转到 tea-svc这个service,当请求/coffee时,转发到coffee-svc,是不是像nginx??事实上,一个ingress对象就是对nginx配置的一个描述.
当你创建了ingress对象,怎么把这个配置转化为能力呢?当然是controller,还记得上面说过,controller就是对pod,deployment等资源进行控制的.我们把nginx-controller运行起来,这个 IngressController 会根据你定义的 Ingress 对象,提供对应的代理能力.
此处注意两个概念,ingress:配置对象 ingressController:代理能力实现,通常是一个pod.
问题:
- ingress-controller是作为pod来运行的,以什么方式部署比较好
- ingress解决了把如何请求路由到集群内部,那它自己怎么暴露给外部比较好
Deployment+LoadBalancer模式的Service:
ingress部署在公有云,那用这种方式比较合适.用Deployment部署ingress-controller,创建一个type为LoadBalancer的service关联这组pod
Deployment+NodePort模式的Service
该方式一般用于宿主机是相对固定的环境ip地址不变的场景。NodePort方式暴露ingress虽然简单方便,但是NodePort多了一层NAT,在请求量级很大时可能对性能会有一定影响。
DaemonSet+HostNetwork+nodeSelector
每个节点都会有一个pod.
该方式整个请求链路最简单,性能相对NodePort模式更好。缺点是由于直接利用宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。比较适合大并发的生产环境使用
4.资源管理与任务调度
参考
5.网络模型
参考[k8s]从docker容器网络到flannel_责任全在mg的博客-CSDN博客
k8s ingress原理及ingress-nginx部署测试 - SegmentFault 思否
Kubernetes 入门&进阶实战 - 知乎