1 背景
“化繁为简、大巧不工”是机器学习的初衷之一。
费米曾讲述一个故事,冯·诺依曼告诉他,用四个参数就可以拟合出一头大象,用五个参数就可以让大象鼻子动起来,这就是“四个参数画大象”的故事。
但AI模型规模不断剧增已是不争的事实。2017年,Transformer结构的提出使深度学习模型参数突破了1亿。随后,BERT、DALL-E、GPT-3、Switch Transformer在国际上相继出现, M6、Alicemind、悟道、盘古等国内大模型也相继获得成功,模型参数增长至百亿、千亿、万亿甚至十万亿,大模型在算力推动下演变为人工智能领域一场新的“军备竞赛”。
这种竞赛很大程度推动了人工智能的发展,但随之而来的能耗和端侧部署问题限制了大模型应用落地。2022达摩院十大科技趋势指出,“大模型参数竞赛正进入冷静期,大小模型将在云边端协同进化”——大模型向边、端的小模型输出模型能力,小模型负责实际的推理与执行,同时小模型再向大模型反馈算法与执行成效。
2 “洛犀”端云协同平台
在 “中国工程院院刊:信息领域青年学术前沿论坛”上,上海浙江大学高等研究院、阿里达摩院、上海人工智能实验室联合发布“洛犀”端云协同平台。该平台提供一站式的端云协同模型训练、部署、通信能力,致力于促进大小模型协同进化,构建充分利用大模型应用潜力的新一代人工智能体系。

“洛犀”一名取自宇宙中大小星体间永恒的洛希吸引力,并含强大、坚韧之意,寓意大小模型珠联璧合。
洛犀平台背后还有一层深意:“须弥藏芥子,芥子纳须弥。”
据传,唐朝江州刺史李渤曾问禅师:“佛经上所讲的未免太离奇了,小小的一粒种子怎么可能容纳那么大的一座须弥山?”禅师微笑反问:“人家说你读书破万卷,可你的头颅只有一粒椰子那么大,怎么可能装得下万卷书呢?”
大模型能迁移到小模型的秘诀,也在于取其精髓、化繁为简。大模型通过高精度压缩,约简为终端可用的小模型,小模型的实践向大模型汇聚累积起来,将不断提升云端大模型的认知推理能力,最终实现“集众智者无畏于圣人”。
端云协同是让这一联合进化机制成为可能的关键技术。据介绍,达摩院智能计算实验室与浙江大学人工智能研究所、浙江大学上海高等研究院联合进行了长期研究,在端云协同领域取得了多项研究成果。同时,在上海人工智能实验室支持下,三方联合团队正在进行端云协同平台研制。完成主要工作如下:
-
完成了业内第一个端云协同调研总结,该总结系统回顾了端、云相关AI算法,且重点定义了三种“端云协同”的范式,为端云协同社区的研究者和从业者提供了前行方向。
-
结合在阿里相关业务上的落地实践,推出了端云协同平台洛犀1.0并计划对外开放开源,以推动端云协同技术普惠发展。
-
目前在端上部署的模型都属于较为传统的深度学习或者机器学习模型框架(例如CNN、RNN、NaiveBayes等),团队在预训练、图神经网络和强化学习等领域方向完成了端云协同技术链,成功部署了业界首个端上模型。
下面,将为大家详述联合团队在端云协同领域的工作。
2.1 端云协同范式介绍
历史上计算形态经历了几次重要变化。当本地计算成本低于通信成本时,计算模式由分时共享机制迅速转变为本地计算完成方式;当网络技术进步使得通信成本远低于计算成本时,开始出现由本地计算向云计算的过渡。
随着硬件成本降低、计算能力提升、通信带宽飞跃、传感器感知能力进化等技术进步持续发生,传统计算长久以“算力为王”的模式来部署完成,即任务汇聚到大型机上集中处理,而后分散到用户终端设备处理,再然后相当一部分的计算任务重新汇聚到云计算中心处理。随着以苹果手机为代表的智能手机的快速发展迭代,以及以3G/4G为代表的移动通信技术的普及,云计算模式得到了进一步强化,尤其是5G/6G通信技术的出现和萌芽,将进一步大幅降低通信成本。
然而,随着物联网技术的爆发,本地计算需求指数级持续涌现,将全部的计算和数据均交由集中式的云计算中心来处理并不现实,更合理的是既充分发挥云计算优势、又调动端计算敏捷性,形成端云协同的新计算模式。卡内基-梅隆大学的Mahadev Satyanarayanan教授曾经指出:“没有边缘计算的5G大规模部署是没有意义的”。
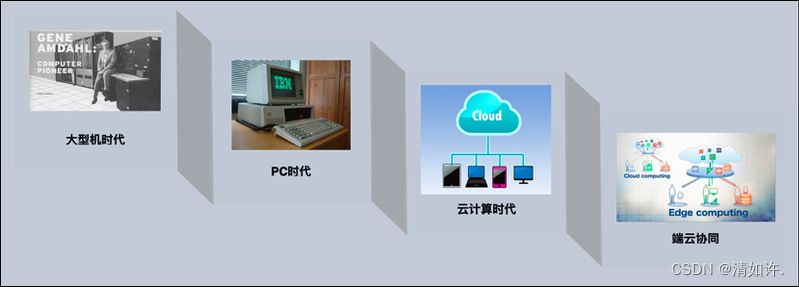
在万物智联的趋势下,端云协同计算会带来下一代计算范式的突破。然而在人工智能领域,充分借助这样的计算优势,构建“端云协同”智能服务的相关实践却少之又少。到目前为止,业界较为知名的“端云协同”算法实践是微众银行推出的联邦学习平台及其社区,但适合端云协同的算法远不止于此。
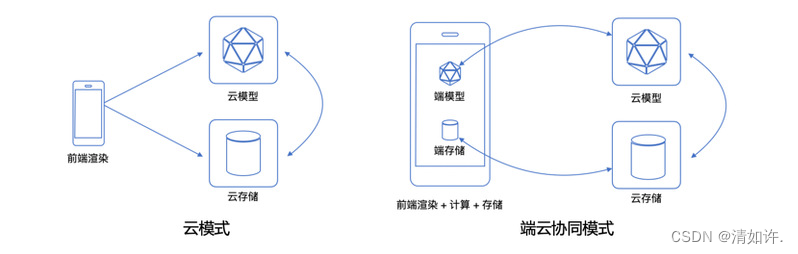
2021年,达摩院联合浙江大学完成了业内第一个端云协同调研,定义了三种“端云协同”的范式,为端云协同研究者提供参考。
-
当以云侧为中心进行模型汇聚,端侧仅提供分布式训练的数据、计算中间结果和轻量计算资源时,称之为“云侧中心化协同”,代表性的工作是联邦学习;
-
当以端侧为中心进行模型个性化,云侧仅仅提供模型校正的数据和巨大算力时,称之为“端侧中心化协同;
-
当云侧有泛化模型、端侧有个性化模型,且两个模型相互协作学习和推理时,称之为“端云双向协同”,代表性方向可参考达摩院十大趋势中提到的大小模型协同演进。
详细可参考论文:[1] Yao J , Zhang S , Yao Y ,et al.Edge-Cloud Polarization and Collaboration: A Comprehensive Survey[J]. 2021.DOI:10.48550/arXiv.2111.06061.
更进一步,端云协同技术也将推动全新的AI范式形成:云端大模型将作为超级大脑,拥有庞大的先验知识,能进行深入的“慢思考”;而端侧小模型作为四肢,能完成高效的“快思考”和有力执行。两者共同进化,让AI向具有认知力和接近人类水平的智能迈进。
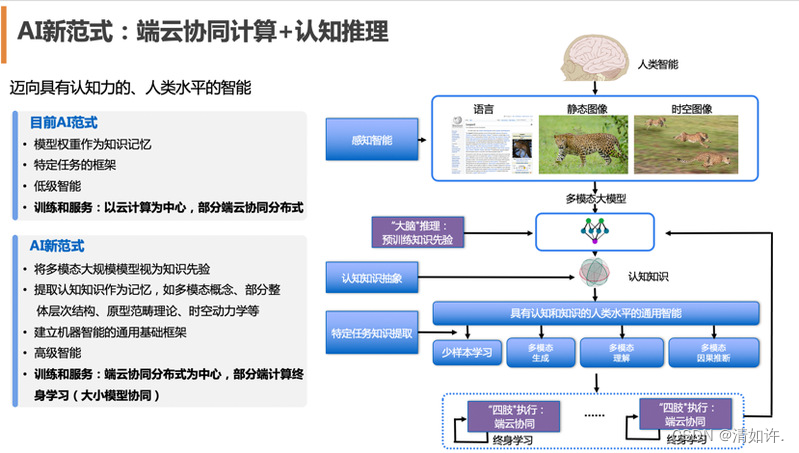
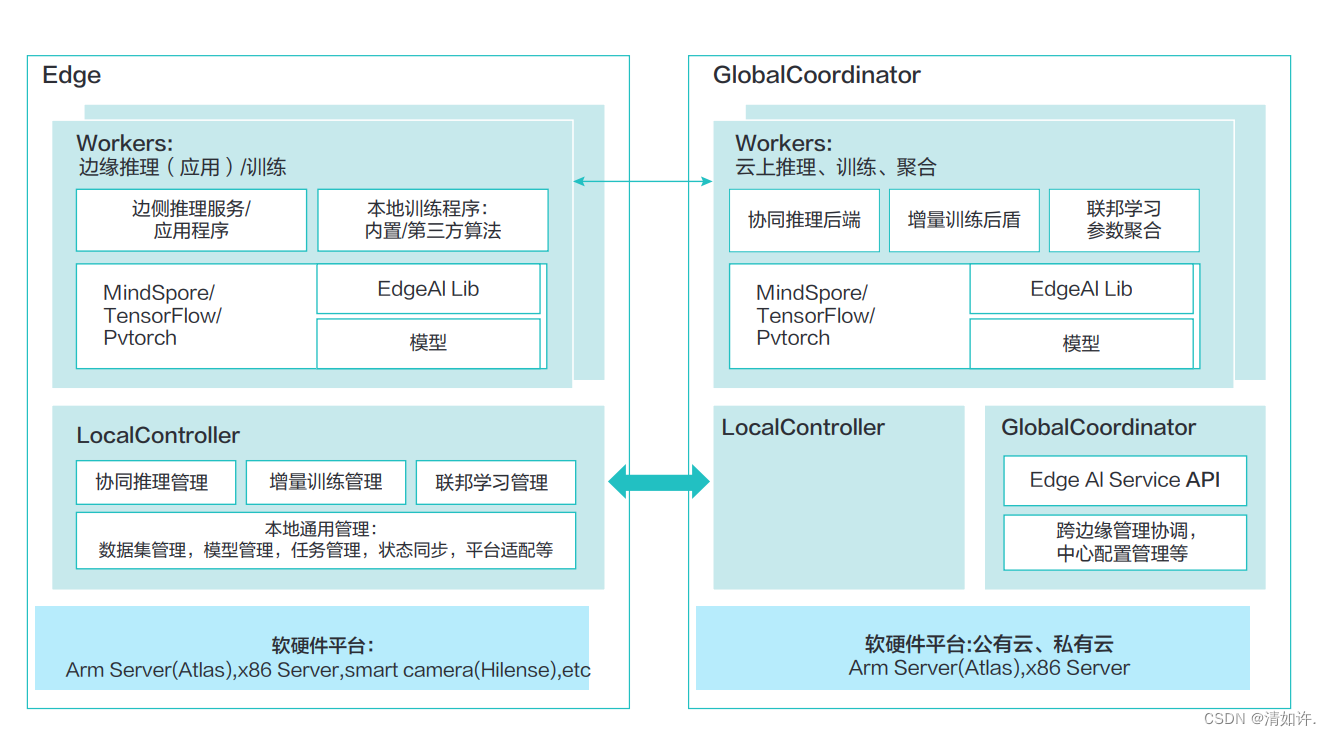
3 边云协同
边缘计算的 CROSS(Connectivity 连接、Realtime 实时、Optimization 数据优化、Smart 智能、Security 安全)价值推动计算模型从集中式的云计算走向更加分布式的边缘计算,边缘计算正在快速兴起,未来几年将迎来爆炸式增长。
边缘计算与云计算各有所长,云计算擅长全局性、非实时、长周期的大数据处理与分析,能够在长周期维护、业务决策支撑等领域发挥优势;边缘计算更适用局部性、实时、短周期数据的处理与分析,能更好地支撑本地业务的实时智能化决策与执行。
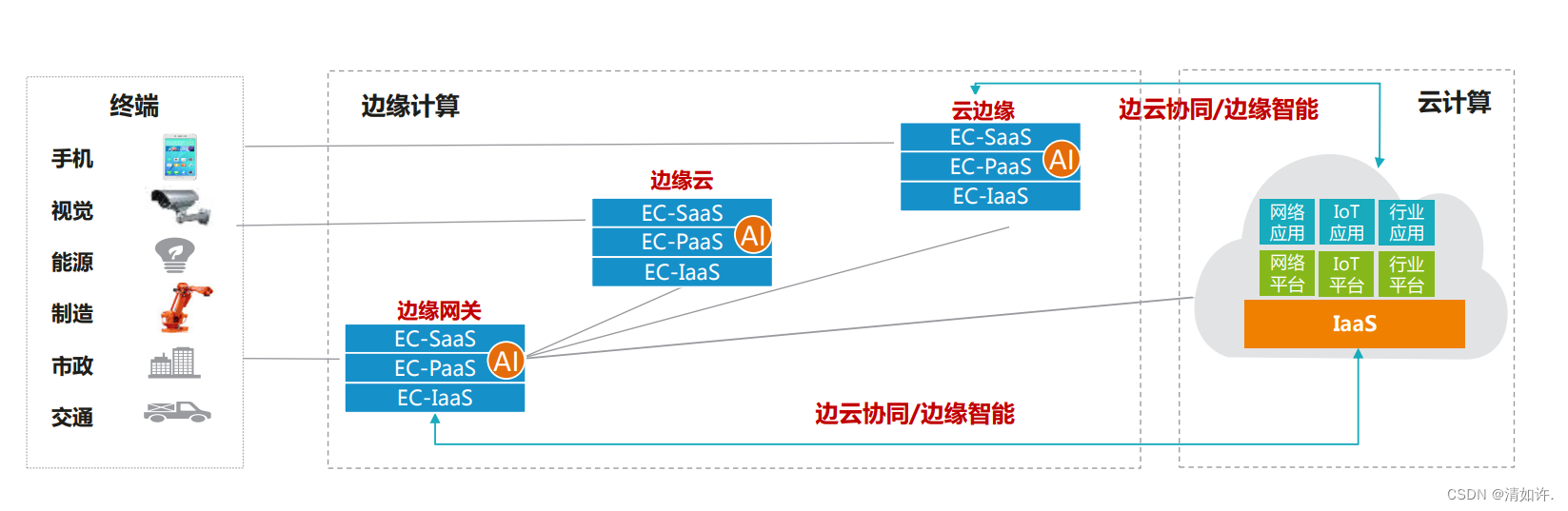
因此,边缘计算与云计算之间不是替代关系,而是互补协同关系。边缘计算与云计算需要通过紧密协同才能更好的满足各种需求场景的匹配,从而放大边缘计算和云计算的应用价值。边缘计算既靠近执行单元,更是云端所需高价值数据的采集和初步处理单元,可以更好地支撑云端应用;反之,云计算通过大数据分析优化输出的业务规则或模型可以下发到边缘侧,边缘计算基于新的业务规则或模型运行。
3.1三层六类边云协同内涵
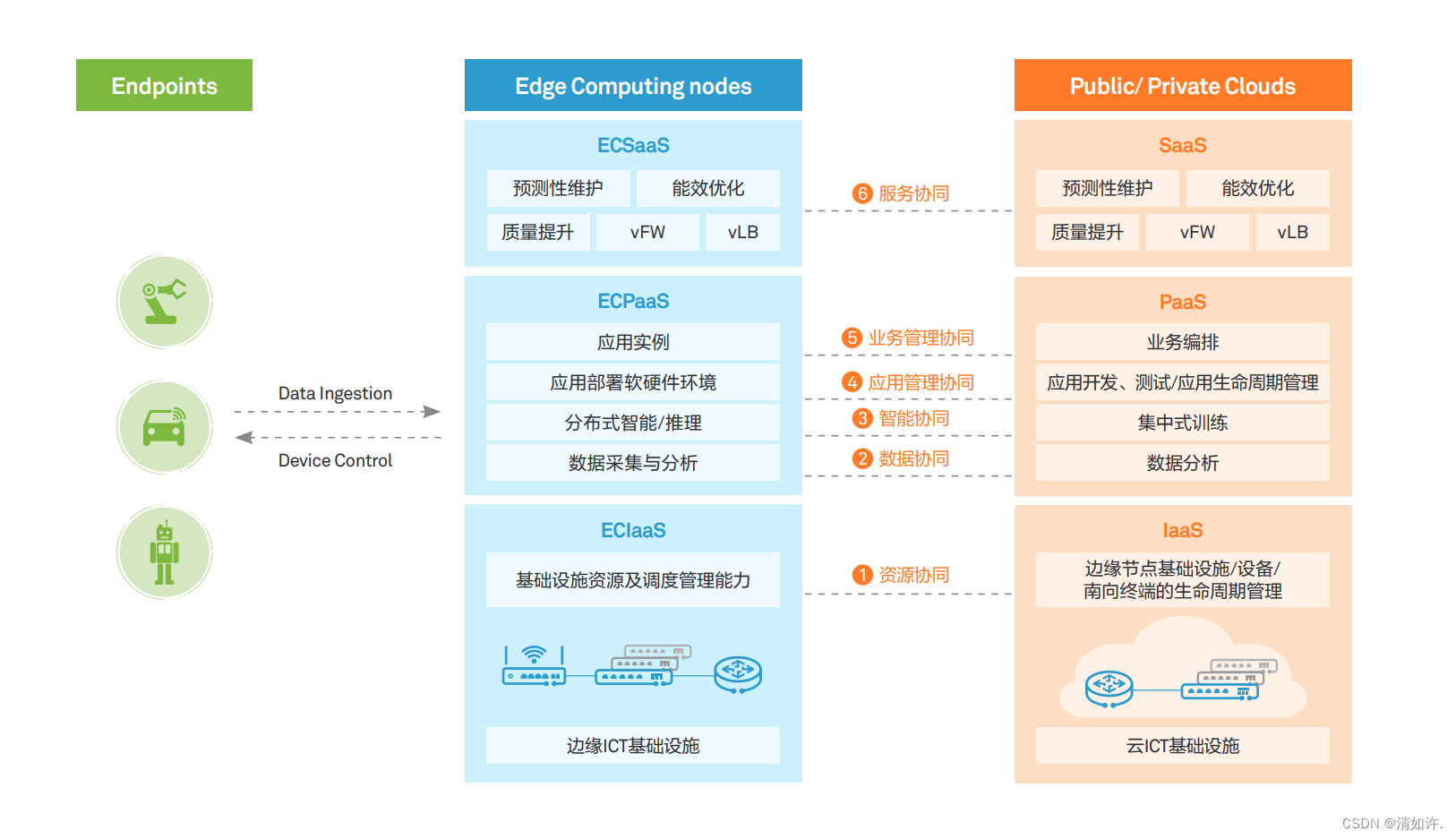
边缘计算不是单一的部件,也不是单一的层次,而是涉及到 EC-IaaS、EC-PaaS、EC-SaaS 的端到端开放平台。典型的边缘计算节点一般涉及网络、虚拟化资源、RTOS、数据面、控制面、管理面、行业应用等,其中网络、虚拟化资源、RTOS 等属于 EC-IaaS 能力,数据面、控制面、管理面等属于EC-PaaS能力,行业应用属于EC-SaaS范畴。边云协同的能力与内涵,涉及 IaaS、PaaS、SaaS 各层面的全面协同。EC-IaaS 与云端 IaaS 应可实现对网络、虚拟化资源、安全等的资源协同;EC-PaaS 与云端 PaaS 应可实现数据协同、智能协同、应用管理协同、业务管理协同;EC-SaaS 与云端 SaaS 应可实现服务协同。
- 资源协同:边缘节点提供计算、存储、网络、虚拟化等基础设施资源、具有本地资源调度管理能力,同时可与云端协同,接受并执行云端资源调度管理策略,包括边缘节点的设备管理、资源管理以及网络联接管理。
- 数据协同:边缘节点主要负责现场 / 终端数据的采集,按照规则或数据模型对数据进行初步处理与分析,并将处理结果以及相关数据上传给云端;云端提供海量数据的存储、分析与价值挖掘。边缘与云的数据协同,支持数据在边缘与云之间可控有序流动,形成完整的数据流转路径,高效低成本对数据进行生命周期管理与价值挖掘。
- 智能协同:边缘节点按照AI模型执行推理,实现分布式智能;云端开展 AI 的集中式模型训练,并将模型下发边缘节点。
- 应用管理协同:边缘节点提供应用部署与运行环境,并对本节点多个应用的生命周期进行管理调度;云端主要提供应用开发、测试环境,以及应用的生命周期管理能力。
- 业务管理协同:边缘节点提供模块化、微服务化的应用/ 数字孪生 / 网络等应用实例;云端主要提供按照客户需求实现应用 / 数字孪生 / 网络等的业务编排能力。
- 服务协同:边缘节点按照云端策略实现部分 ECSaaS 服务,通过 ECSaaS 与云端 SaaS 的协同实现面向客户的按需 SaaS 服务;云端主要提供 SaaS 服务在云端和边缘节点的服务分布策略,以及云端承担的 SaaS 服务能力。
并非所有的场景下都涉及到上述边云协同能力。结合具体的使用场景,边云协同的能力与内涵会有所不同,同时即使是同一种协同能力,在与不同场景结合时其能力与内涵也会不尽相同。
3.2 边云协同 AI 使能
随着 AI 技术在边缘越来越多的广泛应用,同时也带了巨大的挑战,包括:
- » AR、VR、互动直播、视频监控等场景下非结构化数据为主 , 主要采用深度学习方法,主要挑战在数据量大 ,资源用量大,实时要求高,标注困难等。
- » 工业场景下 IoT 结构化数据为主,主要使用传统机器学习算法,方法多样,与业务相关性高,主要挑战是样本少、冷启动和要求模型可解释和可靠性。
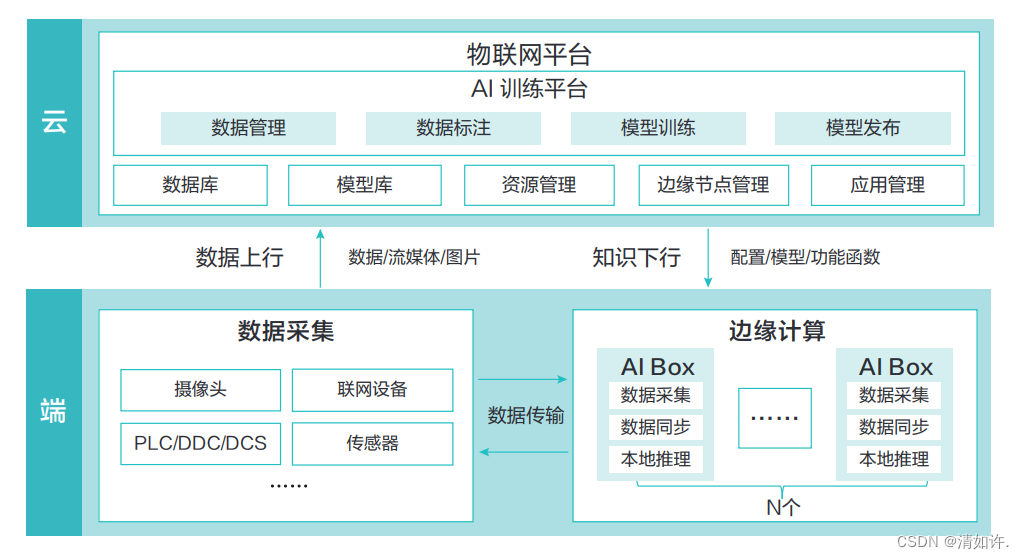
面对上述问题,通过边云协同 AI 的相关技术可以很好解决这些问题。在边缘计算场景下,AI 类应用占据主流。由于边侧计算资源紧缺、网络环境复杂,以及数据量样本量少、数据样本分布不均、数据隐私等原因,AI 类应用在边缘的训练和推理还存在着训练收敛时间长、训练效果差、推理精度低、推理时延高等问题。通过边云协同 AI 技术以很好的解决在边缘训练和推理的精度、时延、通信量、数据隐私等问题。
边云协同 AI 框架将会在算法、接口、部署、性能几个方面带来了好处:
- » 算法:集成多种适合边缘的训练推理算法,适用场景广。
- » 接口:提供边云协同的 lib 库代码,兼容主流框架,tensorflow,pytorch,mindspore;开发简单,原生框架的训练代码经过很少改动可以实现其边云协同的。
- » 性能:针对边云协同进行了通讯、存储的优化,使得边云协同的训练推理更高效。
边云协同 AI 框架的关键技术包括:增量学习、联邦学习、联合推理。
3.2.1 增量学习:
增量学习真对单个租户从时间的维度帮助提升模型效果。数据在边缘侧持续产生,传统的方式是人工定期的收集这些数据,定期的在云上或边上的机器进行重新训练以改进模型效果。这种方式浪费较多的人力,并且模型更新的频率较慢,不能及时用上最新更优的模型。通过增量学习,可以持续监控这些新产生的数据,并通过配置一些触发规则来决定是否要启动训练、评估、部署,以自动化的持续改进模型效果。
3.2.2 联邦学习:
联邦学习跨多个租户从空间的维度帮助提升模型效果。数据天然是在边侧产生的,边云协同联邦学习通过边缘侧的数据联合训练得到一个模型,目的是基于不上传原始数据的前提下,能充分利用分散在不同边侧的数据。单租户场景,基于数据不愿意上云的假设下,租户希望直接利用在边缘产生的数据就近在边缘节点进行训练得到模型,但数据在租户内部是分散在不同节点的,在租户内部集中训练需要另外采购集中训练的机器会带来额外的采购成本,因此可以采用边云协同联邦学习,直接使用边缘节点的计算能力进行训练,使用云上的聚合器进行聚合,在保证数据隐私和高效传输的前提下,提供更快的收敛速度,精度更高、场景更丰富的聚合算法,以完成模型的联合训练。
3.2.3 协同推理:
协同推理利用推理性能较强的云作为推理后端来提升推理效果。
对于推理来说,直接在边侧推理可以有更小的时延和更大的吞吐,而直接在云侧推理可以带来更好的推理精度。如何在边侧推理资源有限的情况下,使得时延和吞吐不明显降低的情况下,使得推理精度提高是个问题。协同推理技术通过把把边侧较难的推理样本检测出来,将其发送到云端进行推理。这样,较简单的样本在边侧推理保证了时延和吞吐,而较复杂的样本在云上推理使得整体精度得到提升。