目录
语言可用性加强 (读现代C++教程有感)
nullptr
constexpr
if/switch 申明强化 (C++17开始)
初始化参数列表
范围for迭代
两种类型推导方式
变长参数模板
SmartPointer
Lambda
多线程 (并发与并行)
并发与并行的概念
C++11中的并发并行
软件层面加锁 (为何叫做软件层面加锁?)
经典的生产者消费者模型
CAS原子操作 (软件层面无锁,硬件层面加锁)
无锁栈实现
分离编译: extern "C" 采取C语言代码和C++代码分离编译的特性进行.
语言可用性加强 (读现代C++教程有感)
nullptr
nullptr : 出现原因, 针对C语言中NULL指针定义在C++中没有了指针类型的隐式类型转换问题
以及定义为0的重载函数调用冲突问题。
eg: 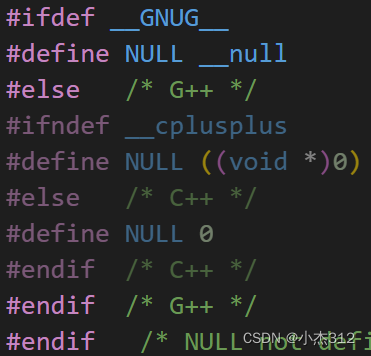
如果是C语言编译器将其定义为(void*)0. 但是C++中针对指针类型一般是不支持隐式类型转换的了。毕竟除了子类对象指针可以向父类对象指针赋值,实现多态这种特殊情况,其他类型指针的转换是十分危险的事情,可能出现内存泄露,或者是非法内存访问等问题。
于是在C++中干脆的将NULL定义为了0作为空地址值。但是这样会存在歧义性问题。举例如下。
constexpr
将一些简单的运算放到编译期间完成,提升运行速度。
eg: 查看汇编代码,明显可以看出,结果已经运算出来了。运算过程是在编译器完成的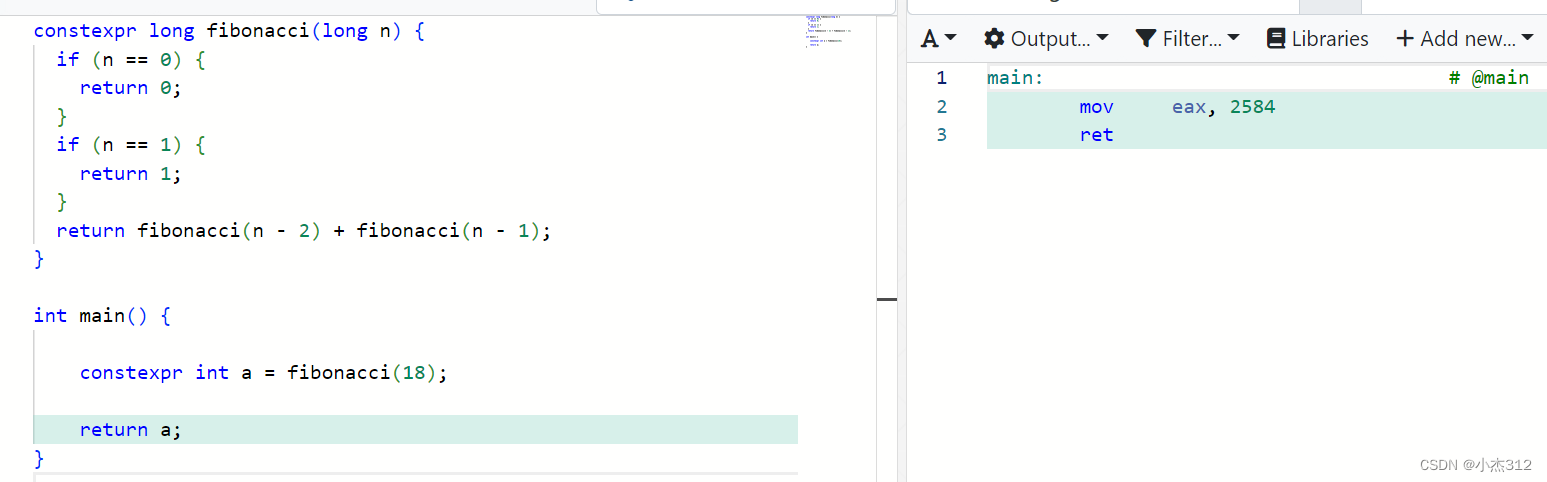
if/switch 申明强化 (C++17开始)
秀儿:可以在判断条件中申明定义变量了
void test() {std::vector<int> nums = {2, 3, 5, 6};if (auto e = std::find_if(nums.begin(), nums.end(), [](int num){return num == 3;}); e != nums.end()) {std::cout << "Find num" << std::endl;} else {std::cout << "Not Found this num" << std::endl;}if (auto e = std::find_if(nums.begin(), nums.end(), [](int num){return num == 20;}); e != nums.end()) {std::cout << "Find num" << std::endl;} else {std::cout << "Not Found this num" << std::endl;}
}
初始化参数列表
统一了初始化方式,支持使用{}进行所有变量的统一初始化。
namespace tyj {class container {public:container(std::initializer_list<int>& l) {//统一所有对象包括容器的初始化方式for (auto e : l) { list.push_back(e);}}private:std::list<int> list; };}范围for迭代
这个没啥好说的,迭代器的功劳,for (auto e:container) {操作};
两种类型推导方式
auto 关键字,自动类型推导原理,在 "编译时" 根据变量的初始化语句的内容来推导。
简单来说:auto 在乎 编译期 + 初始化
{auto a = 2.2;auto b = 1;auto c = 'a';auto iter = some_algorithm(container.begin(), container.end(), [](T&) {运算逻辑;
//T容器中对象的类型});}数组推导不OK

参数推导以前也是不OK的,但是现在编译器越来越牛逼,在超过11的新特性中都已经只是警告,但是可以支持了。
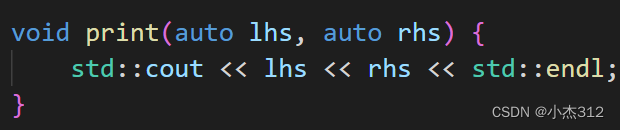
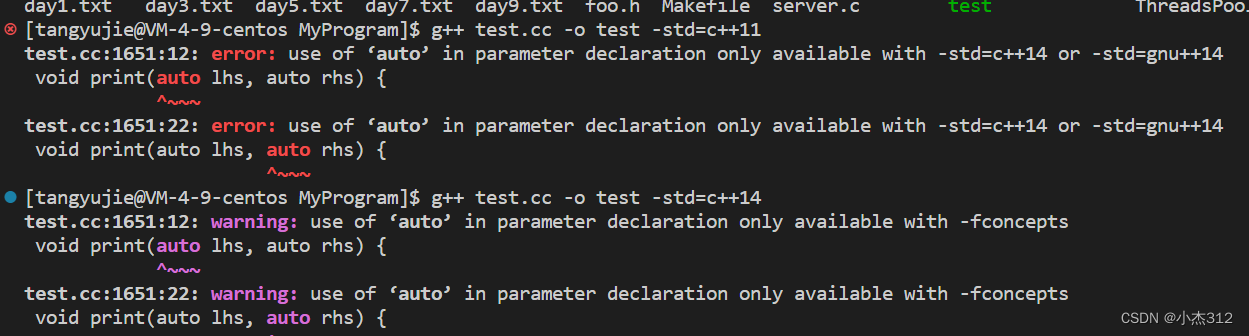
以前declype在很多时候弥补了auto的不足之处,哪个时候auto仅仅只是在编译期间的时候,通过初始化语句的内容进行简单的推导对象类型,很多编译器的功能限制使得auto无能为力。但是现在编译器的强大。使得auto 推导参数了。 甚至也可以推导函数返回值类型了。
编译器可能逐步优化着我们不良编程习惯所带来的低级问题,为我们屏蔽着因为基础不牢靠所带来的各种编程笑话。
decltype 可以推导表达式的结果的类型。用法:decltype(表达式). 在之前,都说的dectype算作是对于auto的一个补充。弥补auto只能在初始化的时候自动推导类型的弊端,在某些场景下我们需要使用decltype来对于表达式的类型进行专门的推导。推断函数返回值类型。 ---- 现在随着编译器的优化,在有些场景下也可以直接使用auto。不使用decltype.
变长参数模板
就是可以支持模板类型的变长参数了. 模板类型是可变长参数包的模板类型.
Ts:相当于是多个T类型的集合.
template <class ... Ts>
void GetArgsNum(Ts ... args) {std::cout << sizeof...(args) << std::endl;
}解参数包的常用手段之递归解包
//最后一个独立参数的解包
template <typename T0 >
void PrintArgs(T0 val) {std::cout << val << std::endl;
}//两个以上参数的解包
template <typename T0, typename ... Ts >
void PrintArgs(T0 val, Ts ... args) {std::cout << val << " ";PrintArgs(args...);
}SmartPointer
智能指针出现的意义:很大程度上减低了内存泄露,野指针的访问。
不带引用计数的智能指针:auto_ptr, unique_ptr
带有引用计数的智能指针:shared_ptr, weak_ptr
std::unique_ptr - cppreference.com
std::shared_ptr - cppreference.com
带不带引用计数,决定了是否可以共享以及管理同一份 资源。 引用计数是一种思维方式,不仅仅可以用在智能指针管理内存资源,好多语言都有它的影子。本质上引用计数的出现是为了节约资源的,避免无谓的拷贝。核心在乎共享。
auto_ptr: 最为危险的,不带引用计数的智能指针,已然是淘汰掉了。原因在乎对拷贝auto_ptr的模糊处理。未禁止它的拷贝构造,而是采取了类似于资源转移,move移动构造的方式。但是没有讲明,界限不明,和move处理一致,但是名头却是左值拷贝。如果不小心误用了拷贝之前的auto_ptr 会直接造成访问nullptr.
unique_ptr:相较于auto_ptr, 禁止了左值拷贝,想来也是,本身就是不带引用计数的智能指针,本就不是干的共享的活。为啥还要支持拷贝??? 难道去支持深拷贝? 疯了吧。所以对于unique_ptr很干脆的禁止了一切的左值拷贝。单单留下了界限明确的 move 操作。针对于将亡右值unique_ptr对象的高效接收操作。

![]()
auto_ptr(auto_ptr<_Tp1>& __a) throw() : _M_ptr(__a.release()) { }make_unique和make_shared,make_unique需要自己写。好处就是必须强制初始化。避免对未初始化的对象的操作。
template <typename T, typename ... Ts>
std::unique_ptr<T> make_unique(Ts&&... args) {//传入参数包对象.return std::unique_ptr<T>(new T(std::forward<Ts>(args)...));
}然后就是带有引用计数的智能指针了, shared_ptr 和 weak_ptr.
weak_ptr是为了解决shared_ptr循环引用的问题而出现的。
1. 为什么shared_ptr最终无法释放,会出现。
本质原因和死锁有几分相似。
智能指针, RAII技术的思想核心:本来我们是想利用栈区对象的局部特性自动释放管理的资源。栈区对象在结束的时候会自动调用析构函数。实现对资源的自动释放。避免资源的泄露。
循环引用为什么就无法释放,答案都知道,循环引用最终引用计数是1, 资源得不到释放。所以问题也就转移成为为什么最终引用计数是1?究竟是哪个引用(智能指针)得不到析构,使得资源得到真正的销毁 ?
(因为智能指针(栈区对象)藏在了堆区资源中。在堆区资源内部,受到堆区资源的保护,这个内部的资源的引用,智能指针,需要外部堆区资源的释放才能解放,但是外部堆区资源同样也受到另外一个堆区资源内部智能指针的管理,同理,这另一个堆区资源内部的智能指针也受到此限制,堆区资源内部的智能指针 和 指向的堆区资源 相互造成死锁)

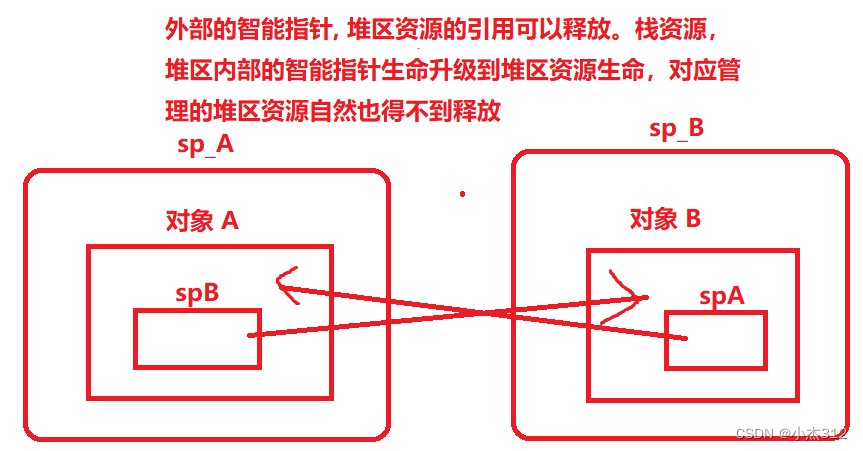
struct A;
struct B;struct A
{std::shared_ptr<B> spB; //成员变量~A(){std::cout << "A被销毁" << std::endl;}
};struct B
{std::shared_ptr<A> spA; //成员变量~B(){std::cout << "B被销毁" << std::endl;}
};int main() {std::shared_ptr<A> sp_A(new A());std::shared_ptr<B> sp_B(new B());sp_A->spB = sp_B;sp_B->spA = sp_A;return 0;
}2. weak_ptr的弱指针,观察性。仅仅观察资源,不增加引用计数。使用的时候可以升级为shared_ptr. 可以破解循环引用的尴尬处境。lock成员函数可以升级。具体可以见文档。
Lambda
匿名函数对象。可不仅仅只是匿名函数如此简单,大大提高了函数的灵活性。可以局部嵌套定义函数对象,相较于全局的函数定义,它的局部性可以使得代码更加简洁优美,更易封装,而且它的闭环特性,可以捕获外部变量的特性也是普通函数所不具备的。
lambda的常用案例:排序...算法操作,作为函数对象function 配合algorithm使用。
std::sort(nums.begin(), nums.end(), [](int a, int b) {return a < b;});作为function参数传入
void ForEach(const std::vector<int > nums, std::function<bool(int)> func) {std::cout << "合理的值: ";for (auto& e: nums) {if(func(e)) {std::cout << e << " ";}}std::cout << std::endl;
}ForEach(arr, [](int val) -> bool {return val > 6;
});Lambda表达式捕获变量
Lambda表达式可以通过捕获变量来获取外部环境中的值,并将其用于Lambda表达式中。捕获变量有两种方式:按值捕获和按引用捕获。
[捕获列表](args) mutable -> returnType{}
&捕获引用,变量名,捕获对应常量拷贝值,加上mutable可以修改,消除const.
多线程 (并发与并行)
并发与并行的概念
并行:并行是指多个任务同时执行,每个任务都有自己的处理器,并且它们在同一时刻执行。
通俗:两个人并列走,两个任务一起进行。就是并行。多个窗口服务,多个人员服务。同时运转。
并发:并发是指多个任务交替执行,在一个时间段内可以看到多个任务同时运行,但是它们可能共享一个或多个处理器,这些处理器按照某种调度算法轮流为这些任务服务。
通俗:一台机器,一个窗口,一个服务员,派发多个任务,但是每个任务根据时间轮转切换执行。
C++11中的并发并行
std::thread对象:线程对象,是C++11中的并发并行基础。创造流水线。流水线是一个载体,承载着相应的服务,和工作任务。所以创建流水线的时候必然需要传入工作任务函数(函数入口,函数指针,function对象,可调用对象)。
void ThreadWork() {std::cout << std::this_thread::get_id() << std::endl;//获取线程id号//do some work;
}int main() {//创建单个线程;std::thread th1(ThreadWork);//创建一个线程数组//初始化方式1, 采用 {} 的统一初始化方式std::thread threads[2] = {std::thread(ThreadWork),std::thread(ThreadWork)}; //set方式2, 先定义,然后采用 operator = 赋值std::thread ths[3];for (int i = 0; i < 3; i ++) {ths[i] = std::thread(ThreadWork);}for (auto &e : threads) {e.join();}for (auto &e : ths) {e.join();}th1.join();return 0;
}软件层面加锁 (为何叫做软件层面加锁?)


实现原理:软件层面实现的,多线程对临界资源的访问。利用软件层面的临界资源(锁,条件变量。。。)控制临界区代码对于全局资源的的互斥写操作。
批注:(多线程访问,注意,多线程,获取了这个互斥量,才能访问互斥量绑定的临界区代码所涉及的全局资源。没有获取的只能进行休眠等待,直到轮到自己获取到互斥量,才能进行访问,存在线程切换,复工复产)
注意区分等待方式:
忙等待,休眠等待 (核心,让不让CPU,不让,忙碌等待,让出休眠等待)
简单来说,就是多个线程,多个流水线,一台生产机器(互斥量/锁)哪个流水线获得这把锁,就可以进行工作,没有获得的流水线则正常休眠/休息。休息的获得机器之后,也不是马上就可以投入生产,需要做好一切准备工作,各个人员到位,原料到位,才能复产(对应线程复原,线程对应的一组寄存器变量复原。)
互斥量 (互斥锁)(休眠锁)
原理:归属于上述的软件层面加锁上。存在大量软件层面的线程间切换。性能问题考虑大量的切换带来的CPU消耗。
和系统调用对比来记忆接口。C++11中的多线程库使用了pthread库的系统调用。
条件变量 (休眠锁)
原理:一般和互斥量配套使用,所以自然也是存在切换的代价。一般用于生产者消费者模型中的通知,平衡生产消费速度。
基础具体使用细节,详见下面的文档,好好利用。
标准库标头 <mutex> - cppreference.com
经典的生产者消费者模型
#include <mutex>
#include <condition_variable>
#include <queue>
#include <thread>//访问临界代码区域的钥匙
static std::condition_variable g_cv;//全局条件变量
static std::mutex g_mtx;//全局锁
static std::queue<int> task_q;//任务队列;
static bool is_running = 1;//是否继续运行//消费者线
static void consumer_routine() {while (1) {{//上锁std::unique_lock<std::mutex> lock(g_mtx);g_cv.wait(lock, []() {return !is_running || !task_q.empty();});if (!is_running) {//停止运行break;}int data = task_q.front();task_q.pop();std::cout << "consume data: " << data << std::endl;}//消费完成之后也可以进行休眠//std::this_thread::sleep_for(std::chrono::milliseconds(100));}
}//生产者线, number 总共生产产品数目
static void producter_routine(int number) {for (int i = 0; i < number; i ++) {{std::unique_lock<std::mutex> lock(g_mtx);//生产操作task_q.push(i);//通知消费g_cv.notify_all();}//生产结束,休眠一会,生产慢一点。, 根据需求调节std::this_thread::sleep_for(std::chrono::milliseconds(100));}//所有产品生产结束,通知停止消费is_running = 0;g_cv.notify_all();
}int main() { //创建线程std::thread consumer_thread(consumer_routine); std::thread producter_thread(producter_routine, 10);//等待回收线程资源consumer_thread.join();producter_thread.join();return 0;
}读写锁 (休眠锁)读读不互斥,读写,写写互斥。提高了读的效率。
自旋锁 (忙等锁)
休眠与忙等:休眠,会让出CPU(存在线程间切换), 忙等,不会让出CPU. (不存在线程间的切换)
软件层面中最为细粒度的锁,也没有线程间切换的代价,因为不是休眠锁。
自旋锁如此的特性:霸占CPU,一直进行忙等待。
其一,适合多核CPU场景。单核CPU的话,容易死锁。
其二:适合处理简单快速完成的任务。太复杂的话,不是一直站着CPU无效忙等。
其三:自旋锁适用于竞争较少的情况,如果竞争太激烈,自旋锁可能会导致CPU资源浪费问题。
class SpinLock {
public:SpinLock() : at_flag(ATOMIC_FLAG_INIT) {}void lock() {//甚至我都想写成trylockwhile(at_flag.test_and_set(std::memory_order_acquire)) ; }void unlock() {//清除标记即可at_flag.clear(std::memory_order_release);}private:std::atomic_flag at_flag;
};atomic_flag的test_and_set函数是一个原子操作,可以保证在多线程环境下对atomic_flag变量的访问是安全的。该函数的返回值是之前atomic_flag变量的值,同时将atomic_flag变量设置为true。如果之前atomic_flag变量的值为false,则函数返回false,并将atomic_flag变量设置为true;如果之前atomic_flag变量的值为true,则函数返回true,并不会改变atomic_flag变量的值。因此,test_and_set函数主要用于实现互斥锁和自旋锁等同步机制
std::atomic_flag - cppreference.com
CAS原子操作 (软件层面无锁,硬件层面加锁)
原理:原子操作,也叫做 Compare And Swap 操作。利用底层多条汇编指令的绑定成原子。要不全执行,要不不执行。
Intel X86指令集提供了指令前缀lock⽤于锁定前端串⾏总线FSB,保证了指令执⾏时不会收到其他处理器 的⼲扰。(原子操作实现原理)
在计算机硬件方面,原子操作通常使用CPU的特殊指令来实现。这些特殊指令被称为“原子指令”。例如,在x86架构的CPU中,有一个lock前缀指令可以保证某个内存地址在执行期间不会被其他线程修改。当CPU执行这个指令时,它会将总线锁定并阻止其他CPU访问该内存地址,然后对该内存地址进行读取或写入操作。只有当当前CPU完成了操作并释放了总线锁定时,其他CPU才能访问该内存地址。
(锁定操作一块内存的过程中,不支持并发操作。从硬件上杜绝并发,自然也就不存在线程间切换。主要是硬件提供的锁定操作。软件层面无锁。)
static int lxx_atomic_add(int *ptr, int increment) {int old_value = *ptr;__asm__ volatile("lock; xadd %0, %1 \n\t": "=r"(old_value), "=m"(*ptr): "0"(increment), "m"(*ptr): "cc", "memory");return *ptr;
}
原子操作的局限性。很明显原子操作需要硬件提供支持,很明显,只能针对支持的简单操作可以直接使用原子操作。一般是针对一块内存的一个硬件锁定操作。
在C++11中,提供了一个自旋锁的实现对象,叫做atomic_flag; 原理就是一直不停的查询一块内存是否被标记为使用,如果标记为使用,则说明自旋锁正在被一个线程使用中,自然本线程就需要不停的自旋循环试探,尝试获取自旋锁。自旋锁,就是一个原子标记.
std::atomic - cppreference.com
核心是下属这个。理解这个即可 。


#include <atomic>
std::atomic<int> g_at_val;void testAdd(int& expected) {if (g_at_val.compare_exchange_strong(expected, expected + 1)) {std::cout << "修改成功" << std::endl;std::cout << "store_val: " << g_at_val.load() << std::endl;} else {std::cout << "修改失败" << std::endl;std::cout << "store_val: " << g_at_val.load() << std::endl;}}int main() { int excepted = g_at_val.load() + 1;//failure, excepted 修改成 memory real store_val;testAdd(excepted);//success memory real store_val ++;testAdd(excepted);return 0;
}该项API常常配合实现无锁数据结构 , 核心利用他的原子更新性质。以达到多线程插入删除操作的安全性,原子性。
各种数据结构多线程下的不安全性就在于,插入删除操作,插入,删除操作的核心几乎又是在容器首部,尾部。。。的操作,那很简单,我们利用原子性的外壳包装插入删除时候需要修改的结点即可。
无锁栈实现
template <typename T >
class LockFreeStack { //无锁队列,利用atomic实现
private:struct Node {T val;//OR dataNode* next;Node(const T& _val, Node* _next = nullptr) : val(_val), next(_next) {}};//栈顶指针headstd::atomic<Node* > head;
public:LockFreeStack() : head(nullptr) {}//利用head结点的原子性操作来实现push和pop原子操作void push(const T& val) {Node *old_head = head.load();Node *new_head = new Node(val, old_head);while (!head.compare_exchange_weak(old_head, new_head));//原子交换栈顶, 这才是真正意义上的插入}//空栈就无法弹出,so, 弹出maybe failure but no error.bool pop(T& val) {//传出参数带出栈顶对象Node *old_head = head.load();while (old_head && !head.compare_exchange_weak(old_head, old_head->next));//原子弹出操作if (old_head) {//获取弹出栈顶数据val = old_head->val;delete old_head;return true;}return false;}
} ;