-1)GeForce RTX 4090
GeForce RTX 4090
| GPU 引擎规格: | NVIDIA CUDA® 核心数量 | 16384 |
| 加速频率 (GHz) | 2.52 | |
| 基础频率 (GHz) | 2.23 | |
| 显存规格: | 标准显存配置 | 24 GB GDDR6X |
| 显存位宽 | 384 位 | |
| 技术支持: | Ray Tracing Core | 第 3 代 |
| Tensor Cores | 第 4 代 | |
| NVIDIA 架构 | Ada Lovelace | |
| 支持 NVIDIA DLSS | 3 | |
| 支持 NVIDIA Reflex | 是 | |
| 支持 NVIDIA Broadcast | 是 | |
| 支持 PCI Express 第 4 代 | 是 | |
| 支持 Resizable BAR | 是 | |
| 支持 NVIDIA® GeForce Experience™ | 是 | |
| 支持 NVIDIA Ansel | 是 | |
| 支持 NVIDIA FreeStyle | 是 | |
| 支持 NVIDIA ShadowPlay | 是 | |
| 支持 NVIDIA Highlights | 是 | |
| 支持 NVIDIA G-SYNC® | 是 | |
| Game Ready 驱动 | 是 | |
| 支持 NVIDIA Studio 驱动 | 是 | |
| NVIDIA Omniverse | 是 | |
| 支持 Microsoft DirectX® 12 Ultimate | 是 | |
| 支持 NVIDIA GPU Boost™ | 是 | |
| 支持 NVIDIA NVLink™ (SLI-Ready) | 否 | |
| 支持 Vulkan RT API, OpenGL 4.6 | 是 | |
| NVIDIA 编码器 (NVENC) | 2x 8th Generation | |
| NVIDIA 解码器 (NVDEC) | 5th Generation | |
| AV1 编码 | 是 | |
| AV1 解码 | 是 | |
| CUDA 能力 | 8.9 | |
| 支持 VR Ready | 是 | |
| 显示器支持: | 最高数字分辨率和刷新率 (1) | 4K 240Hz 或借助DSC技术支持,显示8K 60Hz HDR效果 |
| 标准显示器接口 | HDMI(2), 3x DisplayPort(3) | |
| 可支持的多显示器数 | 4(5) | |
| HDCP | 2.3 | |
| 显卡尺寸: | 长度 | 304 mm |
| 宽度 | 137 mm | |
| 插槽 | 3 插槽 (61mm) | |
| 温度和功率规格: | 最高 GPU 温度 (℃) | 90 |
| 显卡功率 (W) | 450 W | |
| 要求的系统功率 (W) (4) | 850 W | |
| 辅助电源接口 | 3 x PCIe 8-pin 转接线(附赠适配器)或 1 根支持 450W 及更大额定功率的第 5 代 PCIe 接口电源线 |
0)GeForce RTX 3090显卡,好像没有单双精度数据?
| GeForce RTX 3090 Ti | GeForce RTX 3090 | ||
|---|---|---|---|
| GPU 引擎规格: | NVIDIA CUDA® 核心数量 | 10752 | 10496 |
| 加速频率 (GHz) | 1.86 | 1.70 | |
| 基础频率 (GHz) | 1.67 | 1.40 | |
| 显存规格: | 标准显存配置 | 24 GB GDDR6X | 24 GB GDDR6X |
| 显存位宽 | 384 位 | 384 位 | |
| 技术支持: | RT Core | 第 2 代 | 第 2 代 |
| Tensor Cores | 第 3 代 | 第 3 代 | |
| NVIDIA 架构 | Ampere | Ampere | |
| Microsoft DirectX® 12 Ultimate | 是 | 是 | |
| NVIDIA DLSS | 是 | 是 | |
| NVIDIA Reflex | 是 | 是 | |
| NVIDIA Broadcast | 是 | 是 | |
| PCI Express 第 4 代 | 是 | 是 | |
| Resizable BAR | 是 | 是 | |
| NVIDIA® GeForce Experience™ | 是 | 是 | |
| NVIDIA Ansel | 是 | 是 | |
| NVIDIA FreeStyle | 是 | 是 | |
| NVIDIA ShadowPlay | 是 | 是 | |
| NVIDIA Highlights | 是 | 是 | |
| NVIDIA G-SYNC® | 是 | 是 | |
| 支持 Game Ready 驱动程序 | 是 | 是 | |
| NVIDIA Studio 驱动 | 是 | 是 | |
| NVIDIA Omniverse | 是 | 是 | |
| NVIDIA GPU Boost™ | 是 | 是 | |
| NVIDIA NVLink™ (SLI-Ready) | 是 | 是 | |
| Vulkan RT API、OpenGL 4.6 | 是 | 是 | |
| HDMI 2.1 | 是 | 是 | |
| DisplayPort 1.4a | 是 | 是 | |
| NVIDIA 编码器 | 第 7 代 | 第 7 代 | |
| NVIDIA 解码器 | 第 5 代 | 第 5 代 | |
| CUDA 能力 | 8.6 | 8.6 | |
| VR Ready | 是 | 是 | |
| 显示支持: | 最高数字分辨率 (1) | 7680x4320 | 7680x4320 |
| 标准显示器接口 | HDMI(2), 3x DisplayPort(3) | HDMI(2), 3x DisplayPort(3) | |
| 可支持的多显示器数 | 4 | 4 | |
| HDCP | 2.3 | 2.3 | |
| Founders Edition 显卡尺寸: | 长度 | 12.3" (313 mm) | 12.3" (313 mm) |
| 宽度 | 5.4" (138 mm) | 5.4" (138 mm) | |
| 高度 | 3 插槽 | 3 插槽 | |
| Founders Edition 热功率规格: | 最高 GPU 温度 (℃) | 92 | 93 |
| 显卡功率 (W) | 450 | 350 | |
| 推荐系统功率 (W) (2) | 850 | 750 | |
| 辅助电源接口 | 3 个 PCIe 8-Pin 辅助供电接口(盒装适配器)或负载可达 450W 或更高的第五代 PCIe 接口 | 2 个 PCIe 8-Pin 接口 |
1)
A40:
The NVIDIA A40 accelerates the most demanding visual computing workloads from the data center, combining the latest NVIDIA Ampere architecture RT Cores, Tensor Cores, and CUDA® Cores with 48 GB of graphics memory. From powerful virtual workstations accessible from anywhere to dedicated render nodes, NVIDIA A40 brings nextgeneration NVIDIA RTX™ technology to the data center for the most advanced professional visualization workloads.
居然没有单双精度。
带宽也不行。

2)
A30:
Built for AI inference at scale, the same compute resource can rapidly re-train AI models with TF32, as well as accelerate high-performance computing (HPC) applications using FP64 Tensor Cores. Multi-Instance GPU (MIG) and FP64 Tensor Cores combine with fast 933 gigabytes per second (GB/s) of memory bandwidth in a low 165W power envelope, all running on a PCIe card optimal for mainstream servers.

3)A100
NVIDIA A100 GPU采用全新Ampere安培架构的超大核心GA100,7nm工艺,542亿晶体管,826平方毫米面积,6912个核心,搭载5120-bit 40/80GB HBM2显存,带宽近1.6TB/s,功耗400W。
NVIDIA A100 Tensor Core GPU 可在各个规模下为 AI、数据分析 和高性能计算(HPC)应用提供出色的加速性能,为全球的 高性能弹性数据中心提供强劲助力。作为 NVIDIA 数据中心平台 的引擎,与前一代 NVIDIA Volta™ 相比,A100 可使性能提升高达 20 倍。A100 可高效扩展,也可借助多实例 GPU (MIG)技术划分 为 7 个独立的 GPU 实例,从而提供统一的平台,助力弹性数据中 心根据不断变化的工作负载需求动态进行调整。 NVIDIA A100 Tensor Core 技术支持广泛的数学精度,可针对每个 工作负载提供单个加速器。最新一代 A100 80GB 将 GPU 显存 加倍,提供 2TB/s 的全球超快显存带宽,可加速处理超大型模型 和海量数据集。 A100 是完整 NVIDIA 数据中心解决方案的一部分,该解决方案由 硬件、网络、软件、库以及 NGC™ 目录中经优化的 AI 模型和 应用等叠加而成。作为适用于数据中心且功能强大的端到端 AI 和 HPC 平台,A100 可助力研究人员获得真实的结果,并能将解决 方案大规模部署到生产环境中。
可惜不让在中国卖,万恶的鬼佬。

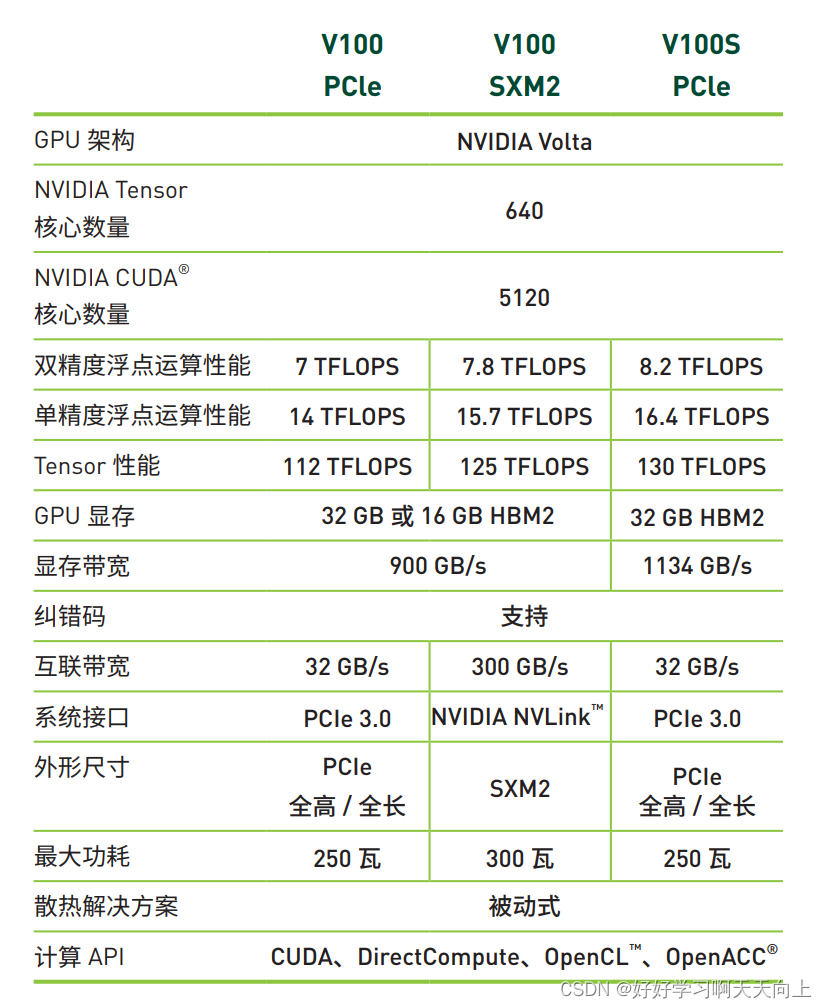
4)V100
NVIDIA® V100 Tensor Core GPU 是深度学习、机器学习、 高性能计算 (HPC) 和图形计算的强力加速器。V100 Tensor Core GPU 采用 NVIDIA Volta™ 架构,可在单个 GPU 中提供近 32 个 CPU 的性能,助力研究人员攻克以前无法应对的挑战。 V100 已在业界首个 AI 基准测试 MLPerf 中拔得头筹,以出色 的成绩证明了其是具有巨大可扩展性和通用性的当今世界上 强大的计算平台。
比A100差不些,但是比A30好一些。
美国人脑壳也是逗比
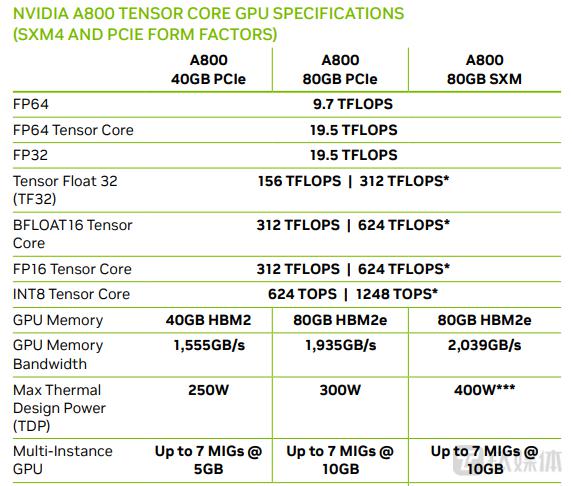
5)A800
NVIDIA将面向中国用户推出新的A800 GPU,用于替代A100,其符合美政府出口管制政策。根据美政府的政策,用于出口的芯片数据传输率不得超过600GB/s,NVIDIA A800则设定在400GB/s。但其他规格尚不清楚,比如核心数量、运行频率、显存、功耗等。
,英伟达和 AMD 就表示,包括英伟达的数据中心芯片 A100 和 H100 等产品,被美国商务部列入出口管制清单。
而据英伟达的说法,新的 A800 可以替代 A100,两者都是 GPU(图形处理单元)处理器。芯片经销商 OMNISKY 容天官网介绍的英伟达 A800 GPU 信息显示,新的芯片数据传输速率为每秒 400GB,低于 A100 的每秒 600GB,代表了数据中心的性能明显下降。而且,A800 支持内存带宽最高达 2TB/s,其他参数变化不大。
6)炸裂的H100
NVIDIA H100是一个整体NVIDIA数据中心的一部分站台为AI、HPC和数据构建分析,平台加速
超过3000个应用程序,并且数据无处不在从中心到边缘,同时提供显著的性能提升和节省成本的机会。

双精度性能达到34TFlops了!天啊
FP16达到2TFlops,间接是AI怪兽!
访存带宽达到3.35TB
NVLINK带宽达到900 GB/s,天啊