文章目录
- 前言
- 一、Anaconda安装
- 二、Pytorch 与 TensorFlow 环境配置
- 三、TensorRT 推理引擎配置
- 总结
前言

Jetson Nano是一款由NVIDIA推出的小型计算机,其性能优异、功耗低、体积小巧,非常适合用于嵌入式系统和边缘设备的深度学习应用。Jetson Nano搭载了NVIDIA的Tegra X1处理器,拥有4个ARM Cortex-A57 CPU核心和128个NVIDIA Maxwell GPU核心,可以提供高达472GFLOPS的运算能力,能够实现实时的深度学习推理。
Jetson Nano支持多种深度学习框架,如TensorFlow、PyTorch、Caffe和MXNet等,可以通过安装相应的软件包来进行深度学习模型训练和推理。Jetson Nano还提供了丰富的硬件接口,如GPIO、I2C、SPI、UART和CSI等,可以方便地连接各种传感器和执行器,实现智能化控制和数据采集。
一、Anaconda安装
首先安装Anaconda是为了解决一个环境冲突的问题,因为ROS的功能包都是基于Python2.7去开发的,而目前主流的深度学习框架都是基于Python3去开发的,不同的Python版本间会导致兼容性问题引来一堆报错,所以最好的解决办法是在Anaconda里面创建一个Python3的虚拟环境,里面运行深度学习的主流框架,这样才不会和ROS冲突
有很多博客说需要先安装ROS,再安装Anaconda,刚好我也是先安装了ROS Melodic,还没装Anaconda3
Anaconda的官网:https://www.anaconda.com/products/individual
其他版本:https://repo.anaconda.com/archive/
下载Anaconda3-2022.05-Linux-aarch64.sh,下载到的目录为/home/nvidia/,在此目录下打开终端,运行.sh文件
bash Anaconda3-2022.05-Linux-aarch64.sh
接下来就是一路回车确认,遇到需要 yes/no 的地方选择 yes。安装完成后,编辑 ~/.bashrc里面配置conda的环境变量,在 ~/.bashrc 文件后面加入下面的东西
sudo vim ~/.bashrc
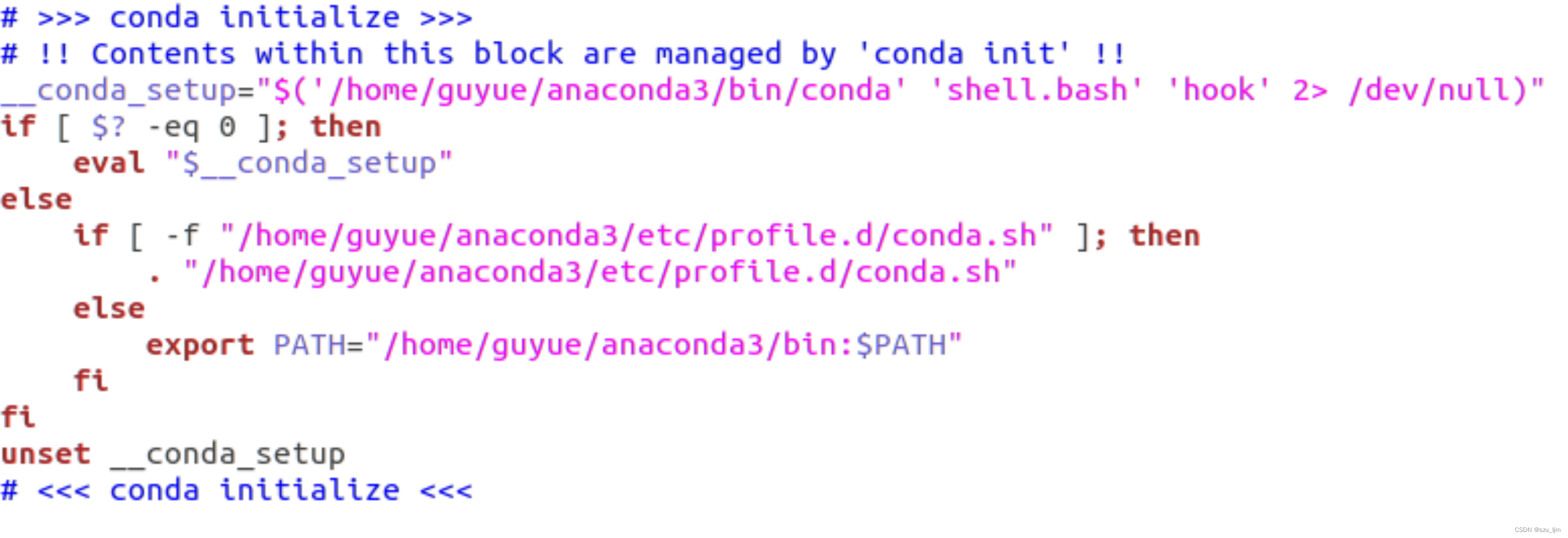
再source一下环境变量
source ~/.bashrc
打开终端,检查conda版本,如果成功显示conda版本信息,就说明Anaconda已经安装好了
conda --version
但是这样的话会和ROS冲突,因为Anaconda3也是基于Python3的开发环境,所以还要把之前在~/.bashrc 文件里面配置的注释掉
sudo vim ~/.bashrc

source ~/.bashrc
重新打开终端,然后启动Anaconda3环境,查看Python版本,不管在终端输入Python和Python3的版本,环境里只会出现Python3版本号,这个虚拟环境不会受到Python2.7的影响
source ~/anaconda3/bin/activate
运行下面命令可以关闭Anaconda虚拟环境
conda deactivate
二、Pytorch 与 TensorFlow 环境配置

TensorFlow和PyTorch都是目前非常流行的深度学习框架,它们都提供了丰富的工具和API来帮助开发者快速构建、训练和部署深度学习模型。
TensorFlow是由Google开发的开源深度学习框架,它具有广泛的应用和社区支持。TensorFlow主要基于静态计算图的方式进行计算,可以在多个设备上进行分布式计算,支持GPU加速,使得它非常适合大规模的深度学习任务。TensorFlow还提供了高级API,如Keras,以及可视化工具TensorBoard等,使得模型的构建和调试变得更加简单。
PyTorch是由Facebook开发的开源深度学习框架,它是一种动态计算图框架,可以更加灵活地构建和调试深度学习模型。PyTorch也支持GPU加速和分布式计算,并且提供了许多高级API和工具,如torchvision和torchaudio等,使得模型的构建和训练变得更加简单。
相比之下,TensorFlow更适合于大规模的深度学习任务,例如图像分类和自然语言处理。而PyTorch则更适合于研究型的深度学习任务,例如新模型的探索和实验。
首先安装TensorFlow之前,要先创建一个Python3的虚拟环境,打开终端
conda create -n mydl python=3.6
激活刚刚创建的虚拟环境
conda activate mydl
按照英伟达官方教程来,我的Jetson Nano 的 JetPack版本为4.6.3,Python版本为3.6,先安装一些工具和依赖项
https://forums.developer.nvidia.com/t/official-tensorflow-for-jetson-agx-xavier/65523
pip3 install -U pip testresources setuptools
安装numpy、keras等常用的数据分析、机器学习库
pip3 install -U numpy==1.19.4 future mock keras_preprocessing keras_applications gast==0.2.1 protobuf pybind11 cython pkgconfig packaging
从英伟达官网下载优化过的TensorFlow框架
pip3 install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v461 tensorflow
接着创建Pytorch环境(1.10版本)
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
安装好后,测试一下有没有安装成功,在终端打开python3输入界面
python3
导入tensorflow包,如果没有报错那就说明tensorflow安装成功
import tensorflow as tf
导入pytorch包,如果没有报错那就说明pytorch安装成功
import torch
import torchvision# 该指令显示pytorch版本
print(torch.__version__)# 若cuda已安装,将显示true
torch.cuda.is_available()
若cuda已安装且配置好,将显示true
三、TensorRT 推理引擎配置
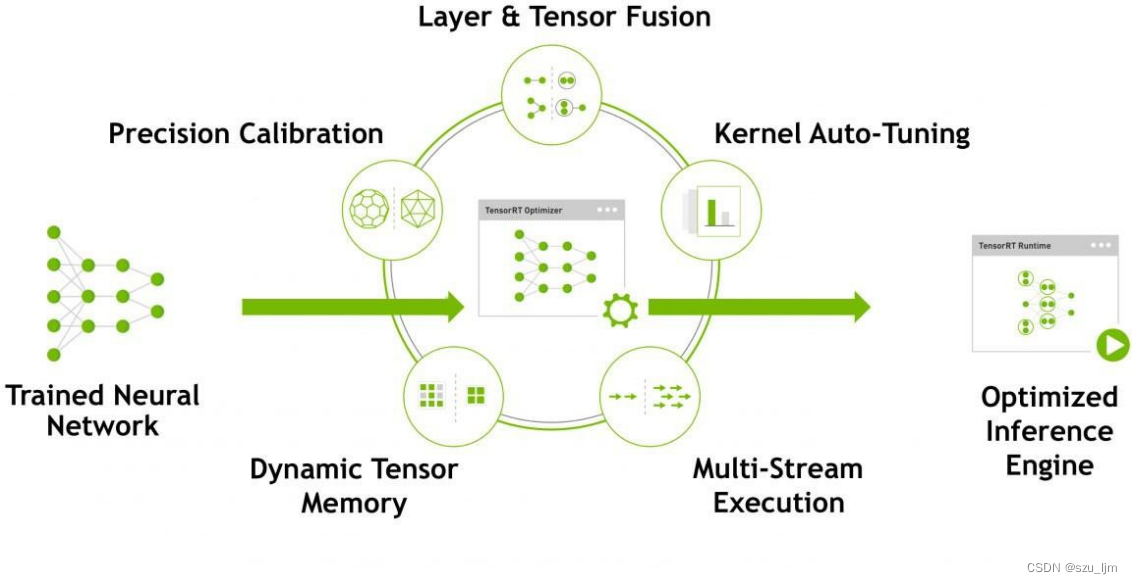
NVIDIA TensorRT是一种深度学习推理引擎,可优化和加速用于生产环境的深度学习推理应用程序。它使用深度学习模型优化和加速推理,从而提高模型的推理性能和效率。
TensorRT可以自动分析深度学习模型,并对其进行优化,以提高推理性能。这些优化包括网络剪枝、层融合、内存优化和精度混合等技术。此外,TensorRT还支持将深度学习模型转换为高度优化的TensorRT引擎格式,以便在生产环境中进行部署。
TensorRT还提供了一组用于编程和性能调优的API,以及与TensorFlow、Caffe和ONNX等流行的深度学习框架的集成。TensorRT优化后的模型可以实现更快的推理速度,减少延迟,提高吞吐量;TensorRT自动进行优化和加速的过程,减少了手动优化的工作量和时间;TensorRT具有高度可靠性和稳定性,已经被广泛应用于各种计算机视觉和自然语言处理应用程序中;TensorRT提供了易于使用的API和集成,以便开发人员轻松地将其应用于现有的深度学习应用程序中。
Jetson Nano的官方文档中给我们推荐了二个例子,其中一个使用Tensor RT做物品识别的例子。具体的可以参考英伟达jetson-inference例子。存放这些模型的服务器被墙了,所以只能将之前下载好的包远程传输到对应的下载目录下。
首先如果您没有安装git和cmake,先安装它们
sudo apt-get install git cmake
接着从git上克隆jetson-inference 库
git clone https://github.com/dusty-nv/jetson-inference
进入文件夹jetson-inference
cd jetson-inference
这里我没有用科学上网的方式下载模型,我直接把模型远程传入Jetson Nano。操作如下:
1)编辑jetson-inference/CMakePrebuild.sh。把./download-models.sh注释掉,(前面加个#注释)
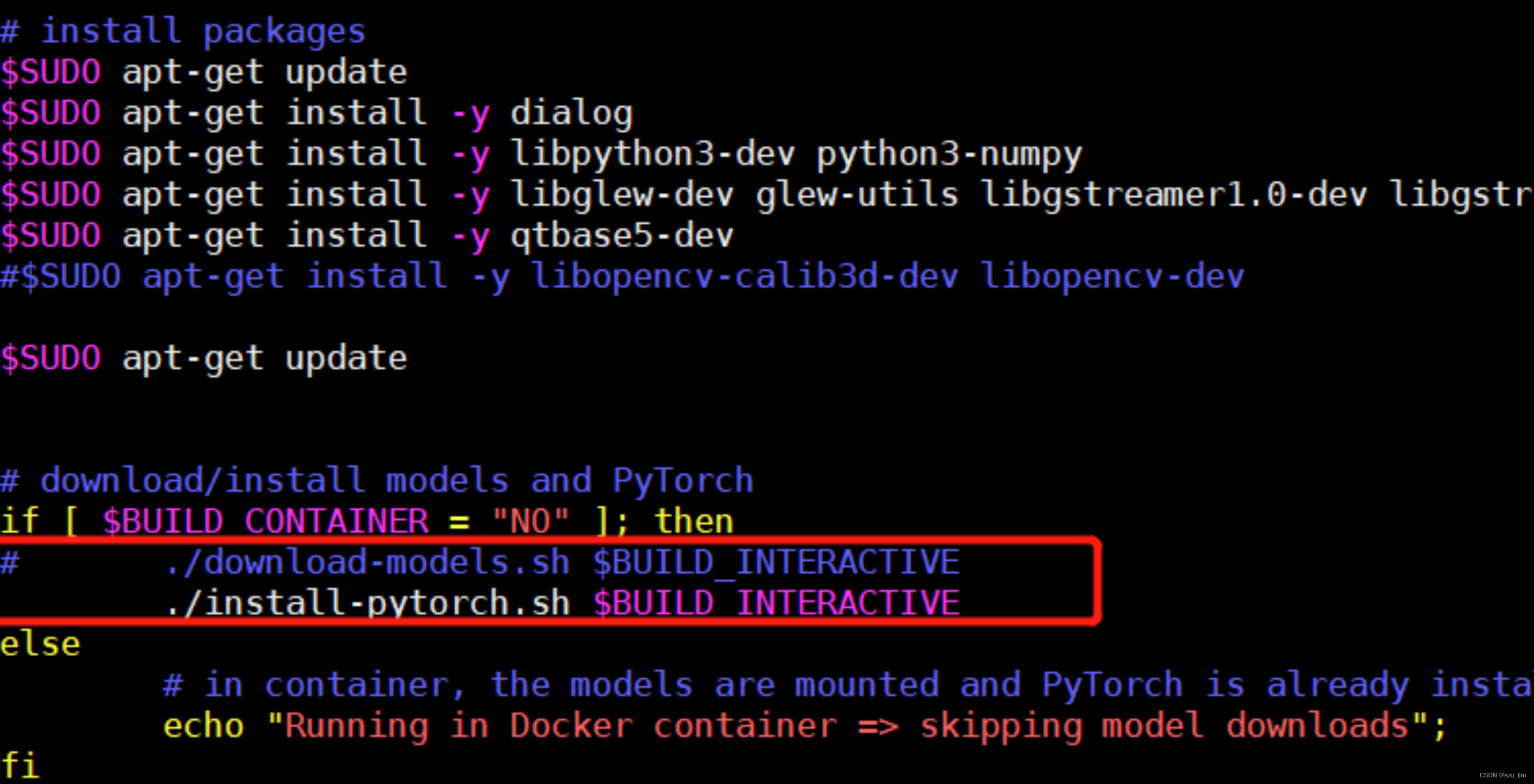
2)把模型远程传输到data/networks目录
新建build文件夹,用来存放编译文件
mkdir build #创建build文件夹
进入文件夹
cd build #进入build
运行cmake
cmake ../ #运行cmake,它会自动执行上一级目录下面的 CMakePrebuild.sh
然后在此目录执行解压:
for tar in *.tar.gz; do tar xvf $tar; done
cmake成功后,就需要编译了,进入build文件夹
cd jetson-inference/build
开始编译
make (或者make -j4) //注意:(在build目录下)
// 这里的 make 不用 sudo
// 后面 -j4 使用 4 个 CPU 核同时编译,缩短时间
如果编译成功,会生成下列文件夹结构

开始测试,测试图像识别结果
cd jetson-inference/build/aarch64/bin
导入图片进行识别
./imagenet-console ./images/bird_0.jpg output_wyk.jpg
总结
以上就是本篇笔记的全部内容。深度学习是当今最热门的技术之一,已经被广泛应用于计算机视觉、自然语言处理、语音识别等领域。在深度学习应用中,通常需要大量的计算资源和算法支持,这就需要配置适当的深度学习环境。
深度学习环境的配置包括安装各种深度学习框架、GPU驱动程序、CUDA和cuDNN等库和工具。正确配置深度学习环境可以使得深度学习算法的开发和调试变得更加方便和高效。同时,在使用GPU加速深度学习时,合适的深度学习环境也可以提高计算速度和资源利用率,加快算法的训练和推理速度。