? 算法:第一步:选K个初始聚类中心,z1(1),z2(1),…,zK(1),其中括号内的序号为寻找聚类中心的迭代运算的次序号。聚类中心的向量值可任意设定,例如可选开始的K个.
k均值聚类:---------一种硬聚类算法,隶属度只有两个取值0或1,提出的基本根据是“类内误差平方和最小化”准则; 模糊的c均值聚类算法:-------- 一种模糊聚类算法,是.
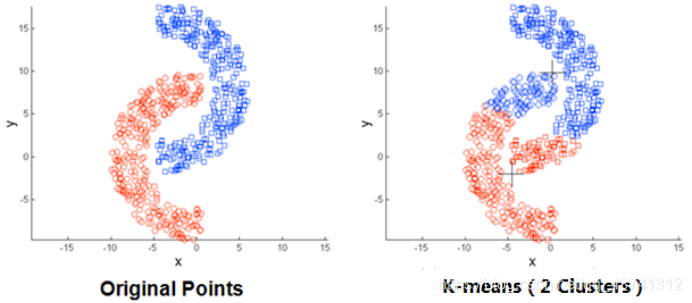
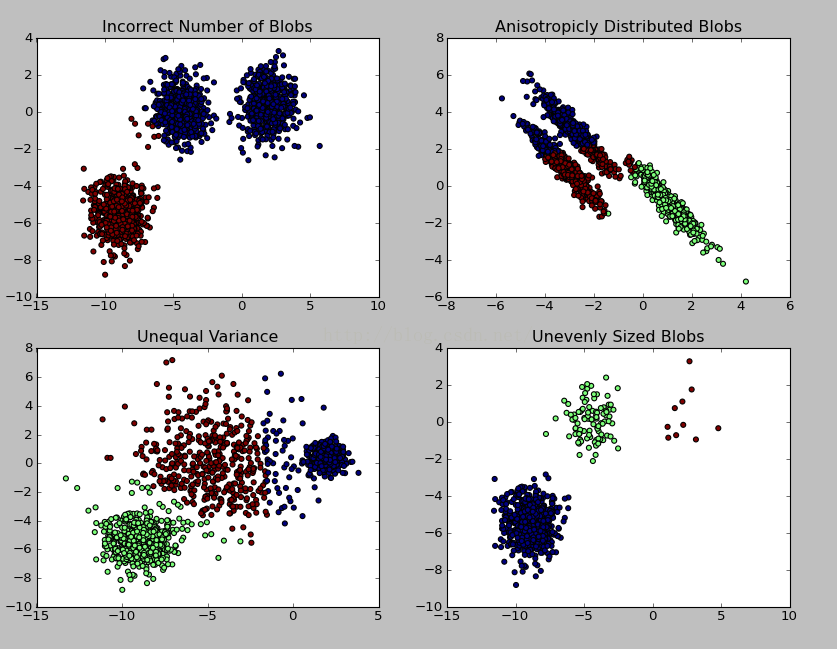
K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及.
#include <stdio.h> #include <math.h>#define TRUE 1#define FALSE 0 int N. //初始化K个簇集合}/*算法描述:K均值算法: 给定类的个数K,将N个对象分到K个类.
k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似.
用k均值算法给出 : 在第一轮执行后的三个簇中心点为多少? 2.最后的三个簇。
第一轮 A1(2,10) B1(5,8),A3(8,4), B2(7,5),B3(6,4),C2(4,9) C1(1,2),A2(2,5) 对应中心分别是(2,10),(6,6),(1.5, 3.5) 最后结果:{A1(2,10),B1(5,8),C2(4,9)} {A3(8,4), B2(7,5).
#include #include #define TRUE 1#define FALSE 0 int N;//数据. //初始化K个簇集合