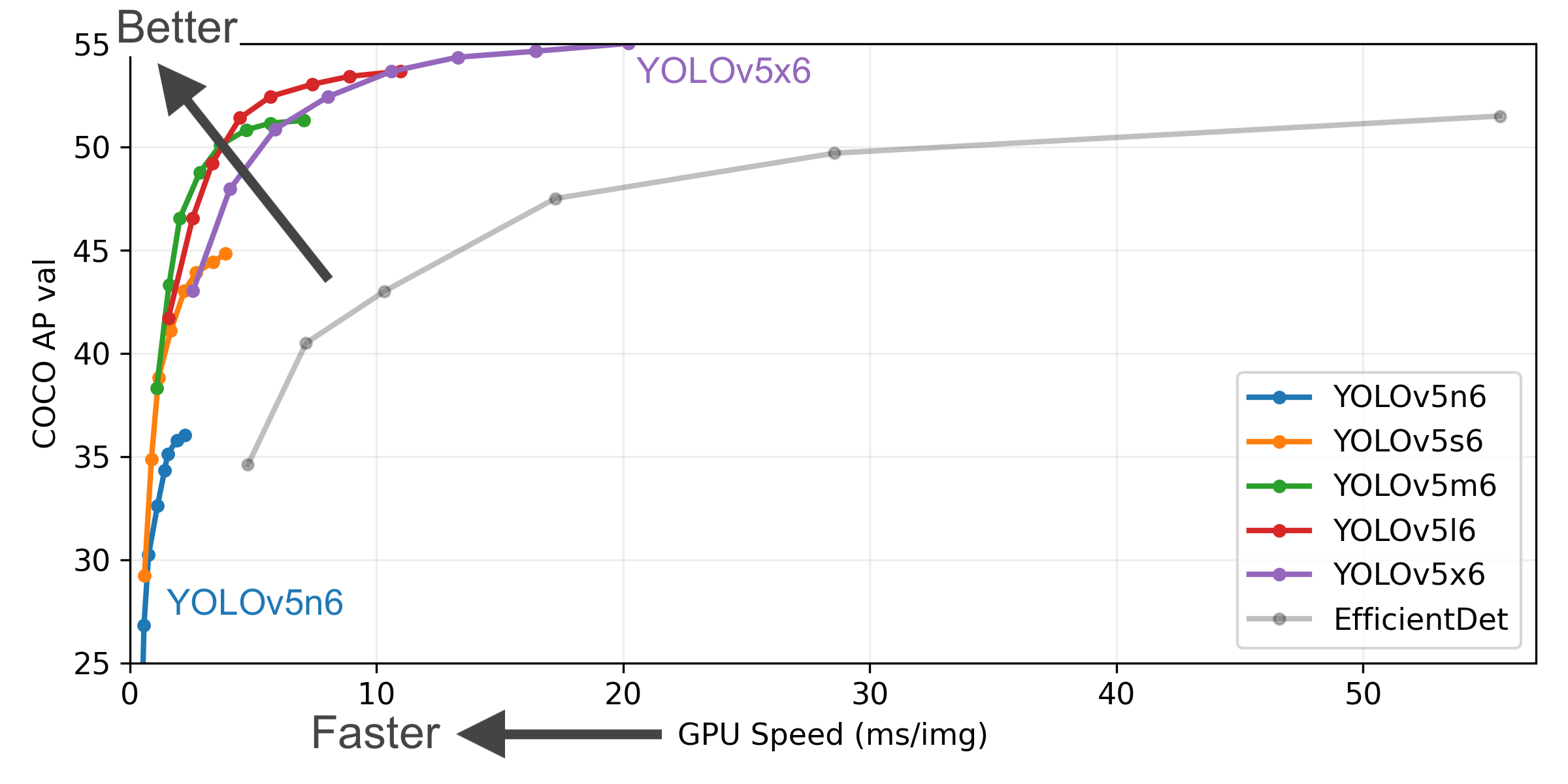
文章目录
- 一、数据准备
- 1.1 YOLOv5 的数据格式
- 1.2 COCO 的数据格式
- 二、YOLOv5 结构介绍
- 2.1 Backbone
- 2.2 Neck
- 2.3 Head
- 三、YOLOv5 的训练过程
- 四、YOLOv5 的预测过程
- 四、如何在 YOLOv5 官方代码(非 MMYOLO)中添加 Swin 作为 backbone,
论文:暂无
代码:https://github.com/ultralytics/yolov5
官方介绍:https://docs.ultralytics.com/
出处:ultralytics 公司
时间:2020.05
YOLOv5 是基于 YOLOv3 改进而来,体积小,YOLOv5 s的权重文件为27MB。
YOLOv4(Darknet架构)的权重文件为244MB。YOLOv5比YOLOv4小近90%。这意味着YOLOv5可以更轻松地部署到嵌入式设备。
此外,因为YOLOv5 是在 PyTorch 中实现的,所以它受益于已建立的 PyTorch 生态系统
YOLOv5 还可以轻松地编译为 ONNX 和 CoreML,因此这也使得部署到移动设备的过程更加简单。
YOLOv5 家族:
- YOLOv5x(最大的模型)
- YOLOv5l
- YOLOv5m
- YOLOv5s(最小的模型)
YOLOv5 优势:
- 使用PyTorch进行编写。
- 可以轻松编译成ONNX和CoreML。
- 速度极快,每秒140FPS。
- 精度超高,可以达到0.895mAP。
- 体积很小:27M。
- 集成了YOLOv3-spp和YOLOv4部分特性
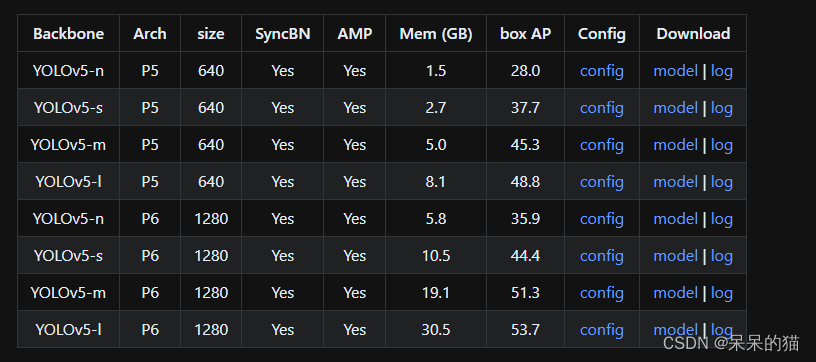
一、数据准备
1.1 YOLOv5 的数据格式
可以下载 coco8 来查看 YOLOv5 需要的具体格式
- images- train- img1.jpg- val- img2.jpg
- labels- train- img1.txt- val- img2.txt
- README.txt
- coco8.yaml
其中,labels 中的 txt 内容示例如下:
类别 x_center y_center width height45 0.479492 0.688771 0.955609 0.5955
45 0.736516 0.247188 0.498875 0.476417
50 0.637063 0.732938 0.494125 0.510583
45 0.339438 0.418896 0.678875 0.7815
49 0.646836 0.132552 0.118047 0.0969375
49 0.773148 0.129802 0.0907344 0.0972292
49 0.668297 0.226906 0.131281 0.146896
49 0.642859 0.0792187 0.148063 0.148062
上面的 5 列数据分别表示框的类别编号(coco 中的类别编号)、框中心点 x 坐标,框中心点 y 坐标,框宽度 w,框高度 h
框的坐标参数如何从 COCO 格式 (x_min, y_min, w, h) 转换为 YOLO 可用的格式 (x_center, y_center, w, h):
- YOLO 中的所有坐标参数都要归一化到 (0, 1) 之间,如下图所示
x_center和width如何从坐标点转换为 0~1 的参数:x_center = x_coco/img_witdh,width = width_coco/img_widthy_center和height如何从坐标点转换为 0~1 的参数:y_center = y_coco/img_height,height = height_coco/img_height

coco8.yaml 内容如下:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)# Classes (80 COCO classes)
names:0: person1: bicycle2: car...77: teddy bear78: hair drier79: toothbrush
下面展示一个方便展示的 coco6 来看看具体形式:
1.2 COCO 的数据格式
coco 的数据标注格式如下:
其中 bbox 对应的四个值分别为: [x_min, y_min, w, h],即左上角点和宽高
{'segmentation': [[510.66, 423.01, 511.72, 420.03, 510.45, 416.0, 510.34, 413.02, 510.77, 410.26, 510.77, 407.5, 510.34, 405.16, 511.51, 402.83, 511.41, 400.49, 510.24, 398.16, 509.39, 397.31, 504.61, 399.22, 502.17, 399.64, 500.89, 401.66, 500.47, 402.08, 499.09, 401.87, 495.79, 401.98, 490.59, 401.77, 488.79, 401.77, 485.39, 398.58, 483.9, 397.31, 481.56, 396.35, 478.48, 395.93, 476.68, 396.03, 475.4, 396.77, 473.92, 398.79, 473.28, 399.96, 473.49, 401.87, 474.56, 403.47, 473.07, 405.59, 473.39, 407.71, 476.68, 409.41, 479.23, 409.73, 481.56, 410.69, 480.4, 411.85, 481.35, 414.93, 479.86, 418.65, 477.32, 420.03, 476.04, 422.58, 479.02, 422.58, 480.29, 423.01, 483.79, 419.93, 486.66, 416.21, 490.06, 415.57, 492.18, 416.85, 491.65, 420.24, 492.82, 422.9, 493.56, 424.39, 496.43, 424.6, 498.02, 423.01, 498.13, 421.31, 497.07, 420.03, 497.07, 415.15, 496.33, 414.51, 501.1, 411.96, 502.06, 411.32, 503.02, 415.04, 503.33, 418.12, 501.1, 420.24, 498.98, 421.63, 500.47, 424.39, 505.03, 423.32, 506.2, 421.31, 507.69, 419.5, 506.31, 423.32, 510.03, 423.01, 510.45, 423.01]], 'area': 702.1057499999998, 'iscrowd': 0, 'image_id': 289343, 'bbox': [473.07, 395.93, 38.65, 28.67], 'category_id': 18, 'id': 1768
}
下面的代码可以实现将 COCO 数据标注格式转换为 YOLOv5 需要的训练格式:
import os
import json
from pathlib import Pathdef coco2yolov5(coco_json_path, yolo_txt_path):with open(coco_json_path, 'r') as f:info = json.load(f)coco_anno = info["annotations"]coco_images = info["images"]for img in coco_images:img_info = {"file_name": img["file_name"],"img_id": img["id"],"img_width": img["width"],"img_height": img["height"]}for anno in coco_anno:image_id = anno["image_id"]category_id = anno["category_id"]bbox = anno["bbox"]line = str(category_id - 1)if image_id == img_info["img_id"]:txt_name = Path(img_info["file_name"]).name.split('.')[0]yolo_txt = yolo_txt_path + '{}.txt'.format(txt_name)with open(yolo_txt, 'a') as wf:# coco: [x_min, y_min, w, h]yolo_bbox = []yolo_bbox.append(round((bbox[0] + bbox[2]) / img_info["img_width"], 6))yolo_bbox.append(round((bbox[1] + bbox[3]) / img_info["img_height"], 6))yolo_bbox.append(round(bbox[2] / img_info["img_width"], 6))yolo_bbox.append(round(bbox[3] / img_info["img_height"], 6))for bbox in yolo_bbox:line += ' ' + str(bbox)line += '\n'wf.writelines(line)if __name__ == "__main__":coco_json_path = "part1_all_coco.json"yolo_txt_path = "val/"if not os.path.exists(yolo_txt_path):os.makedirs(yolo_txt_path)coco2yolov5(coco_json_path, yolo_txt_path)
二、YOLOv5 结构介绍
此处所说 YOLOv5 为 v6.0 版本,没有 Focus 了,替换成 conv 了,使用 SPPF 代替了 SPP
YOLOv5 模型一共有 4 个版本,分别为:
- YOLOv5s:depth_factor:0.33,widen_factor:0.50 (深度、宽度最小,后面的逐渐加大)
- YOLOv5m:depth_factor:0.67,widen_factor:0.75
- YOLOv5l:depth_factor:1,widen_factor:1
- YOLOv5x:depth_factor:1.33,widen_factor:1.25

- deepen_factor:主要控制 stage 的个数
- widen_factor:主要控制输入输出 channel 的个数
# 下面的 layer 是 csp_darknet 中摘出的一部分代码,主要可以看看 deepen_factor 和 widen_factor 在哪里用到了
def build_stage_layer(self, stage_idx: int, setting: list) -> list:"""Build a stage layer.Args:stage_idx (int): The index of a stage layer.setting (list): The architecture setting of a stage layer."""in_channels, out_channels, num_blocks, add_identity, use_spp = settingin_channels = make_divisible(in_channels, self.widen_factor)out_channels = make_divisible(out_channels, self.widen_factor)num_blocks = make_round(num_blocks, self.deepen_factor)stage = []conv_layer = ConvModule(in_channels,out_channels,kernel_size=3,stride=2,padding=1,norm_cfg=self.norm_cfg,act_cfg=self.act_cfg)stage.append(conv_layer)csp_layer = CSPLayer(out_channels,out_channels,num_blocks=num_blocks,add_identity=add_identity,norm_cfg=self.norm_cfg,act_cfg=self.act_cfg)stage.append(csp_layer)if use_spp:spp = SPPFBottleneck(out_channels,out_channels,kernel_sizes=5,norm_cfg=self.norm_cfg,act_cfg=self.act_cfg)stage.append(spp)return stage
YOLOv5 的框架结构如下:
- Bckbone:CSPDarkNet
- Neck:PA-FPN
- Head:三种尺度,每个尺度的每个特征点上放置 3 种 anchor
下图为原创,如有引用请注明出处。
YOLOv5 模型框架如下:
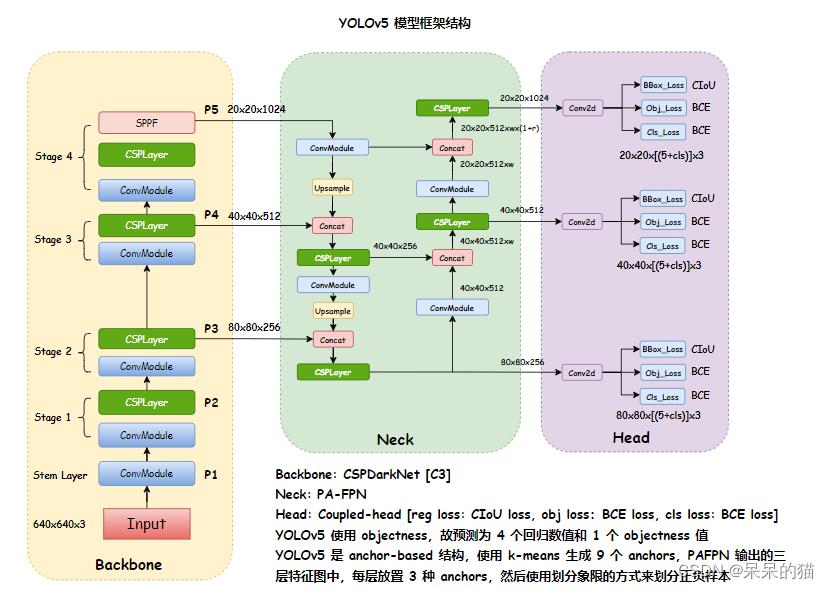
YOLOv5 模块细节如下:
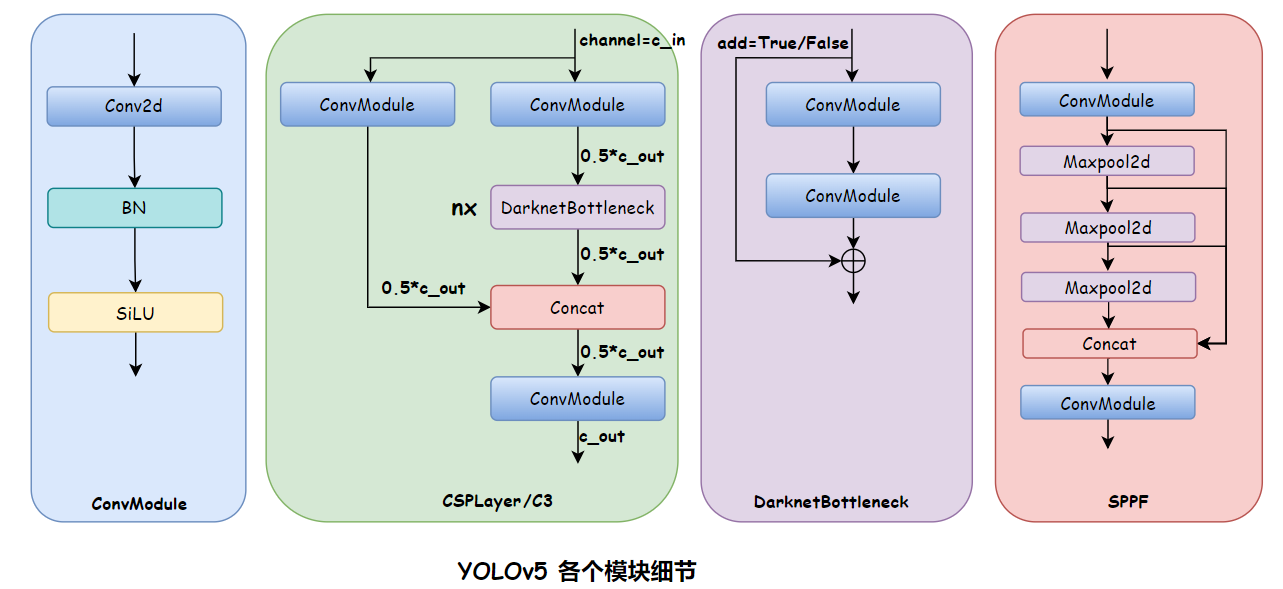
2.1 Backbone
CSPDarkNet
下面代码均出自 MMYOLO
YOLOv5-s 的 config 的 model 内容如下:
deepen_factor = 0.33
widen_factor = 0.5
model = dict(type='YOLODetector',data_preprocessor=dict(type='mmdet.DetDataPreprocessor',mean=[0., 0., 0.],std=[255., 255., 255.],bgr_to_rgb=True),backbone=dict(type='YOLOv5CSPDarknet',deepen_factor=deepen_factor,widen_factor=widen_factor,norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),act_cfg=dict(type='SiLU', inplace=True)),neck=dict(type='YOLOv5PAFPN',deepen_factor=deepen_factor,widen_factor=widen_factor,in_channels=[256, 512, 1024],out_channels=[256, 512, 1024],num_csp_blocks=3,norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),act_cfg=dict(type='SiLU', inplace=True)),bbox_head=dict(type='YOLOv5Head',head_module=dict(type='YOLOv5HeadModule',num_classes=num_classes,in_channels=[256, 512, 1024],widen_factor=widen_factor,featmap_strides=strides,num_base_priors=3),prior_generator=dict(type='mmdet.YOLOAnchorGenerator',base_sizes=anchors,strides=strides),# scaled based on number of detection layersloss_cls=dict(type='mmdet.CrossEntropyLoss',use_sigmoid=True,reduction='mean',loss_weight=0.5 * (num_classes / 80 * 3 / num_det_layers)),loss_bbox=dict(type='IoULoss',iou_mode='ciou',bbox_format='xywh',eps=1e-7,reduction='mean',loss_weight=0.05 * (3 / num_det_layers),return_iou=True),loss_obj=dict(type='mmdet.CrossEntropyLoss',use_sigmoid=True,reduction='mean',loss_weight=1.0 * ((img_scale[0] / 640)**2 * 3 / num_det_layers)),prior_match_thr=4.,obj_level_weights=[4., 1., 0.4]),test_cfg=dict(multi_label=True,nms_pre=30000,score_thr=0.001,nms=dict(type='nms', iou_threshold=0.65),max_per_img=300))
YOLOv5 框架结构:
如何查看模型结构呢:
在 tools/train.py 的 line 109 后面打上断点:
else:# build customized runner from the registry# if 'runner_type' is set in the cfgrunner = RUNNERS.build(cfg)import pdb; pdb.set_trace()# start trainingrunner.train()
然后在终端输入 runner.model 即可拿到模型的结构,由于模型过长,这里简洁整理:
YOLODetector((data_preprocessor): YOLOv5DetDataPreprocessor()(backbone): YOLOv5CSPDarknet()(neck): YOLOv5PAFPN()(bbox_head): YOLOv5Head()
)
Backbone 如下:
(backbone): YOLOv5CSPDarknet((stem): conv(in=3, out=32, size=6x6, s=2, pading=2) + BN + SiLU(stage1): conv(in=32, out=64, size=3X3, s=2, pading=1) + BN + SiLUCSPLayer:conv(in=64, out=32, size=1x1, s=1) + BN + SiLUconv(in=64, out=32, size=1x1, s=1) + BN + SiLUconv(in=64, out=64, size=1x1, s=1) + BN + SiLUDarknetBottleNeck0:conv(in=32, out=32, size=1x1, s=1) + BN + SiLUconv(in=32, out=32, size=3x3, s=1, padding=1) + BN + SiLU(stage2): conv(in=64, out=128, size=3X3, s=2, pading=1) + BN + SiLUCSPLayer:conv(in=128, out=64, size=1x1, s=1) + BN + SiLUconv(in=128, out=64, size=1x1, s=1) + BN + SiLUconv(in=128, out=128, size=1x1, s=1) + BN + SiLUDarknetBottleNeck0:conv(in=64, out=64, size=1x1, s=1) + BN + SiLUconv(in=64, out=64, size=3x3, s=1, padding=1) + BN + SiLU DarknetBottleNeck1:conv(in=64, out=64, size=1x1, s=1) + BN + SiLUconv(in=64, out=64, size=3x3, s=1, padding=1) + BN + SiLU (stage3): conv(in=128, out=256, size=3X3, s=2, pading=1) + BN + SiLUCSPLayer:conv(in=256, out=128, size=1x1, s=1) + BN + SiLUconv(in=256, out=128, size=1x1, s=1) + BN + SiLUconv(in=256, out=128, size=1x1, s=1) + BN + SiLUDarknetBottleNeck0:conv(in=128, out=128, size=1x1, s=1) + BN + SiLUconv(in=128, out=128, size=3x3, s=1, padding=1) + BN + SiLU DarknetBottleNeck1:conv(in=128, out=128, size=1x1, s=1) + BN + SiLUconv(in=128, out=128, size=3x3, s=1, padding=1) + BN + SiLU DarknetBottleNeck2:conv(in=128, out=128, size=1x1, s=1) + BN + SiLUconv(in=128, out=128, size=3x3, s=1, padding=1) + BN + SiLU (stage4): conv(in=256, out=512, size=3X3, s=2, pading=1) + BN + SiLUCSPLayer:conv(in=512, out=256, size=1x1, s=1) + BN + SiLUconv(in=512, out=256, size=1x1, s=1) + BN + SiLUconv(in=512, out=512, size=1x1, s=1) + BN + SiLUDarknetBottleNeck0:conv(in=256, out=256, size=1x1, s=1) + BN + SiLUconv(in=256, out=256, size=3x3, s=1, padding=1) + BN + SiLU SPPF:conv(in=512, out=256, size=1x1, s=1) + BN + SiLUmaxpooling(size=5x5, s=1, padding=2, dilation=1)conv(in=1024, out=512, size=1x1, s=1, padding=1) + BN + SiLU
整个模型框架结构如下:
(backbone): YOLOv5CSPDarknet((stem): ConvModule((conv): Conv2d(3, 32, kernel_size=(6, 6), stride=(2, 2), padding=(2, 2), bias=False)(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(stage1): Sequential((0): ConvModule((conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(1): CSPLayer((main_conv): ConvModule((conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(short_conv): ConvModule((conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(final_conv): ConvModule((conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(blocks): Sequential((0): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))))))(stage2): Sequential((0): ConvModule((conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(1): CSPLayer((main_conv): ConvModule((conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(short_conv): ConvModule((conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(final_conv): ConvModule((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(blocks): Sequential((0): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))(1): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))))))(stage3): Sequential((0): ConvModule((conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(1): CSPLayer((main_conv): ConvModule((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(short_conv): ConvModule((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(final_conv): ConvModule((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(blocks): Sequential((0): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))(1): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))(2): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))))))(stage4): Sequential((0): ConvModule((conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(1): CSPLayer((main_conv): ConvModule((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(short_conv): ConvModule((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(final_conv): ConvModule((conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(blocks): Sequential((0): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))))(2): SPPFBottleneck((conv1): ConvModule((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(poolings): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)(conv2): ConvModule((conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))))(neck): YOLOv5PAFPN((reduce_layers): ModuleList((0): Identity()(1): Identity()(2): ConvModule((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))(upsample_layers): ModuleList((0): Upsample(scale_factor=2.0, mode=nearest)(1): Upsample(scale_factor=2.0, mode=nearest))(top_down_layers): ModuleList((0): Sequential((0): CSPLayer((main_conv): ConvModule((conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(short_conv): ConvModule((conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(final_conv): ConvModule((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(blocks): Sequential((0): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))))(1): ConvModule((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))(1): CSPLayer((main_conv): ConvModule((conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(short_conv): ConvModule((conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(final_conv): ConvModule((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(blocks): Sequential((0): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))))))(downsample_layers): ModuleList((0): ConvModule((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(1): ConvModule((conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))(bottom_up_layers): ModuleList((0): CSPLayer((main_conv): ConvModule((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(short_conv): ConvModule((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(final_conv): ConvModule((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(blocks): Sequential((0): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True)))))(1): CSPLayer((main_conv): ConvModule((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(short_conv): ConvModule((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(final_conv): ConvModule((conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(blocks): Sequential((0): DarknetBottleneck((conv1): ConvModule((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))(conv2): ConvModule((conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)(activate): SiLU(inplace=True))))))(out_layers): ModuleList((0): Identity()(1): Identity()(2): Identity()))(bbox_head): YOLOv5Head((head_module): YOLOv5HeadModule((convs_pred): ModuleList((0): Conv2d(128, 18, kernel_size=(1, 1), stride=(1, 1))(1): Conv2d(256, 18, kernel_size=(1, 1), stride=(1, 1))(2): Conv2d(512, 18, kernel_size=(1, 1), stride=(1, 1))))(loss_cls): CrossEntropyLoss(avg_non_ignore=False)(loss_bbox): IoULoss()(loss_obj): CrossEntropyLoss(avg_non_ignore=False))
)
2.2 Neck
CSP-PAFPN
SPP 和 SPPF:
- SPP:Spatial Pyramid Poolig,是空间金字塔池化,并行的使用不同大小的池化方式,然后将得到的 maxpooling 输出特征图 concat 起来
- SPPF:Spatial Pyramid Poolig Fast,是空间金字塔池化的快速版本,计算量变小的,使用串行的方式,下一个 maxpooling 接收的是上一个 maxpooling 的输出,然后将所有 maxpooling 的输出 concat 起来
import time
import torch
import torch.nn as nnclass SPP(nn.Module):def __init__(self):super().__init__()self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)def forward(self, x):o1 = self.maxpool1(x)o2 = self.maxpool2(x)o3 = self.maxpool3(x)return torch.cat([x, o1, o2, o3], dim=1)class SPPF(nn.Module):def __init__(self):super().__init__()self.maxpool = nn.MaxPool2d(5, 1, padding=2)def forward(self, x):o1 = self.maxpool(x)o2 = self.maxpool(o1)o3 = self.maxpool(o2)return torch.cat([x, o1, o2, o3], dim=1)2.3 Head
YOLOv5 的输出如下:
- 80x80x((5+Ncls)x3):每个特征点上都有 4 个 reg、1 个 置信度、Ncls 个类别得分
- 40x40x((5+Ncls)x3)
- 20x20x((5+Ncls)x3)
YOLOv5 中的 anchor:
# coco 初始设定 anchor 的宽高如下,每个尺度的 head 上放置 3 种 anchor
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32
如何放置 anchor:
- 在 8 倍下采样特征图上(80x80)的每个特征点,分别放置宽高为 (10, 13)、(16, 30)、(33,23) 的 3 种 anchors
- 在 16 倍下采样特征图上(40x40)的每个特征点,分别放置宽高为 (30, 61)、(62, 45)、(59, 119) 的 3 种 anchors
- 在 32 倍下采样特征图上(20x20)的每个特征点,分别放置宽高为 (116, 90)、(156, 198)、(373,326) 的 3 种 anchors
如何进行 anchor 正负的分配:
YOLOv5 是 anchor-based ,一个 gt 由多个特征层中的多个 grid 来负责(一个 gt 可以有 [0, 27] 个 anchors 负责)
- YOLOv5 没有使用 IoU 匹配原则,而是采用了 anchor 和 gt 的宽高比匹配度作为划分规则,同时引入跨邻域网格策略来增加正样本。YOLOv5 不限制每个 gt 只能由某一层的特征图来负责,只要宽高比满足阈值的 anchor,都可以对该 gt 负责。也就是说,YOLOv5 中,一个 gt 可以由多层特征和多个网格来负责,一个 gt 可以对应 [0, 27] 个 anchors。
- 主要包括如下两个核心步骤:
- 首先,统计这些比例和它们倒数之间的最大值,这里可以理解成计算 gt 和 anchor 分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小),宽度比例计算如下的值,如果 r m a x < a n c h o r t h r r^{max} < anchor_{thr} rmax<anchorthr(默认 a n c h o r t h r anchor_{thr} anchorthr 为 4),则判定为正样本,即符合宽高比阈值条件的 anchor 判定为该 gt 的正样本,不符合条件的 anchor 判定为该 gt 的负样本。
- r w = w g t / w a n c h o r r_w = w_{gt} / w_{anchor} rw=wgt/wanchor, r h = h g t / h a n c h o r r_h = h_{gt} / h_{anchor} rh=hgt/hanchor
- r w m a x = m a x { r w , 1 / r w } r_w^{max} = max\{r_w, 1/r_w\} rwmax=max{rw,1/rw}, r h m a x = m a x { r h , 1 / r h } r_h^{max} = max\{r_h, 1/r_h\} rhmax=max{rh,1/rh}
- r m a x = m a x ( r w m a x , r h m a x ) r^{max} = max(r_w^{max}, r_h^{max}) rmax=max(rwmax,rhmax)
- 然后,如果 gt 的中心点落入了某个 grid 的第三象限(grid 是投影到原图中来看的,所以是一个图像块,而非输出 head 特征图上的一个点),则该 grid 的右边和下边的 grid 中,和第一步匹配到的 anchor 的长宽相同的 anchors 也作为正样本。其他三个象限同理,一象限对应左和上,二象限对应上和右,三象限对应右和下,四象限对应左和下。
- 首先,统计这些比例和它们倒数之间的最大值,这里可以理解成计算 gt 和 anchor 分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小),宽度比例计算如下的值,如果 r m a x < a n c h o r t h r r^{max} < anchor_{thr} rmax<anchorthr(默认 a n c h o r t h r anchor_{thr} anchorthr 为 4),则判定为正样本,即符合宽高比阈值条件的 anchor 判定为该 gt 的正样本,不符合条件的 anchor 判定为该 gt 的负样本。

三、YOLOv5 的训练过程
训练过程:
- 输入图像经过 backbone+neck+head,输出三种不同尺度的 head 特征图(80x80,40x40,20x20)
- 在这三种不同尺度的特征图上分别布置三个不同宽高比的 anchor(由 k-means 得到的 anchors)
- 对每个 gt,根据正负样本分配规则来分配 anchors
- 对正样本,计算分类、回归、obj loss
YOLOv5 的 loss 总共包含 3 个,分别为:
- Classes loss:使用的是 BCE loss,计算所有正负样本的分类损失
- Objectness loss:使用的是 BCE loss,计算所有正负样本的 obj 损失,注意这里的 obj 指的是网络预测的目标边界框与 GT Box 的 CIoU
- Location loss:使用的是 CIoU loss,只计算正样本的定位损失
三个 loss 按照一定比例汇总: L o s s = λ 1 L c l s + λ 2 L o b j + λ 3 L l o c Loss=\lambda_1L_{cls}+\lambda_2L_{obj}+\lambda_3L_{loc} Loss=λ1Lcls+λ2Lobj+λ3Lloc
P3、P4、P5 层对应的 Objectness loss 按照不同权重进行相加:
L o b j = 4.0 ⋅ L o b j s m a l l + 1.0 ⋅ L o b j m e d i u m + 0.4 ⋅ L o b j l a r g e L_{obj}=4.0\cdot L_{obj}^{small}+1.0\cdot L_{obj}^{medium}+0.4\cdot L_{obj}^{large} Lobj=4.0⋅Lobjsmall+1.0⋅Lobjmedium+0.4⋅Lobjlarge
四、YOLOv5 的预测过程
-
将输入图像经过 backbone+neck+head,输出三种不同尺度的 head 特征图(80x80,40x40,20x20)
-
第一次阈值过滤:用 score_thr 对类别预测分值进行阈值过滤,去掉低于 score_thr 的预测结果
-
第二次阈值过滤: 将 obj 预测分值和过滤后的类别预测分值相乘,然后依然采用 score_thr 进行阈值过滤
-
还原到原图尺度并进行 NMS: 将前面两次过滤后剩下的检测框还原到网络输出前的原图尺度,然后进行 NMS 即可。这里的 NMS 可以使用普通 NMS,也可以使用 DIoU-NMS,同时考虑 IoU 和两框中心点的距离,能保留更多 IoU 大但中心点距离远的情况,有助于遮挡漏检问题的缓解。
四、如何在 YOLOv5 官方代码(非 MMYOLO)中添加 Swin 作为 backbone,
1、修改 yolol.yaml 为 yolol_swin_transformer.yaml
# Parameters
nc: 80 # number of classes
#ch: 3 # no. input channel
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# Swin-Transformer-Tiny backbone
backbone: #[2,2,6,2]# [from, number, module, args]# input [b, 1, 640, 640][[-1, 1, PatchEmbed, [96, 4]], # 0 [b, 96, 160, 160][-1, 1, SwinStage, [96, 2, 3, 7]], # 1 [b, 96, 160, 160][-1, 1, PatchMerging, [192]], # 2 [b, 192, 80, 80][-1, 1, SwinStage, [192, 2, 6, 7]], # 3 --F0-- [b, 192, 80, 80][ -1, 1, PatchMerging, [384]], # 4 [b, 384, 40, 40][ -1, 1, SwinStage, [384, 6, 12, 7]], # 5 --F1-- [b, 384, 40, 40][ -1, 1, PatchMerging, [768]], # 6 [b, 768, 20, 20][ -1, 1, SwinStage, [768, 2, 24, 7]], # 7 --F2-- [b, 768, 20, 20]]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 11[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 3], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 15 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 12], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 18 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 8], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 21 (P5/32-large)[[15, 18, 21], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]2、在 models 中添加 swintransformer.py
""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows`- https://arxiv.org/pdf/2103.14030Code/weights from https://github.com/microsoft/Swin-Transformer"""import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from typing import Optionaldef drop_path_f(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path_f(x, self.drop_prob, self.training)def window_partition(x, window_size: int):"""将feature map按照window_size划分成一个个没有重叠的windowArgs:x: (B, H, W, C)window_size (int): window size(M)Returns:windows: (num_windows*B, window_size, window_size, C)"""B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)# permute: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H//Mh, W//Mh, Mw, Mw, C]# view: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B*num_windows, Mh, Mw, C]windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size: int, H: int, W: int):"""将一个个window还原成一个feature mapArgs:windows: (num_windows*B, window_size, window_size, C)window_size (int): Window size(M)H (int): Height of imageW (int): Width of imageReturns:x: (B, H, W, C)"""B = int(windows.shape[0] / (H * W / window_size / window_size))# view: [B*num_windows, Mh, Mw, C] -> [B, H//Mh, W//Mw, Mh, Mw, C]x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)# permute: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B, H//Mh, Mh, W//Mw, Mw, C]# view: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H, W, C]x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass Mlp(nn.Module):""" MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.drop1 = nn.Dropout(drop)self.fc2 = nn.Linear(hidden_features, out_features)self.drop2 = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop1(x)x = self.fc2(x)x = self.drop2(x)return xclass WindowAttention(nn.Module):r""" Window based multi-head self attention (W-MSA) module with relative position bias.It supports both of shifted and non-shifted window.Args:dim (int): Number of input channels.window_size (tuple[int]): The height and width of the window.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueattn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0proj_drop (float, optional): Dropout ratio of output. Default: 0.0"""def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # [Mh, Mw]self.num_heads = num_headshead_dim = dim // num_headsself.scale = head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # [2*Mh-1 * 2*Mw-1, nH]# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij")) # [2, Mh, Mw]coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw]# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # [2, Mh*Mw, Mh*Mw]relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh*Mw, Mh*Mw, 2]relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]self.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)nn.init.trunc_normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask: Optional[torch.Tensor] = None):"""Args:x: input features with shape of (num_windows*B, Mh*Mw, C)mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None"""# [batch_size*num_windows, Mh*Mw, total_embed_dim]B_, N, C = x.shape# qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]# reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4).contiguous()# [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size*num_windows, num_heads, embed_dim_per_head, Mh*Mw]# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw]q = q * self.scaleattn = (q @ k.transpose(-2, -1))# relative_position_bias_table.view: [Mh*Mw*Mh*Mw,nH] -> [Mh*Mw,Mh*Mw,nH]relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [nH, Mh*Mw, Mh*Mw]attn = attn + relative_position_bias.unsqueeze(0)if mask is not None:# mask: [nW, Mh*Mw, Mh*Mw]nW = mask.shape[0] # num_windows# attn.view: [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw]# mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]# transpose: -> [batch_size*num_windows, Mh*Mw, num_heads, embed_dim_per_head]# reshape: -> [batch_size*num_windows, Mh*Mw, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass SwinTransformerBlock(nn.Module):r""" Swin Transformer Block.Args:dim (int): Number of input channels.num_heads (int): Number of attention heads.window_size (int): Window size.shift_size (int): Shift size for SW-MSA.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Truedrop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, num_heads, window_size=7, shift_size=0,mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeself.mlp_ratio = mlp_ratioassert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias,attn_drop=attn_drop, proj_drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def forward(self, x, attn_mask):H, W = self.H, self.WB, L, C = x.shapeassert L == H * W, "input feature has wrong size"shortcut = xx = self.norm1(x)x = x.view(B, H, W, C)# pad feature maps to multiples of window size# 把feature map给pad到window size的整数倍pad_l = pad_t = 0pad_r = (self.window_size - W % self.window_size) % self.window_sizepad_b = (self.window_size - H % self.window_size) % self.window_sizex = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))_, Hp, Wp, _ = x.shape# cyclic shiftif self.shift_size > 0:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))else:shifted_x = xattn_mask = None# partition windowsx_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C]# W-MSA/SW-MSAattn_windows = self.attn(x_windows, mask=attn_mask) # [nW*B, Mh*Mw, C]# merge windowsattn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C]shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C]# reverse cyclic shiftif self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = shifted_xif pad_r > 0 or pad_b > 0:# 把前面pad的数据移除掉x = x[:, :H, :W, :].contiguous()x = x.view(B, H * W, C)# FFNx = shortcut + self.drop_path(x)x = x + self.drop_path(self.mlp(self.norm2(x)))return xclass SwinStage(nn.Module):"""A basic Swin Transformer layer for one stage.Args:dim (int): Number of input channels.depth (int): Number of blocks.num_heads (int): Number of attention heads.window_size (int): Local window size.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Truedrop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False."""def __init__(self, dim, c2, depth, num_heads, window_size,mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,drop_path=0., norm_layer=nn.LayerNorm, use_checkpoint=False):super().__init__()assert dim==c2, r"no. in/out channel should be same"self.dim = dimself.depth = depthself.window_size = window_sizeself.use_checkpoint = use_checkpointself.shift_size = window_size // 2# build blocksself.blocks = nn.ModuleList([SwinTransformerBlock(dim=dim,num_heads=num_heads,window_size=window_size,shift_size=0 if (i % 2 == 0) else self.shift_size,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias,drop=drop,attn_drop=attn_drop,drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer)for i in range(depth)])def create_mask(self, x, H, W):# calculate attention mask for SW-MSA# 保证Hp和Wp是window_size的整数倍Hp = int(np.ceil(H / self.window_size)) * self.window_sizeWp = int(np.ceil(W / self.window_size)) * self.window_size# 拥有和feature map一样的通道排列顺序,方便后续window_partitionimg_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1]mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [nW, Mh*Mw]attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1]# [nW, Mh*Mw, Mh*Mw]attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))return attn_maskdef forward(self, x):B, C, H, W = x.shapex = x.permute(0, 2, 3, 1).contiguous().view(B, H*W, C)attn_mask = self.create_mask(x, H, W) # [nW, Mh*Mw, Mh*Mw]for blk in self.blocks:blk.H, blk.W = H, Wif not torch.jit.is_scripting() and self.use_checkpoint:x = checkpoint.checkpoint(blk, x, attn_mask)else:x = blk(x, attn_mask)x = x.view(B, H, W, C)x = x.permute(0, 3, 1, 2).contiguous()return xclass PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, in_c=3, embed_dim=96, patch_size=4, norm_layer=None):super().__init__()patch_size = (patch_size, patch_size)self.patch_size = patch_sizeself.in_chans = in_cself.embed_dim = embed_dimself.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):_, _, H, W = x.shape# padding# 如果输入图片的H,W不是patch_size的整数倍,需要进行paddingpad_input = (H % self.patch_size[0] != 0) or (W % self.patch_size[1] != 0)if pad_input:# to pad the last 3 dimensions,# (W_left, W_right, H_top,H_bottom, C_front, C_back)x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1],0, self.patch_size[0] - H % self.patch_size[0],0, 0))# 下采样patch_size倍x = self.proj(x)B, C, H, W = x.shape# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = x.flatten(2).transpose(1, 2)x = self.norm(x)# view: [B, HW, C] -> [B, H, W, C]# permute: [B, H, W, C] -> [B, C, H, W]x = x.view(B, H, W, C)x = x.permute(0, 3, 1, 2).contiguous()return xclass PatchMerging(nn.Module):r""" Patch Merging Layer.Args:dim (int): Number of input channels.norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, c2, norm_layer=nn.LayerNorm):super().__init__()assert c2==(2 * dim), r"no. out channel should be 2 * no. in channel "self.dim = dimself.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)self.norm = norm_layer(4 * dim)def forward(self, x):"""x: B, C, H, W"""B, C, H, W = x.shape# assert L == H * W, "input feature has wrong size"x = x.permute(0, 2, 3, 1).contiguous()# x = x.view(B, H*W, C)# padding# 如果输入feature map的H,W不是2的整数倍,需要进行paddingpad_input = (H % 2 == 1) or (W % 2 == 1)if pad_input:# to pad the last 3 dimensions, starting from the last dimension and moving forward.# (C_front, C_back, W_left, W_right, H_top, H_bottom)# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]x = self.norm(x)x = self.reduction(x) # [B, H/2*W/2, 2*C]x = x.view(B, int(H/2), int(W/2), C*2)x = x.permute(0, 3, 1, 2).contiguous()return x
3、在 models/yolo.py 中 import swin transformer 模块,并在 271 行增加三个模块的名称
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
YOLO-specific modulesUsage:$ python path/to/models/yolo.py --cfg yolov5s.yaml
"""import argparse
import os
import platform
import sys
from copy import deepcopy
from pathlib import PathFILE = Path(__file__).resolve()
ROOT = FILE.parents[1] # YOLOv5 root directory
if str(ROOT) not in sys.path:sys.path.append(str(ROOT)) # add ROOT to PATH
if platform.system() != 'Windows':ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relativefrom models.common import *
from models.swintransformer import SwinStage, PatchMerging, PatchEmbed
from models.experimental import *
from utils.autoanchor import check_anchor_order
from utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
from utils.plots import feature_visualization
from utils.torch_utils import (fuse_conv_and_bn, initialize_weights, model_info, profile, scale_img, select_device,time_sync)try:import thop # for FLOPs computation
except ImportError:thop = Noneclass Detect(nn.Module):stride = None # strides computed during buildonnx_dynamic = False # ONNX export parameterexport = False # export modedef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0xy = (xy * 2 + self.grid[i]) * self.stride[i] # xywh = (wh * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf), 4)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].devicet = self.anchors[i].dtypeshape = 1, self.na, ny, nx, 2 # grid shapey, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid(y, x, indexing='ij')else:yv, xv = torch.meshgrid(y, x)grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)return grid, anchor_gridclass Model(nn.Module):# YOLOv5 modeldef __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classessuper().__init__()if isinstance(cfg, dict):self.yaml = cfg # model dictelse: # is *.yamlimport yaml # for torch hubself.yaml_file = Path(cfg).namewith open(cfg, encoding='ascii', errors='ignore') as f:self.yaml = yaml.safe_load(f) # model dict# Define modelch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channelsif nc and nc != self.yaml['nc']:LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")self.yaml['nc'] = nc # override yaml valueif anchors:LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')self.yaml['anchors'] = round(anchors) # override yaml valueself.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelistself.names = [str(i) for i in range(self.yaml['nc'])] # default namesself.inplace = self.yaml.get('inplace', True)# Build strides, anchorsm = self.model[-1] # Detect()if isinstance(m, Detect):s = 256 # 2x min stridem.inplace = self.inplacem.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forwardcheck_anchor_order(m) # must be in pixel-space (not grid-space)m.anchors /= m.stride.view(-1, 1, 1)self.stride = m.strideself._initialize_biases() # only run once# Init weights, biasesinitialize_weights(self)self.info()LOGGER.info('')def forward(self, x, augment=False, profile=False, visualize=False):if augment:return self._forward_augment(x) # augmented inference, Nonereturn self._forward_once(x, profile, visualize) # single-scale inference, traindef _forward_augment(self, x):img_size = x.shape[-2:] # height, widths = [1, 0.83, 0.67] # scalesf = [None, 3, None] # flips (2-ud, 3-lr)y = [] # outputsfor si, fi in zip(s, f):xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))yi = self._forward_once(xi)[0] # forward# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # saveyi = self._descale_pred(yi, fi, si, img_size)y.append(yi)y = self._clip_augmented(y) # clip augmented tailsreturn torch.cat(y, 1), None # augmented inference, traindef _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return xdef _descale_pred(self, p, flips, scale, img_size):# de-scale predictions following augmented inference (inverse operation)if self.inplace:p[..., :4] /= scale # de-scaleif flips == 2:p[..., 1] = img_size[0] - p[..., 1] # de-flip udelif flips == 3:p[..., 0] = img_size[1] - p[..., 0] # de-flip lrelse:x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scaleif flips == 2:y = img_size[0] - y # de-flip udelif flips == 3:x = img_size[1] - x # de-flip lrp = torch.cat((x, y, wh, p[..., 4:]), -1)return pdef _clip_augmented(self, y):# Clip YOLOv5 augmented inference tailsnl = self.model[-1].nl # number of detection layers (P3-P5)g = sum(4 ** x for x in range(nl)) # grid pointse = 1 # exclude layer counti = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indicesy[0] = y[0][:, :-i] # largei = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indicesy[-1] = y[-1][:, i:] # smallreturn ydef _profile_one_layer(self, m, x, dt):c = isinstance(m, Detect) # is final layer, copy input as inplace fixo = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPst = time_sync()for _ in range(10):m(x.copy() if c else x)dt.append((time_sync() - t) * 100)if m == self.model[0]:LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')if c:LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency# https://arxiv.org/abs/1708.02002 section 3.3# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.m = self.model[-1] # Detect() modulefor mi, s in zip(m.m, m.stride): # fromb = mi.bias.view(m.na, -1).detach() # conv.bias(255) to (3,85)b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)b[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # clsmi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)def _print_biases(self):m = self.model[-1] # Detect() modulefor mi in m.m: # fromb = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)LOGGER.info(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))# def _print_weights(self):# for m in self.model.modules():# if type(m) is Bottleneck:# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weightsdef fuse(self): # fuse model Conv2d() + BatchNorm2d() layersLOGGER.info('Fusing layers... ')for m in self.model.modules():if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):m.conv = fuse_conv_and_bn(m.conv, m.bn) # update convdelattr(m, 'bn') # remove batchnormm.forward = m.forward_fuse # update forwardself.info()return selfdef info(self, verbose=False, img_size=640): # print model informationmodel_info(self, verbose, img_size)def _apply(self, fn):# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffersself = super()._apply(fn)m = self.model[-1] # Detect()if isinstance(m, Detect):m.stride = fn(m.stride)m.grid = list(map(fn, m.grid))if isinstance(m.anchor_grid, list):m.anchor_grid = list(map(fn, m.anchor_grid))return selfdef parse_model(d, ch): # model_dict, input_channels(3)LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)layers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argsm = eval(m) if isinstance(m, str) else m # eval stringsfor j, a in enumerate(args):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept NameError:passn = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, PatchMerging, PatchEmbed, SwinStage):c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)elif m is Detect:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2else:c2 = ch[f]m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []ch.append(c2)return nn.Sequential(*layers), sorted(save)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')parser.add_argument('--batch-size', type=int, default=1, help='total batch size for all GPUs')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--profile', action='store_true', help='profile model speed')parser.add_argument('--line-profile', action='store_true', help='profile model speed layer by layer')parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')opt = parser.parse_args()opt.cfg = check_yaml(opt.cfg) # check YAMLprint_args(vars(opt))device = select_device(opt.device)# Create modelim = torch.rand(opt.batch_size, 3, 640, 640).to(device)model = Model(opt.cfg).to(device)# Optionsif opt.line_profile: # profile layer by layer_ = model(im, profile=True)elif opt.profile: # profile forward-backwardresults = profile(input=im, ops=[model], n=3)elif opt.test: # test all modelsfor cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):try:_ = Model(cfg)except Exception as e:print(f'Error in {cfg}: {e}')else: # report fused model summarymodel.fuse()


