文章目录
- 一.背景
- 二.内容
一.背景
这是2020届内科大机器学习框架课程的考试复习内容
二.内容
1.变量间的相互关系:
(1)确定性关系或函数关系:研究的是确定现象非随机变量间的关系。
(2)相关关系或统计依赖关系:研究的是非确定现象随机变量间的关系。
2.回归分析是研究一个变量关于另一个(些)变量的具体依赖关系。
收入是解释变量或自变量,消费是被解释变量或因变量。
注意:不线性相关并不意味着不相关;有相关关系并不意味着一定有因果关系;

3.线性回归的正规方程:
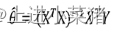
4.正规方程成立的前提条件是什么:
而逆矩阵存在的充分必要条件是特征矩阵不存在多重共线性,也就是矩阵的行列式不为0,也就是要求矩阵为满秩矩阵.
5.多重共线性:
多重共线性是指线性回归模型中的属性/特征之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。存在精确相关关系(成比例)和高度相关关系。 处理方法:手动移除共线性的特征:即先对数据进行相关分析,若两个特征的相关系数大于某特定值(一般为0.7),则手动移除其中一个特征,再继续做回归分析。(岭回归L2范数 lassoL1范数)修复线性回归的漏洞。
6.残差
残差=观测值(真实值)-计算值(预测值)
离差=计算值-真实值
几个常用的结果如下:

TSS(总体平方和)=ESS(回归平方和)+RSS(残差平方和)
7.梯度下降和正规方程的区别:
1>梯度下降:需选择学习率a、需要多次迭代、特征数量N大也可以适用、适用于各种类型的模型。
2>正规方程:一次运算得出,时间复杂度大不适用特征值多、只适用于线性回归模型。
8,需要记住的代码:
Sklearn.linear_model.LinearRegression()正规方程
Sklearn.linear_model.SGDRegressor()梯度下降
mean_squared_error(y_ture,y_pred)均方误差
_absolute_error(..)平均绝对误差 r2_score()计算的拟合度
9.范数
范数就是向量的长度。L1范数是:向量中所有元素的绝对值之和。L2范数是:向量中所有元素的平方和再开根号。
10随机森林:
bootstrap sample,有放回抽样,指每次从样本空间中可以重复抽取同一个样本,bootstrap sample生成的数据集和原始数据集在数据量上是完全一样的但由于进行了重复采样,因此其中有一些数据点会丢失。这是因为通过重新生成数据集,可以让随机森林中的每一棵决策树在构建的时候,会彼此之间有些差异。再加上每棵树的节点都会去选择不同的样本特征,经过这两步动作之后,可以完全肯定随机森林中的每棵树都不一样。
11.Bagging策略:
从样本集中重采样(有重复的)选出n个样本在全部或部分属性/特征上,对这n个样本建立分类器(ID3、C4.5、CART、SVM、Logistic 回归等)
重复以上两步m次,即获得了m个分类器将数据放在m个分类器上计算,最后根据m个分类器的投票结果,决定数据属于哪一类。
12 弱学习机与强学习机
弱学习机(强于随机猜测)–Boosting—>强学习机(最大长度符合实际情况)
13.AdaBoosting算法:
首先给每一个训练样例赋予相同的权重,然后训练第一个基本分类器并用它来对训练集进行测试,对于那些分类错误的测试样例提高其权重(实际算法中是降低分类正确的样例的权重)然后用调整后的带权训练集训练第二个基本分类器,然后重复这个过程直到最后得到一个足够好的学习器。
14.GBDT的原理:
就是对所有弱分类器的结果进行计算得到预测值,然后下一个弱分类器去拟合误差函数对预测值的残差(这个残差就是预测值与真实值之间的误差),它里面的弱分类器的表现形式就是各棵树。
15.随机森林和GBDT:不同点:
组成随机森林的树可以并行生成,而GBDT是串行生成、随机森林对异常值不敏感,而GBDT对异常值比较敏感、随机森林是减少模型的方差(过拟合),而GBDT是减少模型的偏差(提高准确度)
16.XGBoost
XGBoost是对于GBDT的拓展
XGBoost:一阶和二阶导数,支持多类型的基分类器,自动学习缺失值的处理策略GBDT:一阶导数,只采用CART作为基分类器,不能处理缺失值