维基百科
POSIX基本表达式 https://en.wikibooks.org/wiki/Regular_Expressions/POSIX_Basic_Regular_Expressions
POSIX扩展正则表达式 https://en.wikibooks.org/wiki/Regular_Expressions/POSIX-Extended_Regular_Expressions
正则表达式 https://en.wikipedia.org/wiki/Regular_expression#Character_classes
GNU
POSIX基本正则 https://www.gnu.org/software/findutils/manual/html_node/find_html/posix_002dbasic-regular-expression-syntax.html
POSIX扩展正则 https://www.gnu.org/software/findutils/manual/html_node/find_html/posix_002dextended-regular-expression-syntax.html
常见的正则 https://www.gnu.org/software/findutils/manual/html_node/find_html/Regular-Expressions.html
CPLUSPLUS.COM, ECMA的,也可以看看
https://cplusplus.com/reference/regex/ECMAScript/
维基百科


那个为什么是vim……
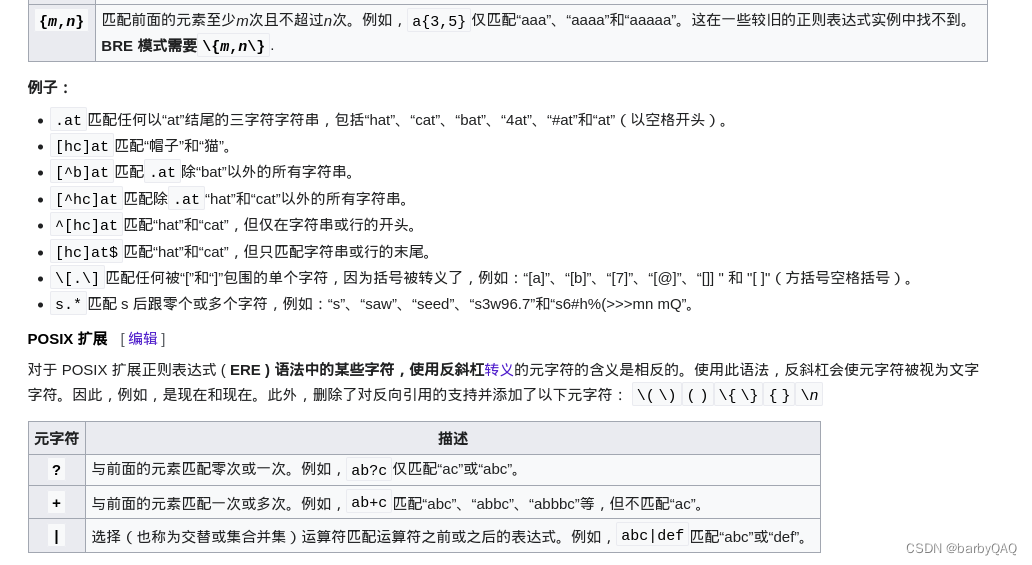
上面还提了一句:POSIX 字符类只能在方括号表达式中使用。例如,匹配大写字母和小写字母“a”和“b”。 [[:upper:]ab]
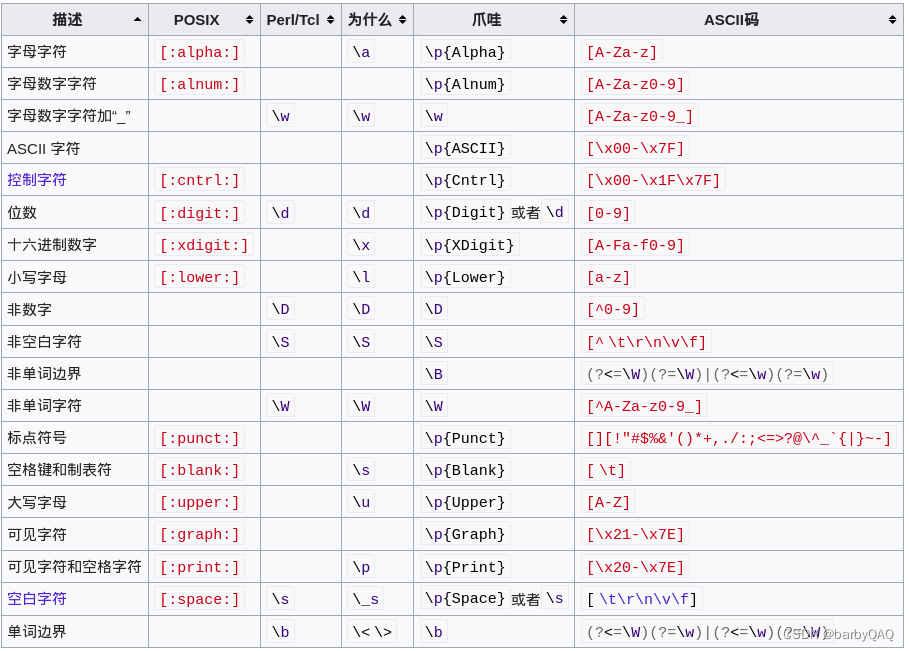
GNU 翻译
gnu的解释少得可怜。
1. POSIX Basic EXP
基本规则
| 符号 | 作用 |
|---|---|
| ‘\+’ | 匹配1次或更多次前面的模式(one or more) |
| ‘\?’ | 匹配0次或更多次前面的模式 ( zero or more ) |
| ‘+和?’ | 匹配它们本身 |
-
括号表达式(Bracket expressions)用来匹配字符范围。
-
范围向后的括号表达式是非法的,例如
[z-a]。 -
方括号中,'\'就是字面意思。
-
支持字符类;例如
[[:digit:]]会匹配单个十进制数。
分组
反斜杠+括号,用于分组,\(和\)。
反斜杠+数字,用于匹配签名的分组,例如\2匹配第2个分组的表达式。
分组的顺序有其左括号\(的位置决定。
逻辑符号
可选运算符是\|。
^只匹配一个字符串的开头:
- 一个正则表达式的开始
- 在一个未闭合分组(open-group,用
\(表示)之后。 - 在一个
\|之后。
$匹配字符串结尾:
- 在正则表达式结束位置
- 在一个闭合的分组之前(closl-group,用
\)表示) - 在一个
\|之前。
\*,\+和\?这些在除以下几种情况时都表示特殊含义:
- 在正则表达式开头
- 在一个未闭合分组之后(open-group,用
\(表示) - 在一个
\|之后。
通过\{和\}来把值间隔开。但是像a\{1z这样的非法间隔是不被接受的。
返回最长匹配——这对整体、分组中的子表达式都适用。
2. POSIX Extended EXP
基本规则
(注意和上面的有差别)
| 符号 | 作用 |
|---|---|
| ‘+’ | 匹配1次或更多次前面的模式(one or more) |
| ‘?’ | 匹配0次或更多次前面的模式 ( zero or more ) |
| ‘\+’ | 匹配一个加号+ |
| ‘\?’ | 匹配一个问号? |
(下面这4条规则和基本的一样)
-
括号表达式(Bracket expressions)用来匹配字符范围。
-
范围向后的括号表达式是非法的,例如
[z-a]。 -
方括号中,'\'就是字面意思。
-
支持字符类;例如
[[:digit:]]会匹配单个十进制数。
分组
分组用()。一个没配对的)只表示它自己。
\ + 数字依然是反向匹配,例如\2匹配第2个分组表达式。
分组的顺序取决于它们的开括号(。
逻辑符号
可选符号是|。
除了在方括号内时,^和$总是一个表示字符串开头、一个表示字符串结尾。
当在方括号内部时,^也可以用来反选(反转匹配指定的字符)。
*, +, 和?在正则表达式中总是有特殊含义,除了下列情况不被允许:
- 正则表达式开头
- 一个开分组(open-griup)
(的后面。 - 一个
|的前面。
用{和 }来间隔值。a{1z这样的非法间隔不被接受。
返回最长的匹配——这对整体和子表达式均适用。


![[计算机图形学]重心坐标应用纹理(前瞻预习/复习回顾)](https://img-blog.csdnimg.cn/3e80f634403241d681a9bdd1cd53655b.png)
