1、什么是缓存?
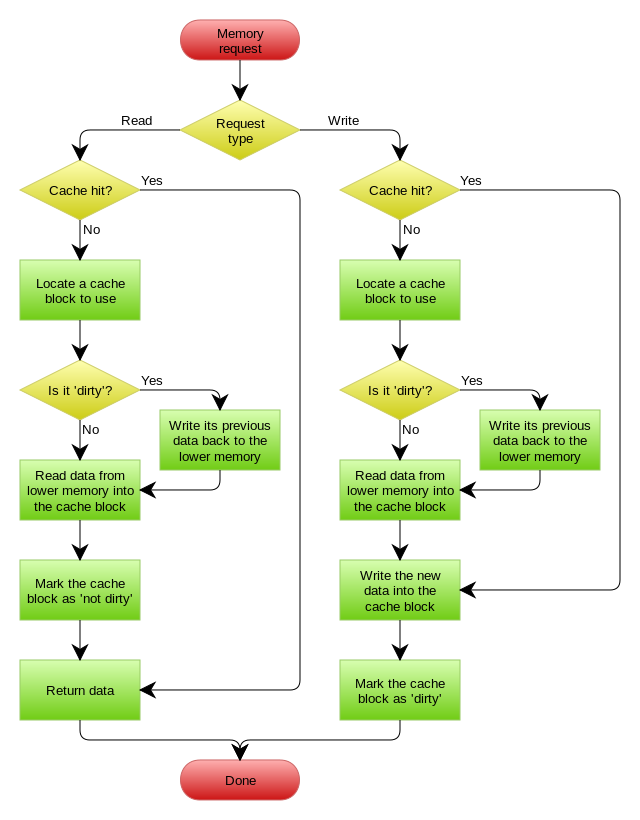
☞ 缓存就是数据交换的缓冲区(称作:Cache),当某一硬件要读取数据时,会首先从缓存汇总查询数据,有则直接执行,不存在时从内存中获取。由于缓存的数据比内存快的多,所以缓存的作用就是帮助硬件更快的运行。
☞ 缓存往往使用的是RAM(断电既掉的非永久存储),所以在用完后还是会把文件送到硬盘等存储器中永久存储。电脑中最大缓存就是内存条,硬盘上也有16M或者32M的缓存。
☞ 高速缓存是用来协调CPU与主存之间存取速度的差异而设置的。一般CPU工作速度高,但内存的工作速度相对较低,为了解决这个问题,通常使用高速缓存,高速缓存的存取速度介于CPU与主存之间。系统将一些CPU在最近几个时间段经常访问的内容存在高速缓存,这样就在一定程度上缓解了由于主存速度低造成的CPU“停工待料”的情况。
☞ 缓存就是把一些外存上的数据保存在内存上而已,为什么保存在内存上,我们运行的所有程序里面的变量都是存放在内存中的,所以如果想将值放入内存上,可以通过变量的方式存储。在JAVA中一些缓存一般都是通过Map集合来实现的。
▁▂▃▅▆ :缓存在不同的场景下,作用是不一样的具体举例说明:
✔ 操作系统磁盘缓存 ——> 减少磁盘机械操作。
✔ 数据库缓存——>减少文件系统IO。
✔ 应用程序缓存——>减少对数据库的查询。
✔ Web服务器缓存——>减少应用服务器请求。
✔ 客户端浏览器缓存——>减少对网站的访问。
2、常见的缓存策略有哪些,如何做到缓存(比如redis)与DB里的数据一致性,你们项目中用到了什么缓存系统,如何设计的。
1)、由于不同系统的数据访问模式不同,同一种缓存策略很难在不同的数据访问模式下取得满意的性能,研究人员提出不同缓存策略以适应不同的需求。
缓存策略的分类: 1)、基于访问的时间:此类算法按各缓存项被访问时间来组织缓存队列,决定替换对象。如LRU
2)、基于访问频率:此类算法用缓存项的被访问频率来组织缓存。如LFU、LRU2、2Q、LIRS。
3)、访问时间与频率兼顾:通过兼顾访问时间和频率。使得数据模式在变化时缓存策略仍有较好性能。如FBR、LRUF、ALRFU。多数此类算法具有一个可调或自适应参数,通过该参数的调节使缓存策略在基于访问时间与频率间取得一个平衡。
4)、基于访问模式:某些应用有较明确的数据访问特点,进而产生与其相适应的缓存策略。如专用的VoD系统设计的A&L缓存策略,同时适应随机、顺序两种访问模式的SARC策略。
2)、数据不一致性产生的原因:
【1】、先操作缓存,再写数据库成功之前,如果有读请求发生,可能导致旧数据入缓存,引发数据不一致。在分布式环境下,数据的读写都是并发的,一个服务多机器部署,对同一个数据进行读写,在数据库层面并不能保证完成顺序,就有可能后读的操作先完成(读取到的是脏数据),如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
【解决办法】:1)、可采用更新前后双删除缓存策略。
2)、可以通过“串行化”解决,保证同一个数据的读写落在同一个后端服务上。
【2】、先操作数据库,再清除缓存。如果删缓存失败了,就会出现数据不一致问题。
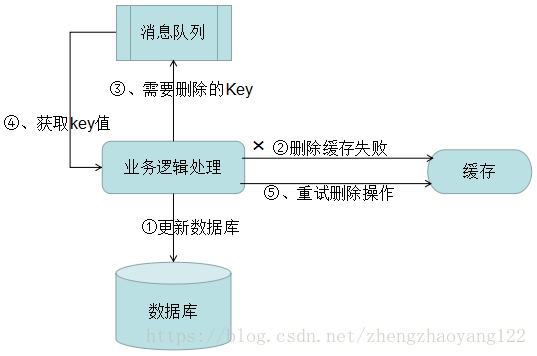
【解决办法】:1)、将删除失败的key值存入队列中重复删除,如下图:
(1)更新数据库数据。
(2)缓存因为种种问题删除失败。
(3)将需要删除的key发送至消息队列。
(4)自己消费消息,获得需要删除的key。
(5)继续重试删除操作,直到成功。
缺点:对业务线代码造成大量的侵入。于是有了方案二。
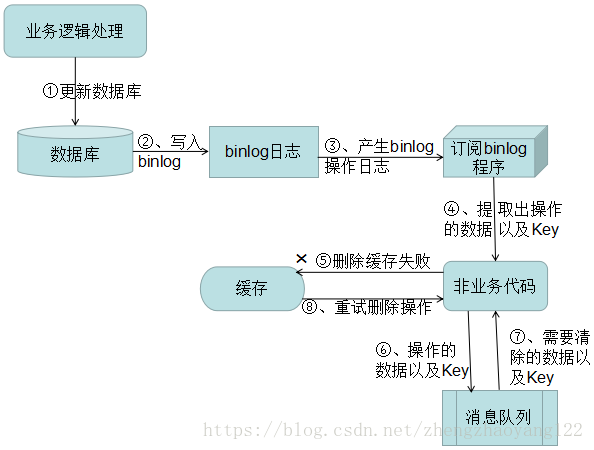
2)、方案二:通过订阅binlog获取需要重新删除的Key值数据。在应用程序中,另起一段程序,获得这个订阅程序传来的消息,进行删除缓存操作。
(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。
---------------------
作者:程序猿进阶
来源:CSDN
原文:https://blog.csdn.net/zhengzhaoyang122/article/details/82184029
版权声明:本文为博主原创文章,转载请附上博文链接!