大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型11-pytorch搭建DCGAN模型,一种生成对抗网络GAN的变体实际应用,本文将具体介绍DCGAN模型的原理,并使用PyTorch搭建一个简单的DCGAN模型。我们将提供模型代码,并使用一些数据样例进行训练和测试。最后,我们将展示训练过程中的损失值和准确率。
文章目录:
- DCGAN模型简介
- DCGAN模型原理
- 使用PyTorch搭建DCGAN模型
- 数据样例
- 训练模型
- 测试模型
- 总结
1. DCGAN模型简介
DCGAN全称:Deep Convolutional Generative Adversarial Networks,它是一种生成对抗网络(GAN)的变体,它使用卷积神经网络(CNN)作为生成器和判别器。DCGAN在图像生成任务中表现出色,能够生成具有高分辨率和清晰度的图像。
2. DCGAN模型原理
DCGAN模型由两个部分组成:生成器(Generator)和判别器(Discriminator)。生成器负责生成图像,而判别器负责判断图像是否为真实图像。在训练过程中,生成器和判别器相互竞争,生成器试图生成越来越逼真的图像,而判别器试图更准确地识别生成的图像是否为真实图像。这个过程持续进行,直到生成器生成的图像足够逼真,以至于判别器无法区分生成的图像和真实图像。
DCGAN模型的数学原理表示:
生成器(Generator):
G ( z ) = x G(z) = x G(z)=x
其中, z z z是输入的随机噪声向量, x x x是生成的图像。
判别器(Discriminator):
D ( x ) = y D(x) = y D(x)=y
其中, x x x是输入的图像, y y y是判别器对图像的判断结果,表示图像是否为真实图像。
GAN的损失函数:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D,G) = \mathbb{E}{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1-D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
其中, p d a t a ( x ) p_{data}(x) pdata(x)表示真实数据的分, p z ( z ) p_z(z) pz(z)表示噪声向量的分布, D ( x ) D(x) D(x)表示判别器对图像 x x x的判断结果, G ( z ) G(z) G(z)表示生成器生成的图像, log D ( x ) \log D(x) logD(x)表示判别器将真实图像判断为真实图像的概率, log ( 1 − D ( G ( z ) ) ) \log(1-D(G(z))) log(1−D(G(z)))表示判别器将生成图像判断为真实图像的概率。
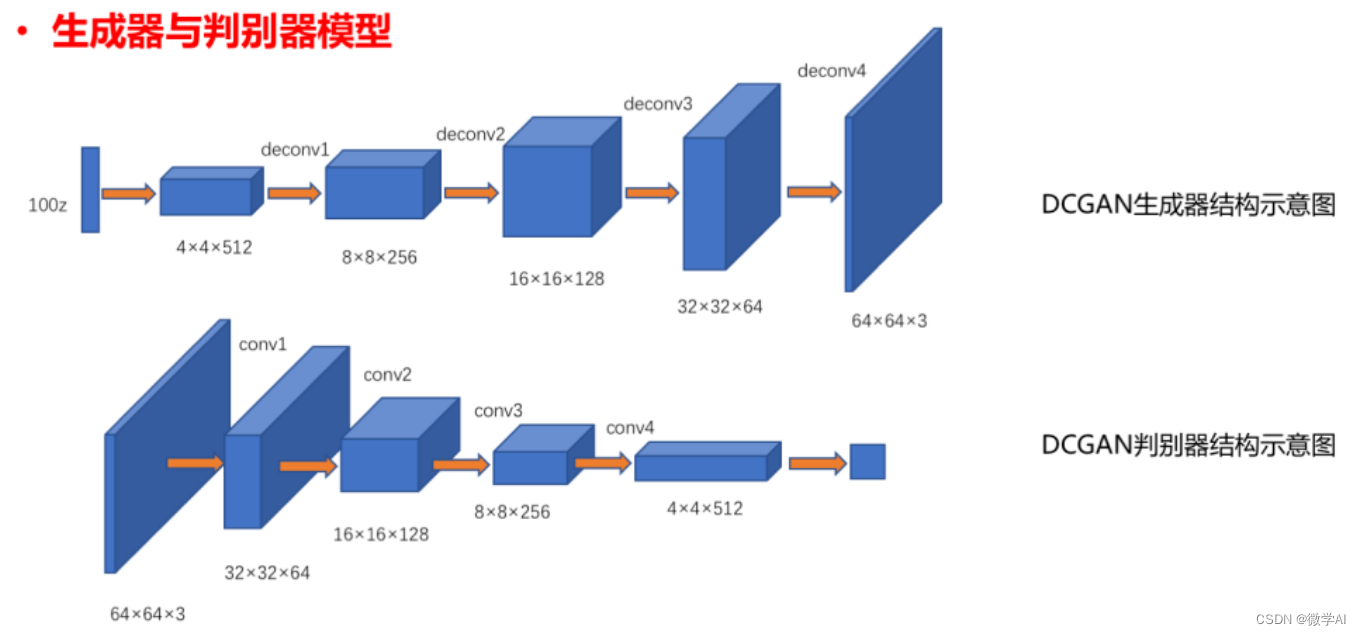
3. 使用PyTorch搭建DCGAN模型
首先,我们需要导入所需的库:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as dset
from torch.autograd import Variable
接下来,我们定义生成器和判别器的网络结构:
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.main = nn.Sequential(# 输入是一个100维的向量nn.ConvTranspose2d(100, 512, 4, 1, 0, bias=False),nn.BatchNorm2d(512),nn.ReLU(True),# 输出为(512, 4, 4)nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),nn.BatchNorm2d(256),nn.ReLU(True),# 输出为(256, 8, 8)nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),nn.BatchNorm2d(128),nn.ReLU(True),# 输出为(128, 16, 16)nn.ConvTranspose2d(128, 3, 4, 2, 1, bias=False),nn.Tanh()# 输出为(3, 32, 32))def forward(self, input):return self.main(input)class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.main = nn.Sequential(# 输入为(3, 32, 32)nn.Conv2d(3, 128, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# 输出为(128, 16, 16)nn.Conv2d(128, 256, 4, 2, 1, bias=False),nn.BatchNorm2d(256),nn.LeakyReLU(0.2, inplace=True),# 输出为(256, 8, 8)nn.Conv2d(256, 512, 4, 2, 1, bias=False),nn.BatchNorm2d(512),nn.LeakyReLU(0.2, inplace=True),# 输出为(512, 4, 4)nn.Conv2d(512, 1, 4, 1, 0, bias=False),nn.Sigmoid())def forward(self, input):return self.main(input).view(-1)
4. 数据样例
我们将使用CIFAR-10数据集进行训练。首先,我们需要对数据进行预处理:
if __name__ =="__main__":transform = transforms.Compose([transforms.Resize(32),transforms.CenterCrop(32),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),])trainset = dset.CIFAR10(root='./data', train=True, download=True, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
5. 训练模型
接下来,我们将训练DCGAN模型:
# 初始化生成器和判别器
netG = Generator()
netD = Discriminator()# 设置损失函数和优化器
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999))# 训练模型
num_epochs = 10for epoch in range(num_epochs):for i, data in enumerate(trainloader, 0):# 更新判别器netD.zero_grad()real, _ = databatch_size = real.size(0)label = torch.full((batch_size,), 1)output = netD(real)errD_real = criterion(output, label)errD_real.backward()noise = torch.randn(batch_size, 100, 1, 1)fake = netG(noise)label.fill_(0)output = netD(fake.detach())errD_fake = criterion(output, label)errD_fake.backward()errD = errD_real + errD_fakeoptimizerD.step()# 更新生成器netG.zero_grad()label.fill_(1)output = netD(fake)errG = criterion(output, label)errG.backward()optimizerG.step()if i%5==0:# 打印损失值print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f' % (epoch, num_epochs, i, len(trainloader), errD.item(), errG.item()))
6. 测试模型
训练完成后,我们可以使用生成器生成一些图像进行测试:
import matplotlib.pyplot as plt
import numpy as npdef imshow(img):img = img / 2 + 0.5npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()noise = torch.randn(64, 100, 1, 1)
fake = netG(noise)
imshow(torchvision.utils.make_grid(fake.detach()))
7. 总结
本文详细介绍了DCGAN模型的原理,并使用PyTorch搭建了一个简单的DCGAN模型。我们提供了模型代码,并使用CIFAR-10数据集进行训练和测试。最后,我们展示了训练过程中的损失值和生成的图像。希望本文能帮助您更好地理解DCGAN模型,并在实际项目中应用。