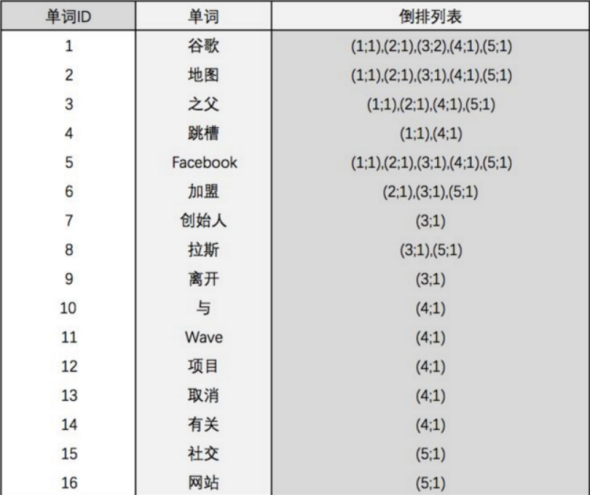
模型总览如下:
背景:本论文是对MMGCN(Wei et al., 2019)的改进。MMGCN简单地在并行交互图上使用GNN,平等地对待从所有邻居传播的信息,无法自适应地捕获用户偏好。
MMGCN的消息聚合方式如下:
![]()
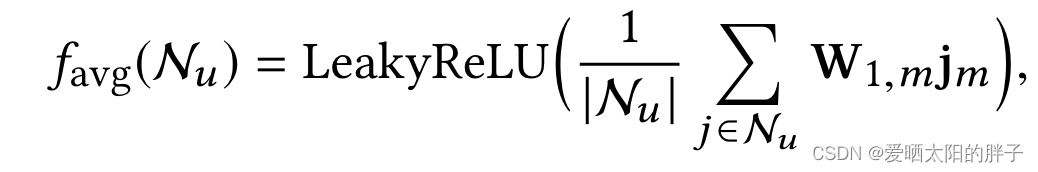 (平均值聚合
(平均值聚合
或
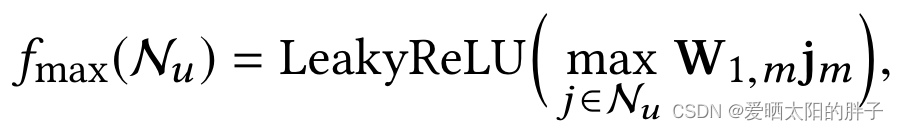 (最大值聚合)
(最大值聚合)
:邻居的特征向量
:可训练的权重矩阵用于提取邻居的有用特征
由公式可见所有邻居都信息都通过矩阵进行特征提取。当用户分别喜欢物品A的音乐,B的字幕。在音频模态上同等程度的提取B的音频特征,无疑会加入噪声。MGAT对MMGCN针对这点做了改进。
MGAT消息构造如下所示:
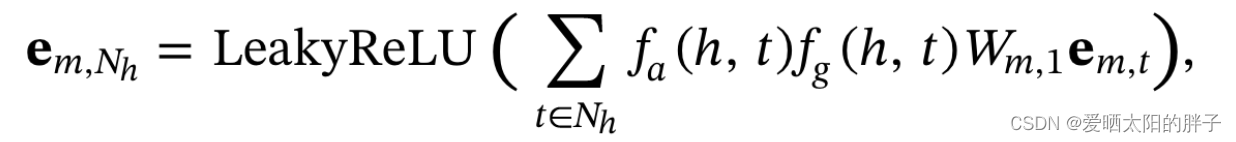
- h:中心节点
- t:h的邻居节点
:物品t在模态m上的特征表示
: 注意力组件,学习不同邻居的重要性,反映两个节点之间的亲疏关系。
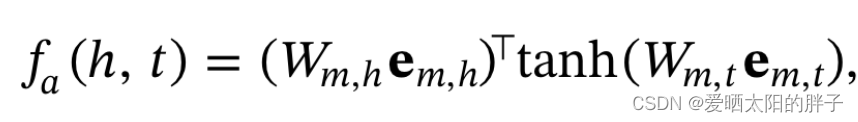
利用Sotfmax函数进行正则化:
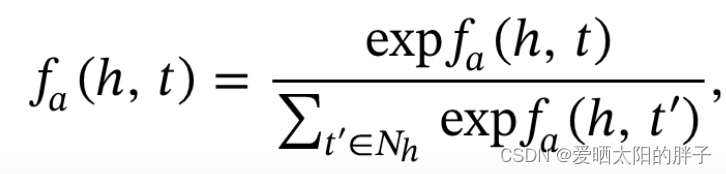
其中以及
是两个可训练矩阵,
为物品i 在模态m上的特征。为了简单起见,论文 中 直接用内积做为注意力分数。
决定项目的每个模态是否将信息传播给目标用户。
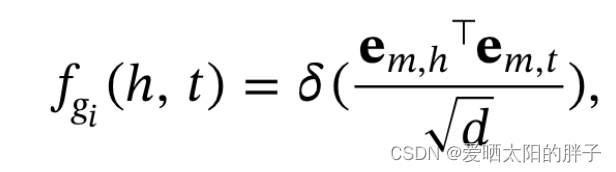 (内积门)
(内积门)
![]() (连接门)
(连接门)
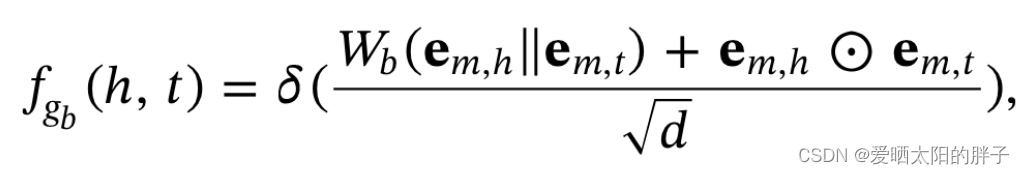 (双相互作用门)
(双相互作用门)
其中d为节点h 的邻居的数量。
三种门的效果对比:

由实验结果可以发现“最简单”的内积门在两个数据集上的表现都最好,可能原因是其他两个门通过变换矩阵做了特征变换,造成了过拟合。
一层信息融合(h距离一跳的邻居):
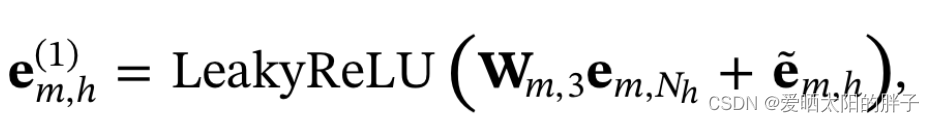
![]()
为用户h在模态m上的特征表示,
为用户h的id特征。物品的不同模态属于不同的语意空间,通过下方的公式将物品所有模态的特征表示都转换到id空间,并在用户的特征表示中加入id属性。上面的公式也是同样的道理,将模态m上从邻居那里得到的信息转换到ID空间,并与自己的特征相结合,得到h在模态m上的最终表示
高层信息融合
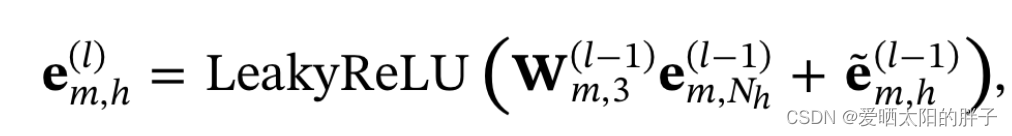
节点h在模态m上汇聚了l跳邻居信息后得到的表征。
节点h的表征为 。
。
预测:
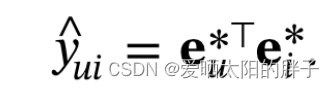
![]()
同时融合了各层邻居的信息。