一、Redis特性
快
为什么快?
- 基于内存操作,操作不需要跟磁盘交互。
- 本身就是k-v结构,类似hashMap,所以查询速度接近O(1)。
- 同时redis自己底层数据结构支持,比如跳表、SDS。
- 命令执行是单线程,同时通信采用多路复用。
- lO多路复用,单个线程中通过记录跟踪每一个sock(I/O流) 的状态来管理多个I/O流 。
其他特性:
- 更丰富的数据类型 ,虽然都是k、v结构,但 value可以存储很多的数据类型
- 完善的内存管理机制、保证数据一致性:持久化机制、过期策略
- 支持多种编程语言
- 高可用,集群、保证高可用
二、Redis应用场景
Redis提供五种数据类型:string,hash,list,set及zset(sorted set)。以下简单介绍下各种数据类型的应用场景:
1. String类型的应用
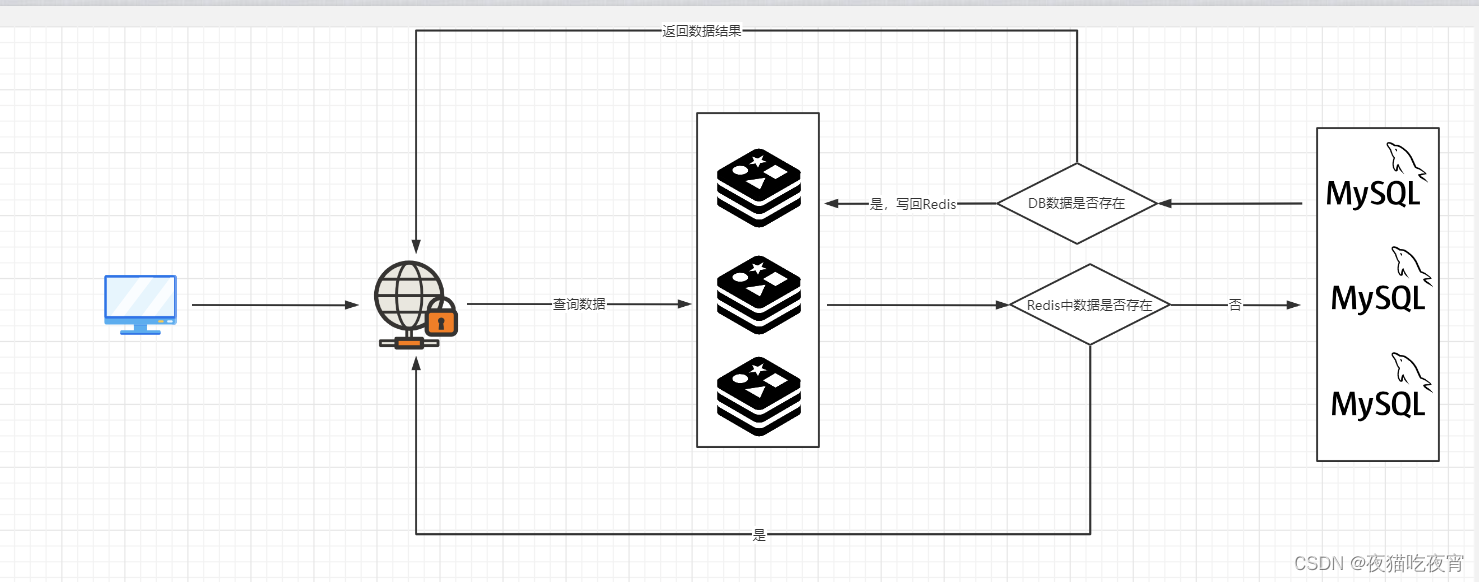
- 缓存相关场景 (缓存、 token,跟过期属性完美契合)
Redis性能比MySQL等数据库快,那么我们把第一次从数据库拿到的数据存至Redis,之后查询优先从Redis取,这样是不是会更快,如下所示:
- 线程安全的计数场景 (软限流、分布式ID等)
数据库数据ID一般用的是数据库自增的ID,如果分表,会出现不同表出现相同ID的情况,这样ID就不能标志数据的唯一性了。
所以我们解决思路:把生成ID这个步骤独立出来,不要在表中生成,可以交给第三方生成,并且生成的步骤不能有并发问题。
而我们的redis里面刚好有个incr 或者incryby的指令 ,递增 并且命令执行是单线程的 所以不会有并发导致ID相同。
2. Hash类型的应用
- 存储对象类的数据(官网说的) 比如一个对象下有多个字段
- 统计类的数据 我可以对单个统计数据进行单独操作
- 购物车 (一般人不会这样做,存在数据丢失)
3. List类型的应用
- 用户消息时间线,利用List的有序性记录时间线。
- 消息队列
4. Set类型的应用
- 抽奖 。spop跟srandmember 随机弹出或者获取元素。
- 点赞、签到等。 sadd 集合存储
- 交集并集 。关注等场景
5. ZSet类型的应用(有序Set)
- 排行榜
三、Redis事务
- mysql的事务,是保证多条sql要么一起执行,要么都不执行。在mysql里开启事务 begin 提交是commit 、 回滚是rollback 。
- redis的事务,存在两种情况:
①可能排队就错误,比如语法的错误 会报错给用户 并且丢失这次事务。
②执行指令的失败,比如你对string类型执行incr 这种事务里面的其他指令会正常执行,并且不提供回滚!
四、时间轮
Redis的定时调度是基于时间轮实现的,这里对时间轮进行简单的介绍。
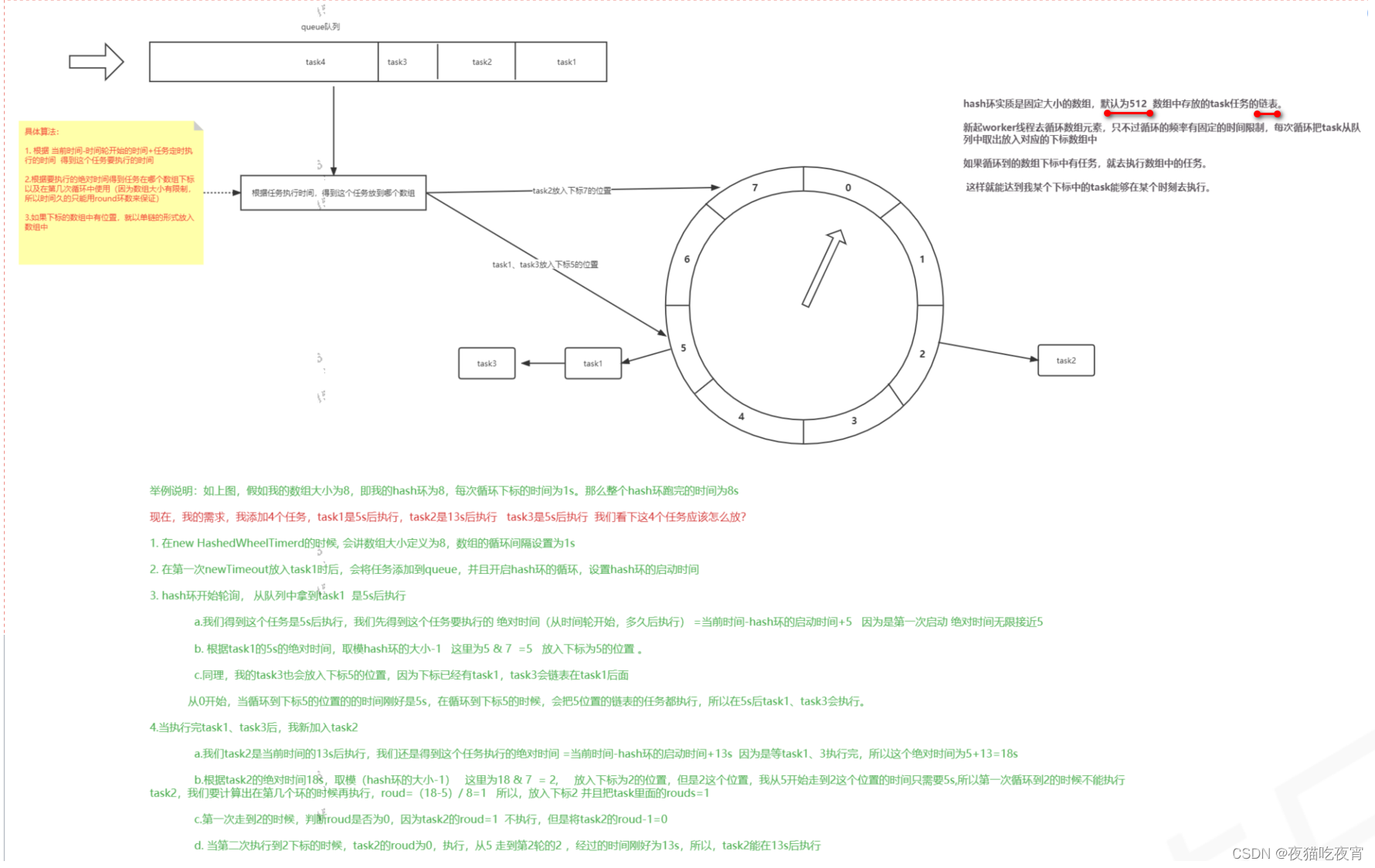
五、Redis管道
我们通常使用 Redis 的方式是,发送命令,命令排队,Redis 执行,然后返回结果,这个过程称为Round trip time(简称RTT, 往返时间)。但是如果有多条命令需要执行时,需要消耗 N 次 RTT,经过 N 次 IO 传输,这样效率明显很低。
于是 Redis 管道(pipeline)便产生了,一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。这就是管道(pipelining),减少了 RTT,提升了效率
重要说明: 使用管道发送命令时,服务器将被迫回复一个队列答复,占用很多内存。所以,如果你需要发送大量的命令,最好是把他们按照合理数量分批次的处理,例如10K的命令,读回复,然后再发送另一个10k的命令,等等。这样速度几乎是相同的,但是在回复这10k命令队列需要非常大量的内存用来组织返回数据内容。
使用场景:
- 在客户端下次写之前不需要读的场景下,大数据量并发写入。
- 对性能有要求。
- 管道里的命令不具备原子性,只能保证某个客户端发送的指令是顺序执行的,但是多客户端的命令会交叉执行。
- 不需要根据上一个指令的返回结果来判断后续的逻辑。
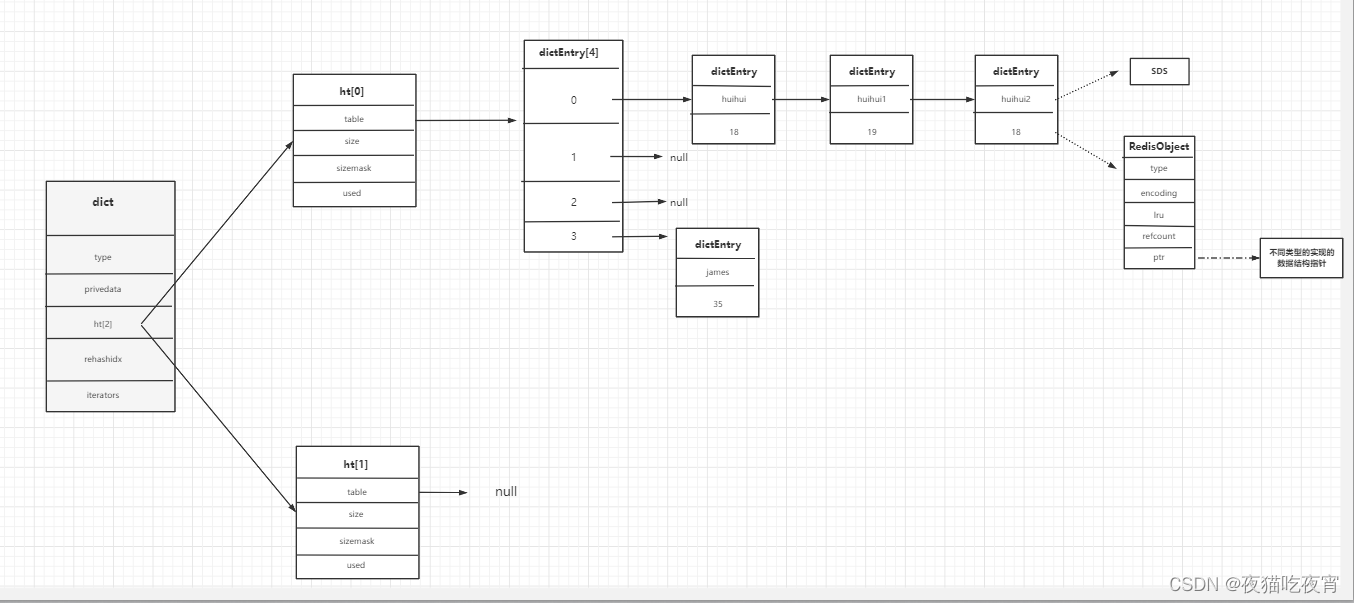
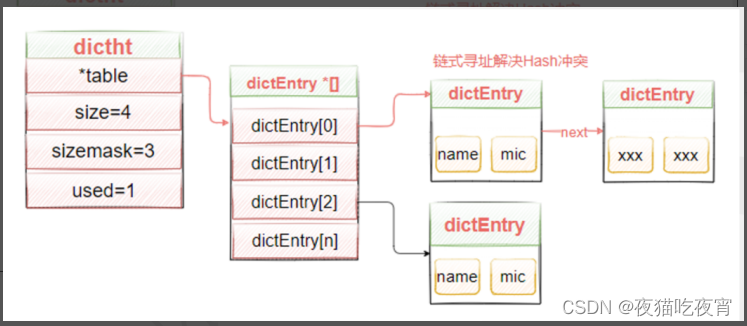
六、Redis的字典数据结构
1. redisDb数据结构(server.h文件)
数据最外层的结构为redisDb
typedef struct redisDb {dict *dict; /* The keyspace for this DB */ //数据库的键dict *expires; /* Timeout of keys with a timeout set */ //设置了超时时间的键dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/ //客户端等待的keysdict *ready_keys; /* Blocked keys that received a PUSH */dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */int id; /* Database ID */ //所在数据库IDlong long avg_ttl; /* Average TTL, just for stats */ //平均TTL,仅用于统计unsigned long expires_cursor; /* Cursor of the active expire cycle. */list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
2. dict数据结构 (dict.h文件)
数据实际存储在redisDb对象的dict中,结构如下:
typedef struct dict {dictType *type; //理解为面向对象思想,为支持不同的数据类型对应dictType抽象方法,不同的数据类型可以不同实现void *privdata; //也可不同的数据类型相关,不同类型特定函数的可选参数。dictht ht[2]; //2个hash表,用来数据存储 2个dicthtlong rehashidx; /* rehashing not in progress if rehashidx == -1 */ // rehash标记 -1代表不再rehashunsigned long iterators; /* number of iterators currently running */
} dict;
3. dictht结构(dict.h文件)
typedef struct dictht {dictEntry **table; //dictEntry 数组unsigned long size; //数组大小 默认为4 #define DICT_HT_INITIAL_SIZE 4unsigned long sizemask; //size-1 用来取模得到数据的下标值unsigned long used; //改hash表中已有的节点数据
} dictht;
4. dictEntry节点结构(dict.h文件)
typedef struct dictEntry {void *key; //keyunion {void *val;uint64_t u64;int64_t s64;double d;} v; //valuestruct dictEntry *next; //指向下一个节点
} dictEntry;
5. redisObject(server.h文件)
typedef struct redisObject {unsigned type:4; //数据类型 string hash listunsigned encoding:4; //底层的数据结构 跳表unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency* and most significant 16 bits access time). */int refcount; //用于回收,引用计数法void *ptr; //指向具体的数据结构的内存地址 比如 跳表、压缩列表
} robj;
6. 数据结构图
7. Redis发生Hash冲突为什么要头插?
头插在并发情况下会形成死链,所以HashMap在1.8之后使用的尾插。而Redis是单线程执行,使用头插法没有并发问题,也不会形成死链表;
同时,头插的性能比尾插的性能高很多,尾插必须找到链表的最后一个位置,而头插只需要加到数据下标,并且把next指向之前的第一个数据。
七、Redis扩容
1. 为什么要扩容?
dictEntry数组默认大小是4,如果不进行扩容,那么我们所有的数据都会以链表的形式添加至数组下标。随着数据量越来越大,之前只需要hash取模就能得到下标位置,现在得去循环我下标的链表,所以性能会越来越慢。
2. 什么时候扩容?
- .当没有fork子进程在进行RDB或者AOF持久化(内存的数据保存到磁盘防止丢失,后面详细讲解)时,ht[0]的used大于等于size时,触发扩容。
- .如果有子进程在进行RDB或者AOF时,ht[0]的used大于等于size的5倍的时候,会触发扩容。解释: 现在操作系统通过写时复制(copy-on-write)来优化子进程的使用效率。 在子线程进入RDB跟AOF时,如果发生大量内存写操作,会导致进程的性能降低 。所以,当在RDB或者AOF时,将扩容阈值放大到5倍。
3. 扩容步骤
①当满足我扩容条件,触发扩容时,判断是否在扩容,如果在扩容,或者扩容的大小小于现在的 ht[0].size,这次扩容不做。
② new一个新的dictht,大小为ht[0].used * 2(但是必须向上2的幂,比如6 ,那么大小为8) ,并且ht[1]=新创建的dictht。
③我们有个更大的table了,但是需要把数据迁移到ht[1].table ,所以将dict的rehashidx(数据迁移的偏移量)赋值为0 ,代表可以进行数据迁移了,也就是可以rehash了。
④等待数据迁移完成,数据不会马上迁移,而是采用渐进式rehash,慢慢的把数据迁移到ht[1]。
⑤当数据迁移完成,ht[0].table=ht[1] ,ht[1] .table = NULL、ht[1] .size = 0、ht[1] .sizemask = 0、 ht[1] .used = 0;
⑥ 把dict的rehashidex=-1。
4. 数据怎么迁移(渐进式Rehash)
假如一次性把数据迁移会很耗时间,会让单条指令等待很久很久。会形成阻塞,所以,Redis采用的是渐进式Rehash,所谓渐进式,就是慢慢的,不会一次性把所有数据迁移。
什么时候进行渐进式Rehash?
- 每次进行key的crud操作都会进行一个hash桶的数据迁移。
- 定时任务,进行部分数据迁移。
八、底层数据结构
Redis的5种数据类型(string hash list set zset),每种类型都有不同的数据结构来支持。
1. Strings
Redis中String的底层没有用c的char来实现,而是用了SDS(Simple Dynamic String)的数据结构来作为实现。并且提供了5种不同的类型。
SDS数据结构定义 (sds.h文件),其中sdshdr5 never used。
struct __attribute__ ((__packed__)) sdshdr5 {unsigned char flags; /* 3 lsb of type, and 5 msb ofstring length */char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* used */ //已使用的长度uint8_t alloc; /* excluding the header and nullterminator */ //分配的总容量 不包含头和空终止符unsigned char flags; /* 3 lsb of type, 5 unused bits*/ //低三位类型 高5bit未使用char buf[]; //数据buf 存储字符串数组
};
struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len; /* used */uint16_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits*/char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len; /* used */uint32_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits*/char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {uint64_t len; /* used */uint64_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits*/char buf[];
};
优势:
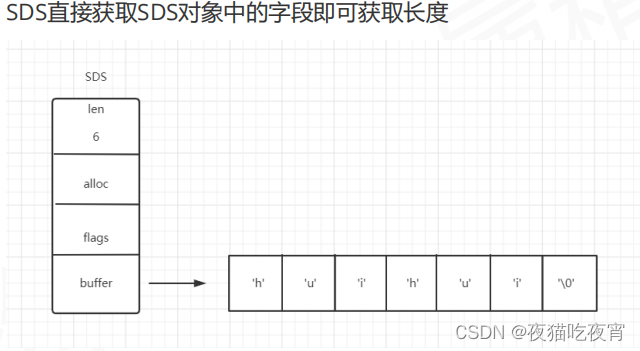
- c字符串不记录自身的长度,所以获取一个字符串长度的复杂度是O(N),但是SDS记录分配的长度alloc,已使用的长度len,获取长度为O(1)。
- 减少修改字符串带来的内存重分配次数。
例如:huihui 更改为 huihui niubi 字符串必须先申明内存,不然会导致内存溢出!截断,trim(huihui)的时候,需要把不再使用的空间回收,不然会内存泄漏。这样的话,如果操作的频率过多,则会导致性能下降!对于Redis是不能容忍的。
SDS则通过空间预分配与惰性空间释放2种策略解决了以上问题!
①空间预分配: SDS长度如果小于1MB,预分配跟长度一样的,大于1M,每次跟len的大小多1M。
②惰性空间释放: 截取的时候 不马上释放空间,供下次使用!同时提供相应的释放SDS未使用空间的API。 - 二进制安全
C字符串中的字符必须符合某种编码(比如ASCII),并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将被误认为是字符串结尾。因为c的字符是以空字符来判断这个字符串是否结束的。这些限制使得C字符串只能保存文本数据,而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
SDS字符串是否结束是根据len来,所以也就不会有这样的问题。
2. Hashes
Hashes 的底层数据结构可能有两种,ZipList 压缩列表 或者 ditcht hash表。
①ZipList 压缩列表
整体布局:
ziplist的总字节数 | 最后一个字节偏移量 | entry数量 | entry | ziplist结尾
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry><zlend>
- 压缩列表会根据存入的数据的不同类型以及不同大小,分配不同大小的空间。所以是为了节省内存而采用的。
- 因为是一块完整的内存空间,当里面的元素发生变更时,会产生连锁更新,严重影响我们的访问性能。所以,只适用于数据量比较小的场景。
所以,Redis会有相关配置,Hashes只有小数据量的时候才会用到ziplist。当hash对象同时满足以下两个条件的时候,使用ziplist编码:
-
哈希对象保存的键值对数量<512个;
-
所有的键值对的健和值的字符串长度都<64byte(一个英文字母一个字节)。
redis.conf配置hash-max-ziplist-value 64 // ziplist中最大能存放的值长度 hash-max-ziplist-entries 512 // ziplist中最多能存放的entry节点数量
②ditcht hash表
3. Lists
Lists使用的底层数据结构为:quickList 快速列表。
quickList 兼顾了ziplist的节省内存,并且一定程度上解决了连锁更新的问题,我们的quicklistNode节点里面是个ziplist,每个节点是分开的。那么就算发生了连锁更新,也只会发生在一个quicklistNode节点。
quicklist.h
typedef struct
{struct quicklistNode *prev; //前指针struct quicklistNode *next; //后指针unsigned char *zl; //数据指针 指向ziplist结果unsigned int sz; //ziplist大小 /* ziplist size in bytes */unsigned int count : 16; /* count of items in ziplist */ //ziplist的元素unsigned int encoding : 2; /* RAW==1 or LZF==2 */ //是否压缩, 1没有压缩 2 lzf压缩unsigned int container : 2; /* NONE==1 or ZIPLIST==2*/ //预留容器字段unsigned int recompress : 1; /* was this node previous compressed? */unsigned int attempted_compress : 1; /* node can't compress; too small */unsigned int extra : 10; /* more bits to steal for future usage */ //预留字段
} quicklistNode;
整体结构图:
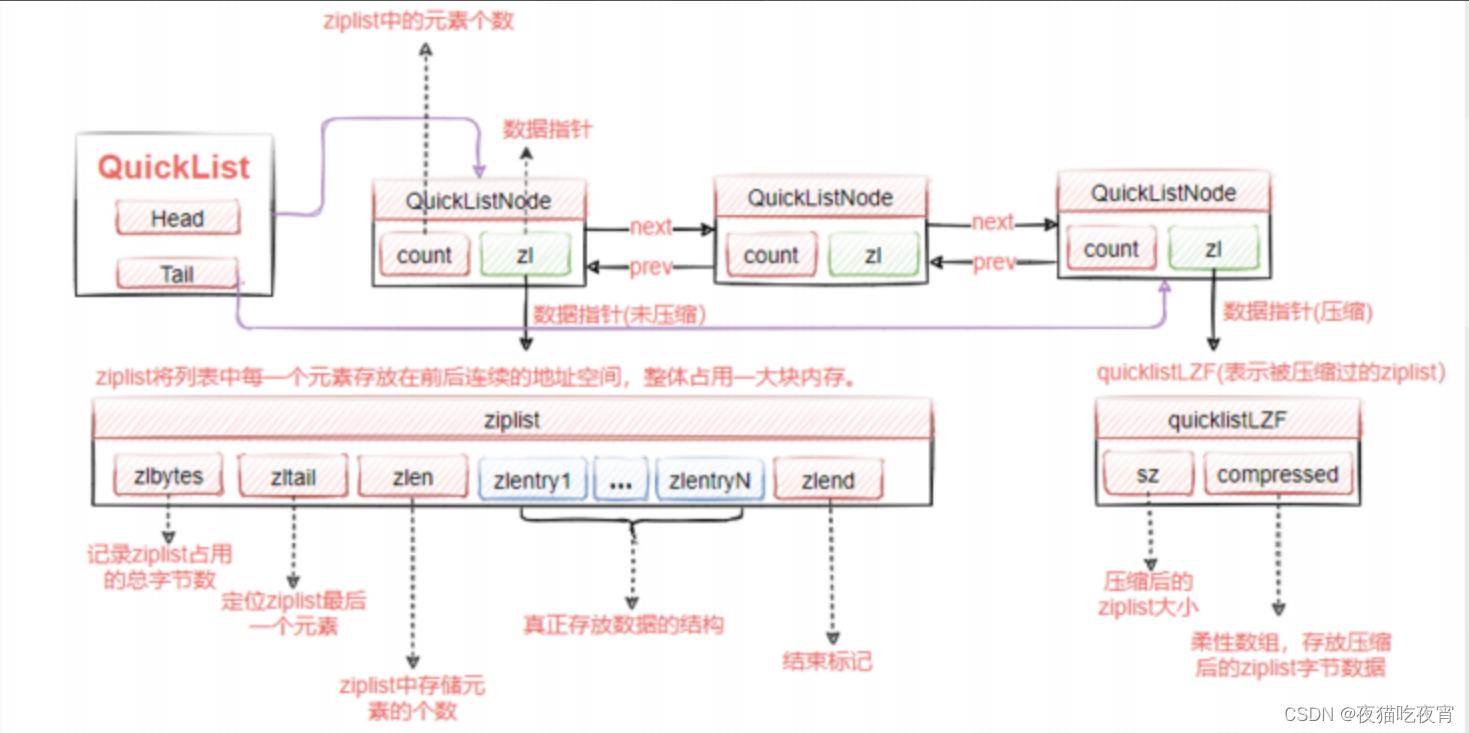
quicklist配置: 每个node的ziplist元素的大小可以通过list-max-ziplist-size进行配置:如果这个配置的值为正数,代表quicklistNode的ziplist的node的数量;如果为负数 固定-5到-1,则代表ziplist的大小。
4. Sets
Redis用intset或hashtable存储set。满足下面条件,就用inset存储。
①如果不是整数类型,就用dictht hash表(数组+链表)。
②如果元素个数超过512个,也会用hashtable存储。跟一个配置有关:
set-max-intset-entries 512
不满足条件就用hashtable。set的key没有value,用hashtable存储时,value存null就好。
5. ZSet(Sorted Sets)
- 默认使用ziplist编码(hash的小编码,quicklist的Node,也都是ziplist)
在ziplist的内部,按照score排序递增来存储。插入的时候要移动之后的数据。
如果元素数量大于等于128个,或者任一member长度大于等于64字节使用skiplist+dict存储。
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
如果不满足条件,采用跳表(skiplist)。结构定义(server.h)如下:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {sds ele; //sds数据double score; //scorestruct zskiplistNode *backward; //后退指针//层级数组struct zskiplistLevel {struct zskiplistNode *forward; //前进指针unsigned long span; //跨度} level[];
} zskiplistNode;//跳表列表
typedef struct zskiplist {struct zskiplistNode *header, *tail; //头尾节点unsigned long length; //节点数量int level; //最大的节点层级
} zskiplist;
ZSKIPLIST_MAXLEVEL默认32 定义在server.h
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
原理图:
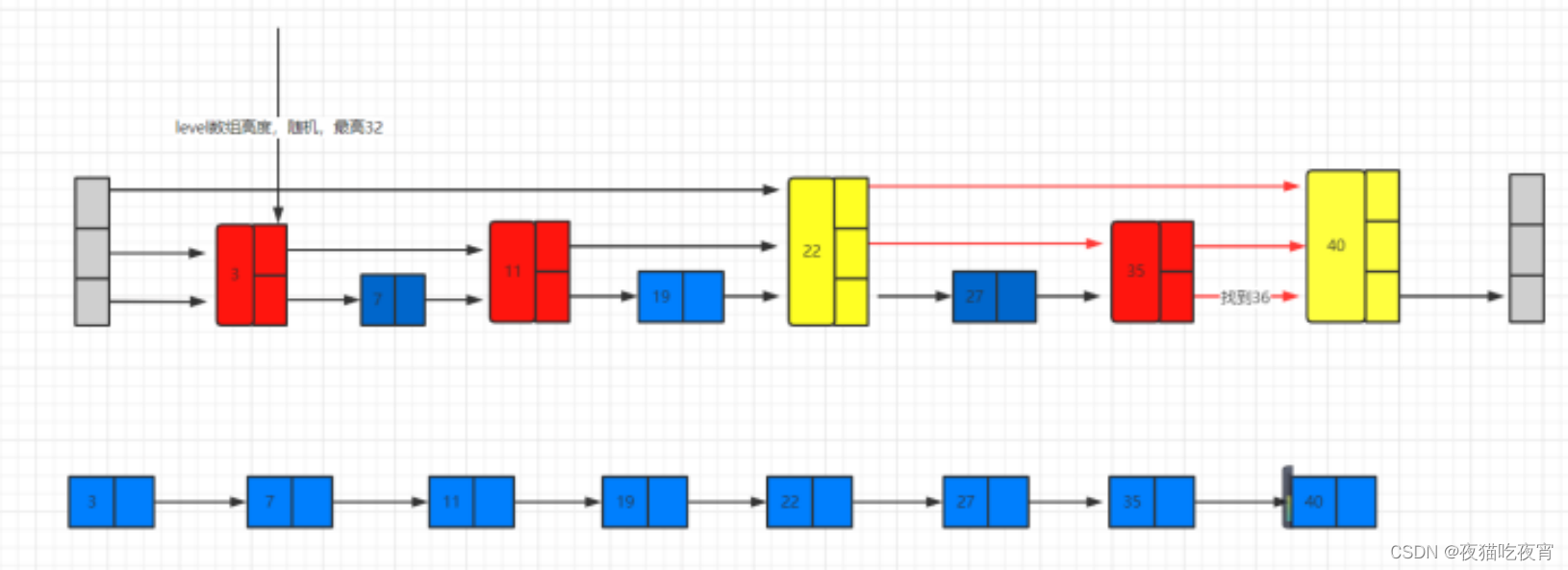
如图,已有数据3.7.11.19.22.27.35.40,假如我找27的数据。
- 只有一个链表的场景:我需要一个一个遍历,随着数据量越大,效率越慢
- 随机多层级跳表:找27,会从最外层开始找,在22-40之间,再找第二层,在22到35之间,就能找到27。在外层的数据,查询的速度越高,比如找22,只需要一次。
九、Redis过期删除策略
Redis keys过期有两种方式:被动和主动方式。
**惰性删除策略:**当一些客户端尝试访问过期 key 时,Redis 发现 key 已经过期便删除掉这些 key。
当然,这样是不够的,因为有些过期的 keys,可能永远不会被访问到。无论如何,这些 keys 应该过期,所以 Redis 会定时删除这些 key。
Redis默认每秒会进行10次(可以通过redis.conf中的hz值修改,提高频率会占用更多CPU)的以下操作:
- 测试随机的20个keys进行相关过期检测。
- 删除所有已经过期的keys。
- 如果有多于25%的keys过期,重复步奏1
同时,为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
注意: 如果某一时刻,有大量key同时过期,Redis 会持续扫描过期字典,造成客户端响应卡顿,因此设置过期时间时,就尽量避免这个问题,在设置过期时间时,可以给过期时间设置一个随机范围,避免同一时刻过期。
十、Redis内存淘汰
1. 内存淘汰策略
当现有内存大于 maxmemory 时,便会触发redis主动淘汰内存方式,通过设置 maxmemory-policy ,有如下几种淘汰方式:
- volatile-lru:淘汰所有设置了过期时间的键值中最久未使用的键值;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- volatile-random:随机淘汰设置了过期时间的任意键值;
- allkeys-random:随机淘汰任意键值;
- volatile-ttl:优先淘汰更早过期的键值;
- noeviction:不淘汰任何数据,当内存不足时,新增操作会报错,Redis 默认内存淘汰策略;
其中 allkeys-xxx 表示从所有的键值中淘汰数据,而 volatile-xxx 表示从设置了过期键的键值中淘汰数据。
2. 内存淘汰策略的使用
- 优先使用allkeys-lru策略。这样,可以充分利用LRU算法的优势,把最近最常访问的数据留在缓存中,提升应用的访问性能。
- 如果你的业务数据中有明显的冷热数据的区分,建议使用allkeys-lru策略。
- 如果业务应用中的数据访问频率不大,没有明显的冷热数据区分,建议使用allkeys-random策略,随机淘汰数据即可。
- 如果业务有置顶的需求,比如置顶新闻、置顶视频,那么,可以使用 volatile-lru策略,同时不给这些置顶数据设置过期时间。这样一来,这些需要置顶的数据一直不会被删除,而其他数据会在过期时根据 LRU 规则进行筛选。
3. 内存淘汰算法
除了随机删除和不删除之外,主要有两种淘汰算法:LRU 算法和 LFU 算法。
LRU
- LRU 全称是Least Recently Used译为最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。
- 一般 LRU 算法的实现基于链表结构,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可。
- Redis 使用的是一种 近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是给现有的数据结构添加一个额外的字段,用于记录此键值的最后一次访问的时间戳,Redis 内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
LFU
除了 LRU 算法,Redis 在 4.0 版本引入了 LFU 算法,就是最不频繁使用(Least Frequently Used,LFU)算法。
- LRU 算法:淘汰最近最少使用的数据,它是根据时间维度来选择将要淘汰的元素,即删除掉最长时间没被访问的元素。
- LFU 算法:淘汰最不频繁访问的数据,它是根据频率维度来选择将要淘汰的元素,即删除访问频率最低的元素。如果两个元素的访问频率相同,则淘汰最久没被访问的元素。
LFU 的基本原理
- LFU(Least Frequently Used)算法,即最少访问算法,根据访问缓存的历史频率来淘汰数据,核心思想是“如果数据在过去一段时间被访问的次数很少,那么将来被访问的概率也会很低”。
- 它是根据频率维度来选择将要淘汰的元素,即删除访问频率最低的元素。如果两个元素的访问频率相同,则淘汰最久没被访问的元素。也就是说 LFU 淘汰的时候会选择两个维度,先比较频率,选择访问频率最小的元素;如果频率相同,则按时间维度淘汰掉最久远的那个元素。
十一、Redis持久化机制
1. RDB快照(Redis Database)
RDB 是 Redis 默认的持久化方案。当满足一定条件的时候,会把当前内存中的数据写入磁盘,生成一个快照文件dump.rdb(默认)。
触发时机
①自动触发,分以下几种情况
-
配置触发
save 900 1 900s检查一次,至少有1个key被修改就触发 save 300 10 300s检查一次,至少有10个key被修改就触发 save 60 10000 60s检查一次,至少有10000个key被修改 -
shutdown正常关闭
-
flushall指令触发
数据清空指令会触发RDB操作,并且是触发一个 空的 RDB文件,所以,如果在没有开启其他的持久化的时候,flushall是可以删库跑路的,在生产环境慎用。
②手动触发
- save指令:主线程去进行备份,备份期间不会去处理其他的指令,其他指令必须等待。
- bgsave指令:子线程去进行备份,其他指令正常执行。
如何备份
①新起子线程,子线程会将当前Redis的数据写入一个临时文件;
②当临时文件写完成后,会替换旧的RDB文件。
优势
RDB恢复与备份都非常的快。
- 备份是个非常紧凑型的文件,非常适合备份与灾难恢复。
- 最大限度的提升了性能,会fork一个子进程,父进程永远不会产于磁盘IO或者类似操作。
- 更快的重启。
不足
- 数据安全性不是很高,因为是根据配置的时间来备份,假如每5分钟备份一次,也会有5分钟数据的丢失。
- .经常fork子进程,所以比较耗CPU,对CPU不友好。
2. AOF(Append Only File)
AOF默认关闭,开启后,每次的更改命令都会附加到AOF文件中。
AOF同步机制
AOF记录每个写操作,但并不是必须每次都与磁盘进行交互,Redis提供了几种策略,可以根据需要进行选择:
# appendfsync always 表示每次写入都执行fsync(刷新)函数 性能会非常非常慢 但是非常安全
appendfsync everysec 每秒执行一次fsync函数 可能丢失1s的数据,默认,最多会有1s丢失
# appendfsync no 由操作系统保证数据同步到磁盘,速度最快 你的数据只需要交给操作系统就行
AOF重写机制
由于AOF是追加的形式,所以文件会越来越大,越大的话,数据加载越慢。所以我们需要对AOF文件进行重写。
重写就是做了这么一件事情,把当前内存的数据重写下来,然后把之前的追加的文件删除。
重写流程
在Redis7之前:
① Redis fork一个子进程,在一个临时文件中写入新的AOF (当前内存的数据生成的新的AOF)。
②那么在写入新的AOF的时候,主进程还会有指令进入,那么主进程会在内存缓存区中累计新的指令 (但是同时也会写在旧的AOF文件中,就算重写失败,也不会导致AOF损坏或者数据丢失)。
③ 如果子进程重写完成,父进程会收到完成信号,并且把内存缓存中的指令追加到新的AOF文件中。
④替换旧的AOF文件 ,并且将新的指令附加到重写好的AOF文件中。
重写时机
配置文件redis.conf中
# 重写触发机制
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb 就算达到了第一个百分比的大小,也必须大于 64M
说明:在 aof 文件小于64mb的时候不进行重写,当到达64mb的时候,就重写一次。重写后的 aof 文件可能是40mb。上面配置了auto-aof-rewrite-percentag为100,即 aof 文件到了80mb的时候,进行再次重写。
优势
- .安全性高,就算默认的持久化同步机制,也最多只会导致1s丢失。
- AOF由于某些原因,比如磁盘满了等导致追加失败,也能通过redis-check-aof 工具来修复。
- AOF内容格式都是追加的日志,所以可读性更高。
不足
- 数据集一般比RDB大。
- 持久化跟数据加载比RDB更慢。
- 在7.0之前,重写的时候,新的指令会缓存在内存区,所以会导致大量的内存使用。并且重写期间,会跟磁盘进行2次IO,一个是写入老的AOF文件,一个是写入新的AOF文件。
十二、Redis集群
1. Redis主从
主从的作用:
- 故障恢复 主挂了或者数据丢失了,还有数据冗余
- 负载均衡 流量分发,可以读写分离,减少单实例的读写压力
2. Redis哨兵模式
Redis sentinel ,是独立于Redis服务的单独的服务,两者之间相互通讯。在集群不可用的时候,Redis sentinel为Redis提供了高可用性。并且提供了监测、通知、自动故障转移、配置提供等功能。
监控: 能够监控Redis各实例是否正常工作
通知: 如果Redis实例出现问题,能够通知给其他实例以及sentinel
自动故障转移: 当master宕机,slave可以自动升级为master
配置提供: sentinel可以提供Redis的master实例地址,那么客户端只需要跟sentinel进行连接,master挂了后会提供新的master
哨兵故障转移流程
①当某个sentinel 跟master通信时(默认1s发送ping),发现在一定时间内(down-after-milliseconds) 没有收到master的有效的回复。这个时候这个sentinel就会认为master是不可用的,对其标记一个状态,这个状态就是SDOWN(Subjectively Downcondition 主观下线)。
② SDOWN时,不会触发故障转移,会去询问其他的sentinel是否能连上master,如果超过Quorum(法定人数)的sentinel都认为master不可用,都标记SDOWN状态,这个时候,master可能就真的是down了。那么就会将master标为ODOWN(Objectively Downcondition 客观下线)
③当状态为ODWON时,需要去触发故障转移,但是有这么多的sentinel,我们需要选一个sentinel去做故障转移这件事情,并且这个sentinel在做故障转移的时候,其他sentinel不能进行故障转移。
④ 所以,我们需要选举一个sentinel来做这件事情,其中这个选举过程有2个因素:
- Quorum如果小于等于一半,那么必须超过半数的sentinel授权,你才能去做故障迁移,比如5台 sentinel,你配置的Quorum=2,那么选举的时候必须有3(5台的一半以上)人同意。
- Quorum如果大于一半,那么必须Quorum的sentinel授权,故障迁移才能启动。
选哪个slave来变成master?
①与master断开连接的时间 :如果slave与主服务器断开的连接时间超过主服务器配置的超时时间
(down-after-milliseconds)的十倍,被认为不适合成为master,直接去除资格。
②优先级:配置 replica-priority,replica-priority越小,优先级越高,但是配置为0的时候,永远没有资格升为master。
③已复制的偏移量:比较slave的赋值的数据偏移量,数据最新的优先升级为master。
④Run ID (每个实例启动都会有个Run ID ):通过info server可以查看。
3. 脑裂问题
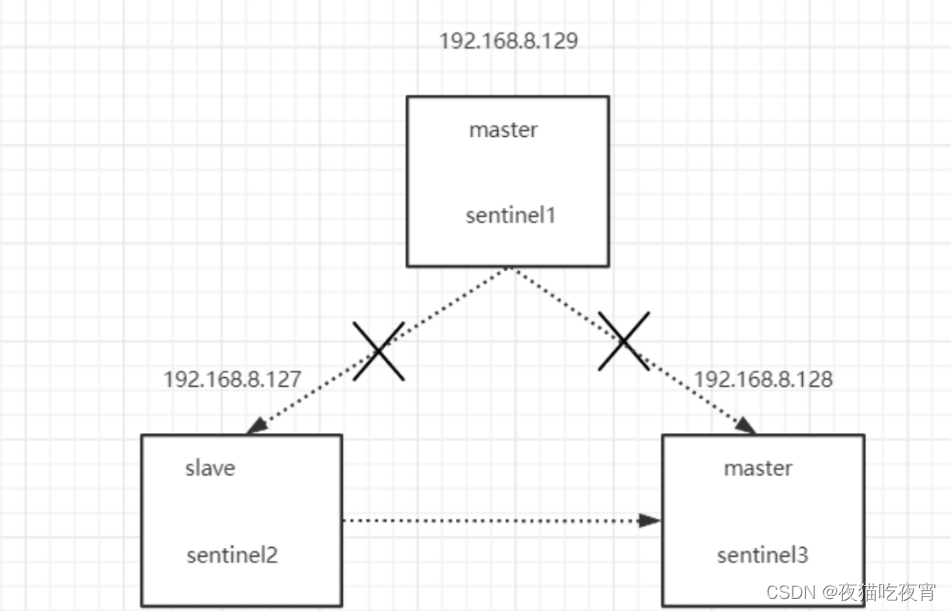
问题描述: 初始129是master,假如129网络断开,跟127.128连接断开后,128sentinel发起故障转移。发现sentinel的个数超过一半,能够发起故障转移。将128升级为master,导致128.129同时2个master并可用。,此时,client会向不同的master写数据,从而在master恢复的时候会导致数据丢失。
解决方案:
在Redis.cfg文件中有2个配置:
min-replicas-to-write 1 至少有1个从节点同步到我主节点的数据,但是由于是异步同步,所以是最终一致性 不会确保有数据写入
min-replicas-max-lag 10 判断上面1个的延迟时间必须小于等于10s
说明
作者在工作之余,花费一个月左右的时间对Redis相关知识点进行了全面梳理,成果来之不易,希望摘要或转载的同学们,能够注明出处,万分感谢。
如果文章内容有遗漏或者不妥之处,欢迎补充和指教。
参考文献
内存淘汰相关:
https://blog.csdn.net/LJZFlying/article/details/124211266
https://www.cnblogs.com/frankyou/p/16283974.html