版权申明:转载和引用图片,都必须经过书面同意。获得留言同意即可
本文使用图片多为本人所画,需要高清图片可以留言联系我,先点赞后取图
这篇博文比较推荐的yolo v3代码是qwe的keras版本,复现比较容易,代码相对来说比较容易理解。同学们可以结合代码和博文共同理解v3的精髓。
github地址:https://github.com/qqwweee/keras-yolo3
前言
前言就是唠唠嗑,想直接看干货可以跳过前言,直接看Yolo v3。
yolo_v3是我最近一段时间主攻的算法,写下博客,以作分享交流。
看过yolov3论文的应该都知道,这篇论文写得很随意,很多亮点都被作者都是草草描述。很多骚年入手yolo算法都是从v3才开始,这是不可能掌握yolo精髓的,因为v3很多东西是保留v2甚至v1的东西,而且v3的论文写得很随心。想深入了解yolo_v3算法,是有必要先了解v1和v2的。以下是我关于v1和v2算法解析所写的文章:
v1算法解析:《yolo系列之yolo v1》
v2算法解析:《yolo系列之yolo v2》
yolo_v3作为yolo系列目前最新的算法,对之前的算法既有保留又有改进。先分析一下yolo_v3上保留的东西:
- “分而治之”,从yolo_v1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样。
- 采用"leaky ReLU"作为激活函数。
- 端到端进行训练。一个loss function搞定训练,只需关注输入端和输出端。
- 从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
- 多尺度训练。在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。
yolo每一代的提升很大一部分决定于backbone网络的提升,从v2的darknet-19到v3的darknet-53。yolo_v3还提供替换backbone——tiny darknet。要想性能牛叉,backbone可以用Darknet-53,要想轻量高速,可以用tiny-darknet。总之,yolo就是天生“灵活”,所以特别适合作为工程算法。
当然,yolo_v3在之前的算法上保留的点不可能只有上述几点。由于本文章主要针对yolo_v3进行剖析,不便跑题,下面切入正题。
YOLO v3
网上关于yolo v3算法分析的文章一大堆,但大部分看着都不爽,为什么呢?因为他们没有这个玩意儿:
这里推荐的模型结构可视化工具是:Netron
netron方便好用,可以直观看到yolo_v3的实际计算结构,精细到卷积层。But,要进一步在人性化的角度分析v3的结构图,还需要结合论文和代码。对此,我是下了不少功夫。
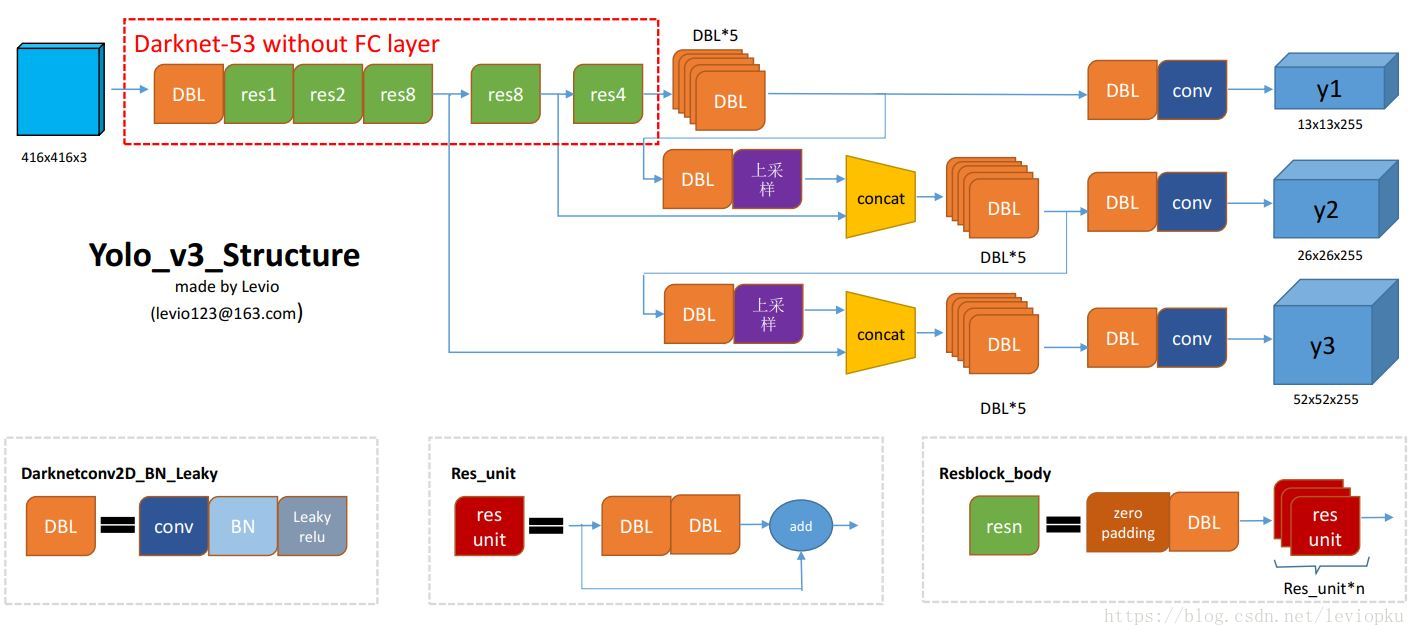
上图表示了yolo_v3整个yolo_body的结构,没有包括把输出解析整理成咱要的[box, class, score]。对于把输出张量包装成[box, class, score]那种形式,还需要写一些脚本,但这已经在神经网络结构之外了(我后面会详细解释这波操作)。
为了让yolo_v3结构图更好理解,我对图1做一些补充解释:
DBL: 如图1左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图1的右下角直观看到,其基本组件也是DBL。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
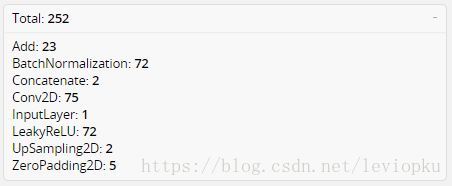
我们可以借鉴netron来分析网络层,整个yolo_v3_body包含252层,组成如下:
1. backbone
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的 1 / 2 5 1/2^5 1/25,即1/32。输入为416x416,则输出为13x13(416/32=13)。
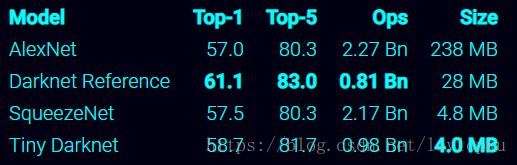
yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。可以对比v2和v3的backbone看看:(DarkNet-19 与 DarkNet-53)
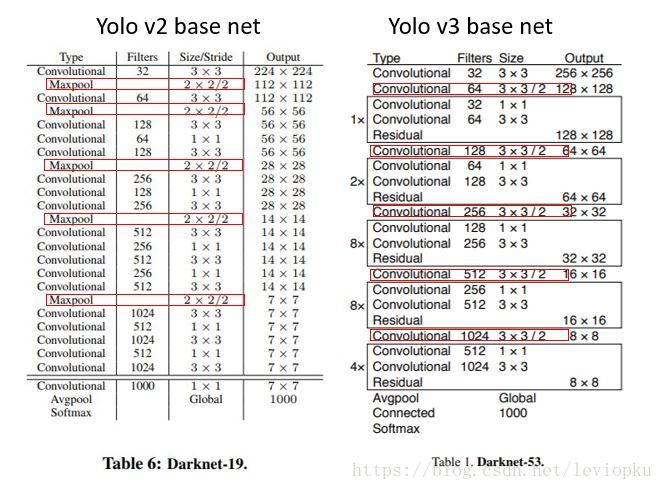
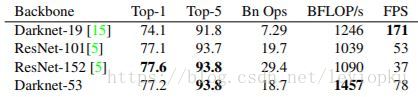
这也是416x416输入得到13x13输出的原因。从图2可以看出,darknet-19是不存在残差结构(resblock,从resnet上借鉴过来)的,和VGG是同类型的backbone(属于上一代CNN结构),而darknet-53是可以和resnet-152正面刚的backbone,看下表:
2. Output
对于图1而言,更值得关注的是输出张量:
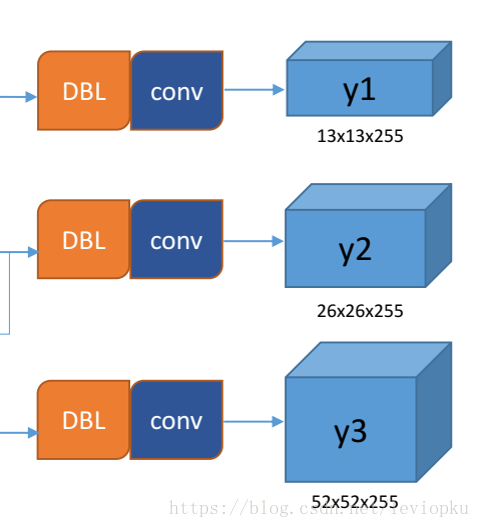
yolo v3输出了3个不同尺度的feature map,如上图所示的y1, y2, y3。这也是v3论文中提到的为数不多的改进点:predictions across scales
这个借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体。
y1,y2和y3的深度都是255,边长的规律是13:26:52
对于COCO类别而言,有80个种类,所以每个box应该对每个种类都输出一个概率。
yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3*(5 + 80) = 255。这个255就是这么来的。(还记得yolo v1的输出张量吗? 7x7x30,只能识别20类物体,而且每个cell只能预测2个box,和v3比起来就像老人机和iphoneX一样)
v3用上采样的方法来实现这种多尺度的feature map,可以结合图1和图2右边来看,图1中concat连接的两个张量是具有一样尺度的(两处拼接分别是26x26尺度拼接和52x52尺度拼接,通过(2, 2)上采样来保证concat拼接的张量尺度相同)。作者并没有像SSD那样直接采用backbone中间层的处理结果作为feature map的输出,而是和后面网络层的上采样结果进行一个拼接之后的处理结果作为feature map。为什么这么做呢? 我感觉是有点玄学在里面,一方面避免和其他算法做法重合,另一方面这也许是试验之后并且结果证明更好的选择,再者有可能就是因为这么做比较节省模型size的。这点的数学原理不用去管,知道作者是这么做的就对了。
3. some tricks
上文把yolo_v3的结构讨论了一下,下文将对yolo v3的若干细节进行剖析。
Bounding Box Prediction
b-box预测手段是v3论文中提到的又一个亮点。先回忆一下v2的b-box预测:想借鉴faster R-CNN RPN中的anchor机制,但不屑于手动设定anchor prior(模板框),于是用维度聚类的方法来确定anchor box prior(模板框),最后发现聚类之后确定的prior在k=5也能够又不错的表现,于是就选用k=5。后来呢,v2又嫌弃anchor机制线性回归的不稳定性(因为回归的offset可以使box偏移到图片的任何地方),所以v2最后选用了自己的方法:直接预测相对位置。预测出b-box中心点相对于网格单元左上角的相对坐标。
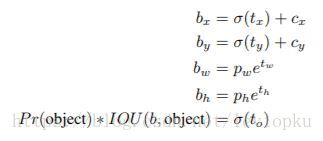
yolo v2直接predict出( t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th, t o t_o to),并不像RPN中anchor机制那样去遍历每一个pixel。可以从上面的公式看出,b-box的位置大小和confidence都可以通过( t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th, t o t_o to)计算得来,v2相当直接predict出了b-box的位置大小和confidence。box宽和高的预测是受prior影响的,对于v2而言,b-box prior数为5,在论文中并没有说明抛弃anchor机制之后是否抛弃了聚类得到的prior(没看代码,所以我不能确定),如果prior数继续为5,那么v2需要对不同prior预测出 t w t_w tw和 t h t_h th。
对于v3而言,在prior这里的处理有明确解释:选用的b-box priors 的k=9,对于tiny-yolo的话,k=6。priors都是在数据集上聚类得来的,有确定的数值,如下:
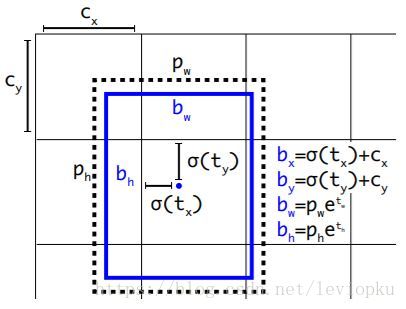
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
每个anchor prior(名字叫anchor prior,但并不是用anchor机制)就是两个数字组成的,一个代表高度另一个代表宽度。
v3对b-box进行预测的时候,采用了logistic regression。这一波操作sao得就像RPN中的线性回归调整b-box。v3每次对b-box进行predict时,输出和v2一样都是( t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th, t o t_o to),然后通过公式1计算出绝对的(x, y, w, h, c)。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。作者在论文种的描述如下:
If the bounding box prior is not the best but does overlap a ground truth object by more than some threshold we ignore the prediction, following[17]. We use the threshold of 0.5. Unlike [17] our system only assigns one bounding box prior for each ground truth object.
如果模板框不是最佳的即使它超过我们设定的阈值,我们还是不会对它进行predict。
不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模。
疑问解答和说明:
在评论里有同学问我关于输出的问题,看来我在这里没有说的很清楚。了解v3输出的输出是至关重要的。第一点, 9个anchor会被三个输出张量平分的。根据大中小三种size各自取自己的anchor。第二点,每个输出y在每个自己的网格都会输出3个预测框,这3个框是9除以3得到的,这是作者设置
的,我们可以从输出张量的维度来看,13x13x255。255是怎么来的呢,3*(5+80)。80表示80个种类,5表
示位置信息和置信度,3表示要输出3个prediction。在代码上来看,3*(5+80)中的3是直接由
num_anchors//3得到的。第三点,作者使用了logistic回归来对每个anchor包围的内容进行了一个目标性评分(objectness score)。
根据目标性评分来选择anchor prior进行predict,而不是所有anchor prior都会有输出。
loss function
对掌握Yolo来讲,loss function不可谓不重要。在v3的论文里没有明确提所用的损失函数,确切地说,yolo系列论文里面只有yolo v1明确提了损失函数的公式。对于yolo这样一种讨喜的目标检测算法,就连损失函数都非常讨喜。在v1中使用了一种叫sum-square error的损失计算方法,就是简单的差方相加而已。想详细了解的可以看我关于v1解释的博文。我们知道,在目标检测任务里,有几个关键信息是需要确定的: ( x , y ) , ( w , h ) , c l a s s , c o n f i d e n c e (x, y), (w, h), class, confidence (x,y),(w,h),class,confidence
根据关键信息的特点可以分为上述四类,损失函数应该由各自特点确定。最后加到一起就可以组成最终的loss_function了,也就是一个loss_function搞定端到端的训练。可以从代码分析出v3的损失函数,同样也是对以上四类,不过相比于v1中简单的总方误差,还是有一些调整的:
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2],from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[..., 2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + \(1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5],from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True)xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
以上是一段keras框架描述的yolo v3 的loss_function代码。忽略恒定系数不看,可以从上述代码看出:除了w, h的损失函数依然采用总方误差之外,其他部分的损失函数用的是二值交叉熵。最后加到一起。那么这个binary_crossentropy又是个什么玩意儿呢?就是一个最简单的交叉熵而已,一般用于二分类,这里的两种二分类类别可以理解为"对和不对"这两种。关于binary_crossentropy的公式详情可参考博文《常见的损失函数》。
总结
v3毫无疑问现在成为了工程界首选的检测算法之一了,结构清晰,实时性好。这是我十分安利的目标检测算法,更值得赞扬的是,yolo_v3给了近乎白痴的复现教程,这种气量在顶层算法研究者中并不常见。你可以很快的用上v3,但你不能很快地懂v3,我花了近一个月的时间才对v3有一个清晰的了解(可能是我悟性不够哈哈哈)。在算法学习的过程中,去一些浮躁,好好理解算法比只会用算法难得很多。



![【群智能算法改进】一种改进的算术优化算法 改进算术优化算法 改进AOA[2]【Matlab代码#38】](https://img-blog.csdnimg.cn/ea4090755e2b40f9a8e2512d59498307.png#pic_center)