在我之前的文章中,关于手写文字、手写数字、手写字母的检测识别相关的项目都有了不少的实践了,这里就不在赘述了,感兴趣的话可以自行移步阅读即可。
《基于轻量级目标检测模型实现手写汉字检测识别计数》
《python开发构建基于机器学习模型的手写数字识别系统》
《Yolov3目标检测实战【实现图像中随机出现手写数字的检测】》
《Python 手写数字识别实战分享》
《超轻量级目标检测模型Yolo-FastestV2基于自建数据集【手写汉字检测】构建模型训练、推理完整流程超详细教程》
《python开发构建轻量级卷积神经网络模型实现手写甲骨文识别系统》
《python基于yolov7开发构建手写甲骨文检测识别系统》
本文是手写甲骨文检测识别三部曲的终章,也是建立在前面两篇文章的数据基础上开发构建的基于轻量级的yolov5s系列的模型,首先看下效果图:
数据集与前文yolov7模型所用的数据集是完全一致的,这里就不再赘述了。
模型所用配置文件如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 40 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
训练数据配置如下:
# Dataset
path: ./dataset
train:- images/train
val:- images/test
test:- images/test# Classes
names:0: 01021: 01032: 01043: 01054: 01065: 01076: 01087: 01098: 01109: 011110: 011211: 011312: 011413: 011514: 011615: 011716: 011817: 011918: 012019: 012120: 012221: 012322: 012423: 012524: 012625: 012726: 012827: 012928: 013029: 013130: 013231: 013332: 013433: 013534: 013635: 013736: 013837: 013938: 014039: 0141共包含40种不同的甲骨文字,使用到的仿真数据集为4w。
默认执行100次epoch的迭代计算,结果评估详情如下所示:
【混淆矩阵】
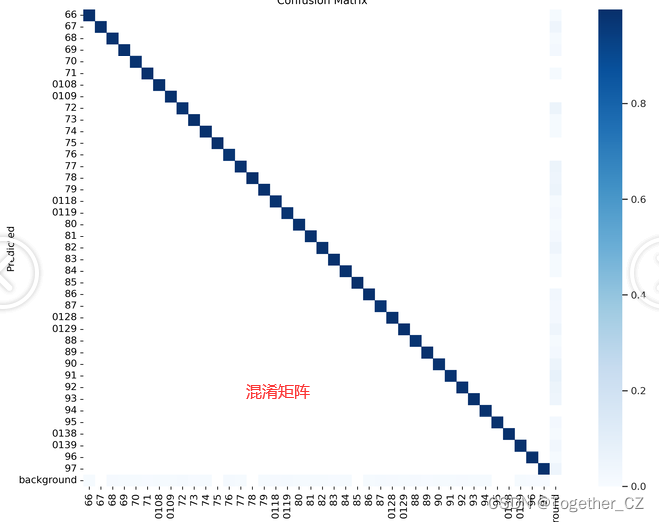
【F1值曲线和PR曲线】

【精确率和召回率曲线】
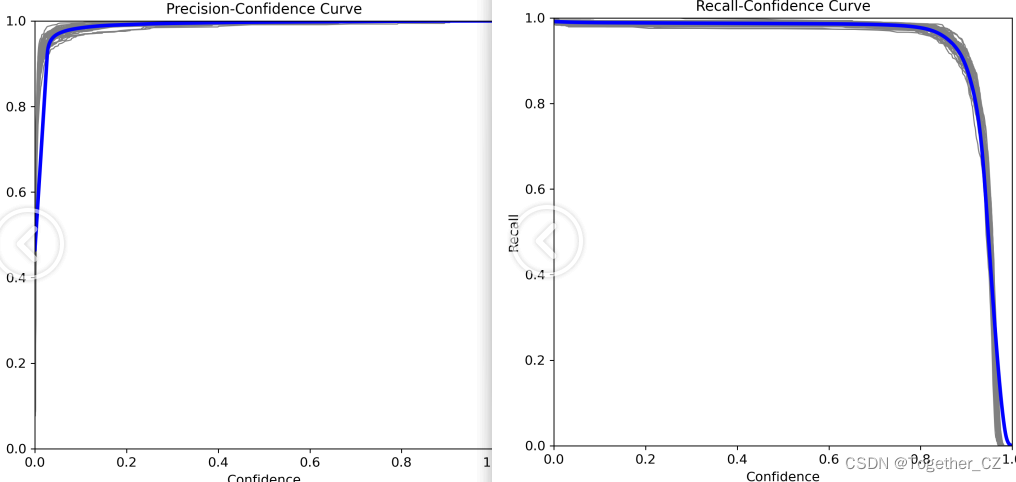
【训练可视化】
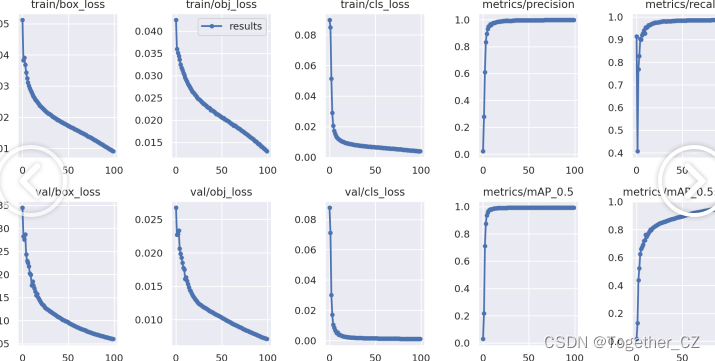
【 batch计算实例】:

从评估结果上来看:模型的检测和和识别效果已经是非常出色了已经。不过这个毕竟是实验环境下仿真数据集,真实环境下肯定是更加复杂多变的,而且真实场景下的数据成本也是很高的,这里只是学习实践。