一、消失的异常堆栈
如何快速定位问题?想必大家心中都有自己的答案,当然最简单直接的办法还是查找异常堆栈信息。
然而有时异常堆栈并不完整,只有一句描述,如下:
Caused by: java.lang.NullPointerException造成这种现象的原因其实很简单,原因如下:
JIT编译器对异常进行了优化,当代码中的某个位置抛出同一个异常很多次后,
JIT服务端编译器(C2)会将其优化成抛出一个事先编译好的、类型匹配的异常,异常堆栈信息就看不到了。二、Fast Throw
Fast Throw,字段上理解就是快速抛异常,目前需要满足以下条件才有如此的优化:
•只针对HotSpot VM才有, 例如oracleJDK, libericaJDK等
•特定位置抛出很多次,其实就是JIT将它优化了
•JIT必须使用C2才会这样优化,不抛出原来的异常,改用fast throw抛出
•这是一个事先分配好的异常,message和堆栈都是空的
可以看出,如果某个异常在同一位置被抛出多次,会被JIT C2优化成空异常,例如本文的NullPointerException,既没有message,也没有堆栈.但他的速度非常快,不用分配内存和获取堆栈.
如果想关闭这个优化,设置-XX:-OmitStackTraceInFastThrow即可。
存在即合理,既然存在fast throw的优化,必然有其价值。fast throw优化的原因是为了提高性能。当同一种异常在相同的位置被抛出多次,编译器就会重新编译此方法。重编译后,编译器可能会使用不提供跟踪的预分配异常来选择更快的策略。
本地测试了一下抛出NullPointerException,在开启与关闭fast throw的性能。
| 执行次数 | 开启Fast Throw | 关闭Fast Throw |
|---|---|---|
| 10w | 996ms | 3525ms |
| 100w | 5983ms | 28345ms |
| 500w | 35678ms | —— |
言而简之,不能因此出现了消失的异常堆栈就尝试关闭fast throw优化功能。
三、问题原因定位
对于线上环境中触发了Fast Throw机制,则可以通过向前追溯相同的日志来定位问题。
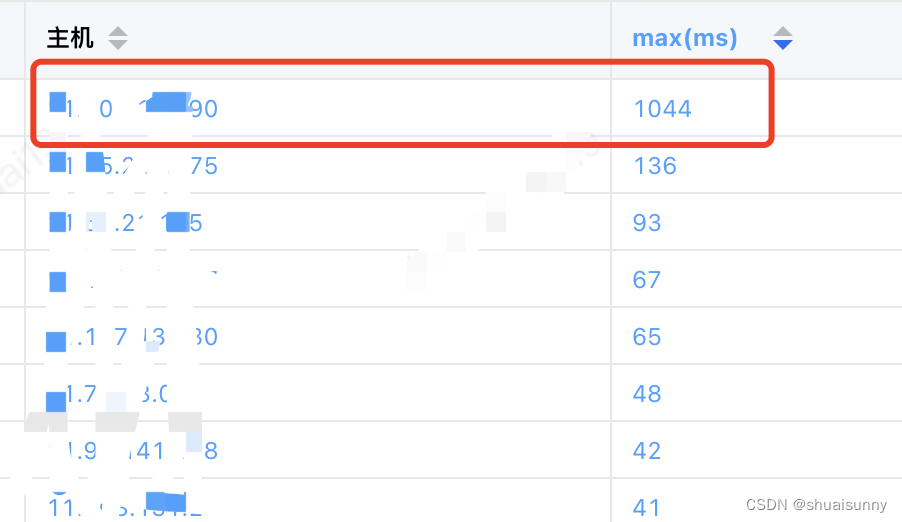
如在开门红中,有个接口的可用率调到98.3%(不是100%),如下图。
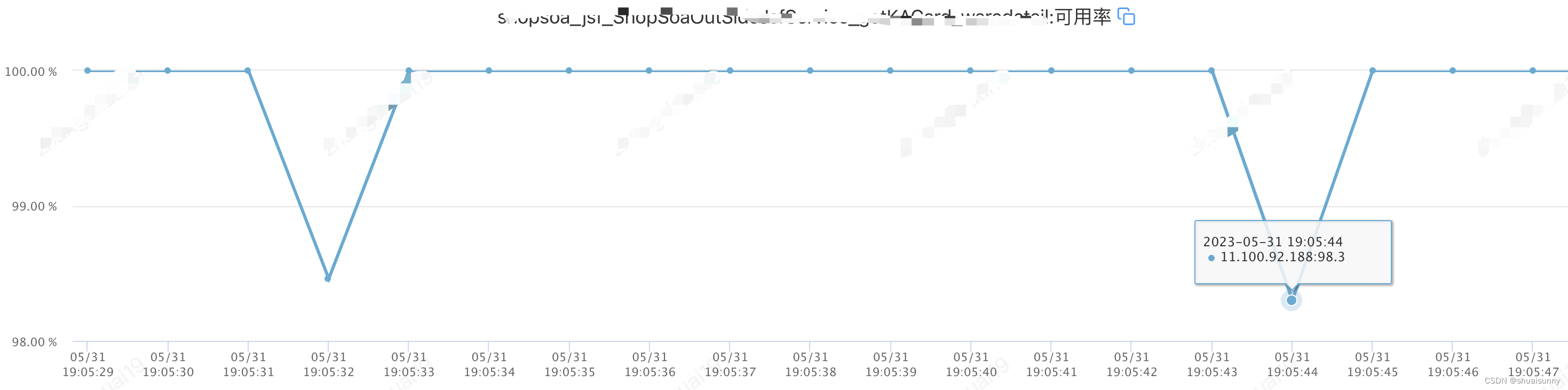
然后搜索日志发现大量的Caused by: java.lang.NullPointerException,没有详细的异常堆栈,很显然是由于fast throw导致的,然后不断向前追溯相同的日志来定位问题如下图。
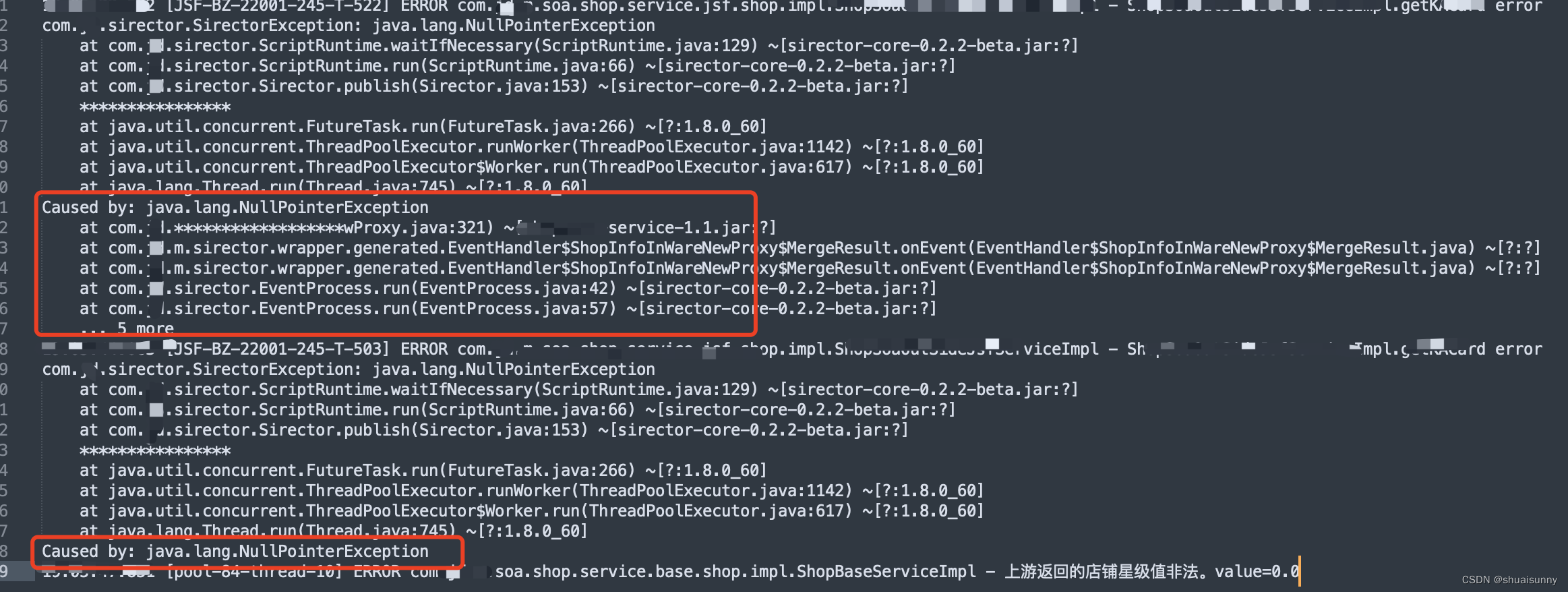
出现问题的原因找到了,接着就分析原因。原因很简单,由于某一台机器性能波动导致接口超时将兜底对象缓存,后续逻辑在处理的过种中对象中的Boolean属性值在转boolean时出现NPE,问题根源还是代码兼容性不足够好。
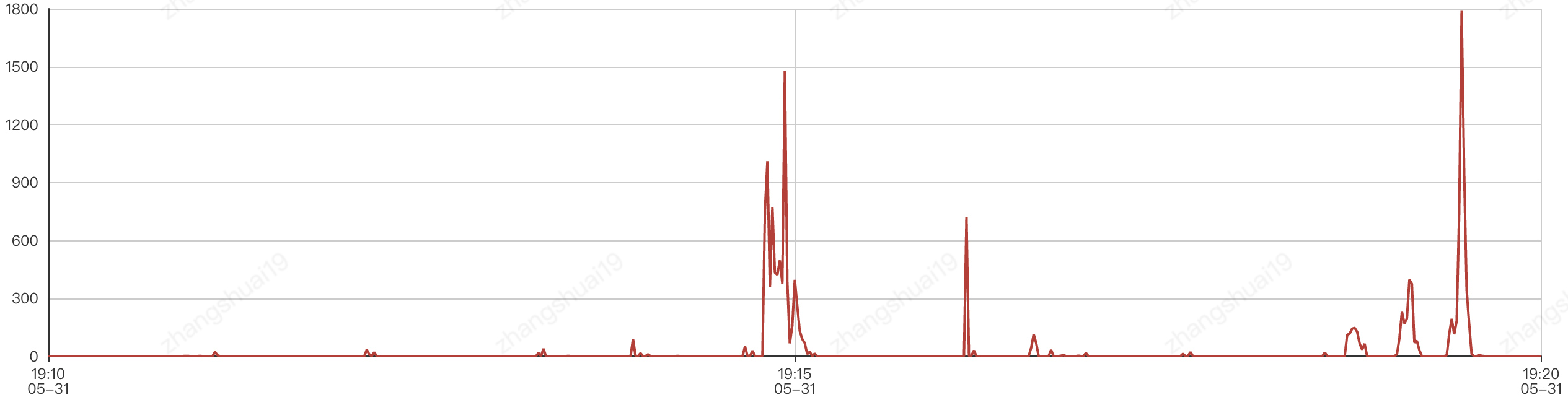
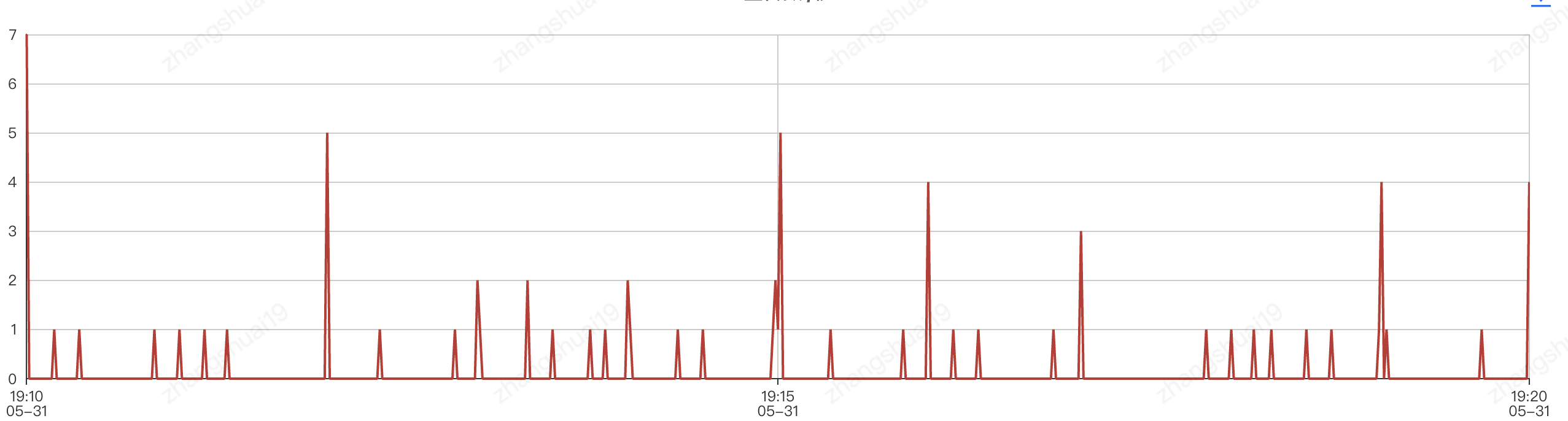
这这台机器进行系统视图层分析,发现TCP重传数较高,如下左图。
|
|
|
|---|
四、问题原因分析
TCP重传主要是为了保证数据传输的可靠性,TCP是一种保证可靠传输的机制,如重传与确认机制、数据校验、数据分片、流量控制、拥塞控制等。TCP重传的类型有超时重传和快速重传。超时重传是在请求包发送出去时开启计时器,当到达时间之后,没有收到ACK,则进行重传直到达到上限次数或者收到ACK。快速重传则依赖于数据包的期望序列号,并进行一致性检查。
•多台机器或者同一机房同时TCP重传
很大原因是网络抖动
•单机或者某个应用出现TCP重传
一般是由于链路的服务器或端口无法访问,对于虚拟机或者docker,还需要考虑宿主机的问题。
通过系统级分析,最后确定是由于宿主机连接性问题导致docker实例TCP重传增高,当然最重要的是补充相关的指标监控。
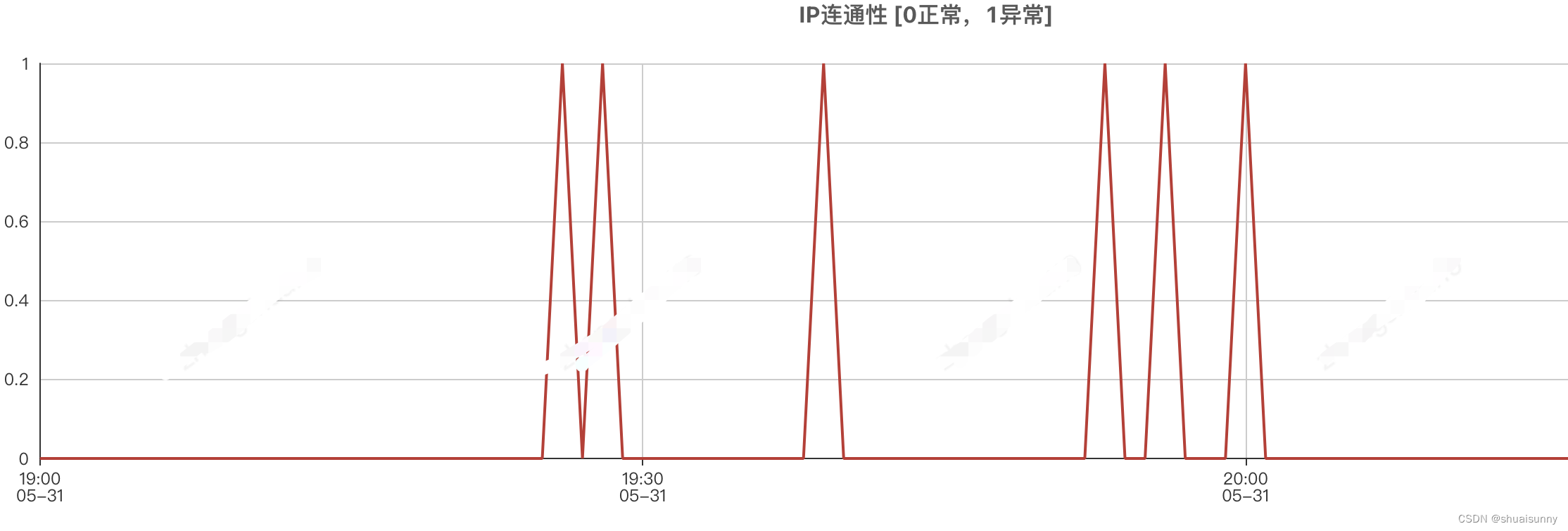
总之,在遇到问题时,要从根源上分析问题。