前言
第一篇文章,这是一篇大杂烩。都是网上的资料,自己做了整理。
1、关于DDR的概念
全称为Double Data Rate Synchronous Dynamic Random Access Memory,中文名为:双倍速率同步动态随机存储器,同步是指需要时钟。
目前DDR3和DDR4颗粒较多,集成在soc上的基本为SDRAM。HI3516EV300是集成DDR3。
RAM可以分为静态随机存储器、动态随机存储器和同步动态随机存储器。
1.1、寻址的基本原理
寻址的流程是先指定Bank地址,再指定行地址,然后指列地址最终的寻址单元。可以理解为看书,先看那一本(bank group),然后看那一页(bank),选择哪一行(ROW),最后那哪一个字(Column)。
2、硬件层
2.1、硬件特性
下图是DDR基本的原理框图,此篇文章将围绕DDR的框图讲解。
型号是MT41J256M8。

2.1.1、DDR引脚描述
-
引脚分类
DDR的引脚基本分为地址信号、数据信号、控制信号、时钟信号、电源和地。 -
DDR3的引脚描述

-
DDR4的引脚描述

-
DDR4的其他说明
新增引脚,上图黄色+红色部分
删除引脚,BANK2,VREFDQ (由内部产生)。
2.1.2、DDR3和DDR4的异同点
| 我 | DDR3 | DDR4 | 备注 |
|---|---|---|---|
| 读写速度 | 2133MHz | 3200MHz | - |
| 大小 | 1GB | 2GB | - |
| 电源 | 1.5V | 1.2V+2.5V | DDR4多一个VPP电源,内部efuse电压 字位线开启电压 |
| Bank | 8 | 8/16 | 哪一个DDR是16个bank?提供型号 |
| BankGroup | - | 4个 | - |
| VREFDQ | 外部提供 | 内部产生 | POD的参考电平Vref大小会随着驱动强度、负载、传输线特性等不同而改变 |
| Data IO | SSTL | POD | POD更省电,下面会讲 |
| DBI | - | 有 | DBI为数据总线倒置,结合POD使DDR4省电 |
| 预取为 | 8n | 8n | DDR4有BankGroup,每一个BankGroup可以独立操作。四个独立的Bank Group=32bit预取,提升吞吐量。 |
2.2、从DDR的原理框图解读
-
DATA IO
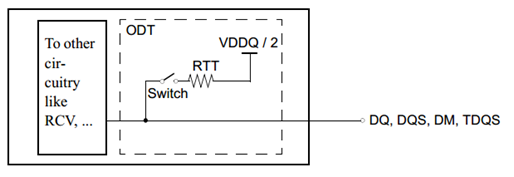
①SSTL,Series-Stud Terminated Logic(也称CCT )
SSTL电平本质是差分对,原理是将信号与参考电平VREF组成差分对进行比较。
下图VREF和VTT=VDDQ/2,接受端的电平取决于驱动器、端接电阻RT、端接电压VTT,驱动器的输出电阻Rs一般不会大于21R,作用是提高信号完整性。

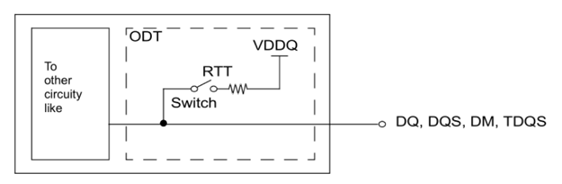
②POD,Pseudo open-drain 伪漏极开路
POD降低寄生引脚电容和IO终端功耗,并使VDD电压降低的情况下也能保证稳定。
内部短接上拉到VDDQ,当驱动端输出高电平时,由驱动端和接收端端接电压均为VDDQ,因此没有电流,降低功耗;驱动端输出低电平时,POD由于上拉电压高,功耗稍大于SSTL。
由于POD的参考电平Vref大小会随着驱动强度、负载、传输线特性等不同而改变,因此VrefDQ是由芯片内部产生的。POD的VREFDQ通过控制寄存器设置值由芯片自行优化调整,称为VREFDQ Training。
另外,LPDDR3的内部端接ODT也是上拉到VDDQ。
③LVSTL(LPDDR4) 低电压摆幅终端逻辑
LVSTL (Low Voltage Swing Terminated Logic), ODT是端接到VSSQ。比POD电平更省电。

它由两个NMOS构成了上下拉,信号的摆动电压幅度是可编程控制的,一般控制在VDDQ/2.5~VDDQ/3之间。
下图是与LPDDR3的接口电平的一个对比情况
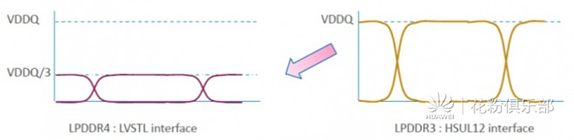
在idle状态下,不需要直流电平,所以也不会有电源的消耗。
小结:
SSTL(DDR3)上拉VDD/2,高低电平都会有功耗;
POD(DDR4 LPDDR3)上拉VDD,高电平没功耗,低电平功耗偏大。故有DBI功能;
LVSTL(LPDDR4)下拉VSSQ,休眠时无功耗。信号电平是可编程的。 -
VTT
VTT tracking termination voltage
为匹配电阻的上拉电源,VTT=VDD/2。DDR的数据线是一驱一的,且内部有ODT做匹配(地址线没有ODT阻抗匹配),不需要VTT做匹配信号质量也可以。如果地址和控制信号线是多负载的情况下,会一驱多,并且内部没有ODT,拓扑结构为T点结构,一般都需要使用VTT电源做信号质量的匹配控制。
如果使用VTT电源,则电流要求比较大,一般在500ma以上(仅计算控制地址总线),PCB走线需要铺铜皮。VTT电源是可以吸电流又可以灌电流。
为什么需要VTT电源呢?
DDR颗粒的接收端比较特殊,它是一个差分放大器,其中的一个PIN脚连接Vref是固定,另一个PIN接在DDR控制器的发送端,发送端发送过来的信号,只要比Vref高,高过一定的门限,接受端就认为1,只要比Vref低,低于一定的门限,接收端就认为0。DDR的速率(电平的切换)是很快的,同时一个控制器会下挂很多颗粒,这就导致总线上的电流(电荷)来不及泄放和补充,这就需要将VTT在VOUT为高的时候,吸收电流,在VOUT为低的时候补充电流。

PS:VTT电源可以参考TPS51200。

-
ODT
ODT(On-Die Termination)技术的目的是通过使DDR SDRAM控制器能够独立的打开或者关断DDR内部的终端电阻来提高存储器通道的信号完整性
ODT作为数据接收端时,打开ODT端接,使ODT电阻上拉至Vtt ( 等于供电电压的一半),数据发送端时,ODT功能关闭,断开ODT电阻。
一个DDR通道,通常会挂接多个Rank,这些Rank的数据线、地址线等等都是共用;数据信号也就依次传递到每个Rank,到达线路末端的时候,波形会有反射,从而影响到原始信号;因此需要加上终端电阻,吸收余波。
所以,使用ODT的目的很简单,是为了让DQS、RDQS、DQ和DM信号在终结电阻处消耗完,防止这些信号在电路上形成反射,进而增强信号完整性。
因为VTT的电压是VDD/2,信号线的电压比VTT高,所以信号可以从VTT泄放掉。

-
ZQ
见3.1.2ZQ校准。 -
DBI
DBI(Data Bus Inversion)数据总线倒置。发送端检测一个Byte(8 bit)输出为“1”的个数,如果小于4,就把所有的DQ输出翻转一下,也就是“0”变成“1”,“1”变成“0”。接收端根据DBI信号去决定是否再翻转一下。这样,一个Byte Data Bus上1的个数总是大于等于4。
每个Byte有一个DBI信号。DBI是双向的信号,读和写都可以利用DBI功能。
结合下DATA IO-POD,传输“1”比“0”省电,所以要翻转。 -
DM
数据掩码信号DQM,为输入输出双向信号,方向与数据流方向一致,高电平有效。当其有效时,数据总线上出现的对应数据字节被接收端屏蔽。16bit位宽芯片,则需要两个DM引脚。
为了屏蔽不需要的数据,人们采用了数据掩码(Data I/O Mask,简称DQM)技术。通过DM,内存可以控制I/O端口取消哪些输出或输入的数据。这里需要强调的是,在读取时,被屏蔽的数据仍然会从存储体传出,只是在“掩码逻辑单元”处被屏蔽。 -
VPP
DDR4的DRAM 的字位线 需要更高的电压来激活存取晶体管,确保上状态期间快速访问和该离开期间超低泄漏状态。2.5V VPP的可用性意味着不必从1.2V VDDQ电源中低效率地提供(提升)字线电压,从而提高了能量/电源效率。
字位线的电压,mos管的源极或者漏极电压。 -
BankGroup
-
DQS
数据选通信号,数据的同步信号。对于x16, DQSL:对应于DQ0-DQ7上的数据;DQSU对应于DQ8-DQ15上的数据。
DQS 是DDR中的重要功能,主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。
在读取时,DQS与数据信号同时生成(也是在CK与CK#的交叉点)。

在写入时,以DQS的高/低电平期中部为数据周期分割点,而不是上/下沿,但数据的接收触发仍为DQS的上/下沿。 -
TDQS
终端数据选通Termination Data Strobe TDQS仅支持x8设备。X4,X8DDR混用时,DQS的负载会不同,TDQS就是为了解决这个问题(详见文档TDQS)。 -
突发传输长度
目前内存的读写基本都是连续的,因为与CPU交换的数据量以一个Cache Line(即CPU内Cache的存储单位)的容量为准,一般为64字节。而现有的Rank位宽为8字节(64bit),那么就要一次连续传输8次,这就涉及到我们也经常能遇到的突发传输的概念。突发(Burst)是指在同一行中相邻的存储单元连续进行数据传输的方式,连续传输的周期数就是突发长度(Burst Lengths,简称BL)。
在进行突发传输时,只要指定起始列地址与突发长度,内存就会依次地自动对后面相应数量的存储单元进行读/写操作而不再需要控制器连续地提供列地址。这样,除了第一笔数据的传输需要若干个周期(主要是之前的延迟,一般的是tRCD+CL)外,其后每个数据只需一个周期的即可获得。

突发连续读取模式:只要指定起始列地址与突发长度,后续的寻址与数据的读取自动进行,而只要控制好两段突发读取命令的间隔周期(与BL相同)即可做到连续的突发传输。 -
8位预取
8bit预取技术即是在I/O控制器发出请求信号之前,存储单元已经事先准备好了8bit的数据。为了实现这一原理,采用了并行转串行数据线的设计,即将多个存储单元构成矩阵,将数据经由统一双极型晶体管DQ总线发射。下图有助于说明。

工作原理就是8数据线并联,8个电容构成矩阵,同时传输8bit数据到I/O控制器上,然后由I/O控制器统一发射。相当于把8个二进制数打包成一个数据包。
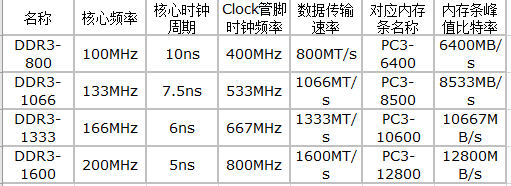
DDR3一次从存储单元预取8-bit的数据,在I/O端口处上下沿触发传输,8-bit需要4个时钟周期完成,所以DDR3的I/O时钟频率是存储单元核心频率的4倍,由于是上下沿都在传输数据,所以实际有效的数据传输频率达到了核心频率的8倍。比如,核心频率为200MHz的DDR3-1600,其I/O时钟频率为800MHz,有效数据传输频率为1600MHz。
2.3、频率
核心频率=等效频率/DDR的预取数。
等效频率(数据的传输频率)=核心频率X8(DDR3预取是8Bit)=工作频率X4(在时钟上升和下降沿各传输一次)
DDR3内存一次从存储单元预取8Bit的数据,在I/O-Buffer(输入/输出缓存)上升和下降中同时传输,因此有效的数据传输频率达到了存储单元核心频率的8倍。同时DDR3内存的时钟频率提高到了存储单元核心的4倍。
- 核心频率
核心频率即为内存Cell阵列(Memory Cell Array)的工作频率,它是内存的真实运行频率(时钟频率)
- 工作频率
工作频率即I/O Buffer(输入/输出缓存)的传输频率;DDR在时钟的上升沿和下降沿各传输一次数据。工作频率=等效频率/2。
- 传输速率
传输速率的频率叫做传输频率或者等效频率
有效数据传输频率则是指数据传送的频率。(等效频率)
2.4、级联
2片DDR是怎么连接的?为什么数据位分开接,地址位一起接?(两个16bit是如何组成一个32bit的。)
两个16bit组成一个32bit,指的是数据,与地址没有关系。(将16bit/32bit指的是数据宽度)。
两块DDR3的BA0-BA2和D0-D14是并行连接到CPU。不过访问的是一块32bit的DDR3。
它们是如何响应的呢?
数据线的连接:第一片的D0-D15连接到了CPU的D0-D15,第二片的D0-D15连接到了CPU的D16-D31。CPU认为自己访问的是一块32bit的内存,所以CPU每给出一个地址,将访问4个字节的数据,读取/写入。
CPU访问的内存地址有256M个,每访问一个地址,将访问4个字节,这样CPU能访问的内存即为1G。(内存计算下一节说明)
2.5、内存计算

先计算地址的容量,然后乘以数据位,最后除以8换算成字节单位。
Bank Address=BA0-BA2,表示DDR3内部有8个bank.
Row Address 表示行的有A0-A14,共15个bit,说明一个bank中有2^15个行。
Column Address表示列的有A0-A9,共10个bit,说明一个bank中有2^10个行。
单块DDR3的地址容量 :2^28=256M
访问一个地址,内存认为是访问16bit的数据,也就是两个字节的数据。
256M个地址,对应512M大小的内存。
2.6、PCB
2.6.1 走线和滤波电容布局
- DDR布线
①阻抗
单端50R,差分(时钟 DQS)100R-----在走线过程中,减小阻抗跳变的因素,如:换层、参考平面完整不跨分割、线宽变化、避免stub。
②分组
数据线每10根线为一组(D0-D7 LDQS LDM,D8-D15,HDQS HDM)-----走线必须同组,组内不能有其他信号线,且保证同层/换层次数一致。长度误差控制在±10mil;地址线、命令线、时钟为一组,长度误差控制在±25mil。
③信号线满足3W原则
数据线、地址控制线、时钟线之间的距离保持20mil以上或者3W原则
④VREF电源走线推荐≥20-30mil
误差范围—差分线号误差范围±5mil数据线误差范围±50mil,地址线误差范围±25mil
- 滤波电容的布局要求
电源设计是PCB设计的核心部分,滤波电容的布局是电源的重要部分,遵循以下原则:
CPU端和DDR3颗粒端,每个引脚对应一个滤波电容,滤波电容尽可能靠近引脚放置。线短而粗,回路尽量短;CPU和颗粒周边均匀摆放一些储能电容,DDR3颗粒每片至少有一个储能电容。
- VREF电路布局
在DDR3中,VREF分成两部分:命令与地址的参考电压VREFCA和数据总线的参考电压VREFDQ。 在布局时,VREFCA、VREFDQ的滤波电容及分压电阻要分别靠近芯片的电源引脚。
- 匹配电阻的布局
为了提高信号质量,地址、控制信号一般要求在源端或终端增加匹配电阻;数据信号可以通过调节ODT 来实现,一般不加电阻。布局时要注意电阻的摆放,到电阻端的走线长度对信号质量有影响。布局原则如下:
对于源端匹配电阻靠近CPU(驱动)放,而对于并联端接则靠近负载端。
而对于终端VTT上拉电阻要放置在相应网络的末端,即靠近最后一个DDR3颗粒的位置放置(T拓扑结构是靠近最大T点放置);注意VTT上拉电阻到DDR3颗粒的走线越短越好;走线长度小于500mil;每个VTT上拉电阻对应放置一个VTT的滤波电容(最多两个电阻共用一个电容);VTT电源一般直接在元件面同层铺铜来完成连接,所以放置滤波电容时需要兼顾两方面,一方面要保证有一定的电源通道,另一方面滤波电容不能离上拉电阻太远,以免影响滤波效果。
2.6.2 T型拓扑和FLY-BY型拓扑
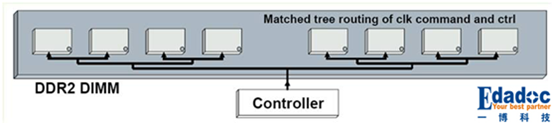
- T型拓扑(主控芯片不支持读写平衡功能,则必须用T型)
它适用于多负载,单向驱动的总线结构 如地址、控制等。当布线不对称时,信号质量影响很大, T型拓扑结构的特点是主控到每个颗粒的长度基本一致,也就是说每个颗粒的信号质量都差不多;缺点就是绕等长时需要更多的布线空间,所以不适合较多颗粒数目的情况,其次是需要同等地位的分支完全对称(包括长度及阻抗等)。所以我们在使用T型拓扑的时候应该注意预留足够的空 间来绕线,另外还需要注意同一个节点分出去的分支(也就是前面说的同等地位的分支)必须对称。
- Fly_by型拓扑(菊花链拓扑结构)
Fly_by 拓扑结构的优点是布线相对简单,其中数据组不需要和时钟信号绕等长,这样就可以节省较多的布线空间,同时也可以支持更高的信号速率;缺点就是信号到达每片颗粒的时间不一致,带来了一定的skew(偏差),这个skew需要一定的技术来弥补。对Fly_by拓扑影响最大的是主干到颗粒 的那段Stub线,所以必须严格控制stub的长度(时钟信号100mil左右,地址、控制等信号150mil左右),这个长度当然是越短越好。至于颗粒间的长度到底影响有多大。
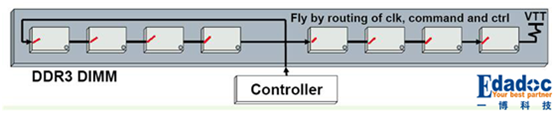
Fly_by拓扑是针对DDR3的时钟、地址、控制和命令信号而言,数据信号就不存在fly-by拓扑的说法。
Qestions:
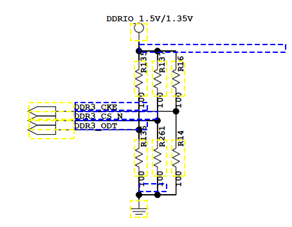
FLY-BY型比T型多了参考电压。
小结:T型和FLY-BY型 原理一样,Uboot不同是因为时序不同。(数据到达每一个DDR的时间不同)。
FLY-BY为了走线,可以改变数据位。
3 DDR的初始化
3.1 DDR初始化流程

DRAM完整的初始化过程(initialzation)包括一下4个单独步骤:
①上电与初始化,Power-on and initialzation;
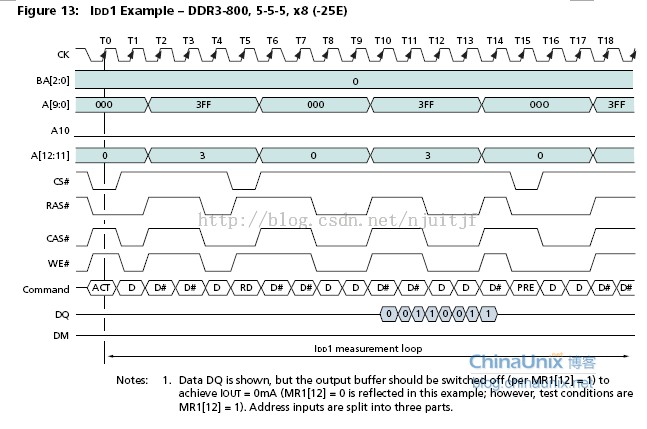
②ZQ校准,ZQ calibration
③VREFDQ校准,VREFDQ calibration
④读写训练,即存储介质训练/初始校准,read/write traning

3.1.1 初始化 initialzation
在系统上电之后,DDR的控制器会被从复位状态中释放,自动执行上电和初始化序列。包括以下步骤(简化):
①给DRAM颗粒上电
②置低DRAM的复位端口RESET,并使能DRAM的时钟使能CKE
③向DRAM发出MRS(mode register set 模式寄存器设置)命令,并按照特定的序列读取/配置DRAM的mode register
④进行ZQ校准(ZQCL)
⑤使DRAM进IDLE(空闲)状态,为读写做准备。
以上系列的操作结束后,DRAM颗粒了解自己的工作频率,时序参数,CAS Latency CAS witer Latency。
3.1.2 ZQ 校准ZQ calibration

在DRAM内部视角中观察,每一个DQ管脚之后都有多个并联的240欧姆电阻组成。(用于提高信号完整性)由于颗粒制造时, CMOS 工艺本身的限制,这些电阻不可能是精确的 240 欧姆。此外,阻值还会随着温度和电压的改变而改变。所以必须校准至接近 240 欧姆,用于提高信号完整性。
为了给电阻进行阻值校准,每个DRAM颗粒具有:
①专用的DQ校准模块
②一个ZQ管脚连接至外部电阻,240欧姆精密电阻。
外挂电阻精密且不会随温度变化而变化,被用于参考阻值。初始化过程中,ZQCL命令发出后,DQ校准模块对每一个DQ管脚连接的电阻进行校准。
①DQ管脚连接的电阻用于提高信号完整性
②需要精确的阻值
③由于制造工艺和温度的变化,这个阻值不精确
④引入ZQ管脚连接的外部电阻和DQ校准模块,在初始化阶段对DQ电阻值进行校准
⑤提高信号完整性,以支持更好的数据速率
DQ 电路中的 240 欧姆电阻是 Poly Silicon Resistor 类型的,通常来说,它们的阻值会略大于 240 欧姆。
下图放大了电阻模块的内部结构,5个PMOS管个DQ电阻并联,通过Voh来控制罐子的开关,以控制电阻的阻值。

连接至 DQ 校准控制模块的电路包括一个由两个电阻组成的分压电路,其中一个是上面提到的可调阻值的 poly 电阻,而另一个则是精准的 240 欧姆电阻。当 ZQCL 命令发出后,DQ 校准控制模块使能,并通过其内部逻辑控制 VOH[0:4] 信号调整 poly 电阻阻值,直到分压电路的电压达到 VDDQ/2,即两者均为 240 欧姆。此时 ZQ 校准结束,并保存此时的 VOH 值,复制到每个 DQ 管脚的电路。

DRAM为什么在初始化才调整240欧姆阻值呢?
因为并联的电阻网络允许用户在不同的使用条件下对电阻进行调整,为读操作做调整驱动强度,为写操作做调整短接电阻值。不同PCB具有不同的阻抗,可调整的电阻网络可针对每一个PCB单独调整阻值,一提高信号完整性,最大化眼图,允许在更高频率下工作。
3.1.3 DQ判决电平校准 VREFDQ calibraton
DDR4 数据线的端接方式 POD(Pseudo Open Drain)。这是为了提高高速下的信号完整性,并节约 IO 功耗。这不是 POD 的首次应用,GDDR5 同样使用 POD。
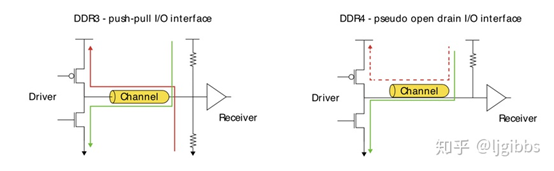
DDR3的接受实际上是一个分压电路。VDD/2作为判决电平。DDR4的判决电平VREFDQ是内部的,控制器需要尝试不同的VREFDQ值,来设置一个能够正确区分高低电平的值。
3.1.4 读写训练 read/write training
完成上诉步骤后,DRAM初始化已经完成,并处于IDLE状态。此时存储介质仍未处于正确的工作状态。在正确读写DRAM之前,还需要进行读写训练。称存储介质训练/初始校准。
①对齐DRAM的时钟信号CK和数据有效信号DQS的边沿
② 确定DRAM颗粒的读写延迟
④报告错误,若信号完整性太差,没办法保证可靠的读写操作
读写训练的目的是什么?
地址/命令信号和数据之间是有相对延迟的,读写训练的目是消除这两个不同数据读写的影响。(设置各种延时)
数据DQ和数据有效DQS信号连接到每个DRAM颗粒,控制器和DRAM数据和数据有效信号是一一对应的,采用星型拓扑。(数据和数据有效不存在Flyby拓扑)
时钟,命令和地址信号连接至DRAM颗粒时,采用Flyby拓扑结构。如上图所示,8个DRAM颗粒工享同一个CA信号,采用Flyby结构能够提高信号完整性和信号速度。
4 时序
4.1 DDR3的时序
在内存的工作周期内,不可能总处于数据传输的状态,因为要有命令、寻址等必要的过程。但这些操作占用的时间越短,内存工作的效率越高,性能也就越好。
非数据传输时间的主要组成部分就是各种延迟与潜伏期。有三个参数对内存的性能影响至关重要,它们是tRCD、CL和tRP。每条正规的内存模组都会在标识上注明这三个参数值,可见它们对性能的敏感性。
tRCD决定了行寻址(有效)至列寻址(读/写命令)之间的间隔,CL决定了列寻址到数据进行真正被读取所花费的时间,tRP则决定了相同L-Bank中不同工作行转换的速度。
4.1.1 tRCD
内存寻址的第一个命令是发送Bank序号和行地址,行激活(Row Active)后,第二个命令是发送列地址和具体读或写操作指令。从行有效到读/写命令发出之间的间隔被定义为tRCD,即RAS to CAS Delay(RAS至CAS延迟,RAS就是行地址选通脉冲,CAS就是列地址选通脉冲)。这是内存寻址中第一个可能发生的延迟。
广义的tRCD以时钟周期(tCK,Clock Time)数为单位,比如tRCD=3,就代表延迟周期为三个时钟周期,具体到确切的时间,则要根据时钟频率而定,DDR3-800,tRCD=3,代表30ns的延迟。图中显示的是tRCD=3

4.1.2 tCL
从列地址激活到数据读出这段时间就是tCL。
接下来,相关的列地址被选中之后,将会触发数据传输,但从存储单元中输出到真正出现在内存芯片的 I/O 接口之间还需要一定的时间(数据触发本身就有延迟,而且还需要进行信号放大。如果指令为读取,还需要激活该逻辑bank中的感应放大器,然后在Cell中读出数据,如果指令为写入,相对简单一些,对于DDR SDRAM写入延迟通常为1个时钟周期左右。)这段时间就是非常著名的 CL(CAS Latency,列地址选通脉冲 潜伏期)。
CL 的数值与 tRCD 一样,以时钟周期数表示。不过CL只是针对读取操作。
4.1.3 tAC
由于芯片体积的原因,存储单元中的电容容量很小,所以信号要经过放大来保证其有效的识别性,这个放大/驱动工作由S-AMP负责,一个存储体对应一个S- AMP通道。但它要有一个准备时间才能保证信号的发送强度(事前还要进行电压比较以进行逻辑电平的判断),因此从数据I/O总线上有数据输出之前的一个时钟上升沿开始,数据即已传向S-AMP,也就是说此时数据已经被触发,经过一定的驱动时间最终传向数据I/O总线进行输出,这段时间我们称之为 tAC(Access Time from CLK,时钟触发后的访问时间)。图中标准CL=2,tAC=1

4.1.4 tRP
从开始关闭现有的工作行,到可以打开新的工作行之间的间隔就是tRP(Row Precharge command Period,行预充电有效周期),单位也是时钟周期数。
实际上,预充电是一种对工作行 中所有存储体进行数据重写,并对行地址进行复位,同时释放S-AMP(重新加入比较电压,一般是电容电压的1/2,以帮助判断读取数据的逻辑电平,因为S-AMP是通过一个参考电压与存储体位线电压的比较来判断逻辑值的),以准备新行的工作。
在数据读取完之后,为了腾出读出放大器以供同一Bank内其他行的寻址并传输数据,内存芯片将进行预充电的操作来关闭当前工作行。还是以上面那个Bank示意图为例。当前寻址的存储单元是B1、R2、C6。如果接下来的寻址命令是B1、R2、C4,则不用预充电,因为读出放大器正在为这一行服务。如果碰巧仍在这一行的不同列,则不用经历tRCD。但如果地址命令是B1、R4、C4,由于是同一Bank的不同行,那么就必须要先把R2关闭,才能对R4寻址。
4.1.5 参考DDR3规格书
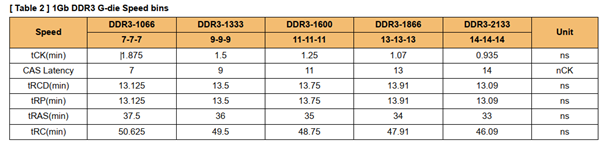
上图,CL以时钟周期数显示,其余以时间显示
CAS Latency (列地址脉冲选通潜伏期)列地址(写命令)触发后,到数据真正出现在I/O的时间(数据传输本来就有延时,而且信号还需要放大)。单位以时钟周期为单位。
tRCD(RAS to CAS delay RAS至CAS延迟,RAS就是行地址选通脉冲,CAS就是列地址选通脉冲)行有效(BANK寻址)到写命令发出(列地址选通)的之间的间隔;以时钟周期数为单位。
tRP (Row Precharge command Period),行预充电有效周期,从现有行到可以打开新的工作行之间的时间间隔。
注:这三个时间间隔并不是越小越好,需要具体搭配。
4.2 三种寻址情况
4.2.1 tRCD+CL
要寻址的行与Bank是空闲的。也就是说该Bank的所有行是关闭的,此时可直接发送行有效命令,数据读取前的总耗时为tRCD+CL,这种情况我们称之为页命中(PH,Page Hit)。
4.2.2 CL
要寻址的行正好是前一个操作的工作行,也就是说要寻址的行已经处于选通有效状态,此时可直接发送列寻址命令,数据读取前的总耗时仅为CL,这就是所谓的背靠背(Back to Back)寻址,我们称之为页快速命中(PFH,Page Fast Hit)或页直接命中(PDH,Page Direct Hit)。
4.2.3 tRP+tRCD+CL
要寻址的行所在的L-Bank中已经有一个行处于活动状态(未关闭),这种现象就被称作寻址冲突,此时就必须要进行预充电来关闭工作行,再对新行发送行有效命令。结果,总耗时就是tRP+tRCD+CL,这种情况我们称之为页错失(PM,Page Miss)。