自2016年至今,模型大小每18个月增长40倍,自2019年到现在,更是每18个月增长340倍。
然而相比之下,硬件增长速度较慢,自2016年至今,GPU的性能增长每18个月1.7倍,模型大小和硬件增长的差距逐渐扩大。显存占用大、算力消费大、成本高昂等瓶颈严重阻碍AIGC行业的快速发展。在此背景下,潞晨科技创始人尤洋认为,分布式训练势在必行。
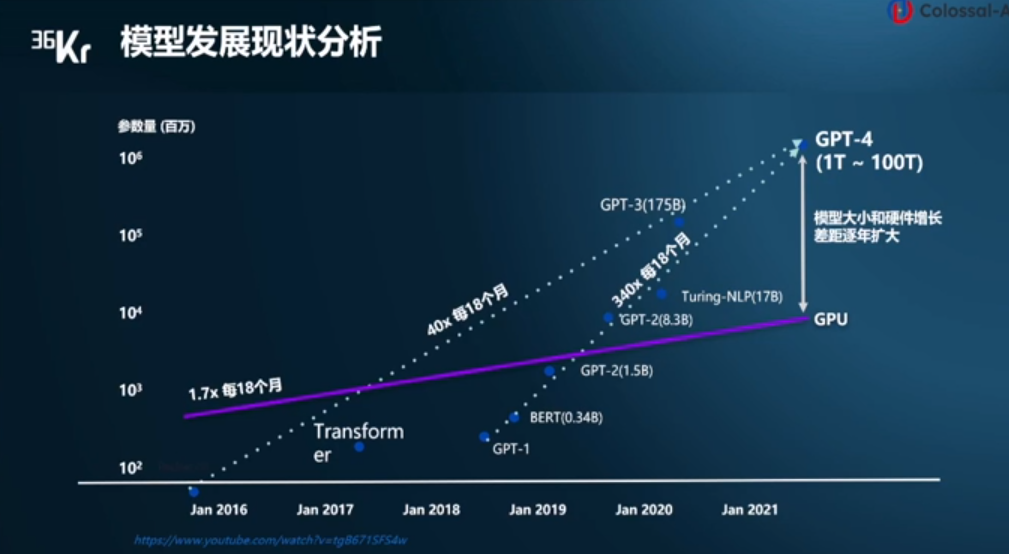
图:潞晨科技创始人尤洋演讲
基础大模型结构为模型训练提供了基础架构
其一、Google首创的Transformer大模型,是现在所有大模型最基础的架构。现在Transformer已经成为除了MLP、CNN、RNN以外第四种最重要的深度学习算法架构。
其二、Google发布的首个预大模型BERT,从而引爆了预练大横型的潮流和的势,BERT强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言横型进行浅层拼接的方法进行预认训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。
其三、ViT Google提出的首个使用Transformert的视觉大模型,ViT作为视觉转换器的使用,而不是CNN威混合方法来执行图像任务,作者假设进一步的预认训练可以提高性能,因为与其他现有技术模型相比,ViT具有相对可扩展性。
其四、Google将Transformer中的Feedforward Network(FFN)层替换成了MoE层,并且将MoE层和数据并行巧妙地结合起来,在数据并行训练时,模型在训练集群中已经被复制了若干份,通过在多路数据并行中引入Al-to-Al通信来实现MoE的功能。
在这些基础大模型结构之上,过去这些年,在大模型的发展历程中,出现了几个具有里程碑意义性的大模型包括GPT-3、T5、Swin Transformer、Switch Transformer。
GPT-3:OpenAI发布的首个百亿规模的大模型,应该非常具有开创性意义,现在的大模型都是对标GPT-3,GPT-3依旧延续自己的单向语言模型认训练方式,只不过这次把模型尺寸增大到了1750亿,并且使用45TB数据进行训练。
T5(Text-To-Text Transfer Transformer):Google T5将所有NLP任务都转化成Text-to-Text(文本到文本)任务。它最重要作用给整个NLP预训型领城提供了一个通用框架,把所有任务都转化成一种形式。
Swin Transformer:微软亚研提出的Swin Transformer的新型视觉Transformer,它可以用作计算机视的通用backbone。在个领域之同的差异,例如视觉实体尺度的巨大差异以及与文字中的单词相比,图像中像素的高分率,带来了使Transformer从语言适应视觉方面的挑战。
超过万亿规模的稀疏大模型Switch Transformer:能够训练包含超过一万亿个参数的语言模型的技术,直接将参数量从GPT-3的1750亿拉高到1.6万亿,其速度是Google以前开发的语言模型T5-XXL的4倍。
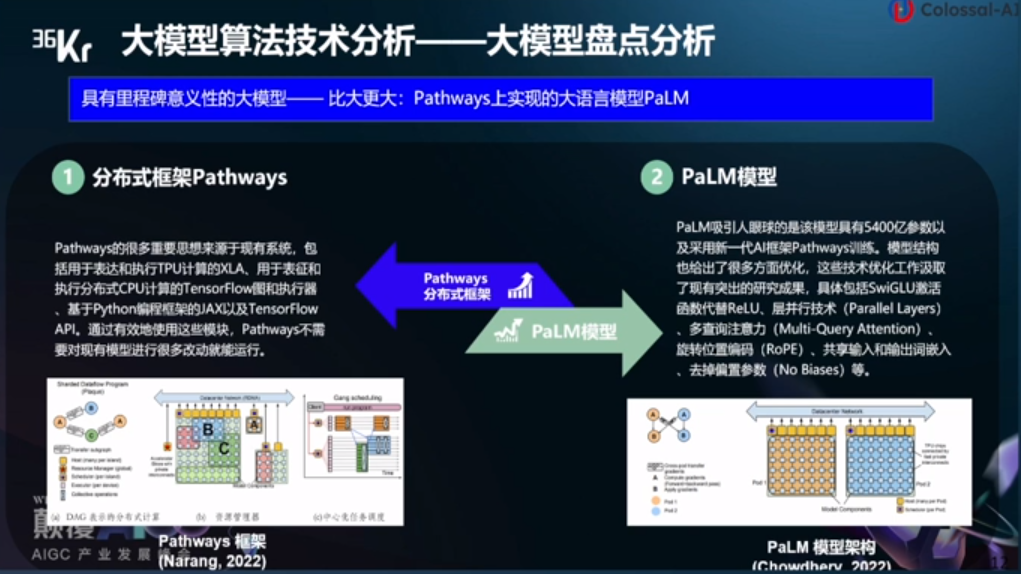
另外,更具里程碑意义的大模型,在Pathways上实现的大预言模型PaLM。
分布式框架Pathways:Pathways的很多重要思想来源于现有系统,包括用于表达和执行TPU计算的XLA、用于表征和执行分布式CPU计算的TensorFlow图和执行器、基于Python编程框架的JAX以及TensorFlow APL,通过有效地使用这些模块,Pathways不需要对现有横型进行很多改动就能运行。
PaLM模型:PaLM吸引人眼球的是该模型具有5400亿参数以及果用新一代AI框架Pathways训练。模型结构也给出了很多方面优化,这些技术优化工作汲取了现有突出的研究成果,具体包括SwiGLU激活函数代替ReLU、层并行技术(Parallel Layers)、多查询注意力(Multi-Query Attention),旋转位置编码(RoPE)、共享输入和输出词嵌入、去掉偏置参数(No Biases)等。
PaLM模型也是通过堆叠Transformer中的Decoder部分而成,该模型具有5400亿参数以及采用新一代AI框架Pathways训练。
大规模分布式训练当前主要技术路线
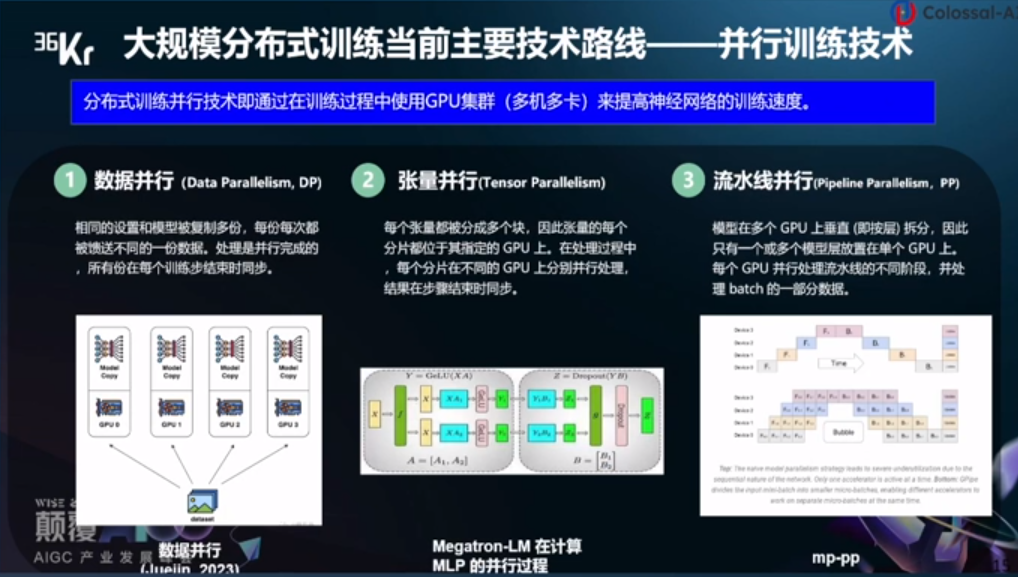
大规模分布式训练当前主要技术路线——并行训练技术。分布式训练并行技术即通过在训练过程中使用GPU集群(多机多卡)来提高神经网络的训练速度。
数据并行:相同的设置和模型被复制多份,每份每次都被馈送不同的一份数据,处理是并行完成的,所有份在每个训练步结束时同步。
张量并行:每个张量都被分成多个块,因此张量的每个分片都位于其指定的GPU上,在处理过程中,每个分片在不同的GPU上分别并行处理,结果在步骤结束时同步。
流水线并行:模型在多个GPU上垂直(即按量)拆分,因此只有一个或多个模型层放置在单个GPU上,每个GPU并行处理流水线的不同阶段,并处理batch的一部分数据。
潞晨科技成立于2021年,是一家致力于“解放AI生产力”的全球性公司。主要业务是通过打造分布式AI开发和部署平台,帮助企业降低大模型的落地成本,提升训练、推理效率。
潞晨开源的智能系统架构Colossal-AI技术,有两大特性:一是最小化部署成本,Colossal-AI 可以显著提高大规模AI模型训练和部署的效率。仅需在笔记本电脑上写一个简单的源代码,Colossal-AI 便可自动部署到云端和超级计算机上。
通常训练大模型 (如GPT-3) 需要 100 多个GPU,而使用Colossal-AI仅需一半的计算资源。即使在低端硬件条件下,Colossal-AI也可以训练2-3倍的大模型。
二是最大化计算效率,在并行计算技术支持下,Colossal-AI在硬件上训练AI模型,性能显著提高。潞晨开源的目标是提升训练AI大模型速度10倍以上。