在学《cuda by example》的时候,对这段代码有点疑惑,没搞清为啥要tid+=blockDim.x*gridDim.x,还有后面那些坐标也有些疑惑,在手推和举例子之后终于明白了,记录下来。
__global__ void dot(float * a, float * b, float * c) {__shared__ float cache[threadsPerBlock];int tid = threadIdx.x + blockIdx.x * blockDim.x;int cacheIndex = threadIdx.x;float temp = 0;while (tid < N) {temp += a[tid] * b[tid];tid += blockDim.x * gridDim.x;}// set the cache valuescache[cacheIndex] = temp;// synchronize threads in this block__syncthreads();// for reductions, threadsPerBlock must be a power of 2 // because of the following codeint i = blockDim.x / 2;while (i != 0) {if (cacheIndex < i) cache[cacheIndex] += cache[cacheIndex + i];__syncthreads();i /= 2;}if (cacheIndex == 0) c[blockIdx.x] = cache[0];
}
假如这是初始情况
girdDim.x=4
blockDim.x=16
每个grid中包含gridDim.x\*blockDim.x=64个线程
待求和的数组的大小N=3*64=192
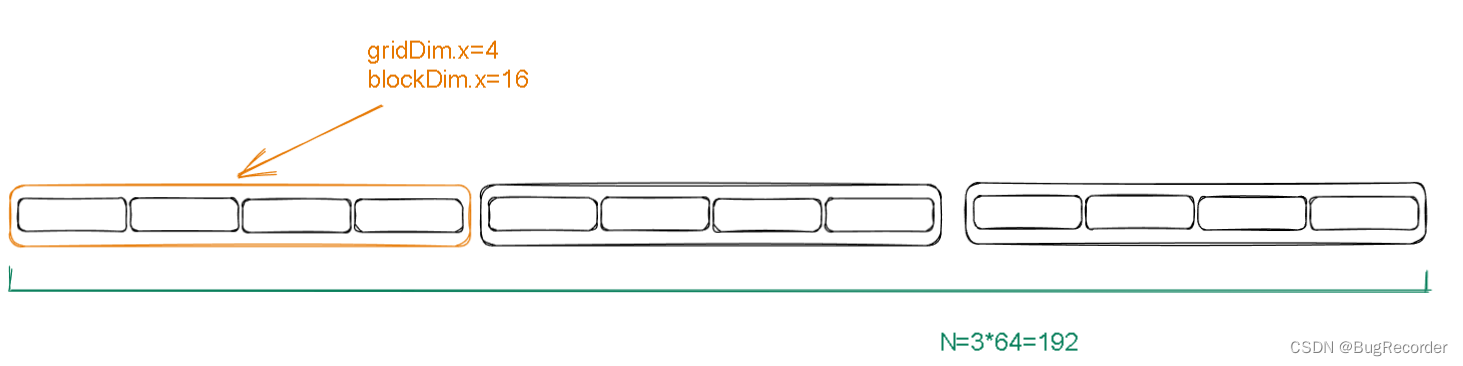
每次进入核函数之后,开启一个shared memory,cacheSize=每个block的size=16
这次进入核函数开启了一个线程,它的threadIdx.x=3, blockIdx.x=1
则它的tid=threadIdx.x + blockIdx.x * blockDim.x=3+1*16=19
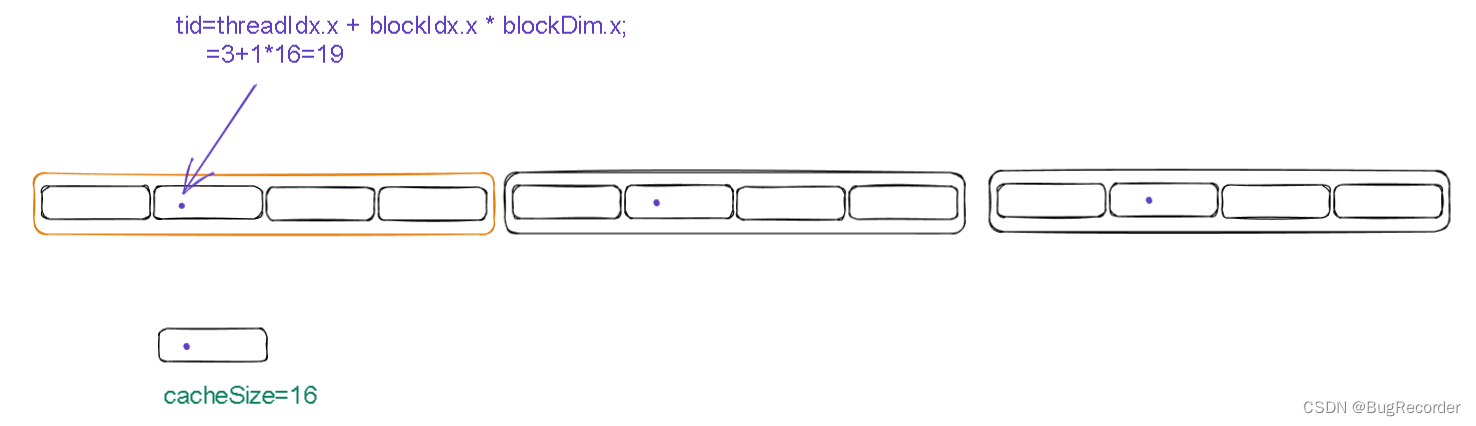
进行完这个while循环之后,数组中下标%64=tid =19 的元素都加到了cache[3]中
即cache[3]=c[19]+c[83]+c[147]
while (tid < N) {temp += a[tid] * b[tid];tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
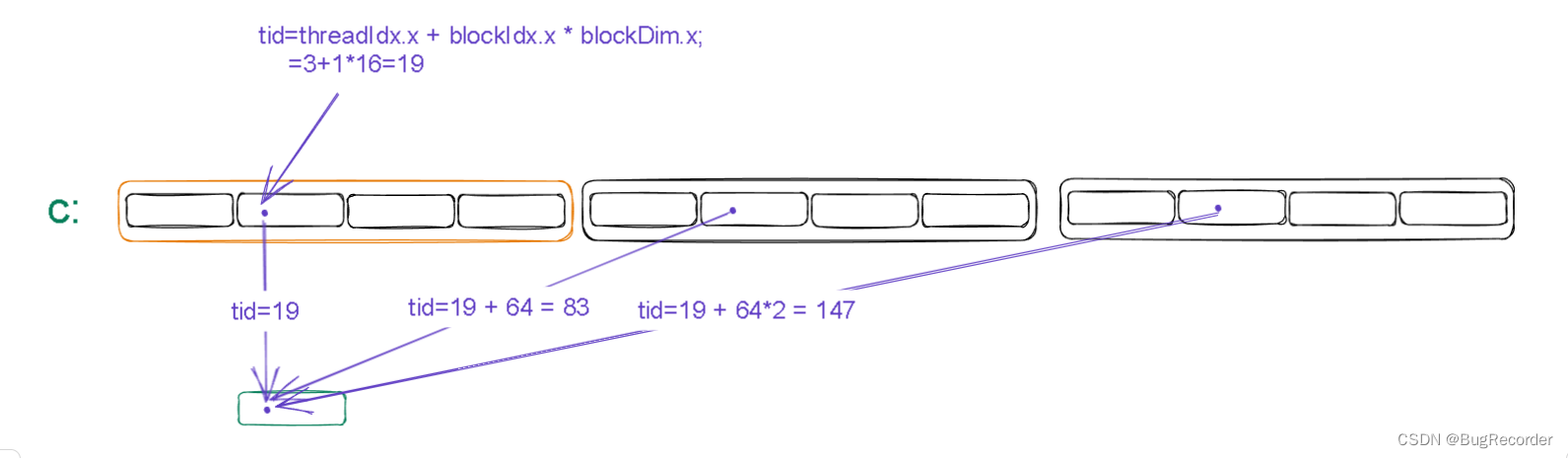
同步之后:
__syncthreads();
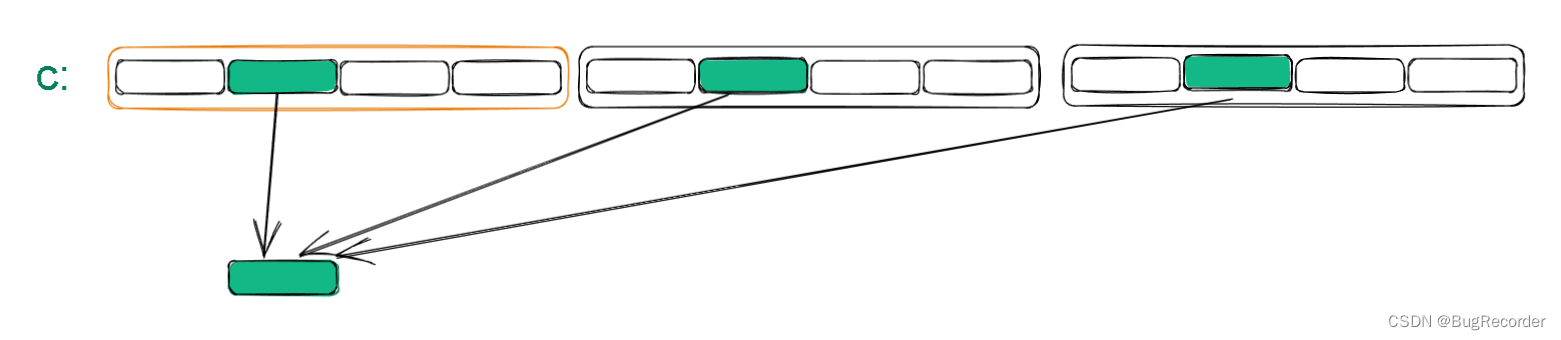
规约之后:
int i = blockDim.x / 2;
while (i != 0) {if (cacheIndex < i) cache[cacheIndex] += cache[cacheIndex + i];__syncthreads();i /= 2;
}
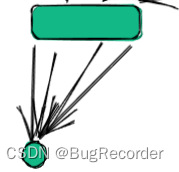
绿色圆圈即cache[0]
然后写入c[blockIdx.x]即c[1]中
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
再见到比较麻烦的公式之类的,耐下心来举个简单的例子,画个图,手推一下,会加深理解。