- 前言: …
-
目录
- 1 分类
- 2 回归
- 3 总结
- 4 代码
k近邻算法(KNN)是监督学习算法,意味着训练数据集需要有label或者类别,KNN的目标是把没有标签的数据点(样本)自动打上标签或者预测所属类别。同时KNN也可用于回归。
KNN的主要实现过程:
计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等)对上面所有的距离值进行排序选前k个最小距离的样本根据这k个样本的标签进行投票,得到最后的分类类别
1 分类
在知乎上有一篇很好的解释knn分类的文章。请访问https://zhuanlan.zhihu.com/p/25994179

根据上图,绿色的点是新的样本,就先 for 循环所有训练样本找出离绿色点最近的 K 个邻。
如果knn的k=3,就看距离绿色的点最近的3个点蓝色和红色哪个多,上图明显是红色多,所以绿色的点的分类是红色分类。如果knn的k=5,距离绿色的点最近的5个点蓝色和红色哪个多,上图明显是蓝色3个红色2个,所以绿色的点的分类是蓝色分类。
分类实战
1)导入需要用到的模块
import pandas as pdfrom sklearn.model_selection import cross_val_scoreimport numpy from sklearn.preprocessing import LabelEncoderfrom sklearn import neighborsimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn import linear_model
2)准备数据
k近邻的分类标签必须是数值型的,sklearn里面有LabelEncoder来自动把文本分类转化为离散数值型发分类。为了方便我们通过图表查看结果,我们选取了两个特征向量进行分类拟合。
iris = pandas.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None)iris.columns=['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']le = LabelEncoder()le.fit(iris['Species'])features = ['SepalWidthCm','PetalWidthCm']X = iris[features]y = le.transform(iris['Species'])
3)建立模型和拟合
knn = neighbors.KNeighborsClassifier(10,weights='uniform')model = knn.fit(X,y)score = numpy.mean(cross_val_score(knn,X,y,cv=5,scoring='accuracy'))print('平均性能得分:'+str(score))
结果:平均性能得分:0.96
就是说预测的准确率是96%
4)画分类图
接下来我们看看预测的和原来的分类的图。我们用原来的X进行knn预测,并把原分类和预测分类通过图表显示出来。
Forecast = knn.predict(X)#用原来的X,利用knn模型进行预测Forecast = pd.DataFrame(Forecast)#转为pandas数据框的格式iris = pd.merge(iris,pd.DataFrame(y),how='inner',right_index=True,left_index=True)#把离散化的新的分类变量合并到irisiris = pd.merge(iris,Forecast,how='inner',right_index=True,left_index=True)#把预测的离散分类变量也合并到irisiris.rename(columns={ iris.columns[5]: "Species_NO" }, inplace=True)#对新的列进行重命名iris.rename(columns={ iris.columns[6]: "Species_NO_Forecast" }, inplace=True)#对新的列进行重命名sns.relplot(x="SepalWidthCm", y="PetalWidthCm", hue="Species_NO", palette="Set1",data=iris)#把分类在图表上画出来。sns.relplot(x="SepalWidthCm", y="PetalWidthCm", hue="Species_NO_Forecast", palette="Set1",data=iris)#把预测分类分类都在图表上画出来。

第一个图是原分类,第二个图是预测分类。可以看出来有四个点的预测是错误的。我们尝试对新的数据进行预测。
5)预测分类
knn.predict([[3,1.4]]) #新数据预测SepalWidthCm=3,PetalWidthCm=1.4进行预测
结果:Out[78]: array([1], dtype=int64),即预测为1的分类。
6)与逻辑回归对比
我们尝试用logistic回归进行分类,用来于k近邻的模型对比
lm = linear_model.LogisticRegression()model = lm.fit(X,y)score = numpy.mean(cross_val_score(lm,X,y,cv=5,scoring='accuracy'))print('平均性能得分:'+str(score))
结果:平均性能得分:0.94 ,就是说预测的准确率是94%
2 回归
有一系列样本坐标(x,y),然后给定一个测试点坐标 x1,求回归曲线上对应的 y1 值。用knn的话,最简单的做法就是取 k 个离 x1 最近的样本坐标,然后对他们的 y1 值求平均。

如上图一个新的x值(上图红点),k=5表示与x距离最近的五个点(红线链接),这五个点的平均值,就作为y的预测值。
回归实战
1)准备数据
因为我们需要用图形来表现,所以我们用一元线性回归进行演示。
X1 = numpy.arange(1,71)Y1= [11.31,10.94,11.37,11.49,12.03,12.73,13.07,13.29,13.56,18.73,22.24,24.76,24.45,25.52,25.08,25.87,26.56,26.96,26.57,27.39,31.54,35.60,38.41,38.44,39.08,39.26,39.52,40.31,39.87,40.32,40.65,41.16,41.49,45.02,46.98,47.92,47.53,48.41,48.94,48.89,49.22,49.41,49.53,50.24,50.72,50.71,50.83,51.25,52.30,51.84,49.92,48.31,48.15,48.25,48.99,49.08,49.08,49.45,50.34,48.15,42.39,41.38,41.17,42.06,42.30,42.26,42.51,42.93,43.09,41.76]X1 = pd.DataFrame(X1)Y1 = pd.DataFrame(Y1)
2)建立模型和拟合
knn = neighbors.KNeighborsRegressor(5,weights = 'uniform')model = knn.fit(X1,Y1)FsctY = knn.predict(X1)FsctY = pd.DataFrame(FsctY)score = numpy.mean(-cross_val_score(knn,X1,Y1,cv=5,scoring='neg_mean_squared_error'))print('平均性能得分:'+str(score))
平均性能得分:34.4531503429
3)画拟合图
在图表上显示原数据和预测数据。
data= pd.merge(X1,Y1,how='inner',right_index=True,left_index=True)data= pd.merge(data,FsctY,how='inner',right_index=True,left_index=True)data.columns=['X1','Y1','FsctY']fig = plt.figure(figsize=[18,6])#设定图片大小ax = fig.add_subplot(111)#添加第一副图sns.relplot(x='X1',y='Y1',data=data,ax=ax)sns.relplot(x='X1',y='FsctY',data=data,ax=ax,kind='line')
 4)与线性回归对比
4)与线性回归对比
lm = linear_model.LinearRegression()
model = lm.fit(X1,Y1)
score = numpy.mean(-cross_val_score(lm,X1,Y1,cv=5,scoring='neg_mean_squared_error'))
print('平均性能得分:'+str(score))
平均性能得分:190.350116387
5)调参
我们希望寻找一个最优的k,我们可以通过遍历k进行迭代。
score_list =[]for i in np.arange(3,100):knn = neighbors.KNeighborsClassifier(i,weights='uniform')score = cross_val_score(knn,X,y,cv=5,scoring='accuracy').mean()score_list.append(score)plt.figure(figsize=[10,5])plt.plot(range(3,100),score_list)plt.show()
 我们可以看出来,k从3开始到60,基本上比较稳定,再大的k值,准确率迅速下降。
我们可以看出来,k从3开始到60,基本上比较稳定,再大的k值,准确率迅速下降。
用下面的代码,通过GridSearchCV进行网格搜索(参数遍历),同样可以得到上图,并能自动判定最好的参数。
from sklearn.grid_search import GridSearchCVscore_list =[]param_test8 = {'n_neighbors':np.arange(3,101,1)}gsearch8 = GridSearchCV(estimator = neighbors.KNeighborsClassifier(weights='uniform'),param_grid = param_test8, scoring='accuracy',iid=False, cv=5)gsearch8.fit(X,y)gsearch8.grid_scores_, gsearch8.best_params_, gsearch8.best_score_for i in gsearch8.grid_scores_:score_list.append(i.mean_validation_score)plt.figure(figsize=[10,5])plt.plot(range(3,101),score_list)plt.show()
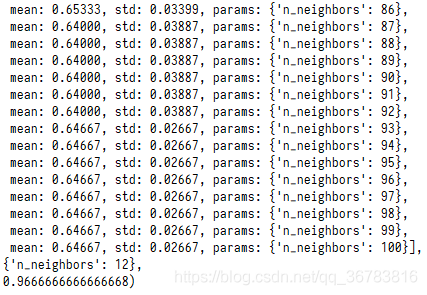
最好的k为12,准确率为96.6667%
3 总结
对于任何的预测模型,我们要解决的两个问题就是如何解释模型,以及如何读懂模型分析的输出。
对于KNN,我们还要解决另外两个问题,一个是K值的确定,另一个是距离的度量。如果数据之间线性关系比较明显的话,线性回归会优于KNN,如果数据之间线性关系不明显的话,KNN会比较好一些。但总得来说,这两个都是机器学习中最简单,最基础的模型。随着维度的上升,这两个模型,尤其是KNN会面临失效的问题,这就是所谓的维度灾难。
- 当自变量维度在1-3时,选择KNN方法能够显著减少误差,当维度为1时,KNN方法能够提供比线性回归更多的信息来进行回归,但随着变量逐渐增多,K个最近的观测值对应的因变量的均值可能会成倍的距离偏离实际的因变量的值,因此当变量多的时候,KNN效果就会逐渐降低。
- 使用线性回归时,一般不受到变量个数的影响,因此变量多少,对残差的影响并不是很大。当预测变量或是自变量多于3或4时,尽量选择线性回归作为回归效果可能会更好些。线性回归不能拟合非线性数据。
- KNN计算量大,大量的数据分析对设备性能要求高。
4 代码
import pandas as pdfrom sklearn.model_selection import cross_val_scoreimport numpy as npfrom sklearn.preprocessing import LabelEncoderfrom sklearn import neighborsimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn import linear_modeliris = pd.read_csv('iris.data',header=None)iris.columns=['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']le = LabelEncoder()le.fit(iris['Species'])features = ['SepalWidthCm','PetalWidthCm']X = iris[features]y = le.transform(iris['Species'])knn = neighbors.KNeighborsClassifier(3,weights='uniform')model = knn.fit(X,y)score = np.mean(cross_val_score(knn,X,y,cv=5,scoring='accuracy'))print('KNN分类模型平均性能得分:'+str(score))Forecast = knn.predict(X)#用原来的X,利用knn模型进行预测Forecast = pd.DataFrame(Forecast)#转为pandas数据框的格式iris = pd.merge(iris,pd.DataFrame(y),how='inner',right_index=True,left_index=True)#把离散化的新的分类变量合并到irisiris = pd.merge(iris,Forecast,how='inner',right_index=True,left_index=True)#把预测的离散分类变量也合并到irisiris.rename(columns={ iris.columns[5]: "Species_NO" }, inplace=True)#对新的列进行重命名iris.rename(columns={ iris.columns[6]: "Species_NO_Forecast" }, inplace=True)#对新的列进行重命名sns.relplot(x="SepalWidthCm", y="PetalWidthCm", hue="Species_NO", palette="Set1",data=iris)#把分类在图表上画出来。sns.relplot(x="SepalWidthCm", y="PetalWidthCm", hue="Species_NO_Forecast", palette="Set1",data=iris)#把预测分类分类都在图表上画出来。knn.predict([[3,1.4]]) #新数据预测SepalWidthCm=3,PetalWidthCm=1.4进行预测#我们尝试用logistic回归进行模型对比。lm = linear_model.LogisticRegression()model = lm.fit(X,y)score = np.mean(cross_val_score(lm,X,y,cv=5,scoring='accuracy'))print('logistic回归模型平均性能得分:'+str(score))#knn回归X1 = np.arange(1,71)Y1= [11.31,10.94,11.37,11.49,12.03,12.73,13.07,13.29,13.56,18.73,22.24,24.76,24.45,25.52,25.08,25.87,26.56,26.96,26.57,27.39,31.54,35.60,38.41,38.44,39.08,39.26,39.52,40.31,39.87,40.32,40.65,41.16,41.49,45.02,46.98,47.92,47.53,48.41,48.94,48.89,49.22,49.41,49.53,50.24,50.72,50.71,50.83,51.25,52.30,51.84,49.92,48.31,48.15,48.25,48.99,49.08,49.08,49.45,50.34,48.15,42.39,41.38,41.17,42.06,42.30,42.26,42.51,42.93,43.09,41.76]X1 = pd.DataFrame(X1)Y1 = pd.DataFrame(Y1)knn = neighbors.KNeighborsRegressor(5,weights = 'uniform')model = knn.fit(X1,Y1)FsctY = knn.predict(X1)FsctY = pd.DataFrame(FsctY)score = np.mean(-cross_val_score(knn,X1,Y1,cv=5,scoring='neg_mean_squared_error'))print('KNN回归模型平均性能得分:'+str(score))data= pd.merge(X1,Y1,how='inner',right_index=True,left_index=True)data= pd.merge(data,FsctY,how='inner',right_index=True,left_index=True)data.columns=['X1','Y1','FsctY']fig = plt.figure(figsize=[18,6])#设定图片大小ax = fig.add_subplot(111)#添加第一副图sns.relplot(x='X1',y='Y1',data=data,ax=ax)sns.relplot(x='X1',y='FsctY',data=data,ax=ax,kind='line')lm = linear_model.LinearRegression()model = lm.fit(X1,Y1)score = np.mean(-cross_val_score(lm,X1,Y1,cv=5,scoring='neg_mean_squared_error'))print('线性回归平均性能得分:'+str(score))#第一种方法调参score_list =[]for i in np.arange(3,100):knn = neighbors.KNeighborsClassifier(n_neighbors=i,weights='uniform')score = cross_val_score(knn,X,y,cv=5,scoring='accuracy').mean()score_list.append(score)plt.figure(figsize=[10,5])plt.plot(range(3,100),score_list)plt.show()#第二种方法调参from sklearn.grid_search import GridSearchCVscore_list =[]param_test8 = {'n_neighbors':np.arange(3,101,1)}gsearch8 = GridSearchCV(estimator = neighbors.KNeighborsClassifier(weights='uniform'),param_grid = param_test8, scoring='accuracy',iid=False, cv=5)gsearch8.fit(X,y)gsearch8.grid_scores_, gsearch8.best_params_, gsearch8.best_score_for i in gsearch8.grid_scores_:score_list.append(i.mean_validation_score)plt.figure(figsize=[10,5])plt.plot(range(3,101),score_list)plt.show()







