1、SQL Server 了解
SQL Server 2014是Microsoft公司推出的一款关系型数据库管理系统,它在数据库领域具有广泛的影响力和应用。
1.1 SQL Server 2014 主要特性【简单了解就行】
SQL Server 2014 引入了一系列新特性和改进,这些特性和改进旨在提高性能、增强安全性、简化管理以及加强与其他工具和技术的集成。
- 内存优化技术(In-Memory OLTP):
引入了一种新的内存优化表类型,这些表将数据存储在内存中而不是传统的磁盘上,从而极大地提高了事务处理的速度。
适用于需要高性能、低延迟和高吞吐量的OLTP工作负载。 - 列存储索引:
提供了一种新的列存储索引,特别适用于分析查询和大数据工作负载。
列存储索引将数据以列为单位进行存储,从而提高了数据压缩率和查询性能。 - AlwaysOn 可用性组:
增强了 AlwaysOn 可用性组的功能,提供了更高级别的数据冗余和故障转移能力。
可用性组允许您在多个副本之间实现数据库的高可用性,并在出现故障时自动将流量重定向到备用副本。 - 备份和恢复增强:
提供了更灵活和可靠的备份和恢复选项,包括备份压缩、增量备份和页面还原。
备份压缩可以减小备份文件的大小并减少备份和还原所需的带宽和时间。 - 混合云解决方案:
提供了与 Microsoft Azure 的集成,允许您将 SQL Server 数据库扩展到云端。
提供了备份到 Azure、Azure 虚拟机中的 SQL Server 以及 SQL Server 弹性池等选项。 - 安全性增强:
引入了透明数据加密(TDE)的增强功能,包括加密密钥的滚动和更精细的访问控制。
提供了 Always Encrypted 功能,允许在客户端和服务器之间加密敏感数据,以保护数据在传输和存储时的安全性。 - Power BI 集成:
增强了与 Power BI 的集成,允许用户更轻松地将 SQL Server 数据用于数据分析和可视化。
提供了 Power Query 和 Power Pivot 的更新,使用户能够更方便地从各种源导入和分析数据。 - 高可用性增强:
提供了更多的高可用性选项,如 AlwaysOn 故障转移群集实例和 AlwaysOn 读取可扩展性组。
这些选项允许您根据业务需求配置适当的高可用性解决方案。 - 性能监视和诊断:
提供了更强大的性能监视和诊断工具,如 SQL Server Management Studio (SSMS) 和 SQL Server Profiler 的更新。
这些工具可以帮助您监视和诊断性能问题,以便更快地解决它们。 - 简化的安装和配置:
提供了更简化的安装和配置选项,使设置和管理 SQL Server 变得更加容易。
引入了新的安装向导和配置管理器,使用户能够更轻松地完成安装和配置任务。
SQL Server各个版本
| 序号 | 版本名称 | 发布年份 | 主要特性 |
|---|---|---|---|
| 1 | SQL Server 4.21 | 1993年 | 引入了基本的数据库管理功能,如事务处理、数据完整性和并发控制 |
| 2 | SQL Server 6.0 | 1995年 | 引入了新功能,如存储过程、触发器和视图 |
| 3 | SQL Server 6.5 | 1996年 | 改进了性能和可伸缩性 |
| 4 | SQL Server 7.0 | 1998年 | 引入新功能,如OLAP支持、数据仓库和数据挖掘功能 |
| 5 | SQL Server 2000 | 2000年 | 引入了新功能,如XML支持、分布式查询和数据库镜像 |
| 6 | SQL Server 2005 | 2005年 | 引入了CLR集成、XML数据类型和快照隔离事务 |
| 7 | SQL Server 2008 | 2008年 | 引入了分区表、稀疏列、数据库压缩和表值参数等特性 |
| 8 | SQL Server 2008 R2 | 未具体提供年份 | 引入了主从复制的增强功能、备份压缩和PowerPivot等 |
| 9 | SQL Server 2012 | 2013年 | 引入了列存储索引、AlwaysOn可用性组和FileTable等 |
| 10 | SQL Server 2014 | 2014年 | 引入了内存优化表、延迟数据库复制和缩放性增强等特性 |
| 11 | SQL Server 2016 | 2017年 | 引入了JSON支持、Stretch Database和PolyBase等特性,支持Linux操作系统和Hadoop集成 |
| 12 | SQL Server 2017 | 2017年 | 支持跨平台,能在Linux操作系统上运行SQL Server,引入了自适应查询处理和图数据库功能 |
| 13 | SQL Server 2019 | 2019年 | 引入了Big Data Clusters、加密扩展和智能查询处理等功能,加强了大数据平台的数据管理和分析能力 |
| 14 | SQL Server 2022 | 2022年 | 增强了自适应查询功能、安全性和高可用性功能,提供了对ARM处理器的支持 |
2、SQL Server2014 安装
请转到 https://blog.csdn.net/weixin_46171048/article/details/139946232
3、数据库操作
3.1 数据库的创建
在SQL Server中创建数据库,可以通过两种主要方式进行:使用SQL Server Management Studio(SSMS)的图形化界面,或者使用Transact-SQL(T-SQL)中的CREATE DATABASE语句。
使用Transact-SQL(T-SQL)中的CREATE DATABASE语句
CREATE DATABASE [数据库名]
ON
( NAME = [数据库名], FILENAME = 'D:\SQLData\[数据库名].mdf', --数据文件SIZE = 10, -- 大小MAXSIZE = 50, -- 最大大小FILEGROWTH = 5 ) -- 增长量
LOG ON
( NAME = [数据库名_log], FILENAME = 'D:\SQLData\[数据库名_log].ldf', -- 日志文件SIZE = 5MB, MAXSIZE = 25MB, FILEGROWTH = 5MB ) ;
实际操作如下:
CREATE DATABASE testdb2 ON PRIMARY
( NAME = 'testdb2', FILENAME = 'D:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\testdb2.mdf', --数据文件SIZE = 10, -- 大小MAXSIZE = 50, -- 最大大小FILEGROWTH = 5 ) -- 增长量
LOG ON
( NAME = 'testdb2_Log', FILENAME = 'D:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\\testdb2_Log.ldf', -- 日志文件SIZE = 5MB, MAXSIZE = 25MB, FILEGROWTH = 5MB ) ;
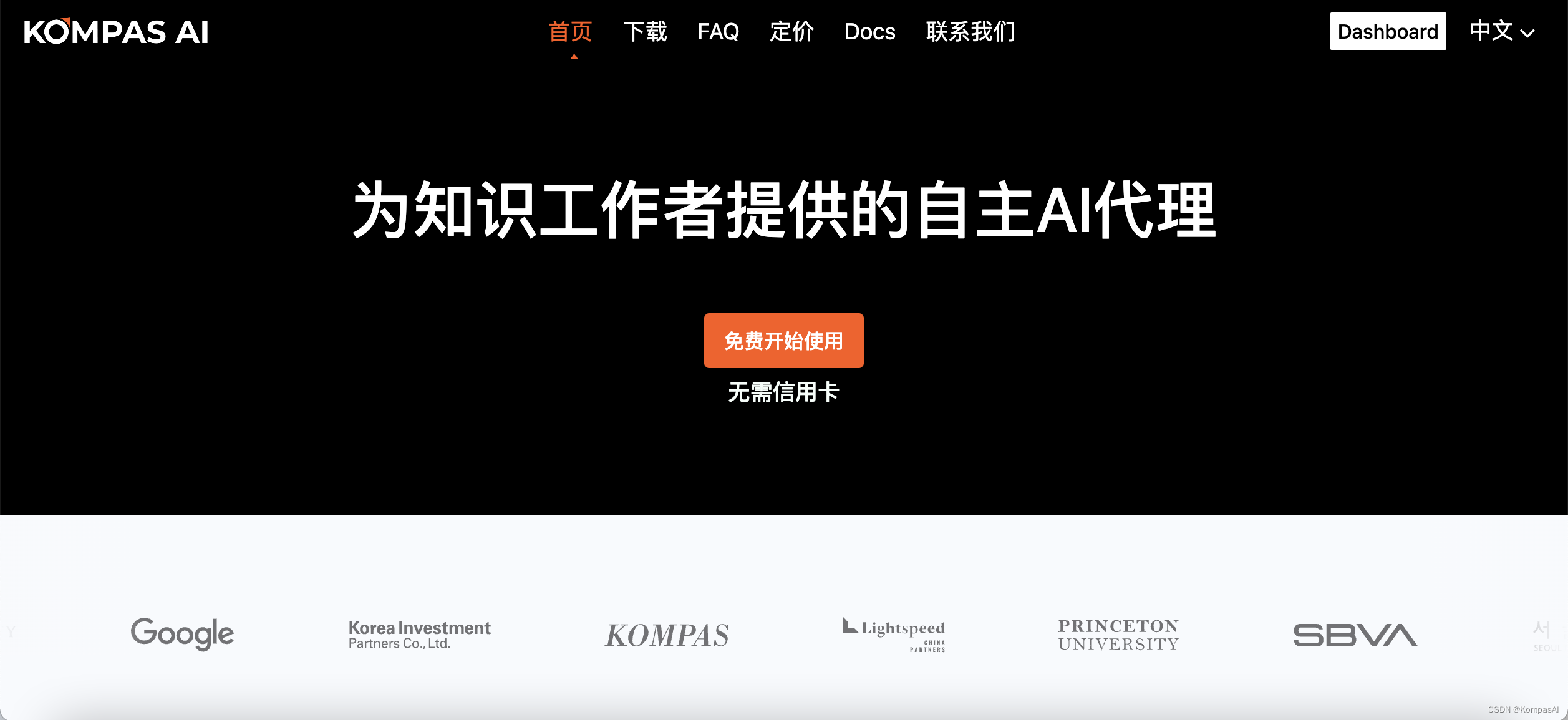
3.2 创建数据库工具界面具体操作
右键选择【新建数据库】 ,为数据库取名称,可以设置参数,修改数据文件(.mdf)和日志文件(.ldf)的路径、大小、最大大小和增长量
3.3 数据库的修改
修改数据库名称
ALTER DATABASE YourDatabaseName
MODIFY NAME = NewDatabaseName
COLLATE Chinese_PRC_CI_AS;
-- 注意:MODIFY NAME 用于重命名数据库,而 COLLATE 用于更改排序规则
修改数据文件
-- 修改数据库文件
ALTER DATABASE testdb2
MODIFY FILE(
NAME = ‘testdb2’ , -- 数据库名称是原来的文件名称(之前就算修改了数据库也是原来的数据库名称)
SIZE = 20MB,
MAXSIZE = 80MB,
FILEGROWTH = 10MB
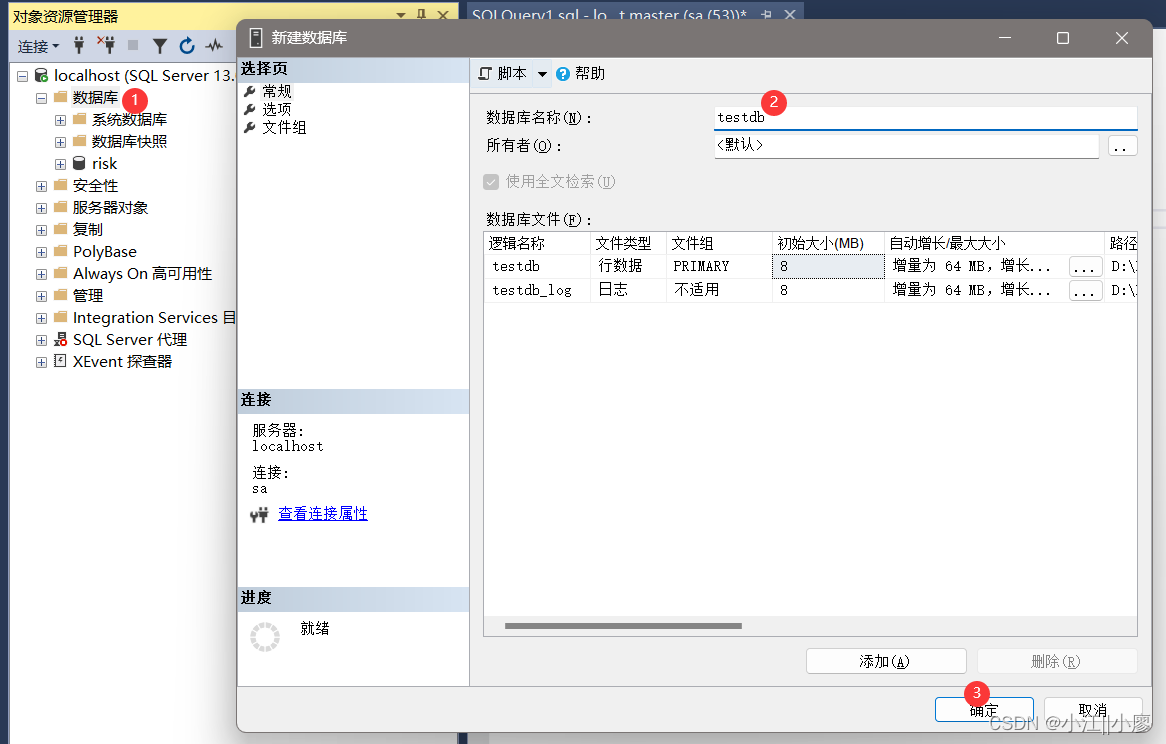
) 3.4 数据库工具界面具体操作
选中数据库右键点击【属性】,再文件重可以修改参数
3.5 数据库删除
使用 DROP DATABASE 语句可以删除数据库及其所有对象和数据。
-- 删除数据库
DROP DATABASE testdb2;
4、 数据库备份与还原
备份是保护数据、确保业务连续性和满足合规性要求的重要措施。
还原是恢复数据、进行测试、审计、故障排查和版本迁移的关键操作。
4.1 数据库备份
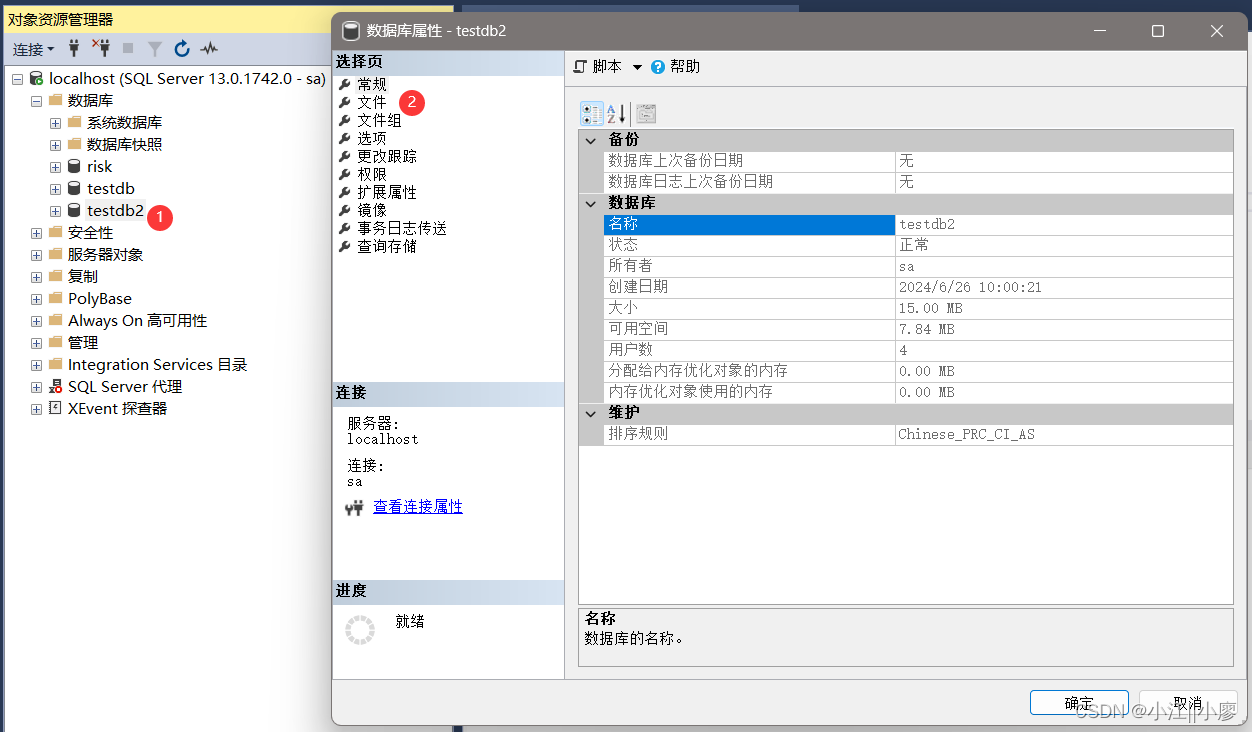
1、在“对象资源管理器”中,找到并展开“数据库”节点。
2、右键点击你想要备份的数据库,选择“任务” -> “备份”。
3、备份类型:
完整:备份整个数据库,包括所有数据、事务日志和所有系统对象。
差异:只备份自上次完整备份以来发生更改的数据。
事务日志:只备份事务日志中的内容,允许执行数据库的点时间恢复。
4、目标:
选择备份文件的存储位置,可以是本地磁盘、网络位置或备份设备。
输入备份文件的名称和路径。
5、点击确认
4.2 数据库还原
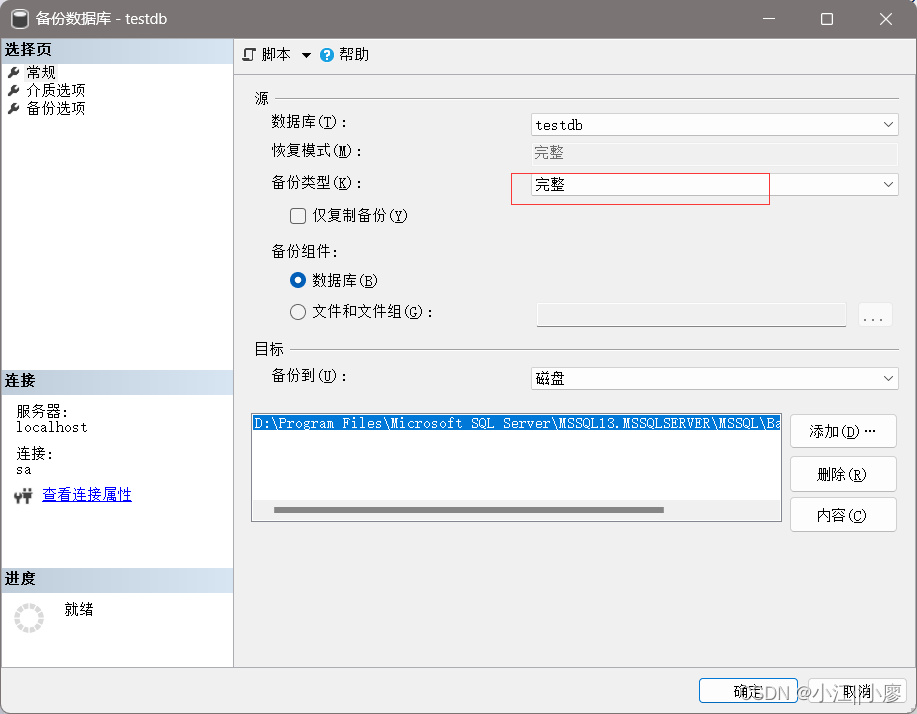
1、右键点击,选择“任务” -> “还原” -> “数据库”。
2、点击【设备】–>【设备】–>选择需要还原的.bak文件
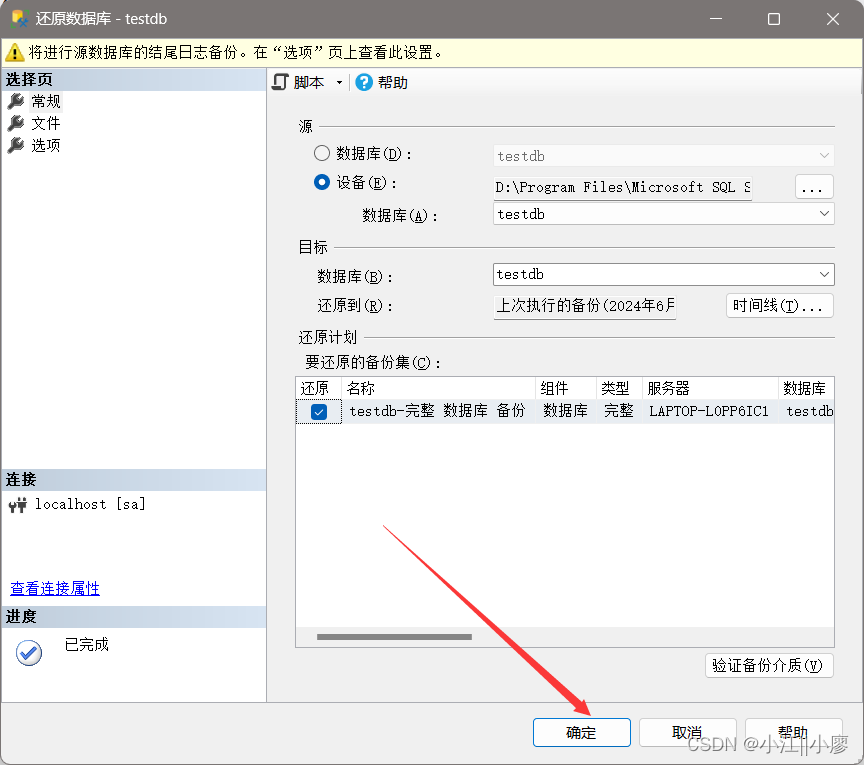
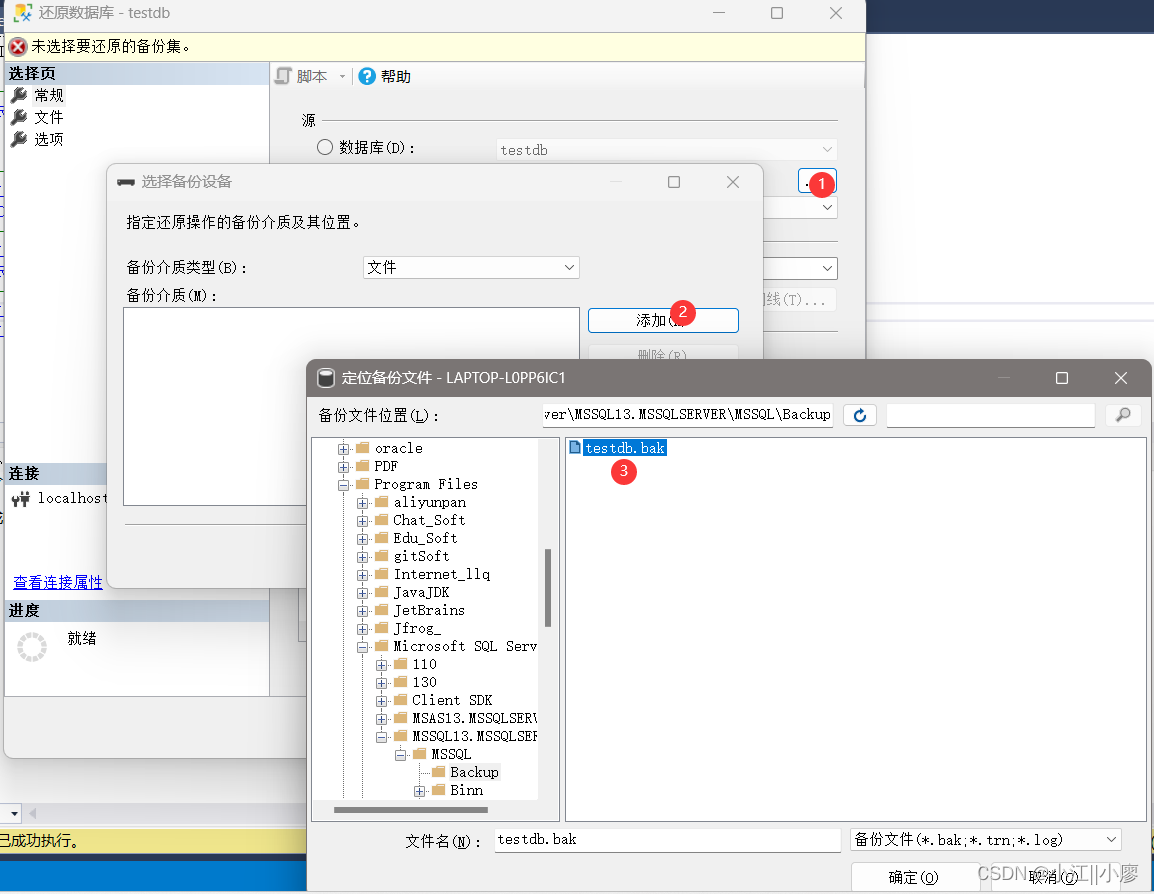 点击确认就行
点击确认就行
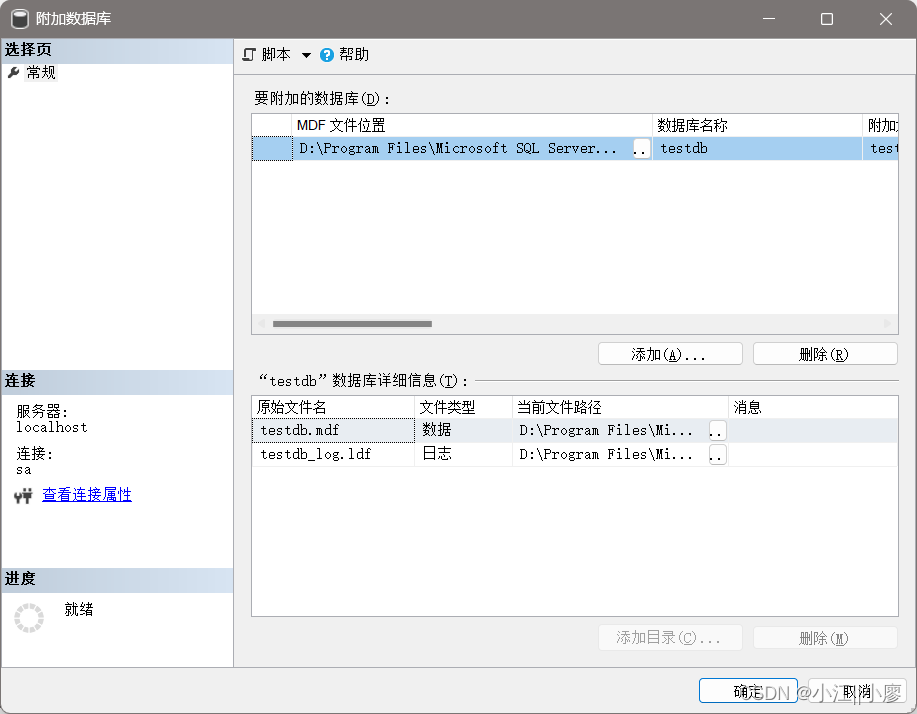
通过数据组数据文件来还原 【附加】
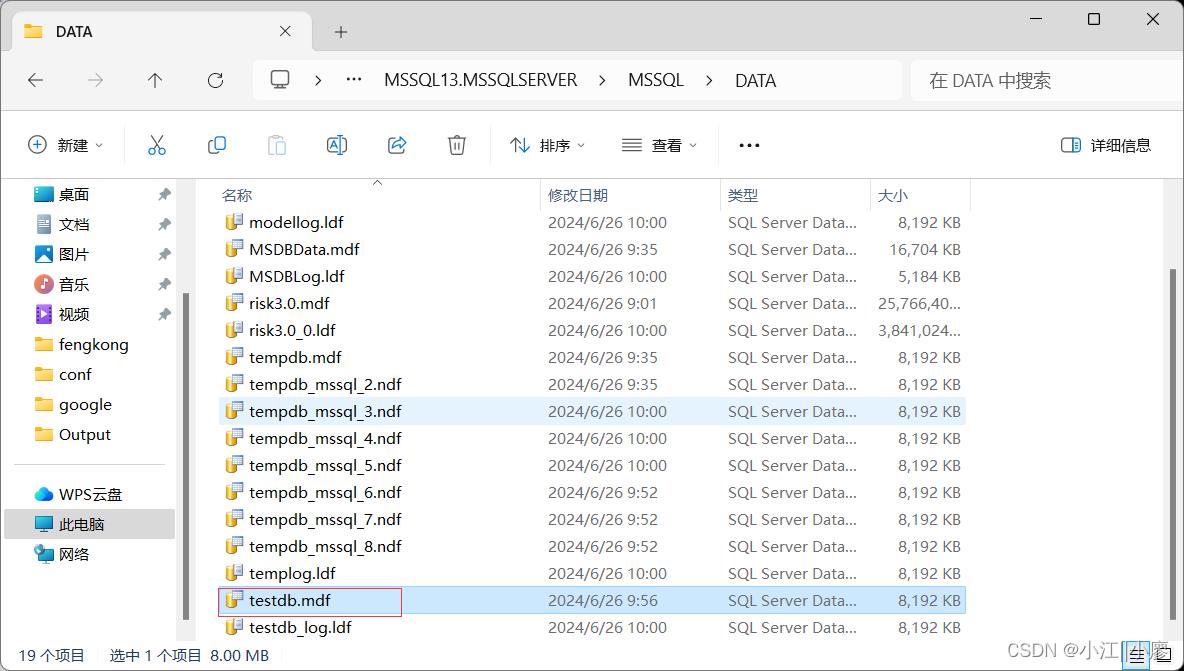
1、SQL Server Management Studio 选择“任务” -> “分离” ,点击分离后,数据库就看不见了。
2、右键数据库点击【附加】
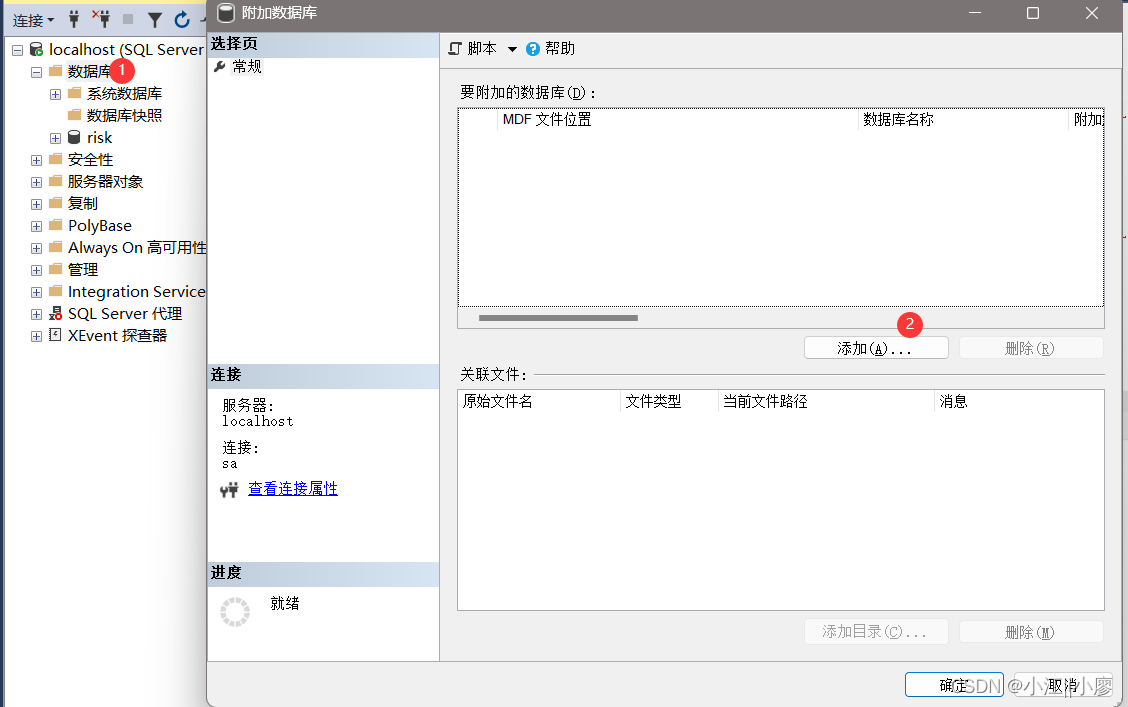
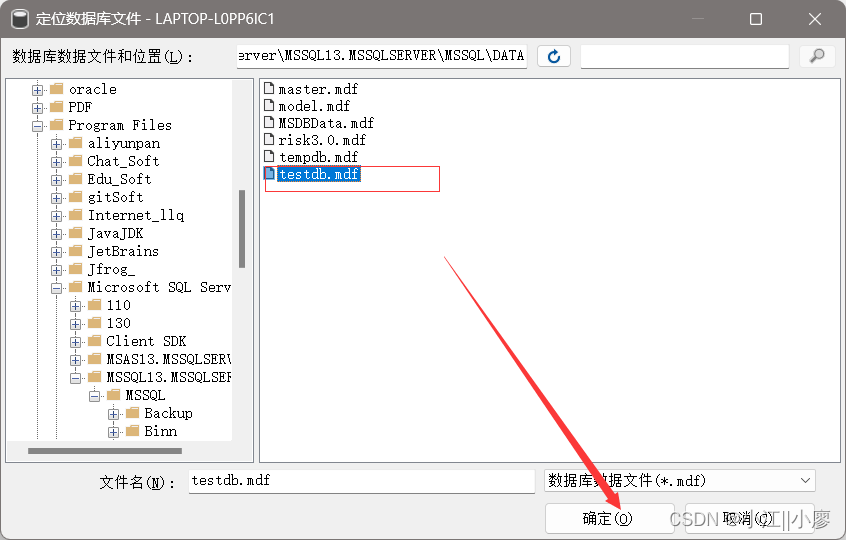
点击确认,可以还原数据库
5、数据类型 【和其它数据库几乎一样,了解过请忽略】
| 数据类型 | 描述 | 示例 | 存储大小 |
|---|---|---|---|
| BIT | 存储二进制值,可以是 0、1 或 NULL | 1 | 1 到 3 字节 |
| TINYINT | 从 0 到 255 的整数 | 123 | 1 字节 |
| SMALLINT | 从 -32,768 到 32,767 的整数 | -12345 | 2 字节 |
INT | 从 -2,147,483,648 到 2,147,483,647 的整数 | 123456789 | 4 字节 |
| BIGINT | 从 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 的整数 | 9223372036854775807 | 8 字节 |
| DECIMAL(p,s) / NUMERIC(p,s) | 精确数值数据类型,具有 p(精度)和 s(小数位数) | DECIMAL(10,2) 可以存储 12345678.90 | p+s 字节,最大为 17 字节 |
| FLOAT(n) | 近似数值数据类型,n 指定精度(1-53) | FLOAT(24) | 4 或 8 字节 |
| REAL | 近似数值数据类型,单精度浮点数 | 123.45 | 4 字节 |
DATE | 仅日期 | ‘2023-10-23’ | 3 字节 |
TIME | 仅时间 | ‘13:45:30.1234567’ | 3 到 5 字节,取决于精度 |
| DATETIME | 日期和时间 | ‘2023-10-23 13:45:30.123’ | 8 字节 |
| DATETIME2(n) | 日期和时间,具有 n 的小数秒精度 | DATETIME2(7) 可以存储 ‘2023-10-23 13:45:30.1234567’ | 6 到 8 字节,取决于精度 |
| SMALLDATETIME | 日期和时间,但精度较低 | ‘2023-10-23 13:45:00’ | 4 字节 |
CHAR(n) | 固定长度的非 Unicode 字符序列 | CHAR(10) 可以存储 ‘Hello’ | n 字节,最大为 8,000 字节 |
VARCHAR(n) | 可变长度的非 Unicode 字符序列 | VARCHAR(10) 可以存储 ‘Hello’ | n+2 字节,最大为 8,000 字节 |
| TEXT | 存储大量的非 Unicode 字符数据 | ‘Long text…’ | 最大为 2^31-1 字节 (2 GB) |
| NCHAR(n) | 固定长度的 Unicode 字符序列 | NCHAR(10) 可以存储 ‘こんにちは’ | 2n 字节,最大为 16,000 字节 |
NVARCHAR(n) | 可变长度的 Unicode 字符序列 | NVARCHAR(10) 可以存储 ‘こんにちは’ | 2n+2 字节,最大为 16,000 字节 |
| NTEXT | 存储大量的 Unicode 字符数据 | ‘Long text in Unicode…’ | 最大为 2^30-1 字节 (1 GB) |
| BINARY(n) | 固定长度的二进制数据 | BINARY(10) 可以存储任意 10 字节的二进制数据 | n 字节,最大为 8,000 字节 |
| VARBINARY(n) | 可变长度的二进制数据 | VARBINARY(10) 可以存储任意 10 字节的二进制数据 | n+2 字节,最大为 8,000 字节 |
| IMAGE | 存储大量的二进制数据 | ‘Binary image data…’ | 最大为 2^31-1 字节 (2 GB) |
| UNIQUEIDENTIFIER | 存储全局唯一标识符 (GUID) | '6F9619FF-8 |
6、表的操作
6.1 图形化工具创建
6.2 SQL语句创建表
执行创建数据库语句后,刷新数据库—>查看【表】
-- 创建表use testdb -- 选择数据库CREATE TABLE userInfo ( ID INT PRIMARY KEY IDENTITY(1,1), --IDENTITY(1,1) 自动增加1name VARCHAR(50) NOT NULL, age int NULL,
);
6.3 操作表结构
6.3.1 添加not null 约束或修改列
alter table 表名
alter column 字段名 字段类型 not null
6.3.2 设置主键或外键
alter table 表名
add constraint 主键名 primary key(字段名)-- 设置外键
ALTER TABLE 表名
ADD CONSTRAINT 外键名称[FK_主_从] FOREIGN KEY (从表重外键ID) REFERENCES 主表(主表ID);
6.3.3 更改字段名或表名
-- 更改字段名
EXEC sp_rename 'userInfo.age','userage','column'-- 更改表名
EXEC sp_rename 'OldTableName', 'NewTableName';6.3.4 添加字段名
alter table 表名 add 字段名 字段类型 [DEFAULT null]
6.3.5 添加唯一约束
还可以添加PRIMARY KEY、FOREIGN KEY、CHECK等约束
ALTER TABLE Employees
ADD CONSTRAINT UC_Email UNIQUE (Email);
6.3.6 删除列
ALTER TABLE 表名
DROP COLUMN 列名;
6.3.4 删除表
DROP TABLE 表名;
7、定义表主键、外键
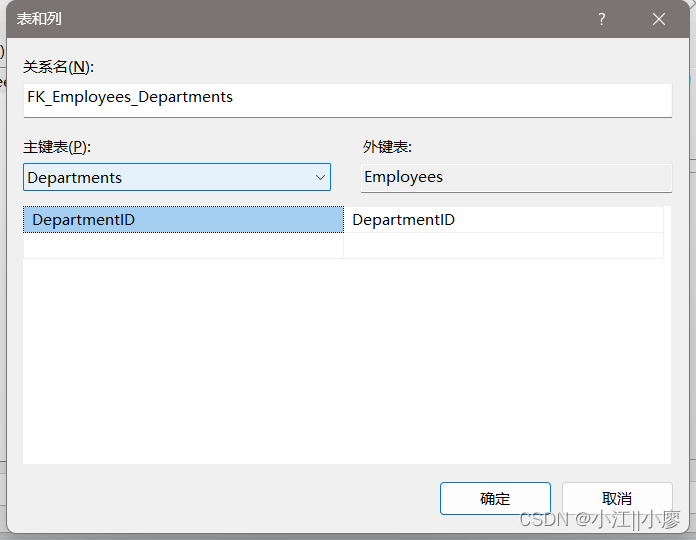
主表
CREATE TABLE Departments ( DepartmentID INT PRIMARY KEY, DepartmentName NVARCHAR(50) -- 其他列...
);
下面是从表
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, FirstName NVARCHAR(50), LastName NVARCHAR(50), DepartmentID INT, CONSTRAINT FK_Employees_Departments FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID) -- 其他列和约束...
);
也可以先创建表后设置外键关系
-- 创建外键
alter table employees
add constraint FK_EM_DE foreign key(DepartmentID) references Departments(DepartmentID)
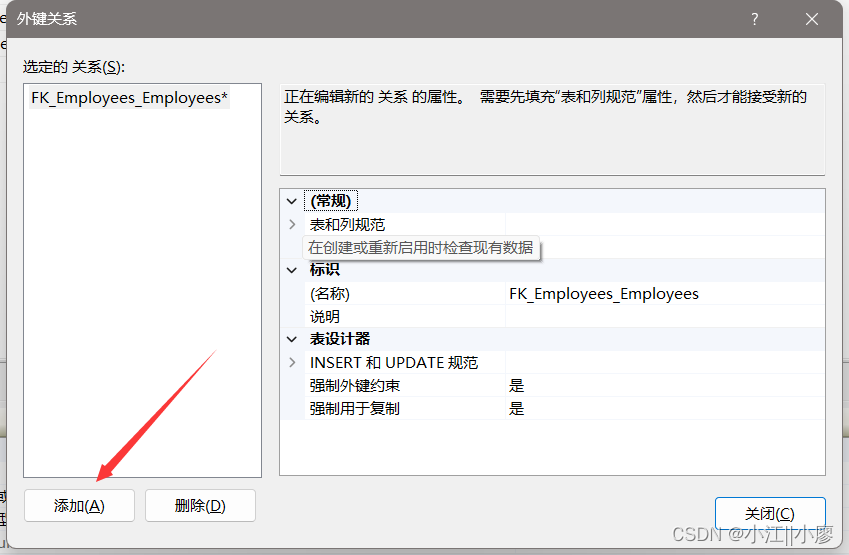
7.1 图形化界面设置外键
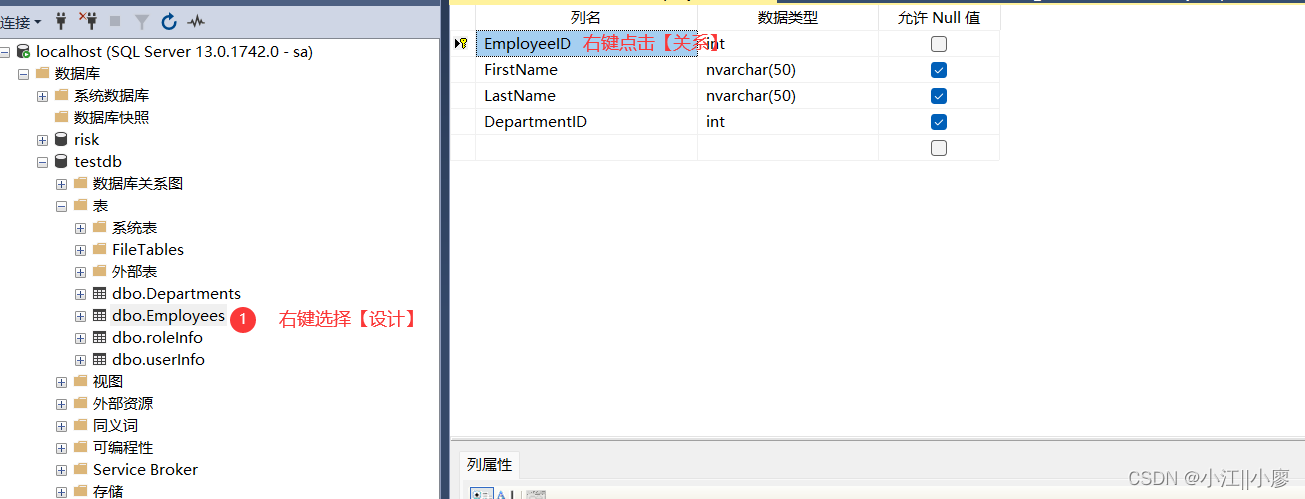 点击【添加】
点击【添加】
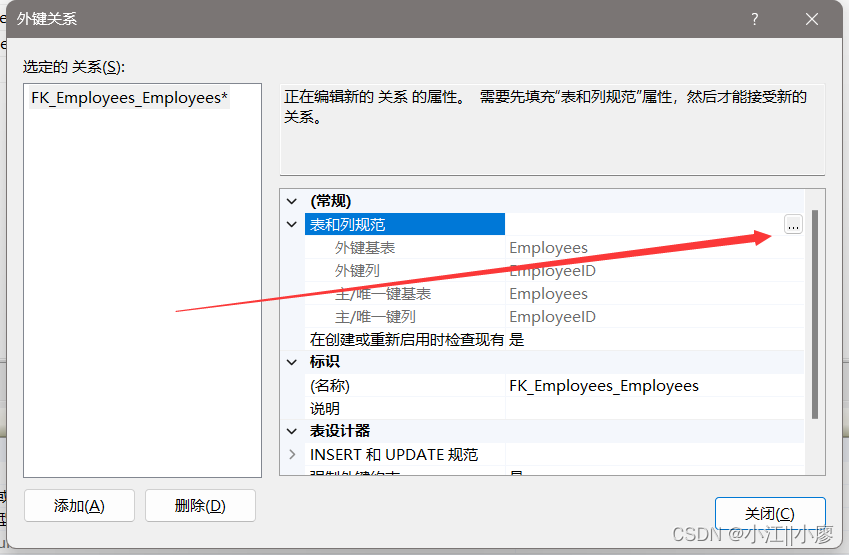
 设置表和列规范
设置表和列规范
设置主键表和外键表的关系
8、数据库CRUD
8.1 新增数据
单个表的新增
create table student(name varchar(20),age int,email varchar(50)
)-- 添加多行数据
INSERT INTO student (Name, Age, Email)
VALUES ('John Doe', 30, 'john.doe@example.com'), ('Jane Smith', 25, 'jane.smith@example.com');从其它表拷贝数据,注意的是列的数量和类型要对应
create table student2(name varchar(20),age int,email varchar(50)
)INSERT INTO student2 (Name, Age, Email)
SELECT NAME , Age,Email FROM student
8.2 查询数据
-- 查询所有学生
SELECT * FROM student;SELECT Name, Email FROM student;-- 去重 distinct
SELECT distinct Name, Email FROM student;-- 查询前五条数据
SELECT top 5 * FROM student;-- 查询所有年龄大于30岁的学生:SELECT * FROM student WHERE Age > 30;
-- 按年龄对学生进行排序
SELECT * FROM student ORDER BY Age ASC; -- 升序排序
SELECT * FROM student ORDER BY Age DESC; -- 降序排序-- 按年龄组对学生进行分组,并计算每个年龄组的学生数:
SELECT Age, COUNT(*) AS NumberOfStudent
FROM student
GROUP BY Age;-- 筛选出学生数超过2的年龄组:
SELECT Age, COUNT(*) AS NumberOfEmployees
FROM student
GROUP BY Age
HAVING COUNT(*) > 2;
-- 查询名字以'Jo'开头的学生
SELECT * FROM student WHERE Name LIKE 'Jo%';
8.3 修改数据
-- 将name为'John Doe'的学生的age修改为25UPDATE student
SET age = 25
WHERE name = 'John Doe';-- 将name为'Jane Smith'的学生的age修改为26,并且将email修改为jane.newemail@example.comUPDATE student
SET age = 26, email = 'jane.newemail@example.com'
WHERE name = 'Jane Smith';-- 将所有age大于20的学生的email都添加一个后缀_studentUPDATE student
SET email = email + '_student'
WHERE age > 20;-- 设计age小于20,则添加_junior后缀,如果age在20到25之间,则添加_student后缀,如果age大于25,则添加_senior后缀UPDATE student
SET email = CASE WHEN age < 20 THEN email + '_junior' WHEN age BETWEEN 20 AND 25 THEN email + '_student' WHEN age > 25 THEN email + '_senior' ELSE email -- 其他情况保持原样
END
WHERE email IS NOT NULL AND email <> ''; -- 排除空或NULL的email字段8.4 删除数据
-- 删除name为'John Doe'的学生的记录
DELETE FROM student
WHERE name = 'John Doe';-- 删除所有年龄大于25的学生的记录
DELETE FROM student
WHERE age > 25;-- 删除所有记录
DELETE FROM student;
-- 或
TRUNCATE TABLE student; -- TRUNCATE TABLE是一个不可回滚的操作
8.5 条件限制where
-- 查询名字为'John Doe'的学生
SELECT * FROM student
WHERE name = 'John Doe';-- 查询邮箱以'@example.com'结尾的学生
SELECT * FROM student
WHERE email LIKE '%_senior';-- 查询名字包含'doe'的学生(默认不区分大小写)
SELECT * FROM student
WHERE name LIKE '%doe%';
-- 查询名字包含'doe'的学生(区分大小写)
SELECT * FROM student
WHERE name COLLATE Latin1_General_BIN LIKE '%doe%';8.6 子查询 IN
--查询年龄为 20、22 或 25 的学生SELECT * FROM student
WHERE age IN (20, 22, 25);-- 从另一个表(比如 student2 )中动态地获取这些允许的年龄,并用于 IN 子句中
SELECT * FROM student
WHERE age IN (SELECT age FROM student2);-- student2 表有一个名为 name 的字段
SELECT * FROM student
WHERE name IN (SELECT name FROM student2);
8.7 EXISTS
EXISTS 是一个布尔运算符,它用于测试子查询是否返回至少一行数据。如果子查询返回至少一行数据,则 EXISTS 运算符返回 TRUE,否则返回 FALSE。这在你想基于另一个表中的数据来过滤结果时特别有用。
-- 查询在 userInfo 表中列出的学生
SELECT *
FROM student s
WHERE EXISTS ( SELECT 1 FROM userInfo ui WHERE ui.name = s.name
);-- 使用 NOT EXISTS 来排除某些学生
SELECT *
FROM student s
WHERE NOT EXISTS ( SELECT 1 FROM userInfo ss WHERE ss.name = s.name
);
EXISTS 通常比使用 IN 更快,特别是当子查询返回大量数据时,因为 EXISTS 会在找到第一行匹配项时立即停止搜索。
8.8 order by
对返回记录集合进行排序
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
-- 排序SELECT *
FROM student order by age -- 默认是asc降序SELECT *
FROM student order by age desc
9、数据库关联查询
9.1 INNER JOIN(内连接)
返回两个表中匹配条件的行。如果某个表中的行在另一个表中没有匹配的行,则这些行不会出现在结果集中。
SELECT A.*, B.*
FROM TableA A
INNER JOIN TableB B ON A.Key = B.Key;
9.2 LEFT JOIN(左外连接)
返回左表中的所有行,以及右表中匹配的行。如果左表中的某行在右表中没有匹配的行,则结果集中右表的部分包含 NULL 值
SELECT A.*, B.*
FROM TableA A
LEFT JOIN TableB B ON A.Key = B.Key;
9.3 RIGHT JOIN(右外连接)
SELECT A.*, B.*
FROM TableA A
RIGHT JOIN TableB B ON A.Key = B.Key;
9.4 FULL JOIN (全外连接)
返回左表和右表中的所有行。如果某行在另一个表中没有匹配的行,则结果集中对应表的部分包含 NULL 值。
SELECT A.*, B.*
FROM TableA A
FULL JOIN TableB B ON A.Key = B.Key;9.5 CROSS JOIN(交叉连接)
返回左表中的每一行与右表中的每一行的组合。它不使用任何连接条件,生成的结果集是左表行数乘以右表行数的笛卡尔积。
SELECT A.*, B.*
FROM TableA A
CROSS JOIN TableB B;
9.6 SELF JOIN(自连接)
一个表与其自身进行连接。通常用于比较表中的行,例如查找具有相同属性但具有不同值的行。
SELECT A.*, B.*
FROM TableA A, TableA B
WHERE A.Column1 = B.Column2 AND A.PrimaryKey <> B.PrimaryKey;
-- 或者使用显式 JOIN 语法
SELECT A.*, B.*
FROM TableA A
INNER JOIN TableA B ON A.Column1 = B.Column2 AND A.PrimaryKey <> B.PrimaryKey;
10、函数
10.1 常见的函数
| 函数名称 | 具体作用 | 示例 |
|---|---|---|
| CONCAT() | 连接两个或多个字符串 | SELECT CONCAT('Hello', ' ', 'World') AS Result; |
| UPPER() | 将字符串转换为大写 | SELECT UPPER('hello') AS UpperResult; |
| LOWER() | 将字符串转换为小写 | SELECT LOWER('HELLO') AS LowerResult; |
| SUBSTRING() | 从字符串中提取子字符串 | SELECT SUBSTRING('Hello World', 1, 5) AS SubstringResult; |
| LEN() | 返回字符串的长度 | SELECT LEN('Hello') AS StringLength; |
| LTRIM() | 删除字符串左侧的空格 | SELECT LTRIM(' Hello') AS LeftTrimResult; |
| RTRIM() | 删除字符串右侧的空格 | SELECT RTRIM('Hello ') AS RightTrimResult; |
| REPLACE() | 在字符串中替换指定的子字符串 | SELECT REPLACE('Hello World', 'World', 'SQL Server') AS ReplaceResult; |
| ABS() | 返回数字的绝对值 | SELECT ABS(-10) AS AbsoluteValue; |
| ROUND() | 将数字四舍五入到指定的小数位数 | SELECT ROUND(123.4567, 2) AS RoundedValue; |
| CEILING() | 向上舍入到最接近的整数 | SELECT CEILING(123.45) AS CeilingValue; |
| FLOOR() | 向下舍入到最接近的整数 | SELECT FLOOR(123.45) AS FloorValue; |
| POWER() | 返回数字的乘方 | SELECT POWER(2, 3) AS PowerResult; |
| SQRT() | 返回数字的平方根 | SELECT SQRT(16) AS SquareRootResult; |
| GETDATE() | 返回当前日期和时间 | SELECT GETDATE() AS CurrentDateTime; |
| DATEADD() | 在日期中添加或减去指定的时间间隔 | SELECT DATEADD(DAY, 1, '2023-09-13') AS NewDate; |
| DATEDIFF() | 返回两个日期之间的时间间隔 | SELECT DATEDIFF(DAY, '2023-09-01', '2023-09-13') AS DateDifference; |
| DAY() | 返回日期的日部分 | SELECT DAY(GETDATE()) AS DayPart; |
| MONTH() | 返回日期的月部分 | SELECT MONTH(GETDATE()) AS MonthPart; |
| YEAR() | 返回日期的年部分 | SELECT YEAR(GETDATE()) AS YearPart; |
| FORMAT() | 将日期/时间/数字转换为格式化的字符串 | SELECT FORMAT(GETDATE(), 'yyyy-MM-dd HH:mm:ss') AS FormattedDateTime; |
10.2 聚合函数
| 函数 | 功能 | 示例(基于student表) |
|---|---|---|
| CONCAT() | 连接两个或多个字符串 | SELECT CONCAT(name, ' (', age, ')') AS full_info FROM student; |
| UPPER() | 将字符串转换为大写 | SELECT UPPER(name) AS upper_name FROM student; |
| LOWER() | 将字符串转换为小写 | SELECT LOWER(email) AS lower_email FROM student; |
| LEFT() | 从字符串的左侧提取指定数量的字符 | SELECT LEFT(email, 4) AS email_prefix FROM student; |
| RIGHT() | 从字符串的右侧提取指定数量的字符 | SELECT RIGHT(email, 3) AS email_suffix FROM student; |
| REPLACE() | 在字符串中替换指定的子字符串 | SELECT REPLACE(email, '@example.com', '@school.edu') AS new_email FROM student; |
| AVG() | 返回数值列的平均值 | SELECT AVG(age) AS average_age FROM student; |
| SUM() | 返回数值列的总和 | SELECT SUM(CASE WHEN ... THEN 1 ELSE 0 END) AS total_count FROM student; -- 假设我们需要基于某些条件计数 |
| GETDATE() | 返回当前日期和时间 | SELECT GETDATE() AS current_date; -- 注意:这里未直接关联student表 |
| DATEDIFF() | 返回两个日期之间的时间间隔 | SELECT DATEDIFF(YEAR, '2020-01-01', GETDATE()) AS years_since_2020; -- 示例,未直接使用student表字段 |
| ISNULL() | 检查一个表达式是否为NULL,如果是则返回另一个值 | SELECT name, ISNULL(age, 0) AS age_or_zero FROM student WHERE age IS NULL; |
| LEN() | 返回字符串的长度 | SELECT name, LEN(email) AS email_length FROM student; |
| CAST() | 数据类型转换 | SELECT name, CAST(age AS NVARCHAR(5)) AS age_string FROM student; |
| CONVERT() | 数据类型转换(与CAST()功能类似) | SELECT name, CONVERT(NVARCHAR(5), age) AS age_string FROM student; |
10.3 RAND() 随机数
-- 可以随机得到一个小时
select rand()-- 向下取整
select floor(rand()*100)
-- 向上取整
select ceiling(rand()*1000)10.4 len() datalength() 区别
LEN 函数返回字符串中的字符数,而 DATALENGTH 返回数据的字节数。对于非 Unicode 字符串,这两个值可能是相同的,但对于 Unicode 字符串,DATALENGTH 的值将是 LEN 值的两倍(再加上可能的额外字节用于存储长度信息)。
NVARCHAR 数据类型用于存储 Unicode 字符,而 VARCHAR 用于存储非 Unicode 字符。因此,NVARCHAR 中的每个字符通常占用 2 个字节,而 VARCHAR 中的每个字符通常占用 1 个字节
-- len() datalength() 区别 取决于数据的类型,可以说是存储方式DECLARE @UnicodeString NVARCHAR(50) = 'Hello';
DECLARE @NonUnicodeString VARCHAR(50) = 'Hello'; SELECT LEN(@UnicodeString) AS UnicodeStringLength, DATALENGTH(@UnicodeString) AS UnicodeDataLength, LEN(@NonUnicodeString) AS NonUnicodeStringLength, DATALENGTH(@NonUnicodeString) AS NonUnicodeDataLength;
11、日期函数
11.1 获取当前时间
GETDATE():常用于本地时间敏感的应用程序,如计划会议、记录本地事件等。
GETUTCDATE():常用于需要全球一致时间戳的应用程序,如日志记录、时间同步、分布式数据库等
-- getdate() getutcdate()select getdate() currentDateselect getutcdate() currentDate
11.2 convert()
CONVERT() 函数用于将一种数据类型转换为另一种数据类型。这个函数非常有用,特别是当你需要将日期、时间、数字或字符数据类型转换为其他格式或类型时。
语法如下:CONVERT (data_type[(length)], expression [, style])-- data_type[(length)]:目标数据类型和长度(如果需要的话)。
-- expression:要转换的值或列。
-- style(可选):对于日期和时间数据类型select convert(varchar(10),getdate(),110)
-
style 可取的值
101:mm/dd/yyyy
102:yyyy.mm.dd
103:dd/mm/yyyy
104:dd.mm.yyyy
105:dd-mm-yyyy
110:mm-dd-yyyy
111:yyyy/mm/dd
112:yyyymmdd(无分隔符)
120(或 126 对于 datetimeoffset):YYYY-MM-DD HH:MI:SS(ODBC 规范)
121(或 127 对于 datetimeoffset):YYYY-MM-DD HH:MI:SS.mmm(包括毫秒)
11.3 DATEDIFF() & DATEADD()
DATEDIFF() 函数返回两个日期之间的差异,以指定的日期部分(如年、月、日等)为单位。
DATEDIFF ( datepart , startdate , enddate )SELECT DATEDIFF(YEAR, '2000-01-01', '2024-10-23') AS YearsDifference;
DATEADD() 函数在给定的日期上添加或减去指定的时间间隔。
DATEADD ( datepart , number , date )-- datepart 是你想要添加或减去的日期部分。-- number 是你想要添加或减去的数量(可以是负数以表示减去)。-- date 是你要修改的日期。SELECT DATEADD(MONTH, 3, '2023-10-23') AS NewDate;
11.4 DATEPART() 提取year month day
DATEPART() 和DATENAME() 函数允许你提取日期或时间值的任何部分,如年、月、日、小时、分钟等。DATEPART() 返回INT类型,DATENAME() 返回VARCHAR型
DATEPART(datepart, date)
-- datepart:指定你想要返回的日期/时间部分。例如,year、month、day、hour 等。
-- 额外 可取参数week:返回日期是一年中的第几周。weekday:返回日期是星期几(1 表示星期日,2 表示星期一,以此类推)。quarter:返回日期是一年中的哪个季度。hour、minute、second:分别返回时间的小时、分钟和秒部分。SELECT DATEPART(year, '2024-10-23') AS YearPart;
-- 返回结果:2024SELECT DATEPART(month, '2024-10-23') AS YearPart;
-- 返回结果:10SELECT DATENAME(month, '2024-10-23') AS YearPart;
-- 返回结果:10-- 可以通过year month day 函数获取部分日期
select year(getdate()) AS YEAR
select month(getdate()) AS month
select day(getdate()) AS day
11.5 CHARINDEX()
主要用于查找一个子字符串在另一个字符串中的位置
类似PATINDEX 允许使用模式匹配
CHARINDEX ( expressionToFind , expressionToSearch [ , start_location ] )expressionToFind:要查找的子字符串。expressionToSearch:要在其中进行搜索的字符串。start_location(可选):开始搜索的起始位置,默认为1。SELECT CHARINDEX('world', 'hello world') AS Position;
-- 返回结果:7,因为'world'在'hello world'中从第7个字符开始。SELECT CHARINDEX('o', 'hello world', 5) AS Position; -- 返回结果:8,从第5个字符开始查找,'o'在'hello world'中从第8个字符开始。SELECT patindex('%o%', 'hello world') AS Position;
-- 返回结果:5
12、字符串函数
12.1 STUFF() 删除并替换字符串
用于删除字符串中的指定数量的字符,并在相同位置插入另一个字符串。
-- 注意 是从下角标1开始数
STUFF ( character_expression , start , length , replaceWith_expression )SELECT STUFF('123456789', 4, 3, 'abc') AS Result; -- 结果:'123abc789'
11.5 SUBSTRING() 截取字符串
从特定位置开始提取固定长度的子字符串
SELECT SUBSTRING('Hello, World!', 8, 5) AS Result;
-- 结果:'World'
11.6 LEFT() & RIGHT() 截取字符串
LEFT 和 RIGHT 是两个常用的字符串函数,用于从字符串的左侧或右侧提取指定数量的字符。
SELECT LEFT('Hello,world', 5) AS ExtractedString
-- 返回结果:Hello
SELECT RIGHT('Hello,World', 5) AS ExtractedString
-- 返回结果:World11.7 LTRIM () 删除空白字符串
ltrim 函数会扫描字符串的开始部分,并删除连续的空白字符(包括空格、制表符、换行符等),直到遇到第一个非空白字符。
SELECT ' Hello,World ' AS tem , LTRIM(' Hello,World ') AS TrimmedString
11.8 REVERSE() 反转字符串
REVERSE函数的作用是反转字符串中的字符顺序。
SELECT REVERSE('Hello World') AS ReversedString; -- 结果:'dlroW olleH'
11.9 replicate & space()
SPACE函数的作用是返回一个由指定数量的空格字符组成的字符串
select replicate('abc',5) as replicateStr
-- 返回结果: abcabcabcabcabc-- 获取空格字符串
select space(5) as spaceStr
13、 类型转换
13.1 CAST()
CAST函数允许你将一个数据类型的值转换为另一个数据类型的值。
CAST (expression AS data_type [ ( length ) ])expression:这是你要转换的值或表达式。data_type:这是你希望将expression转换成的数据类型。length(可选):这是目标数据类型的长度。对于某些数据类型(如VARCHAR),长度是必需的。SELECT name, CAST(age AS NVARCHAR(5)) AS age_string FROM student;-- 将字符串转换为整数
SELECT CAST('123' AS INT);-- 将日期时间字符串转换为日期时间格式:
SELECT CAST('2020-01-01 12:30:00' AS DATETIME);
14、条件判断
CASE函数是一个条件表达式,它允许在查询中根据指定的条件对数据进行条件判断和转换。
简单CASE函数
CASE <表达式> WHEN <值1> THEN <结果1> WHEN <值2> THEN <结果2> ... ELSE <默认结果>
ENDSELECT id, name, CASE sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '其他' END AS gender
FROM student;
搜索CASE函数
判断表达式的真假,并返回相应的结果。
sql
CASE WHEN <条件1> THEN <结果1> WHEN <条件2> THEN <结果2> ... ELSE <默认结果>
ENDSELECT id, name, CASE WHEN sex = '1' THEN '男' WHEN sex = '2' THEN '女' ELSE '其他' END AS gender
FROM student;

![mybatis varchar[] string[] 对应](/images/no-images.jpg)