系列文章目录🚩
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
文章目录
- 系列文章目录🚩
- 前言
- 一、概述
- 二、分词的粒度
- 三、分词器的类型
- 四、BPE/BBPE分词
- 五、WordPiece分词
- 六、Unigram 分词
- 七、分词器的选择
- 八、各大模型的分词效果
- 九、SentencePiece分词器使用
前言
在自然语言处理领域,大语言模型预训练数据准备是一个重要的环节。其中,词元化(Tokenization)作为预训练前期的关键步骤,旨在将原始文本分割成模型可识别和建模的词元序列,为大语言模型提供输入数据。本文将对词元化技术进行详细介绍,包括分词的粒度、分词器的类型以及各大模型的分词效果等内容。
一、概述
分词(词元化):词元化(Tokenization)是数据预处理中的一个关键步骤,旨在将原始文本分割成模型可识别和建模的词元序列,作为大语言模型的输入数据;形成一个词汇表。
传统自然语言处理研究(如基于条件随机场的序列标注)主要使用基于词汇的分词方法,这种方法更符合人类的语言认知。然而,基于词汇的分词在某些语言(如中文分词)中可能对于相同的输入产生不同的分词结果,导致生成包含海量低频词的庞大词表,还可能存在未登录词(Out-of-vocabulary, OOV)等问题。因此,一些语言模型开始采用字符作为最小单位来分词。其中子词分词器(Subword Tokenizer)被广泛应用于基于 Transformer 的语言模型中,包括 BPE 分词、WordPiece 分词和 Unigram 分词三种常见方法。
二、分词的粒度
从分词的粒度区分,主要包括3种类型,Word 、Subword、Char
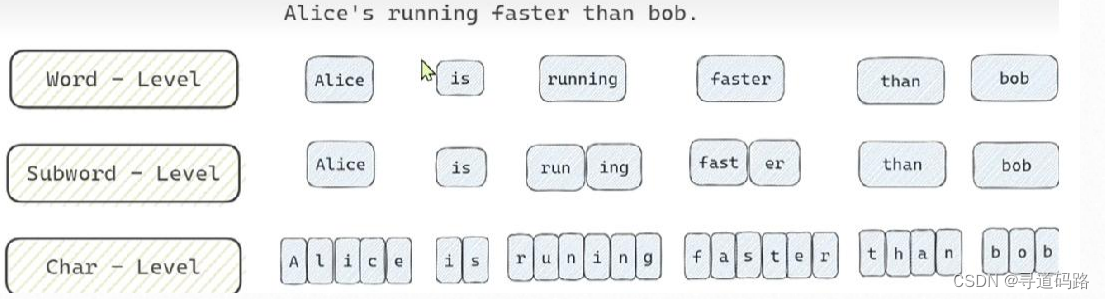
1)Word分词粒度以完整的单词为单位进行分词,能够很好地保留每个词的语义,适合上下文理解和语义分析。然而,它面临着长尾效应和稀有词问题,可能导致词汇表庞大并且出现OOV(Out-of-Vocabulary)问题。
OOV是“Out-Of-Vocabulary”的缩写,直译为“词汇表外的”,在自然语言处理中,表示的是那些在词汇表中没有的单词
2)Char分词粒度则是将文本拆分为字符级别,这样可以解决OOV问题,因为可以处理任何字符,但缺点是可能缺乏明确的语义信息,并且由于粒度过细,会增加后续处理的计算成本和时间。
3)Subword分词粒度介于Word和Char之间,旨在克服两者的缺点,同时保留语义信息并减少OOV问题的发生。Subword分词方法如BPE(Byte Pair Encoding)或WordPiece通过统计学方法切分单词为更小的有意义的单元,这使得它们在处理生僻词和缩写时更为有效。(目前使用比较广泛)
三、分词器的类型
针对Subword常用的分词器有3种:BPE 分词、WordPiece 分词和 Unigram 分词。
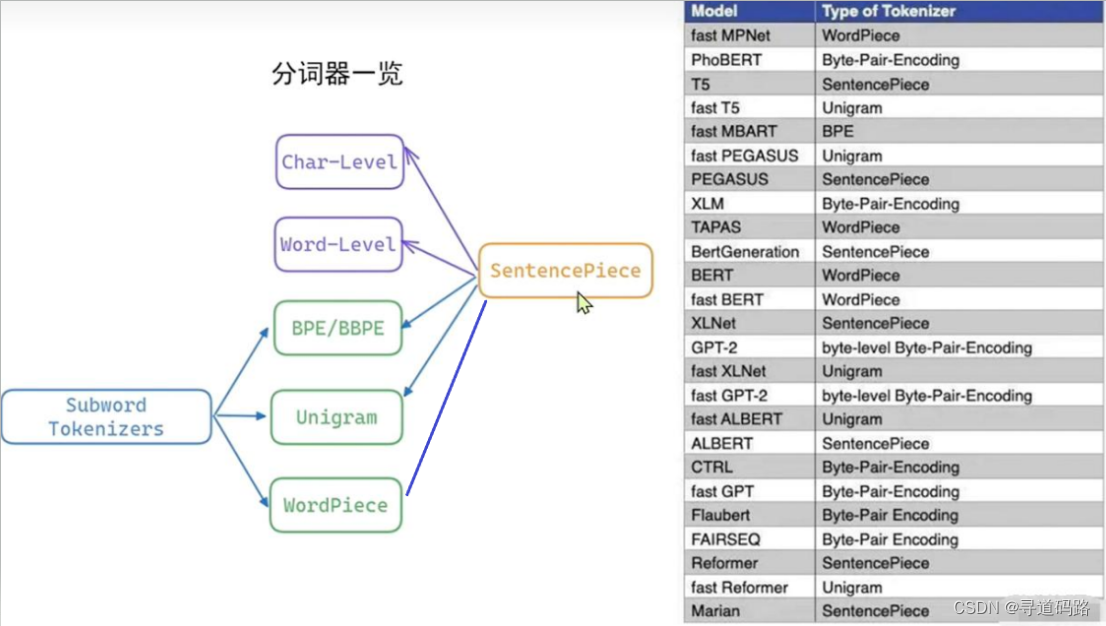
SentencePiece 是一个开源的分词器工具;是由谷歌开发的,旨在提供一种高效的方式来对文本进行分词,尤其适用于处理变长和不规则的文本数据。它通过训练特定领域的模型来代替预训练模型中的词表,从而更有效地处理词汇。常用的BPE、WordPiece、 Unigram分词器都支持。
四、BPE/BBPE分词
1)BPE:从字符级别开始,逐步合并最频繁连续出现的字符或字符组合,形成新的词汇单元。
2)BBPE:字节级别的 BPE(Byte-level BPE, B-BPE)是 BPE 算法的一种拓展。它将字节视为合并操作的基本符号,从而可以实现更细粒度的分割,且解决了未登录词问题。采用这种词元化方法的代表性语言模型包括 GPT-2 、BART 和 LLaMA 。
3)对于英文、拉美体系的语言来说使用BPE分词足以在可接受的词表大小下解决OOV的问题,但面对中文、日文等语言时,其稀有的字符可能会不必要的占用词汇表(词汇表要么巨大要么会OOV),因此考虑使用字节级别byte-level解决不同语言进行分词时OOV的问题。具体的,BBPE将一段文本的UTF-8编码(UTF-8保证任何语言都可以通用)中的一个字节256位不同的编码作为词表的初始化基础Subword。
例如,GPT-2 的词表大小为 50,257 ,包括 256 个字节的基本词元、一个特殊的文末词元以及通过 50,000 次合并学习到的词元。(相当于既有了BPE特性,又兼容了中文)

BBPE的优点:不会出现 OOV 的情况。不管是怎样的汉字,只要可以用字节表示,就都会存在于初始词表中。
BBPE的缺点:一个汉字由3个字节组成,一个汉字就会被切成多个token,但实际上这多个token没必要进行训练。
BPE词表构建整体流程如下:

五、WordPiece分词
1)WordPiece 分词和 BPE 分词的想法非常相似,都是通过迭代合并连续的词元,但是合并的选择标准略有不同WordPiece 分词算法并不选择最频繁的词对,而是使用下面的公式为每个词对计算分数

比如unable,BPE 只关心 token pair 的出现频率,即 freq_of_pair;WordPiece 还考虑了每个 token 的出现频率。即使 unable 出现频率很高,但如果 un 和 able 单个 token 的出现频率都很高,也不会合并它们。
2)WordPiece:就是将所有的「常用字」和「常用词」都存到词表中,当需要切词的时候就从词表里面查找即可。
WordPiece 的方式很有效,但当字词数目过于庞大时这个方式就有点难以实现了。对于一些多语言模型来讲,要想穷举所有语言中的常用词,这个量会非常大(穷举不全会造成 OOV)
六、Unigram 分词
Unigram分词器与BPE和WordPiece的不同在于它的构建过程。Unigram初始化时会创建一个非常大的词汇表,然后根据一定的标准逐步丢弃较不常用的词汇单元,直到满足限定的词汇表大小(比较适合处理生僻词)
七、分词器的选择
大语言模型通常使用 SentencePiece 代码库为预训练语料训练定制化的分词器(也可以自定义);
这一代码库支持字节级别的 BPE 、 Unigram 、WordPiece分词。为了训练出高效的分词器,通常主要关注以下几个因素。首先,分词器必须具备无损重构的特性,即其分词结果能够准确无误地还原为原始输入文本。其次,分词器应具有高压缩率,即在给定文本数据的情况下,经过分词处理后的词元数量应尽可能少,从而实现更为高效的文本编码和存储。具体来说,压缩比可以通过将原始文本的 UTF-8 字节数除以分词器生成的词元数(即每个词元的平均字节数)来计算:
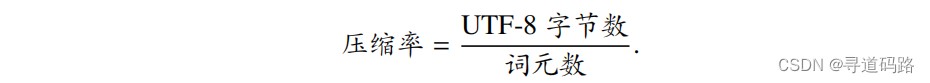
例如,给定一段大小为 1MB(1,048,576 字节)的文本,如果它被分词为 200,000
个词元,其压缩率即为 1,048,576/200,000=5.24
八、各大模型的分词效果
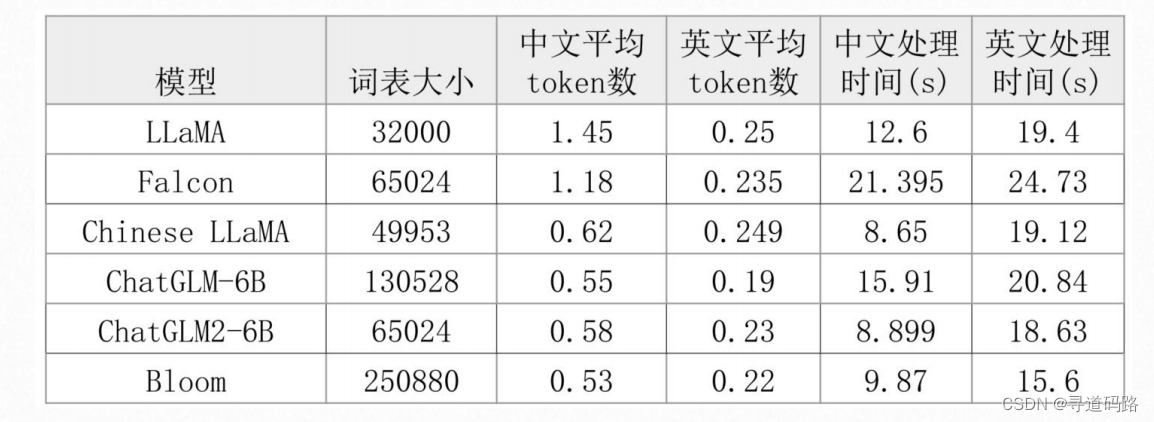
分词效果:男儿何不带吴钩,收取关山五十州
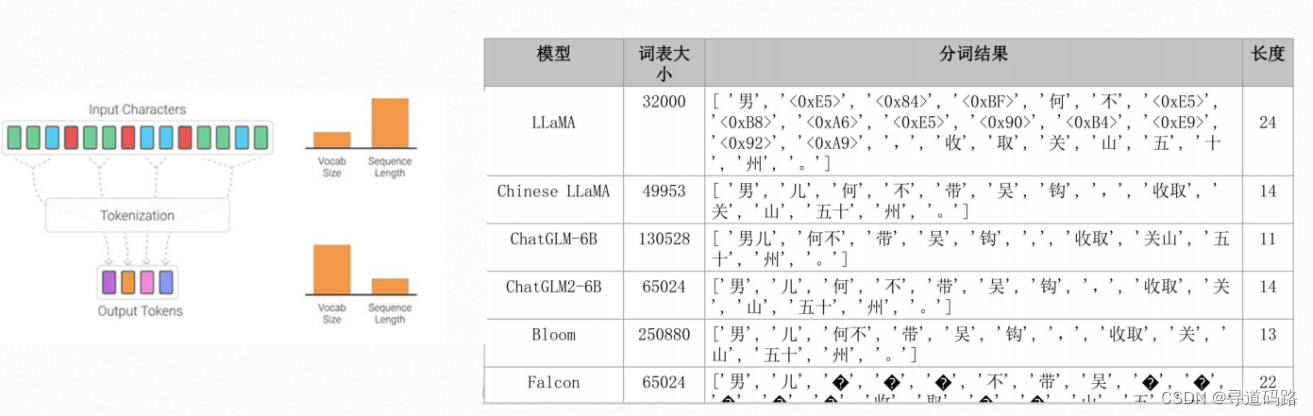
1、LLaMA 词表是最小的,LLaMA 在中英文上的平均 token 数都是最多的,意味 LLaMA 对中英文分词都会比较碎,比较细粒度。
尤其在中文上平均 token 数高达1.45,这意味着 LLaMA 大概率会将中文字符切分为2个以上的 token。
2、Chinese LLaMA 扩展词表后,中文平均 token 数显著降低,会将一个汉字或两个汉字切分为一个 token,提高了中文编码效率。
3、ChatGLM-6B 是平衡中英文分词效果最好的 tokenizer。由于词表比较大,中文处理时间也有增加。
4、BLOOM 虽然是词表最大的,但由于是多语种的,在中英文上分词效率与 ChatGLM-6B 基本相当。
九、SentencePiece分词器使用
SentencePiece地址:https://github.com/google/sentencepiece
1)安装相关依赖
pip install sentencepiece
2)分词器使用
% spm_train --input=<input> --model_prefix=<model_name> --vocab_size=8000 --character_coverage=1.0 --model_type=<type>
参数说明:
--input:原始语料库文件,可以传递以逗号分隔的文件列表。
--model_prefix:输出的词表名称; 文件格式:<model_name>.model 、 <model_name>.vocab
--vocab_size:设置词表大小,例如 8000、16000 或 32000
--character_coverage:词表对语料库的覆盖率,默认:0.9995 对于具有丰富字符集的语言(如日语或中文)和其他具有小字符集的语言可以设置为1.0 (即对原料库的覆盖率为100%,包含语料库所有的单词)
--model_type:模型类型。unigram (default), bpe, char, or word
🔖更多专栏系列文章:🚩🚩🚩AIGC-AI大模型探索之路
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,还望各位老铁多多关注并给予支持。




